Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Azure Stream Analytics mendukung partisi output blob kustom dengan bidang atau atribut kustom dan pola jalur kustom DateTime .
Bidang isian atau atribut kustom
Bidang isian atau atribut isian kustom meningkatkan alur kerja pemrosesan dan pelaporan data downstream dengan memungkinkan kontrol lebih besar atas output.
Opsi kunci partisi
Kunci partisi, atau nama kolom, yang digunakan untuk mempartisi data input mungkin berisi karakter apa pun yang diterima untuk nama blob. Tidak dimungkinkan untuk menggunakan bidang berlapis sebagai kunci partisi kecuali digunakan bersama dengan alias. Namun, Anda dapat menggunakan karakter tertentu untuk membuat hierarki file. Misalnya, untuk membuat kolom yang menggabungkan data dari dua kolom lain untuk membuat kunci partisi unik, Anda bisa menggunakan kueri berikut:
SELECT name, id, CONCAT(name, "/", id) AS nameid
Kunci partisi harus NVARCHAR(MAX), , BIGINTFLOAT, atau BIT (tingkat kompatibilitas 1.2 atau lebih tinggi). Jenis DateTime, Array, dan Records tidak didukung, tetapi dapat digunakan sebagai kunci partisi jika dikonversi ke string. Untuk informasi selengkapnya, lihat Jenis data Azure Stream Analytics.
Contoh
Misalkan pekerjaan mengambil data input dari sesi pengguna langsung yang terhubung ke layanan video game eksternal di mana data yang diserap berisi kolom client_id untuk mengidentifikasi sesi. Untuk mempartisi data menurut client_id, atur bidang pola Jalur blob untuk menyertakan token {client_id} partisi dalam properti output blob saat Anda membuat pekerjaan. Sebagai data dengan berbagai client_id nilai mengalir melalui pekerjaan Azure Stream Analytics, data output disimpan ke dalam folder terpisah berdasarkan satu client_id nilai per folder.

Demikian pula, jika input pekerjaan adalah data sensor dari jutaan sensor di mana setiap sensor memiliki sensor_id, pola jalurnya adalah {sensor_id} mempartisi setiap data sensor ke folder yang berbeda.
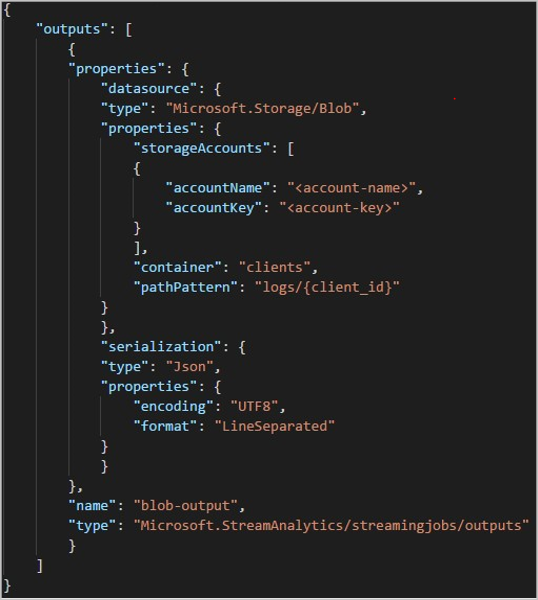
Saat Anda menggunakan REST API, bagian output dari file JSON yang digunakan untuk permintaan tersebut mungkin terlihat seperti gambar berikut:
Setelah pekerjaan mulai berjalan, clients kontainer mungkin terlihat seperti gambar berikut:
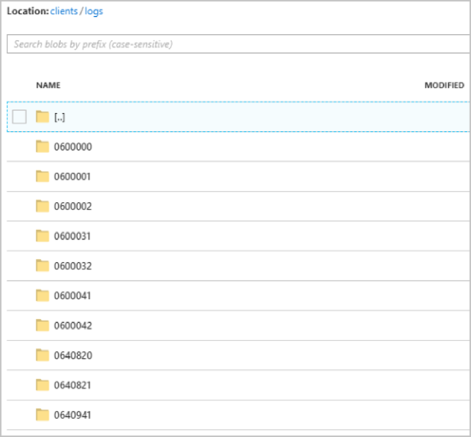
Setiap folder mungkin berisi beberapa blob di mana setiap blob berisi satu atau beberapa rekaman. Dalam contoh sebelumnya, ada satu blob dalam folder berlabel "06000000" konten berikut:
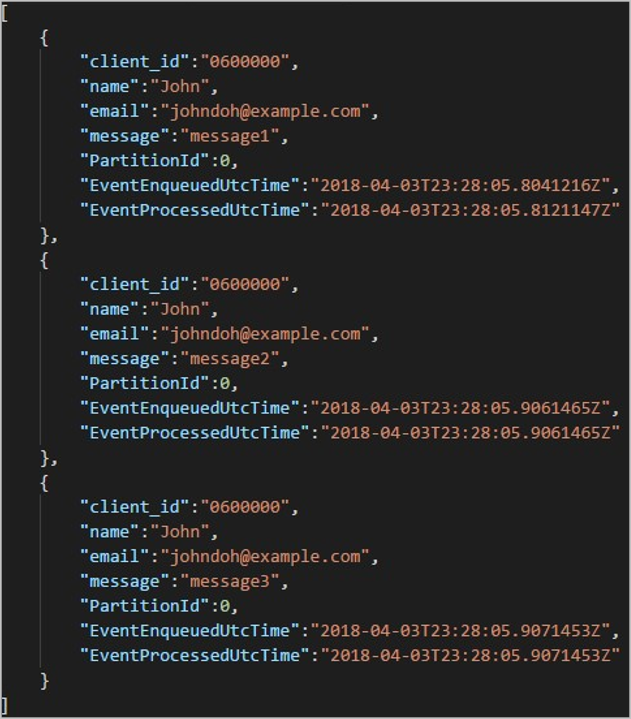
Perhatikan bahwa setiap rekaman dalam blob memiliki kolom yang client_id cocok dengan nama folder karena kolom yang digunakan untuk mempartisi output di jalur output adalah client_id.
Batasan
Hanya satu kunci partisi kustom yang diizinkan dalam properti output blob pola jalur. Semua pola jalur berikut valid:
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
Jika pelanggan ingin menggunakan lebih dari satu bidang input, mereka dapat membuat kunci komposit dalam kueri untuk partisi jalur kustom dalam output blob dengan menggunakan
CONCAT. Contohnyaselect concat (col1, col2) as compositeColumn into blobOutput from input. Kemudian mereka dapat menentukancompositeColumnsebagai jalur kustom di Azure Blob Storage.Kunci partisi tidak peka huruf besar/kecil, sehingga kunci partisi seperti
Johndanjohnsetara. Selain itu, ekspresi tidak dapat digunakan sebagai kunci partisi. Misalnya,{columnA + columnB}tidak berfungsi.Ketika aliran input terdiri dari rekaman dengan kardinalitas kunci partisi di bawah 8.000, rekaman ditambahkan ke blob yang ada. Mereka hanya membuat blob baru jika diperlukan. Jika kardinalitas lebih dari 8.000, tidak ada jaminan blob yang ada akan ditulis. Blob baru tidak akan dibuat untuk jumlah rekaman arbitrer dengan kunci partisi yang sama.
Jika output blob dikonfigurasi sebagai tidak dapat diubah, Azure Stream Analytics membuat blob baru setiap kali data dikirim.
Pola jalur DateTime kustom
Pola jalur kustom DateTime memungkinkan Anda menentukan format output yang selaras dengan konvensi Hive Streaming, memberi Azure Stream Analytics kemampuan untuk mengirim data ke Azure HDInsight dan Azure Databricks untuk pemrosesan hilir. Pola jalur kustom DateTime mudah diimplementasikan dengan menggunakan datetime kata kunci di bidang Awalan Jalur output blob Anda, bersama dengan penentu format. Contohnya {datetime:yyyy}.
