Pengantar pemantauan kesehatan Service Fabric
Azure Service Fabric memperkenalkan model kesehatan yang menyediakan evaluasi dan pelaporan kesehatan yang kaya, fleksibel, dan dapat diperluas. Model ini memungkinkan pemantauan hampir real-time dari keadaan kluster dan layanan yang berjalan di dalamnya. Anda dapat dengan mudah mendapatkan informasi kesehatan dan memperbaiki masalah potensial sebelum bertingkat dan menyebabkan pemadaman besar-besaran. Dalam model umum, layanan mengirim laporan berdasarkan tampilan lokal mereka, dan informasi itu dikumpulkan untuk memberikan tampilan tingkat kluster secara keseluruhan.
Komponen Service Fabric menggunakan model kesehatan yang kaya ini untuk melaporkan keadaannya saat ini. Anda dapat menggunakan mekanisme yang sama untuk melaporkan kesehatan aplikasi Anda. Jika Anda berinvestasi dalam pelaporan kesehatan berkualitas tinggi yang menangkap kondisi kustom Anda, Anda dapat mendeteksi dan memperbaiki masalah untuk aplikasi yang sedang berjalan dengan lebih mudah.
Catatan
Kita memulai subsistem kesehatan untuk mengatasi kebutuhan akan peningkatan yang terpantau. Service Fabric menyediakan peningkatan aplikasi dan kluster yang dipantau yang memastikan ketersediaan penuh, tidak ada downtime dan minimal untuk tidak ada intervensi pengguna. Untuk mencapai tujuan ini, peningkatan memeriksa kesehatan berdasarkan kebijakan peningkatan yang telah dikonfigurasi. Peningkatan hanya dapat dilanjutkan ketika kesehatannya sesuai dengan ambang batas yang diinginkan. Jika tidak, peningkatan secara otomatis digulung balik atau dijeda untuk memberi administrator kesempatan memperbaiki masalahnya. Untuk mempelajari selengkapnya tentang peningkatan aplikasi, lihat artikel ini.
Penyimpanan kesehatan
Penyimpanan kesehatan menyimpan informasi terkait kesehatan tentang entitas dalam kluster agar mudah diambil dan dievaluasi. Ini diimplementasikan sebagai layanan stateful yang terus ada di Service Fabric untuk memastikan ketersediaan dan skalabilitas yang tinggi. Penyimpanan kesehatan adalah bagian dari aplikasi fabric:/System, dan tersedia ketika kluster sedang berjalan.
Entitas kesehatan dan hierarki
Entitas kesehatan diatur dalam hierarki logis yang menangkap interaksi dan ketergantungan di antara entitas yang berbeda. Penyimpanan kesehatan secara otomatis membangun entitas kesehatan dan hierarki berdasarkan laporan yang diterima dari komponen Service Fabric.
Entitas kesehatan mencerminkan entitas Service Fabric. (Misalnya, entitas aplikasi kesehatan cocok dengan instans aplikasi yang diterapkan dalam kluster, sementara entitas node kesehatan cocok dengan node kluster Service Fabric.) Hierarki kesehatan menangkap interaksi entitas sistem, dan itu adalah dasar untuk evaluasi kesehatan lanjutan. Anda dapat mempelajari konsep Service Fabric utama dalam rangkuman teknis Service Fabric. Untuk informasi selengkapnya tentang aplikasi, lihat model aplikasi Service Fabric.
Entitas kesehatan dan hierarki memungkinkan kluster dan aplikasi dilaporkan, didebug, dan dipantau secara efektif. Model kesehatan memberikan representasi yang akurat dan terperinci kesehatan dari komponen-komponen yang bergerak dalam kluster.
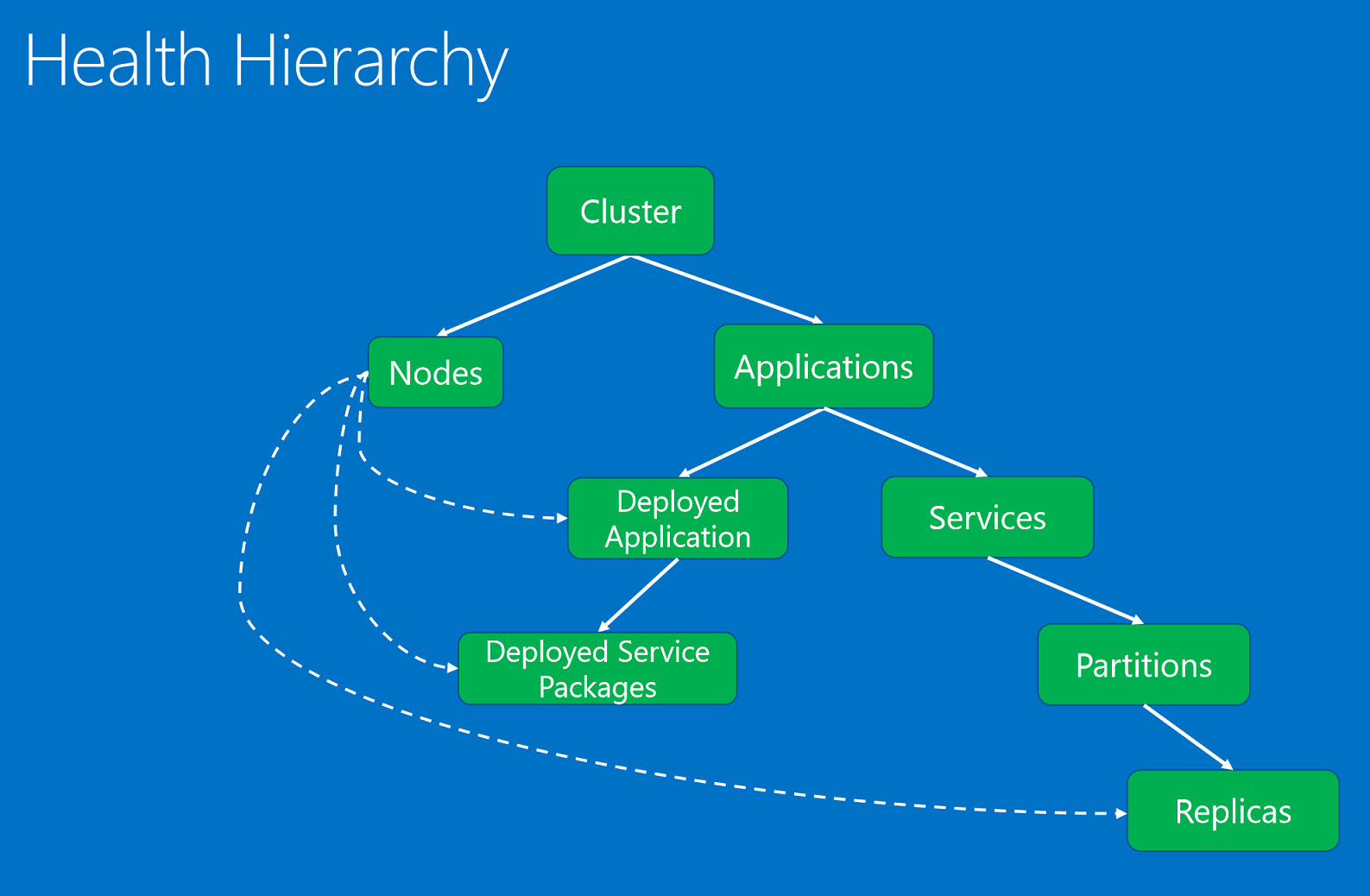 Entitas kesehatan, diatur dalam hierarki berdasarkan hubungan induk-anak.
Entitas kesehatan, diatur dalam hierarki berdasarkan hubungan induk-anak.
Entitas kesehatan adalah:
