Mulai cepat: Mengimpor dan mem-vektorisasi wizard data (pratinjau)
Penting
Wizard impor dan vektorisasi data berada dalam pratinjau publik di bawah Ketentuan Penggunaan Tambahan. Secara default, ini menargetkan REST API Pratinjau 2024-05-01.
Mulai menggunakan vektorisasi terintegrasi (pratinjau) menggunakan wizard Impor dan vektorisasi data di portal Azure. Panduan ini memanggil model penyematan yang ditentukan pengguna untuk mem-vektorisasi konten selama pengindeksan dan untuk kueri.
Anda memerlukan tiga sumber daya Azure dan beberapa file sampel untuk menyelesaikan panduan ini:
- Penyimpanan Azure Blob atau Microsoft Fabric dengan OneLake untuk data Anda
- Vektorisasi Azure: akun multiservice layanan Azure AI, Azure OpenAI, atau katalog model Azure AI Studio
- Pencarian azure AI untuk pengindeksan dan kueri
Batasan pratinjau
Data sumber adalah file Dan pintasan Azure Blob Storage atau OneLake, menggunakan mode penguraian default (satu dokumen pencarian per blob atau file).
Skema indeks tidak dapat dikonfigurasi. Bidang sumber mencakup "konten" (dipotong dan di-vektorisasi), "metadata_storage_name" untuk judul, dan "metadata_storage_path" untuk kunci dokumen, yang diwakili sebagai
parent_iddalam Indeks.Penggugusan tidak dapat dikonfigurasi. Pengaturan yang efektif adalah:
textSplitMode: "pages", maximumPageLength: 2000, pageOverlapLength: 500
Untuk lebih sedikit batasan atau lebih banyak opsi sumber data, coba pendekatan basis kode. Lihat sampel vektorisasi terintegrasi untuk detailnya.
Prasyarat
Langganan Azure. Buat akun gratis.
Untuk data, gunakan penyimpanan Azure Blob atau lakehouse OneLake.
Azure Storage harus merupakan akun performa standar (tujuan umum v2). Tingkat akses bisa panas, dingin, dan dingin. Jangan gunakan ADLS Gen2 (akun penyimpanan dengan namespace hierarkis). ADLS Gen2 tidak didukung dengan versi wizard ini.
Untuk vektorisasi, miliki akun multiservice layanan Azure AI atau titik akhir Azure OpenAI dengan penyebaran.
Untuk multimodal dengan Azure AI Vision, buat layanan Azure AI di SwedenCentral, EastUS, NorthEurope, WestEurope, WestUS, SoutheastAsia, KoreaCentral, FranceCentral, AustraliaEast, WestUS2, SwissNorth, JapanEast. Periksa dokumentasi untuk daftar yang diperbarui.
Anda juga dapat menggunakan katalog model Azure AI Studio (dan hub dan proyek) dengan penyebaran model.
Pencarian Azure AI, di wilayah yang sama dengan layanan Azure AI Anda. Kami merekomendasikan tingkat Dasar atau yang lebih tinggi.
Penetapan peran atau kunci API diperlukan agar koneksi dapat menyematkan model dan sumber data. Instruksi untuk akses berbasis peran disediakan dalam artikel ini.
Semua sumber daya di atas harus mengaktifkan akses publik agar simpul portal dapat mengaksesnya. Jika tidak, wizard gagal. Setelah wizard berjalan, firewall dan titik akhir privat dapat diaktifkan pada komponen integrasi yang berbeda untuk keamanan. Untuk informasi selengkapnya, lihat Mengamankan koneksi di wizard impor.
Jika titik akhir privat sudah ada dan tidak dapat dinonaktifkan, opsi alternatifnya adalah menjalankan alur end-to-end masing-masing dari skrip atau program dari komputer virtual dalam jaringan virtual yang sama dengan titik akhir privat. Berikut adalah sampel kode Python untuk vektorisasi terintegrasi. Dalam repositori GitHub yang sama adalah sampel dalam bahasa pemrograman lainnya.