Token yang didukung
Token penentu format berikut dapat digunakan sendiri atau dalam kombinasi untuk mencapai format kustom DateTime .
| Penentu format | Deskripsi | Hasil pada waktu contoh 2018-01-02T10:06:08 |
|---|---|---|
| {datetime:yyyy} | Tahun sebagai angka empat digit | 2018 |
| {datetime:MM} | Bulan dari 01 hingga 12 | 01 |
| {datetime:M} | Bulan dari 1 hingga 12 | 1 |
| {datetime:dd} | Hari dari 01 hingga 31 | 02 |
| {datetime:d} | Hari dari 1 hingga 31 | 2 |
| {datetime:HH} | Jam menggunakan format 24 jam, dari 00 hingga 23 | 10 |
| {datetime:mm} | Menit dari 00 hingga 60 | 06 |
| {datetime:m} | Menit dari 0 hingga 60 | 6 |
| {datetime:ss} | Detik dari 00 hingga 60 | 08 |
Jika Anda tidak ingin menggunakan pola kustom DateTime , Anda dapat menambahkan {date} dan/atau {time} token ke bidang Awalan Jalur untuk menghasilkan dropdown dengan format bawaan DateTime .
Ekstensibilitas dan pembatasan
Anda dapat menggunakan token sebanyak yang{datetime:<specifier>} Anda suka dalam pola jalur sampai Anda mencapai batas karakter awalan jalur. Penentu format tidak dapat dikombinasikan dalam satu token di luar kombinasi yang sudah dicantumkan oleh drop-down tanggal dan waktu.
Untuk partisi jalur logs/MM/dd:
| Ekspresi yang valid | Ekspresi yang tidak valid |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
Anda mungkin menggunakan penentu format yang sama beberapa kali dalam awalan jalur. Token harus diulang setiap kali.
Konvensi Apache Hive Streaming
Pola jalur kustom untuk Blob Storage dapat digunakan dengan konvensi Hive Streaming, yang mengharapkan folder diberi label dalam column= nama folder.
Contohnya year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}.
Output kustom menghilangkan kerumitan mengubah tabel dan menambahkan partisi secara manual ke data port antara Stream Analytics dan Apache Hive. Sebagai gantinya, banyak folder dapat ditambahkan secara otomatis dengan menggunakan:
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
Contoh
Buat akun penyimpanan, grup sumber daya, pekerjaan Azure Stream Analytics, dan sumber input sesuai dengan mulai cepat Azure Stream Analytics portal Azure. Gunakan data sampel yang sama yang digunakan dalam mulai cepat. Data sampel juga tersedia di GitHub.
Buat sink output blob dengan konfigurasi berikut:
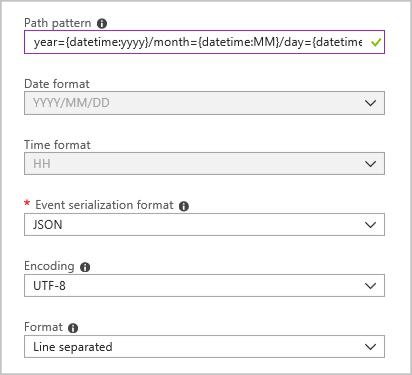
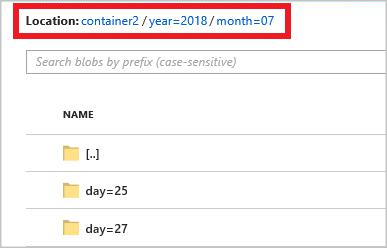
Pola jalur lengkapnya adalah:
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
Ketika Anda memulai pekerjaan, struktur folder berdasarkan pola jalur dibuat dalam kontainer blob Anda. Anda dapat menelusuri paling detail ke tingkat hari.