- Kluster. Merepresentasikan kesehatan kluster Service Fabric. Laporan kesehatan kluster menjelaskan kondisi yang memengaruhi seluruh kluster. Kondisi ini memengaruhi beberapa entitas dalam kluster atau kluster itu sendiri. Berdasarkan kondisi tersebut, pelapor tidak bisa mempersempit masalah tersebut kepada satu atau beberapa anak yang tidak sehat. Contohnya termasuk otak kluster yang membelah karena partisi jaringan atau masalah komunikasi.
- Node. merepresentasikan kesehatan dari node Service Fabric. Laporan kesehatan node menjelaskan kondisi yang memengaruhi fungsionalitas node. Kondisi tersebut biasanya memengaruhi semua entitas yang dikerahkan yang berjalan di atasnya. Contohnya termasuk node di luar ruang disk (atau properti di seluruh komputer lainnya, seperti memori, koneksi) dan ketika sebuah node mati. Entitas node diidentifikasi dengan nama node (string).
- Aplikasi. Mewakili kesehatan instans aplikasi yang berjalan di kluster. Laporan kesehatan aplikasi menjelaskan kondisi yang memengaruhi kesehatan aplikasi secara keseluruhan. Kondisi tersebut tidak dapat dipersempit ke anak-anak individu (layanan atau aplikasi yang diterapkan). Contohnya termasuk interaksi end-to-end di antara berbagai layanan dalam aplikasi. Entitas aplikasi diidentifikasi dengan nama aplikasi (URI).
- Layanan. Merepresentasikan kesehatan layanan yang berjalan di kluster. Laporan kesehatan layanan menjelaskan kondisi yang memengaruhi kesehatan layanan secara keseluruhan. Pelapor tidak dapat mempersempit masalah ke partisi atau replika yang tidak sehat. Contohnya termasuk konfigurasi layanan (seperti port atau berbagi file eksternal) yang menyebabkan masalah untuk semua partisi. Entitas layanan diidentifikasi dengan nama layanan (URI).
- Partisi. Merepresentasikan kesehatan partisi layanan. Laporan kesehatan partisi menjelaskan kondisi yang memengaruhi seluruh set replika. Contohnya termasuk ketika jumlah replika di bawah jumlah target dan ketika partisi berada dalam hilangnya kuorum. Entitas partisi diidentifikasi oleh ID partisi (GUID).
- Replika. Mewakili kesehatan replika layanan stateful atau instans layanan stateless. Replika adalah unit terkecil yang dapat dilaporkan oleh pengawas dan komponen sistem untuk aplikasi. Untuk layanan stateful, contohnya termasuk replika utama yang tidak dapat mereplikasi operasi ke sekunder dan replikasi lambat. Selain itu, instans stateless dapat melaporkan ketika kehabisan sumber daya atau memiliki masalah konektivitas. Entitas replika diidentifikasi oleh ID partisi (GUID) dan ID replika atau instans (panjang).
- DeployedApplication. Merepresentasikan kesehatan aplikasi yang berjalan pada node. Laporan kesehatan aplikasi yang disebarkan menjelaskan kondisi khusus untuk aplikasi pada node yang tidak dapat dipersempit ke paket layanan yang diterapkan pada node yang sama. Contohnya termasuk kesalahan ketika paket aplikasi tidak dapat diunduh pada node tersebut dan masalah pengaturan prinsip keamanan aplikasi pada node. Aplikasi yang digunakan diidentifikasi dengan nama aplikasi (URI) dan nama node (string).
- DeployedServicePackage. Mewakili kesehatan paket layanan yang berjalan pada node di kluster. Ini menjelaskan kondisi khusus untuk paket layanan yang tidak memengaruhi paket layanan lain pada node yang sama untuk aplikasi yang sama. Contohnya termasuk paket kode dalam paket layanan yang tidak dapat dimulai dan paket konfigurasi yang tidak dapat dibaca. Paket layanan yang digunakan diidentifikasi dengan nama aplikasi (URI), nama node (string), nama manifes layanan (string), dan ID aktivasi paket layanan (string).