Layanan pencarian gratis mendukung kontrol akses berbasis peran pada koneksi ke Azure AI Search, tetapi tidak mendukung identitas terkelola pada koneksi keluar ke Azure Storage atau Azure AI Vision. Ini berarti Anda harus menggunakan autentikasi berbasis kunci pada koneksi layanan pencarian gratis ke layanan Azure lainnya. Untuk koneksi yang lebih aman, gunakan tingkat dasar atau di atasnya dan konfigurasikan identitas terkelola dan penetapan peran untuk menerima permintaan dari Azure AI Search di layanan Azure lainnya.
Periksa ruang
Jika Anda memulai dengan layanan gratis, Anda dibatasi hingga tiga indeks, tiga sumber data, tiga set keterampilan, dan tiga pengindeks. Pastikan Anda memiliki ruang untuk item tambahan sebelum memulai. Mulai cepat ini membuat salah satu dari setiap objek.
Periksa identitas layanan
Kami merekomendasikan penetapan peran untuk koneksi layanan pencarian ke sumber daya lain.
Pada Azure AI Search, aktifkan akses berbasis peran.
Konfigurasikan layanan pencarian Anda untuk menggunakan sistem atau identitas terkelola yang ditetapkan pengguna.
Di bagian berikut, Anda dapat menetapkan identitas terkelola layanan pencarian ke peran di layanan lain. Langkah-langkah untuk penetapan peran disediakan jika berlaku.
Periksa peringkat semantik
Wizard ini mendukung peringkat semantik, tetapi hanya pada tingkat Dasar dan yang lebih tinggi, dan hanya jika peringkat semantik sudah diaktifkan pada layanan pencarian Anda. Jika Anda menggunakan tingkat yang dapat ditagih, periksa untuk melihat apakah peringkat semantik diaktifkan.
Menyiapkan data sampel
Bagian ini mengarahkan Anda ke data yang berfungsi untuk mulai cepat ini.
Masuk ke portal Azure dengan akun Azure Anda, dan buka akun Azure Storage Anda.
Di panel navigasi, di bawah Penyimpanan Data, pilih Kontainer.
Buat kontainer baru lalu unggah dokumen PDF paket kesehatan yang digunakan untuk mulai cepat ini.
Pada Kontrol akses, tetapkan Pembaca Data Blob Penyimpanan pada kontainer ke identitas layanan pencarian. Atau, dapatkan string koneksi ke akun penyimpanan dari halaman Kunci akses.
Menyiapkan model penyematan
Vektorisasi terintegrasi dan wizard Impor dan vektorisasi data ketuk model penyematan yang disebarkan selama pengindeksan untuk mengonversi teks dan gambar menjadi vektor.
Anda dapat menggunakan model penyematan yang disebarkan di Azure OpenAI, Azure AI Vision untuk penyematan multimodal, atau di katalog model di Azure AI Studio.
Impor dan vektorisasi data mendukung: text-embedding-ada-002, text-embedding-3-large, text-embedding-3-small. Secara internal, wizard menggunakan keterampilan AzureOpenAIEmbedding untuk menyambungkan ke Azure OpenAI.
Gunakan instruksi ini untuk menetapkan izin atau mendapatkan kunci API untuk koneksi layanan pencarian ke Azure OpenAI. Anda harus menyiapkan izin atau memiliki informasi koneksi sebelum menjalankan wizard.
Masuk ke portal Azure dengan akun Azure Anda, dan buka sumber daya Azure OpenAI Anda.
Siapkan izin:
Pilih Kontrol akses dari menu sebelah kiri.
Pilih Tambahkan lalu pilih Tambahkan penetapan peran.
Di bawah Peran fungsi pekerjaan, pilih Pengguna OpenAI Cognitive Services lalu pilih Berikutnya.
Di bawah Anggota, pilih Identitas terkelola lalu pilih Anggota.
Filter menurut langganan dan jenis sumber daya (layanan Pencarian), lalu pilih identitas terkelola layanan pencarian Anda.
Pilih Tinjau + tetapkan.
Pada halaman Gambaran Umum, pilih Klik di sini untuk melihat titik akhir dan Klik di sini untuk mengelola kunci jika Anda perlu menyalin titik akhir atau kunci API. Anda dapat menempelkan nilai-nilai ini ke dalam wizard jika Anda menggunakan sumber daya Azure OpenAI dengan autentikasi berbasis kunci.
Di bawah Manajemen Sumber Daya dan penyebaran Model, pilih Kelola Penyebaran untuk membuka Azure AI Studio.
Salin nama penyebaran text-embedding-ada-002 atau model penyematan lain yang didukung. Jika Anda tidak memiliki model penyematan, sebarkan sekarang.
Memulai wizard
Masuk ke portal Azure dengan akun Azure Anda, dan buka layanan Pencarian Azure AI Anda.
Pada halaman Gambaran Umum , pilih Impor dan vektorisasi data.

Hubungkan ke data Anda
Langkah selanjutnya adalah menyambungkan ke sumber data yang akan digunakan untuk indeks pencarian.
Di wizard Impor dan vektorisasi data pada tab Sambungkan ke data Anda, perluas daftar dropdown Sumber Data dan pilih Azure Blob Storage atau OneLake.
Tentukan langganan Azure.
Untuk OneLake, tentukan URL lakehouse atau berikan ID ruang kerja dan lakehouse.
Untuk Azure Storage, pilih akun dan kontainer yang menyediakan data.
Tentukan apakah Anda ingin deteksi penghapusan.
Pilih Selanjutnya.
Vektorisasi teks Anda
Dalam langkah ini, tentukan model penyematan yang digunakan untuk mem-vektorisasi data yang dipotong.
Tentukan apakah model yang disebarkan ada di Azure OpenAI, katalog model Azure AI Studio, atau sumber daya multimodal Azure AI Vision yang ada di wilayah yang sama dengan Azure AI Search.
Tentukan langganan Azure.
Untuk Azure OpenAI, pilih layanan, penyebaran model, dan jenis autentikasi. Lihat Menyiapkan model penyematan untuk detailnya.
Untuk katalog AI Studio, pilih proyek, penyebaran model, dan jenis autentikasi. Lihat Menyiapkan model penyematan untuk detailnya.
Untuk vektorisasi Visi AI, pilih akun. Lihat Menyiapkan model penyematan untuk detailnya.
Pilih kotak centang yang mengakui dampak penagihan menggunakan sumber daya ini.
Pilih Selanjutnya.
Vektorisasi dan perkaya gambar Anda
Jika konten Anda menyertakan gambar, Anda dapat menerapkan AI dengan dua cara:
- Gunakan model penyematan gambar yang didukung dari katalog, atau pilih API penyematan multimodal Azure AI Vision untuk mem-vektorisasi gambar.
- Gunakan OCR untuk mengenali teks dalam gambar.
Azure AI Search dan sumber daya Azure AI Anda harus berada di wilayah yang sama.
Tentukan jenis koneksi yang harus dibuat wizard. Untuk vektorisasi gambar, ia dapat terhubung ke model penyematan di Azure AI Studio atau Azure AI Vision.
Tentukan langganan.
Untuk katalog model Azure AI Studio, tentukan proyek dan penyebaran. Lihat Menyiapkan model penyematan untuk detailnya.
Secara opsional, Anda dapat memecahkan gambar biner (misalnya, file dokumen yang dipindai) dan menggunakan OCR untuk mengenali teks.
Pilih kotak centang yang mengakui dampak penagihan menggunakan sumber daya ini.
Pilih Selanjutnya.
Pengaturan tingkat lanjut
Secara opsional, Anda dapat menambahkan peringkat semantik untuk mererank hasil di akhir eksekusi kueri, mempromosikan kecocokan yang paling relevan secara semantik ke bagian atas.
Secara opsional, tentukan jadwal run time untuk pengindeks.
Pilih Selanjutnya.
Menjalankan wizard
Pada Tinjau dan buat, tentukan awalan untuk objek yang dibuat saat wizard berjalan. Awalan umum membantu Anda tetap terorganisir.
Pilih Buat untuk menjalankan wizard. Langkah ini membuat objek berikut:
Koneksi sumber data.
Indeks dengan bidang vektor, vektorizer, profil vektor, algoritma vektor. Anda tidak diminta untuk merancang atau mengubah indeks default selama alur kerja wizard. Indeks sesuai dengan REST API 2024-05-01-preview.
Keterampilan dengan keterampilan Pemisahan Teks untuk pemotongan dan keterampilan penyematan untuk vektorisasi. Keterampilan penyematan adalah keterampilan AzureOpenAIEmbeddingModel untuk keterampilan Azure OpenAI atau AML untuk katalog model Azure AI Studio.
Pengindeks dengan pemetaan bidang dan pemetaan bidang output (jika berlaku).
