Cara kerja failover terencana yang dikelola pelanggan (pratinjau)
Failover terencana yang dikelola pelanggan dapat berguna dalam skenario seperti perencanaan dan pengujian bencana dan pemulihan, remediasi proaktif dari bencana skala besar yang diantisipasi, dan pemadaman terkait nonstorase.
Selama proses failover yang direncanakan, wilayah utama dan sekunder akun penyimpanan Anda ditukar. Wilayah utama asli diturunkan dan menjadi sekunder baru sementara wilayah sekunder asli dipromosikan dan menjadi primer baru. Akun penyimpanan harus tersedia di wilayah utama dan sekunder sebelum failover yang direncanakan dapat dimulai.
Artikel ini menjelaskan apa yang terjadi selama failover dan failback terencana yang dikelola pelanggan di setiap tahap proses. Untuk memahami cara kerja failover karena pemadaman titik akhir penyimpanan yang tidak terduga, lihat Cara kerja failover yang dikelola pelanggan (tidak direncanakan).
Penting
Failover terencana yang dikelola pelanggan saat ini dalam PRATINJAU dan terbatas pada wilayah berikut:
- Prancis Tengah
- Prancis Selatan
- India Tengah
- India Barat
- Asia Timur
- Asia Tenggara
Lihat Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure untuk persyaratan hukum yang berlaku pada fitur Azure dalam versi beta, pratinjau, atau belum dirilis secara umum.
Untuk ikut serta dalam pratinjau, lihat Menyiapkan fitur pratinjau di langganan Azure dan menentukan AllowSoftFailover sebagai nama fitur. Nama penyedia untuk fitur pratinjau ini adalah Microsoft.Storage.
Penting
Setelah failover yang direncanakan, nilai Waktu Sinkronisasi Terakhir (LST) akun penyimpanan mungkin tampak kedaluwarsa atau dilaporkan sebagai NULL saat data Azure Files ada.
Rekam jepret sistem dibuat secara berkala di wilayah sekunder akun penyimpanan untuk mempertahankan titik pemulihan yang konsisten yang digunakan selama failover dan failback. Memulai failover terencana yang dikelola pelanggan menyebabkan wilayah utama asli menjadi sekunder baru. Dalam beberapa kasus, tidak ada rekam jepret sistem yang tersedia pada sekunder baru setelah failover yang direncanakan selesai, menyebabkan nilai LST keseluruhan akun tampak basi atau ditampilkan sebagai Null.
Karena aktivitas pengguna seperti membuat, memodifikasi, atau menghapus objek dapat memicu pembuatan rekam jepret, akun apa pun tempat aktivitas ini terjadi setelah failover yang direncanakan tidak akan memerlukan perhatian tambahan. Namun, akun yang tidak memiliki rekam jepret atau aktivitas pengguna dapat terus menampilkan Null nilai LST hingga pembuatan rekam jepret sistem dipicu.
Jika perlu, lakukan salah satu aktivitas berikut untuk setiap berbagi dalam akun penyimpanan untuk memicu pembuatan rekam jepret. Setelah selesai, akun Anda harus menampilkan nilai LST yang valid dalam waktu 30 menit.
- Pasang berbagi, lalu buka file apa pun untuk dibaca.
- Unggah file pengujian atau sampel ke berbagi.
Manajemen redundansi selama failover dan failback yang direncanakan
Tip
Untuk memahami berbagai status redundansi selama proses failover dan failback yang dikelola pelanggan secara rinci, lihat Redundansi Azure Storage untuk definisi masing-masing.
Selama proses failover yang direncanakan, titik akhir layanan penyimpanan wilayah utama menjadi baca-saja sementara pembaruan yang tersisa selesai mereplikasi ke wilayah sekunder. Selanjutnya, semua entri layanan nama domain (DNS) titik akhir layanan penyimpanan dialihkan. Titik akhir sekunder akun penyimpanan Anda menjadi titik akhir utama baru, dan titik akhir utama asli menjadi sekunder baru. Replikasi data dalam setiap wilayah tetap tidak berubah meskipun wilayah utama dan sekunder dialihkan.
Proses failback yang direncanakan pada dasarnya sama dengan proses failover yang direncanakan, tetapi dengan satu pengecualian. Selama failback yang direncanakan, Azure menyimpan konfigurasi redundansi asli akun penyimpanan Anda dan memulihkannya ke status aslinya setelah failback. Misalnya, jika akun penyimpanan Anda awalnya dikonfigurasi sebagai GZRS, akun penyimpanan akan menjadi GZRS setelah failback.
Catatan
Tidak seperti failover yang dikelola pelanggan (tidak direncanakan), selama failover yang direncanakan, replikasi dari wilayah utama ke sekunder harus selesai sebelum entri DNS untuk titik akhir diubah ke sekunder baru. Karena itu, kehilangan data tidak diharapkan selama failover atau failback yang direncanakan selama wilayah utama dan sekunder tersedia sepanjang proses.
Cara memulai failover
Untuk mempelajari cara memulai failover, lihat Memulai failover akun.
Proses failover dan failback yang direncanakan
Diagram berikut menunjukkan apa yang terjadi selama failover terencana yang dikelola pelanggan dan failback akun penyimpanan.
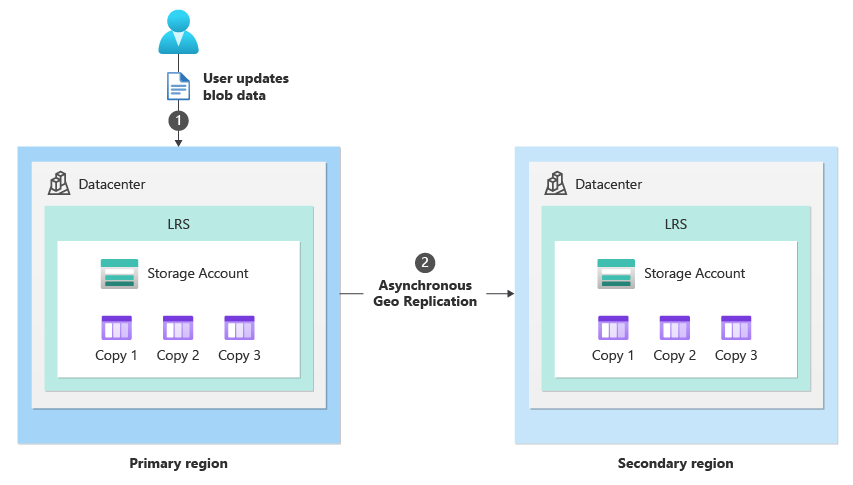
Dalam keadaan normal, klien menulis data ke akun penyimpanan di wilayah utama melalui titik akhir layanan penyimpanan (1). Data kemudian disalin secara asinkron dari wilayah utama ke wilayah sekunder (2). Gambar berikut menunjukkan status normal akun penyimpanan yang dikonfigurasi sebagai GRS:

Proses failover yang direncanakan (GRS/RA-GRS)
Mulai pengujian pemulihan bencana dengan memulai failover akun penyimpanan Anda ke wilayah sekunder. Langkah-langkah berikut menjelaskan proses failover, dan gambar berikutnya memberikan ilustrasi:
- Wilayah utama asli menjadi baca saja.
- Replikasi semua data dari wilayah utama ke wilayah sekunder selesai.
- Entri DNS untuk titik akhir layanan penyimpanan di wilayah sekunder dipromosikan dan menjadi titik akhir utama baru untuk akun penyimpanan Anda.
Kegagalan biasanya berlangsung sekitar satu jam.

Setelah failover selesai, wilayah utama asli menjadi sekunder baru (1), dan wilayah sekunder asli menjadi primer baru (2). URI untuk titik akhir layanan penyimpanan untuk blob, tabel, antrean, dan file tetap sama, tetapi entri DNS mereka diubah untuk menunjuk ke wilayah utama baru (3). Pengguna dapat melanjutkan penulisan data ke akun penyimpanan di wilayah utama baru, dan data kemudian disalin secara asinkron ke sekunder baru (4) seperti yang ditunjukkan pada gambar berikut:

Saat dalam status failover, lakukan pengujian pemulihan bencana Anda.
Proses failback yang direncanakan (GRS/RA-GRS)
Setelah pengujian selesai, lakukan failover lain untuk failback ke wilayah utama asli. Selama proses failover, seperti yang ditunjukkan pada gambar berikut:
- Wilayah utama asli menjadi baca saja.
- Semua data selesai mereplikasi dari wilayah utama saat ini ke wilayah sekunder saat ini.
- Entri DNS untuk titik akhir layanan penyimpanan diubah untuk mengarahkan kembali ke wilayah yang merupakan primer sebelum failover awal dilakukan.
Failback biasanya memakan waktu sekitar satu jam.

Setelah failback selesai, akun penyimpanan dipulihkan ke konfigurasi redundansi aslinya. Pengguna dapat melanjutkan penulisan data ke akun penyimpanan di wilayah utama asli (1) sementara replikasi ke sekunder asli (2) berlanjut seperti sebelum failover: