Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tutorial ini menunjukkan kepada Anda cara mengumpulkan statistik tentang kontainer Anda dengan menggunakan inventori Azure Blob Storage bersama dengan Azure Databricks.
Dalam tutorial ini, Anda akan mempelajari cara:
- Membuat laporan inventaris
- Membuat ruang kerja dan buku catatan Azure Databricks
- Membaca file inventori blob
- Dapatkan jumlah dan ukuran total blob, cuplikan, dan versi
- Mendapatkan jumlah blob berdasarkan jenis blob dan jenis konten
Prasyarat
Langganan Azure - buat akun secara gratis
Akun penyimpanan Azure - membuat akun penyimpanan
Pastikan identitas pengguna Anda mengemban peran Kontributor Data Blob Penyimpanan.
Membuat laporan inventaris
Aktifkan laporan inventori blob untuk akun penyimpanan Anda. Lihat Mengaktifkan laporan inventori blob Azure Storage.
Gunakan pengaturan konfigurasi berikut:
| Pengaturan | Nilai |
|---|---|
| Nama aturan | blobinventory |
| Kontainer | <nama kontainer Anda> |
| Jenis objek untuk inventarisasi | Blob |
| Jenis blob | Blob blok, blob Halaman, dan blob Tambahkan |
| Subjenis | sertakan versi blob, sertakan rekam jepret, sertakan blob yang dihapus |
| Bidang inventori Blob | Semua |
| Frekuensi inventaris | Harian |
| Format ekspor | CSV |
Anda mungkin harus menunggu hingga 24 jam setelah mengaktifkan laporan inventori agar laporan pertama Anda dibuat.
Mengonfigurasi Azure Databricks
Di bagian ini, Anda membuat ruang kerja dan buku catatan Azure Databricks. Kemudian dalam tutorial ini, Anda menempelkan cuplikan kode ke dalam sel notebook, lalu menjalankannya untuk mengumpulkan statistik kontainer.
Membuat ruang kerja Azure Databricks. Lihat Membuat ruang kerja Azure Databricks.
Buat notebook baru. Lihat Membuat buku catatan.
Pilih Python sebagai bahasa default buku catatan.
Membaca file inventori blob
Salin dan tempel blok kode berikut ke dalam sel pertama, tetapi jangan menjalankan kode ini dulu.
from pyspark.sql.types import StructType, StructField, IntegerType, StringType import pyspark.sql.functions as F storage_account_name = "<storage-account-name>" storage_account_key = "<storage-account-key>" container = "<container-name>" blob_inventory_file = "<blob-inventory-file-name>" hierarchial_namespace_enabled = False if hierarchial_namespace_enabled == False: spark.conf.set("fs.azure.account.key.{0}.blob.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("wasbs://{0}@{1}.blob.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true') else: spark.conf.set("fs.azure.account.key.{0}.dfs.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("abfss://{0}@{1}.dfs.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true')Dalam blok kode ini, ganti nilai berikut:
Ganti nilai placeholder
<storage-account-name>dengan nama akun penyimpanan.Ganti nilai
<storage-account-key>dengan kunci akun dari akun penyimpanan Anda.Ganti nilai placeholder dengan kontainer yang menyimpan laporan persediaan.
Ganti
<blob-inventory-file-name>penampung dengan nama file inventori yang lengkap dan memenuhi syarat (misalnya:2023/02/02/02-16-17/blobinventory/blobinventory_1000000_0.csv).Jika akun Anda memiliki namespace hierarkis, atur variabel ke
hierarchical_namespace_enabledTrue.
Tekan tombol Jalankan untuk menjalankan kode dalam sel ini.
Mendapatkan jumlah dan ukuran blob
Di sel baru, tempelkan kode berikut:
print("Number of blobs in the container:", df.count()) print("Number of bytes occupied by blobs in the container:", df.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Tekan tombol jalankan untuk menjalankan sel.
Notebook menampilkan jumlah blob dalam kontainer dan jumlah byte yang ditempati oleh blob dalam kontainer.

Dapatkan jumlah dan ukuran cuplikan
Di sel baru, tempelkan kode berikut:
from pyspark.sql.functions import * print("Number of snapshots in the container:", df.where(~(col("Snapshot")).like("Null")).count()) dfT = df.where(~(col("Snapshot")).like("Null")) print("Number of bytes occupied by snapshots in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Tekan tombol jalankan untuk menjalankan sel.
Notebook menampilkan jumlah rekam jepret dan jumlah total byte yang ditempati oleh rekam jepret blob.

Dapatkan jumlah dan ukuran versi
Di sel baru, tempelkan kode berikut:
from pyspark.sql.functions import * print("Number of versions in the container:", df.where(~(col("VersionId")).like("Null")).count()) dfT = df.where(~(col("VersionId")).like("Null")) print("Number of bytes occupied by versions in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Tekan SHIFT + ENTER untuk menjalankan sel.
Notebook ini menampilkan jumlah versi blob dan jumlah total byte yang digunakan oleh versi blob.

Dapatkan jumlah blob menurut jenis blob
Di sel baru, tempelkan kode berikut:
display(df.groupBy('BlobType').count().withColumnRenamed("count", "Total number of blobs in the container by BlobType"))Tekan SHIFT + ENTER untuk menjalankan sel.
Buku catatan menampilkan jumlah tipe blob menurut jenis.

Mendapatkan jumlah blob menurut jenis konten
Di sel baru, tempelkan kode berikut:
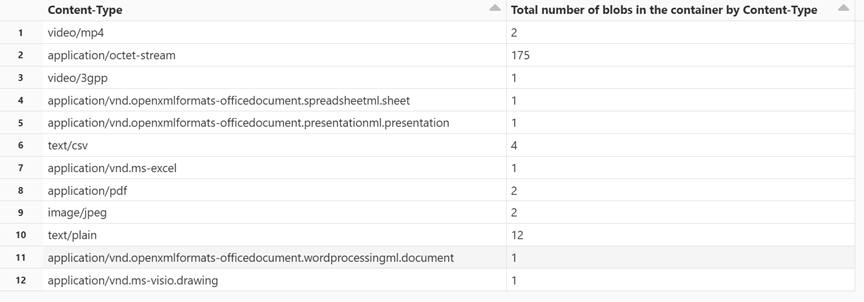
display(df.groupBy('Content-Type').count().withColumnRenamed("count", "Total number of blobs in the container by Content-Type"))Tekan SHIFT + ENTER untuk menjalankan sel.
Buku catatan menampilkan jumlah blob yang terkait dengan setiap tipe konten.
Menghentikan kluster
Untuk menghindari penagihan yang tidak perlu, hentikan sumber daya komputasi Anda. Lihat mengakhiri komputasi.
Langkah berikutnya
Pelajari cara menggunakan Azure Synapse untuk menghitung jumlah blob dan ukuran total blob per kontainer. Lihat Menghitung jumlah blob dan ukuran total per kontainer menggunakan inventori Azure Storage
Pelajari cara menghasilkan dan memvisualisasikan statistik yang menjelaskan kontainer dan blob. Lihat Tutorial: Menganalisis laporan inventori blob
Pelajari tentang cara mengoptimalkan biaya Anda berdasarkan analisis blob dan kontainer Anda. Lihat artikel ini:
Merencanakan dan mengelola biaya untuk Azure Blob Storage
Memperkirakan biaya pengarsipan data
Mengoptimalkan biaya dengan mengelola siklus hidup data secara otomatis