Jika Anda tidak dapat memilih vektorizer Azure AI Vision, pastikan Anda memiliki sumber daya Azure AI Vision di wilayah yang didukung, dan bahwa identitas terkelola layanan pencarian Anda memiliki izin Pengguna OpenAI Cognitive Services.
Jika Anda tidak dapat maju melalui wizard karena opsi lain tidak tersedia (misalnya, Anda tidak dapat memilih sumber data atau model penyematan), kunjungi kembali penetapan peran. Pesan kesalahan menunjukkan bahwa model atau penyebaran tidak ada, padahal sebenarnya masalah sebenarnya adalah bahwa layanan pencarian tidak memiliki izin untuk mengaksesnya.
Memeriksa hasil
Penjelajah pencarian menerima string teks sebagai input lalu mem-vektorisasi teks untuk eksekusi kueri vektor.
Di portal Azure, di bawah Manajemen Pencarian dan Indeks, pilih indeks yang Anda buat.
Secara opsional, pilih Opsi kueri dan sembunyikan nilai vektor di hasil pencarian. Langkah ini membuat hasil pencarian Anda lebih mudah dibaca.
Pilih tampilan JSON sehingga Anda bisa memasukkan teks untuk kueri vektor Anda di parameter kueri vektor teks .
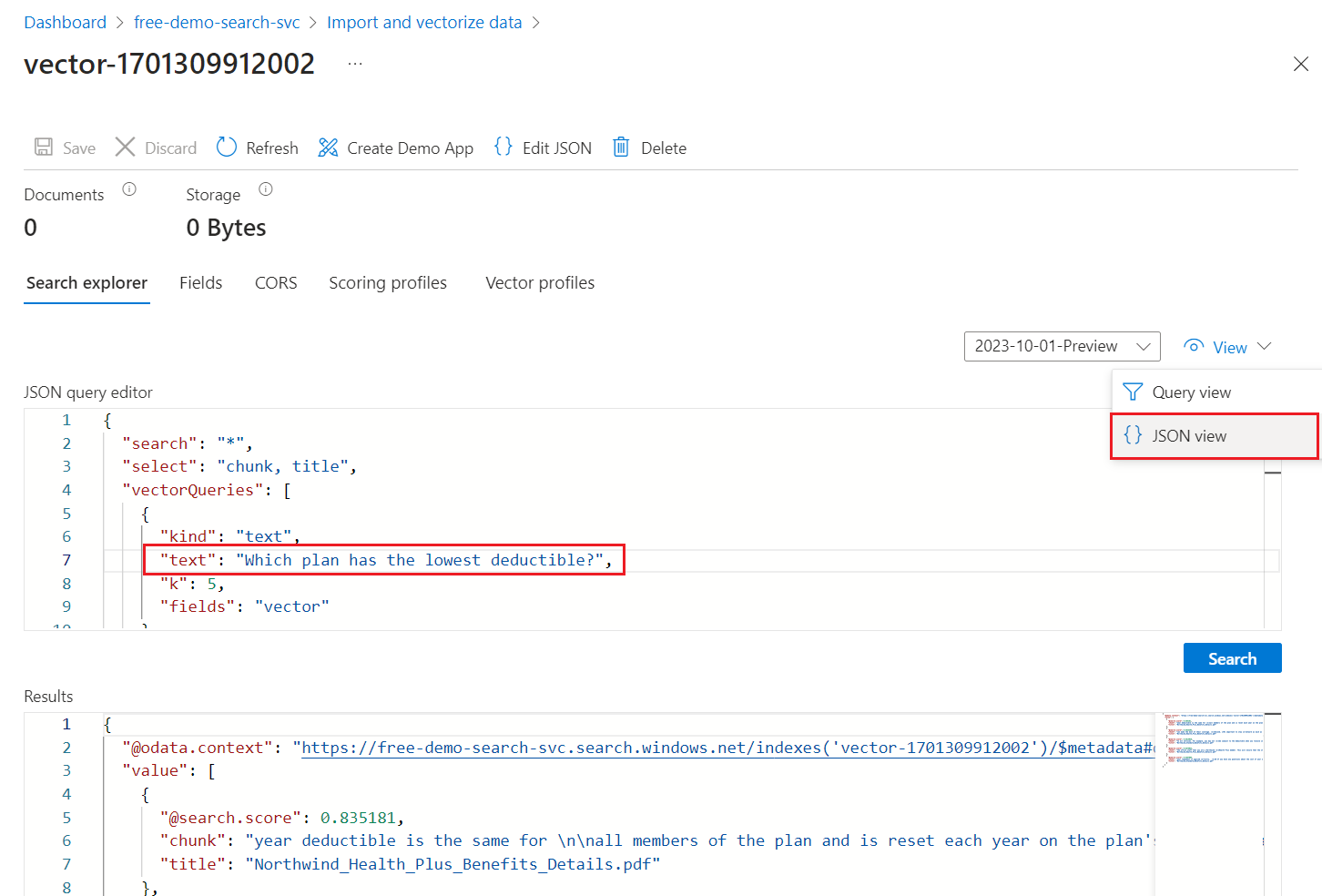
Wizard ini menawarkan kueri default yang mengeluarkan kueri vektor pada bidang "vektor", mengembalikan 5 tetangga terdekat. Jika Anda memilih untuk menyembunyikan nilai vektor, kueri default Anda menyertakan pernyataan "pilih" yang mengecualikan bidang vektor dari hasil pencarian.