Granularitas model kesehatan membuatnya mudah untuk mendeteksi dan memperbaiki masalah. Misalnya, jika layanan tidak merespons, layak untuk melaporkan bahwa instans aplikasi tidak sehat. Pelaporan pada tingkat tersebut tidak ideal, tetapi karena masalahnya mungkin tidak memengaruhi semua layanan dalam aplikasi itu. Laporan harus diterapkan ke layanan tidak sehat atau partisi anak tertentu, jika informasi lebih lanjut menunjuk ke partisi tersebut. Data secara otomatis muncul melalui hierarki, dan partisi yang tidak sehat dibuat terlihat pada tingkat layanan dan aplikasi. Agregasi ini membantu menentukan dan menyelesaikan akar penyebab masalah dengan lebih cepat.
Hierarki kesehatan terdiri dari hubungan induk-anak. Kluster terdiri dari node dan aplikasi. Aplikasi memiliki layanan dan aplikasi yang digunakan. Aplikasi yang digunakan telah menyebarkan paket layanan. Layanan memiliki partisi, dan setiap partisi memiliki satu atau beberapa replika. Ada hubungan khusus antara node dan entitas yang digunakan. Node yang tidak sehat seperti yang dilaporkan oleh komponen sistem otoritasnya, layanan Failover Manager, memengaruhi aplikasi, paket layanan, dan replika yang diterapkan di atasnya.
Hierarki kesehatan mewakili keadaan terbaru sistem berdasarkan laporan kesehatan terbaru, berupa informasi yang hampir real-time. Pengawas internal dan eksternal dapat melaporkan entitas yang sama berdasarkan logika khusus aplikasi atau kondisi yang dipantau khusus. Laporan-laporan pengguna hadir berdampingan dengan laporan sistem.
Rencanakan untuk berinvestasi dalam cara melaporkan dan menanggapi kesehatan selama desain layanan cloud besar. Investasi di muka ini membuat layanan lebih mudah untuk didebug, dipantau, dan dioperasikan.
Status kesehatan
Service Fabric menggunakan tiga status kesehatan untuk menggambarkan apakah entitas tersebut sehat ataukah tidak: OK, peringatan, dan kesalahan. Setiap laporan yang dikirim ke penyimpanan kesehatan harus menentukan salah satu status ini. Hasil evaluasi kesehatannya adalah salah satu status ini.
Kemungkinan dari status kesehatan adalah:
- OK. Entitasnya sehat. Tidak ada masalah yang diketahui yang dilaporkan di dalamnya atau di dalam anak-anaknya (jika berlaku).
- Peringatan. Entitas memiliki beberapa masalah, tetapi masih dapat berfungsi dengan benar. Misalnya, terjadi keterlambatan, tetapi belum menyebabkan masalah fungsional. Dalam beberapa kasus, kondisi peringatan dapat memperbaiki dirinya sendiri tanpa intervensi eksternal. Dalam kasus ini, laporan kesehatan meningkatkan kesadaran dan memberikan visibilitas terhadap apa yang sedang terjadi. Dalam kasus lain, kondisi peringatan dapat menurun menjadi masalah parah tanpa intervensi pengguna.
- Kesalahan. Entitasnya tidak sehat. Tindakan harus diambil untuk memperbaiki keadaan entitas, karena tidak dapat berfungsi dengan baik.
- Tidak diketahui. Entitas tidak ada di penyimpanan kesehatan. Hasil ini dapat diperoleh dari kueri terdistribusi yang menggabungkan hasil dari beberapa komponen. Misalnya, kueri dapatkan daftar node menuju ke FailoverManager, ClusterManager, dan HealthManager; kueri dapatkan daftar aplikasi masuk ke ClusterManager dan HealthManager. Kueri ini menggabungkan hasil dari beberapa komponen sistem. Jika komponen sistem lain mengembalikan entitas yang tidak ada di penyimpanan kesehatan, hasil gabungan memiliki status kesehatan yang tidak diketahui. Entitas tidak disimpan karena laporan kesehatan belum diproses atau entitas telah dibersihkan setelah penghapusan.
Kebijakan kesehatan
Penyimpanan kesehatan menerapkan kebijakan kesehatan untuk menentukan apakah entitas sehat berdasarkan laporannya dan anak-anaknya.
Catatan
Kebijakan kesehatan dapat ditentukan dalam manifes kluster (untuk evaluasi kesehatan kluster dan node) atau dalam manifes aplikasi (untuk evaluasi aplikasi dan anak-anaknya). Permintaan evaluasi kesehatan juga dapat lolos dalam kebijakan evaluasi kesehatan kustom, yang hanya digunakan untuk evaluasi tersebut.
Secara default, Service Fabric menerapkan aturan ketat (semuanya harus sehat) untuk hubungan hierarki induk-anak. Jika pun salah satu anak memiliki satu kejadian tidak sehat, induk dianggap tidak sehat.
Kebijakan kesehatan kluster
Kebijakan kesehatan kluster digunakan untuk mengevaluasi status kesehatan kluster dan status kesehatan node. Kebijakan dapat ditentukan dalam manifes kluster. Jika tidak ada, akan digunakan kebijakan default (nol kegagalan yang ditoleransi).
Kebijakan kesehatan kluster berisi:
ConsiderWarningAsError. Menentukan apakah akan memperlakukan laporan kesehatan peringatan sebagai kesalahan selama evaluasi kesehatan. Default: false.
MaxPercentUnhealthyApplications. Menentukan persentase maksimum aplikasi yang ditoleransi yang dapat tidak sehat sebelum kluster dianggap dalam kesalahan.
MaxPercentUnhealthyNodes. Menentukan persentase maksimum node yang ditoleransi yang dapat tidak sehat sebelum kluster dianggap dalam kesalahan. Dalam kluster besar, beberapa node akan selalu dihentikan atau keluar untuk perbaikan, jadi persentase ini harus dikonfigurasi untuk mentolerir itu.
ApplicationTypeHealthPolicyMap. Peta kebijakan kesehatan jenis aplikasi dapat digunakan selama evaluasi kesehatan kluster untuk menggambarkan jenis aplikasi khusus. Secara default, semua aplikasi dimasukkan ke dalam kumpulan dan dievaluasi dengan MaxPercentUnhealthyApplications. Jika beberapa jenis aplikasi harus diperlakukan secara berbeda, maka dapat dibawa keluar dari kolam global. Sebaliknya, jenis-jenis aplikasi tersebut dievaluasi terhadap persentase yang terkait dengan nama jenis aplikasi mereka di peta. Misalnya, dalam sebuah kluster ada ribuan aplikasi dari berbagai jenis, dan beberapa instans aplikasi kontrol dari jenis aplikasi khusus. Aplikasi kontrol tidak boleh dalam status kesalahan. Anda dapat menentukan MaxPercentUnhealthyApplications global hingga 20% untuk menolerir beberapa kegagalan, tetapi untuk jenis aplikasi "ControlApplicationType" atur MaxPercentUnhealthyApplications ke 0. Dengan demikian, jika beberapa dari banyak aplikasi dalam status tidak sehat, tetapi di bawah persentase tidak sehat global, kluster akan dievaluasi ke Peringatan. Status kesehatan peringatan tidak memengaruhi peningkatan kluster atau pemantauan lain yang dipicu oleh status kesehatan Kesalahan. Tetapi bahkan satu aplikasi kontrol dalam status kesalahan akan membuat kluster tidak sehat, yang memicu pembatalan atau menjeda peningkatan kluster, tergantung konfigurasi peningkatannya. Untuk jenis aplikasi yang ditentukan dalam peta, semua instans aplikasi diambil dari kumpulan aplikasi global. Semua instans aplikasi tersebut dievaluasi berdasarkan jumlah total aplikasi dari jenis aplikasi, menggunakan MaxPercentUnhealthyApplications tertentu dari peta. Semua aplikasi lainnya tetap berada di kumpulan global dan dievaluasi dengan MaxPercentUnhealthyApplications.
Contoh berikut adalah kutipan dari manifes kluster. Untuk menentukan entri dalam peta jenis aplikasi, awali nama parameter dengan "ApplicationTypeMaxPercentUnhealthyApplications-", diikuti dengan nama jenis aplikasi.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="ApplicationTypeMaxPercentUnhealthyApplications-ControlApplicationType" Value="0" /> </Section> </FabricSettings>NodeTypeHealthPolicyMap. Peta kebijakan kesehatan jenis node dapat digunakan selama evaluasi kesehatan kluster untuk menggambarkan jenis node khusus. Jenis-jenis aplikasi tersebut dievaluasi terhadap persentase yang terkait dengan nama jenis node mereka di peta. Menetapkan nilai ini tidak berpengaruh pada kumpulan node global yang digunakan untukMaxPercentUnhealthyNodes. Misalnya, kluster memiliki ratusan node dari berbagai jenis dan beberapa jenis node yang menghosting pekerjaan penting. Tidak ada node dalam jenis tersebut yang harus turun. Anda dapat menentukanMaxPercentUnhealthyNodesglobal hingga 20% untuk mentolerir beberapa kegagalan untuk semua node, tetapi untuk jenis nodeSpecialNodeType, aturMaxPercentUnhealthyNodeske 0. Dengan demikian, jika beberapa dari banyak node dalam status tidak sehat, tetapi di bawah persentase tidak sehat global, kluster akan dievaluasi sebagai berada dalam status kesehatan Peringatan. Status kesehatan peringatan tidak memengaruhi peningkatan kluster atau pemantauan lain yang dipicu oleh status kesehatan Kesalahan. Tetapi bahkan satu node jenisSpecialNodeTypedalam status kesehatan Kesalahan akan membuat kluster tidak sehat dan memicu pembatalan atau menjeda peningkatan kluster, tergantung konfigurasi peningkatannya. Sebaliknya, mengatur globalMaxPercentUnhealthyNodeske 0 dan menetapkanSpecialNodeTypenode tidak sehat persen maks menjadi 100 dengan satu node jenisSpecialNodeTypedalam status kesalahan akan tetap menempatkan kluster tersebut dalam status kesalahan karena pembatasan global lebih ketat dalam kasus ini.Contoh berikut adalah kutipan dari manifes kluster. Untuk menentukan entri dalam peta jenis node, awali nama parameter dengan "NodeTypeMaxPercentUnhealthyNodes-", diikuti dengan nama jenis node.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="NodeTypeMaxPercentUnhealthyNodes-SpecialNodeType" Value="0" /> </Section> </FabricSettings>
Kebijakan kesehatan aplikasi
Kebijakan kesehatan aplikasi menggambarkan bagaimana evaluasi peristiwa dan agregasi anak-status dilakukan untuk aplikasi dan anak-anaknya. Ini dapat didefinisikan dalam manifes aplikasi, ApplicationManifest.xml, dalam paket aplikasi. Jika tidak ada kebijakan yang ditentukan, Service Fabric mengasumsikan bahwa entitas tersebut tidak sehat jika memiliki laporan kesehatan atau anak pada status kesehatan peringatan atau kesalahan. Kebijakan yang dapat dikonfigurasi adalah:
- ConsiderWarningAsError. Menentukan apakah akan memperlakukan laporan kesehatan peringatan sebagai kesalahan selama evaluasi kesehatan. Default: false.
- MaxPercentUnhealthyDeployedApplications. Menentukan persentase maksimum aplikasi yang disebarkan yang dapat tidak sehat sebelum aplikasi dianggap dalam kesalahan. Persentase ini dihitung dengan membagi jumlah aplikasi yang tidak sehat yang disebarkan melebihi jumlah node yang saat ini digunakan aplikasi di kluster tersebut. Perhitungan dibulatkan ke atas untuk mentolerir satu kegagalan pada sejumlah kecil node. Persentase default: nol.
- DefaultServiceTypeHealthPolicy. Menentukan kebijakan kesehatan jenis layanan default, yang menggantikan kebijakan kesehatan default untuk semua jenis layanan dalam aplikasi.
- ServiceTypeHealthPolicyMap. Menyediakan peta kebijakan kesehatan layanan per jenis layanan. Kebijakan ini menggantikan kebijakan kesehatan jenis layanan default untuk setiap jenis layanan yang telah ditentukan. Misalnya, jika aplikasi memiliki jenis layanan gateway stateless dan jenis layanan komputer stateful, Anda dapat mengonfigurasi kebijakan kesehatan untuk evaluasinya secara berbeda. Ketika Anda menentukan kebijakan per jenis layanan, Anda dapat memperoleh kontrol yang lebih terperinci tentang kesehatan layanan tersebut.
Kebijakan kesehatan jenis layanan
Kebijakan kesehatan jenis layanan menentukan cara mengevaluasi dan menggabungkan layanan dan anak-anak layanan. Kebijakan tersebut berisi:
- MaxPercentUnhealthyPartitionsPerService. Menentukan persentase maksimum yang ditoleransi dari partisi tidak sehat sebelum layanan dianggap tidak sehat. Persentase default: nol.
- MaxPercentUnhealthyReplicasPerPartition. Menentukan persentase maksimum yang ditoleransi dari replika tidak sehat sebelum suatu partisi dianggap tidak sehat. Persentase default: nol.
- MaxPercentUnhealthyServices. Menentukan persentase maksimum yang ditoleransi dari layanan tidak sehat sebelum suatu aplikasi dianggap tidak sehat. Persentase default: nol.
Contoh berikut adalah kutipan dari manifes aplikasi:
<Policies>
<HealthPolicy ConsiderWarningAsError="true" MaxPercentUnhealthyDeployedApplications="20">
<DefaultServiceTypeHealthPolicy
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="10"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="FrontEndServiceType"
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="20"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="BackEndServiceType"
MaxPercentUnhealthyServices="20"
MaxPercentUnhealthyPartitionsPerService="0"
MaxPercentUnhealthyReplicasPerPartition="0">
</ServiceTypeHealthPolicy>
</HealthPolicy>
</Policies>
Evaluasi kesehatan
Pengguna dan layanan otomatis dapat mengevaluasi kesehatan untuk entitas apa pun kapan saja. Untuk mengevaluasi kesehatan entitas, penyimpanan kesehatan menggabungkan semua laporan kesehatan pada entitas dan mengevaluasi semua anak-anaknya (jika berlaku). Algoritma agregasi kesehatan menggunakan kebijakan kesehatan yang menentukan cara mengevaluasi laporan kesehatan dan cara menggabungkan status kesehatan anak (jika berlaku).
Agregasi laporan kesehatan
Satu entitas dapat memiliki beberapa laporan kesehatan yang dikirimkan oleh pelapor yang berbeda (komponen sistem atau pengawas) pada properti yang berbeda. Agregasi menggunakan kebijakan kesehatan terkait, khususnya anggota ConsiderWarningAsError dari kebijakan kesehatan aplikasi atau kluster. ConsiderWarningAsError menentukan cara mengevaluasi peringatan.
Keadaan kesehatan agregat dipicu oleh laporan kesehatan terburuk pada entitas. Jika setidaknya ada satu laporan kesehatan kesalahan, status kesehatan agregatnya adalah kesalahan.
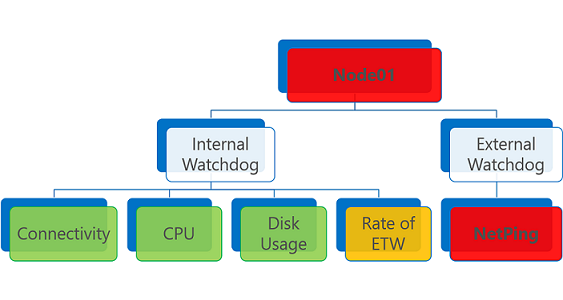
Entitas kesehatan yang memiliki satu atau beberapa laporan kesehatan kesalahan dievaluasi sebagai Kesalahan. Hal yang sama berlaku untuk laporan kesehatan yang kedaluwarsa, apa pun kondisi kesehatannya.
Jika tidak ada laporan kesalahan dan satu atau beberapa peringatan, status kesehatan agregatnya adalah peringatan atau kesalahan, tergantung bendera kebijakan ConsiderWarningAsError.
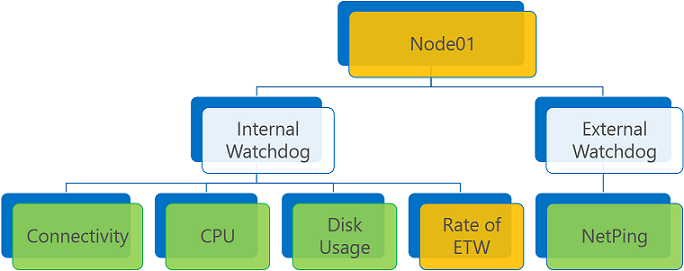
Agregasi laporan kesehatan dengan laporan peringatan dan ConsiderWarningAsError diatur ke false (default).
Agregasi kesehatan anak
Status kesehatan agregat entitas mencerminkan status kesehatan anak (jika berlaku). Algoritme untuk menggabungkan status kesehatan anak menggunakan kebijakan kesehatan yang berlaku berdasarkan jenis entitas.
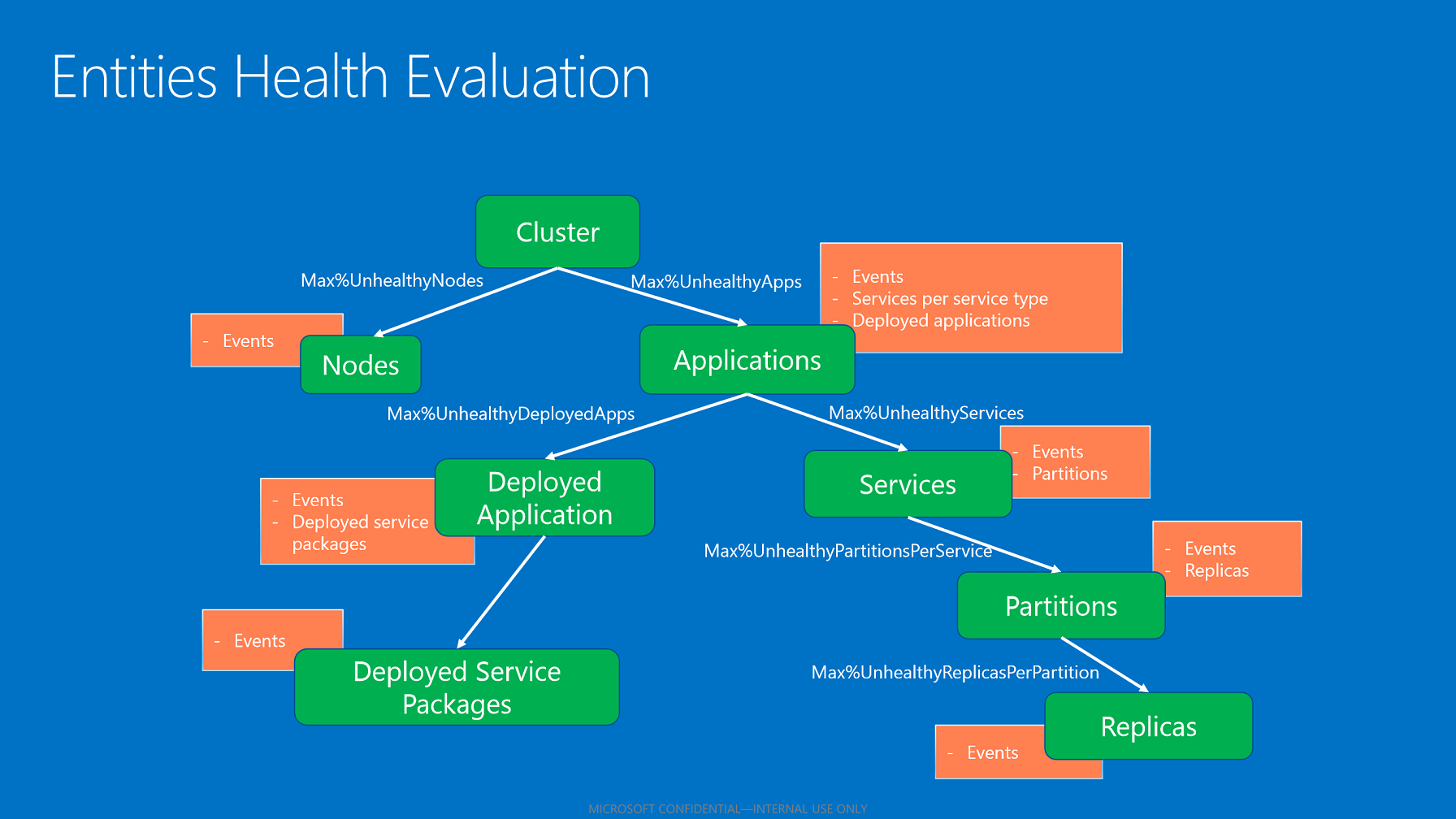
Agregasi anak berdasarkan kebijakan kesehatan.
Setelah penyimpanan kesehatan mengevaluasi semua anak, itu menggabungkan keadaan kesehatan mereka berdasarkan persentase maksimum yang dikonfigurasi dari anak-anak yang tidak sehat. Persentase ini diambil dari kebijakan berdasarkan entitas dan jenis anak.
- Jika semua anak memiliki status OK, status kesehatan agregat anak adalah OK.
- Jika anak-anak memiliki status OK dan peringatan, maka status kesehatan agregat anak adalah peringatan.
- Jika ada anak-anak dengan kesalahan menyatakan bahwa tidak menghormati persentase maksimum yang diizinkan dari anak-anak yang tidak sehat, status kesehatan induk yang dikumpulkan adalah kesalahan.
- Jika anak-anak dengan kesalahan sesuai dengan persentase maksimum yang diizinkan dari anak-anak yang tidak sehat, berarti status kesehatan induk yang dikumpulkan adalah peringatan.
Pelaporan kesehatan
Komponen sistem, aplikasi System Fabric, dan pengawas internal/eksternal dapat melaporkan terhadap entitas Service Fabric. Pelapor membuat penetapan lokal kesehatan entitas yang dipantau, berdasarkan kondisi yang mereka pantau. Pelapor tidak perlu melihat status global atau data agregatnya. Perilaku yang diinginkan adalah memiliki pelapor sederhana, dan bukan organisme kompleks yang perlu melihat banyak hal untuk menyimpulkan informasi apa yang harus dikirim.
Untuk mengirim data kesehatan ke penyimpanan kesehatan, pelapor perlu mengidentifikasi entitas yang terkena dampak dan membuat laporan kesehatan. Untuk mengirim laporan, gunakan FabricClient.HealthClient.ReportHealth API, laporkan API kesehatan yang terekspos di Partition atau objek CodePackageActivationContext, cmdlet PowerShell, atau REST.
Laporan kesehatan
Laporan kesehatan untuk tiap-tiap entitas dalam kluster berisi informasi berikut:
SourceId. Suatu string yang secara unik mengidentifikasi pelapor peristiwa kesehatan.
Pengenal entitas. Mengidentifikasi entitas tempat laporan diterapkan. Ini berbeda berdasarkan jenis entitas:
- Kluster. Tidak ada.
- Node. Nama node (string).
- Aplikasi. Nama aplikasi (URI). Merepresentasikan nama instans aplikasi yang diterapkan dalam kluster.
- Layanan. Nama layanan (URI). Merepresentasikan nama instans layanan yang diterapkan dalam kluster.
- Partisi. ID Partisi (GUID). Merepresentasikan pengidentifikasi unik partisi.
- Replika. ID replika layanan stateful atau ID instans layanan stateless (INT64).
- DeployedApplication. Nama aplikasi (URI) dan nama node (string).
- DeployedServicePackage. Nama aplikasi (URI), nama node (string), dan nama manifes layanan (string).
Properti. Suatu string (bukan pencacahan tetap) yang memungkinkan pelapor untuk mengkategorikan peristiwa kesehatan untuk properti tertentu dari sebuah entitas. Misalnya, pelapor A dapat melaporkan kesehatan properti "Penyimpanan" Node01 dan reporter B dapat melaporkan kesehatan properti "Konektivitas" Node01. Di penyimpanan kesehatan, laporan ini diperlakukan sebagai peristiwa kesehatan terpisah untuk entitas Node01.
Deskripsi. String yang memungkinkan pelapor untuk memberikan informasi terperinci tentang peristiwa kesehatan. SourceId, Property, dan HealthState harus sepenuhnya menjelaskan laporan. Deskripsi menambahkan informasi yang dapat dibaca manusia tentang laporan tersebut. Teks memudahkan administrator dan pengguna untuk memahami laporan kesehatan.
HealthState. Sebuah enumerasi yang menggambarkan keadaan kesehatan laporan. Nilai yang diterima adalah OK, Peringatan, dan Kesalahan.
TimeToLive. Jangka waktu yang menunjukkan berapa lama laporan kesehatan tersebut valid. Ditambah dengan RemoveWhenExpired, ini memungkinkan penyimpanan kesehatan tahu cara mengevaluasi peristiwa yang kedaluwarsa. Secara default, nilainya adalah tidak terbatas, dan laporan berlaku selamanya.
RemoveWhenExpired. Sebuah boolean. Jika diatur ke true, laporan kesehatan yang kedaluwarsa akan dihapus secara otomatis dari penyimpanan kesehatan, dan laporan tersebut tidak memengaruhi evaluasi kesehatan entitas. Digunakan saat laporan valid untuk jangka waktu tertentu saja, dan pelapor tidak perlu membersihkannya secara eksplisit. Ini juga digunakan untuk menghapus laporan dari penyimpanan kesehatan (misalnya, pengawas diubah dan berhenti mengirim laporan dengan sumber dan properti sebelumnya). Ini dapat mengirim laporan dengan TimeToLive singkat bersama dengan RemoveWhenExpired untuk membersihkan status sebelumnya dari penyimpanan kesehatan. Jika nilai diatur ke false, laporan yang kedaluwarsa diperlakukan sebagai kesalahan pada evaluasi kesehatan. Nilai false memberi sinyal ke penyimpanan kesehatan yang harus dilaporkan sumber secara berkala pada properti ini. Jika tidak, maka pasti ada yang salah dengan pengawasnya. Kesehatan pengawas diambil dengan mempertimbangkan peristiwa tersebut sebagai kesalahan.
SequenceNumber. Bilangan bulat positif yang perlu terus meningkat, yang mewakili urutan laporan. Ini digunakan oleh penyimpanan kesehatan untuk mendeteksi laporan kedaluwarsa yang diterima terlambat karena keterlambatan jaringan atau masalah lainnya. Laporan ditolak jika nomor urut kurang dari atau sama dengan angka yang terakhir diterapkan untuk entitas, sumber, dan properti yang sama. Jika tidak ditentukan, nomor urut akan dihasilkan secara otomatis. Penting untuk memasukkan nomor urut hanya ketika melaporkan transisi status. Dalam situasi ini, sumber perlu mengingat laporan mana yang dikirim dan menyimpan informasi untuk pemulihan failover.
Keempat informasi ini--SourceId, pengidentifikasi entitas, Properti, dan HealthState--diperlukan untuk setiap laporan kesehatan. String SourceId tidak diizinkan untuk memulai dengan awalan "Sistem.", yang disediakan untuk laporan sistem. Untuk entitas yang sama, hanya ada satu laporan untuk sumber dan properti yang sama. Beberapa laporan untuk sumber dan properti yang sama saling menimpa, baik di sisi klien kesehatan (jika ditumpuk) atau di sisi penyimpanan kesehatan. Penggantiannya didasarkan pada nomor urut; laporan yang lebih baru (dengan nomor urutan yang lebih tinggi) menggantikan laporan yang lebih lama.
Peristiwa kesehatan
Secara internal, penyimpanan kesehatan menyimpan peristiwa kesehatan, yang berisi semua informasi dari laporan, dan metadata tambahan. Metadata mencakup waktu laporan diberikan kepada klien kesehatan dan waktu dimodifikasi di sisi server. Peristiwa kesehatan dikembalikan oleh kueri kesehatan.
Metadata yang ditambahkan terdiri dari:
- SourceUtcTimestamp. Waktu laporan diberikan kepada klien kesehatan (UTC).
- LastModifiedUtcTimestamp. Waktu laporan terakhir dimodifikasi di sisi server (UTC).
- IsExpired. Bendera untuk menunjukkan apakah laporan kedaluwarsa saat kueri dijalankan oleh penyimpanan kesehatan. Peristiwa hanya dapat kedaluwarsa jika RemoveWhenExpired false. Jika tidak, peristiwa tidak dikembalikan oleh kueri dan dihapus dari penyimpanan.
- LastOkTransitionAt, LastWarningTransitionAt, LastErrorTransitionAt. Terakhir kali untuk transisi OK/peringatan/kesalahan. Bidang-bidang ini menginformasikan riwayat transisi status kesehatan untuk peristiwa tersebut.
Bidang-bidang transisi status dapat digunakan untuk pemberitahuan yang lebih cerdas atau informasi peristiwa kesehatan "historis". Bidang-bidang tersebut memungkinkan skenario seperti:
- Pemberitahuan ketika properti telah berada dalam status peringatan/kesalahan selama lebih dari X menit. Memeriksa kondisi selama jangka waktu tertentu akan menghindari pemberitahuan pada kondisi sementara. Misalnya, peringatan jika status kesehatan telah memperingatkan selama lebih dari lima menit dapat diterjemahkan ke dalam (HealthState == Peringatan dan Sekarang - LastWarningTransitionTime > 5 menit).
- Hanya waspada terhadap kondisi yang telah berubah dalam X menit terakhir. Jika suatu laporan sudah berada pada status kesalahan sebelum waktu yang ditentukan, laporan dapat diabaikan karena sudah diisyaratkan sebelumnya.
- Jika properti beralih antara peringatan dan kesalahan, tentukan berapa lama properti berada dalam status tidak sehat (artinya, tidak OK). Misalnya, peringatan jika properti belum sehat selama lebih dari lima menit dapat diterjemahkan ke dalam (HealthState != Ok dan Sekarang - LastOkTransitionTime > 5 menit).
Contoh: Melaporkan dan mengevaluasi kesehatan aplikasi
Contoh berikut mengirimkan laporan kesehatan melalui PowerShell pada aplikasi fabric:/WordCount dari sumber MyWatchdog. Laporan kesehatan berisi informasi tentang "ketersediaan" properti kesehatan dalam keadaan kesehatan kesalahan, dengan TimeToLive yang tak terbatas. Kemudian mengkueri kesehatan aplikasi, yang mengembalikan kesalahan status kesehatan agregat dan peristiwa kesehatan yang dilaporkan dalam daftar peristiwa kesehatan.
PS C:\> Send-ServiceFabricApplicationHealthReport –ApplicationName fabric:/WordCount –SourceId "MyWatchdog" –HealthProperty "Availability" –HealthState Error
PS C:\> Get-ServiceFabricApplicationHealth fabric:/WordCount -ExcludeHealthStatistics
ApplicationName : fabric:/WordCount
AggregatedHealthState : Error
UnhealthyEvaluations :
Error event: SourceId='MyWatchdog', Property='Availability'.
ServiceHealthStates :
ServiceName : fabric:/WordCount/WordCountService
AggregatedHealthState : Error
ServiceName : fabric:/WordCount/WordCountWebService
AggregatedHealthState : Ok
DeployedApplicationHealthStates :
ApplicationName : fabric:/WordCount
NodeName : _Node_0
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_2
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_3
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_4
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_1
AggregatedHealthState : Ok
HealthEvents :
SourceId : System.CM
Property : State
HealthState : Ok
SequenceNumber : 360
SentAt : 3/22/2016 7:56:53 PM
ReceivedAt : 3/22/2016 7:56:53 PM
TTL : Infinite
Description : Application has been created.
RemoveWhenExpired : False
IsExpired : False
Transitions : Error->Ok = 3/22/2016 7:56:53 PM, LastWarning = 1/1/0001 12:00:00 AM
SourceId : MyWatchdog
Property : Availability
HealthState : Error
SequenceNumber : 131032204762818013
SentAt : 3/23/2016 3:27:56 PM
ReceivedAt : 3/23/2016 3:27:56 PM
TTL : Infinite
Description :
RemoveWhenExpired : False
IsExpired : False
Transitions : Ok->Error = 3/23/2016 3:27:56 PM, LastWarning = 1/1/0001 12:00:00 AM
Penggunaan model kesehatan
Model kesehatan memungkinkan layanan cloud dan platform Service Fabric yang mendasarinya untuk diskalakan, karena pemantauan dan penentuan kesehatan didistribusikan di antara berbagai monitor dalam kluster. Sistem lain memiliki layanan terpusat tunggal di tingkat kluster yang memilah semua informasi yang berpotensi berguna yang dikeluarkan oleh layanan. Pendekatan ini menghambat skalabilitasnya. Ini juga tidak memungkinkan mereka mengumpulkan informasi tertentu untuk membantu mengidentifikasi masalah dan potensi masalah sedekat mungkin dengan akar penyebabnya.
Model kesehatan digunakan dititikberatkan terutama untuk pemantauan dan diagnosis, untuk mengevaluasi kesehatan kluster dan aplikasi, dan untuk peningkatan terpantau. Layanan lain menggunakan data kesehatan untuk melakukan perbaikan otomatis, membuat riwayat kesehatan kluster, dan mengeluarkan peringatan pada kondisi tertentu.
Langkah berikutnya
Melihat laporan kesehatan Service Fabric
Menggunakan laporan kesehatan sistem untuk memecahkan masalah
Cara melaporkan dan memeriksa kesehatan layanan
Menambahkan laporan kesehatan Service Fabric khusus