{ "select": "chunk_id,parent_id,chunk,title", "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "vector" } ] }Ganti teks
"*"dengan pertanyaan yang terkait dengan rencana kesehatan, seperti "paket mana yang memiliki pengurangan terendah".Pilih Cari untuk menjalankan kueri.
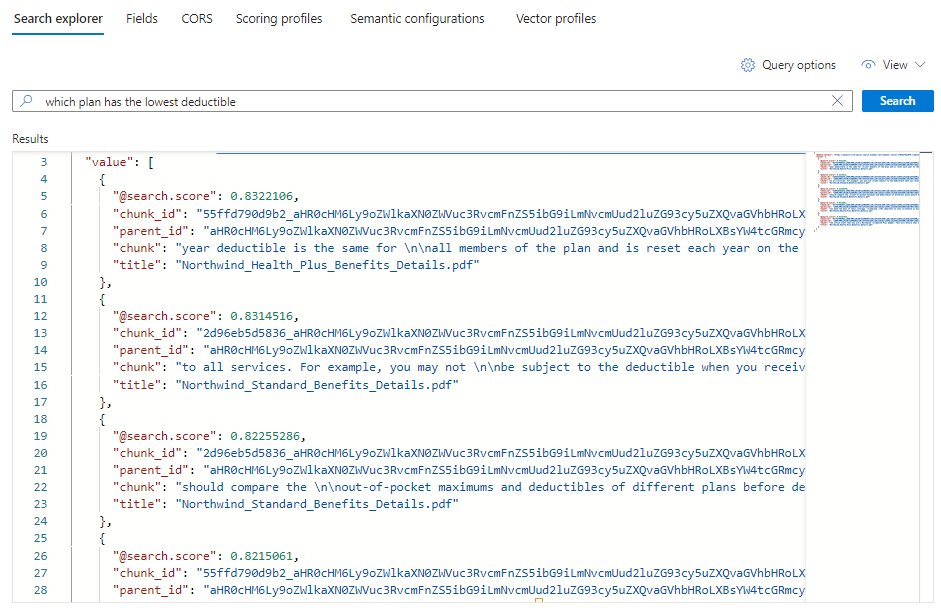
Anda akan melihat 5 kecocokan, di mana setiap dokumen adalah potongan PDF asli. Bidang judul menunjukkan DARI PDF mana gugus berasal.
Untuk melihat semua gugus dari dokumen tertentu, tambahkan filter untuk bidang judul untuk PDF tertentu:
{ "select": "chunk_id,parent_id,chunk,title", "filter": "title eq 'Benefit_Options.pdf'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "vector" } ] }
Penghapusan
Azure AI Search adalah sumber daya yang dapat ditagih. Jika tidak lagi diperlukan, hapus dari langganan Anda untuk menghindari biaya.
Langkah berikutnya
Mulai cepat ini memperkenalkan Anda ke wizard Impor dan vektorisasi data yang membuat semua objek yang diperlukan untuk vektorisasi terintegrasi. Jika Anda ingin menjelajahi setiap langkah secara rinci, coba sampel vektorisasi terintegrasi.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk