Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dalam tutorial ini, Anda mempelajari cara menggunakan Text Analytics untuk menganalisis teks yang tidak terstruktur di Azure Synapse Analytics. Text Analytics adalah layanan Azure AI yang memungkinkan Anda melakukan penambangan teks dan analisis teks dengan fitur Natural Language Processing (NLP).
Tutorial ini menunjukkan cara menggunakan analisis teks dengan SynapseML untuk:
- Mendeteksi label sentimen pada tingkat kalimat atau dokumen
- Mengidentifikasi bahasa untuk input teks yang diberikan
- Mengenali entitas dari teks dengan tautan ke basis pengetahuan terkenal
- Mengekstrak frasa kunci dari teks
- Mengidentifikasi entitas yang berbeda dalam teks dan mengategorikannya ke dalam kelas atau jenis yang telah ditentukan sebelumnya
- Mengidentifikasi dan menghapus entitas sensitif dalam teks tertentu
Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai.
Prasyarat
- Ruang kerja Azure Synapse Analytics dengan akun penyimpanan Azure Data Lake Storage Gen2 yang dikonfigurasi sebagai penyimpanan default. Anda harus menjadi Kontributor Data Blob Penyimpanan dari sistem file Data Lake Storage Gen2 yang Anda gunakan.
- Kumpulan spark di ruang kerja Azure Synapse Analytics Anda. Untuk detailnya, lihat Membuat kumpulan Spark di Azure Synapse.
- Langkah-langkah prakonfigurasi yang dijelaskan dalam tutorial Mengonfigurasi layanan Azure AI di Azure Synapse.
Memulai
Buka Synapse Studio dan buat notebook baru. Untuk memulai, impor SynapseML.
import synapse.ml
from synapse.ml.services import *
from pyspark.sql.functions import col
Mengonfigurasi analisis teks
Gunakan analitik teks tertaut yang Anda konfigurasikan dalam langkah-langkah prakonfigurasi.
linked_service_name = "<Your linked service for text analytics>"
Sentimen Teks
Analisis Sentimen Teks menyediakan cara untuk mendeteksi label sentimen (seperti "negatif", "netral", dan "positif") dan skor keyakinan pada tingkat kalimat dan dokumen. Lihat bahasa yang didukung di API Analisis Teks untuk daftar bahasa yang diaktifkan.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("I am so happy today, it's sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The Azure AI services on spark aint bad", "en-US"),
], ["text", "language"])
# Run the Text Analytics service with options
sentiment = (TextSentiment()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
# Show the results of your text query in a table format
results = sentiment.transform(df)
display(results
.withColumn("sentiment", col("sentiment").getItem("document").getItem("sentences")[0].getItem("sentiment"))
.select("text", "sentiment"))
Hasil yang diharapkan
| text | sentimen |
|---|---|
| Aku sangat bahagia hari ini, cerah! | positif |
| Saya frustrasi dengan lalu lintas jam sibuk ini | negatif |
| Layanan Azure AI pada spark aint buruk | netral |
Detektor Bahasa
Detektor Bahasa mengevaluasi input teks untuk setiap dokumen dan mengembalikan pengidentifikasi bahasa dengan skor yang menunjukkan kekuatan analisis. Kemampuan ini berguna untuk penyimpanan konten yang mengumpulkan teks arbitrer, di mana bahasa tidak diketahui. Lihat bahasa yang didukung di API Analisis Teks untuk daftar bahasa yang diaktifkan.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("Hello World",),
("Bonjour tout le monde",),
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
("你好",),
("こんにちは",),
(":) :( :D",)
], ["text",])
# Run the Text Analytics service with options
language = (LanguageDetector()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("language")
.setErrorCol("error"))
# Show the results of your text query in a table format
display(language.transform(df))
Hasil yang diharapkan
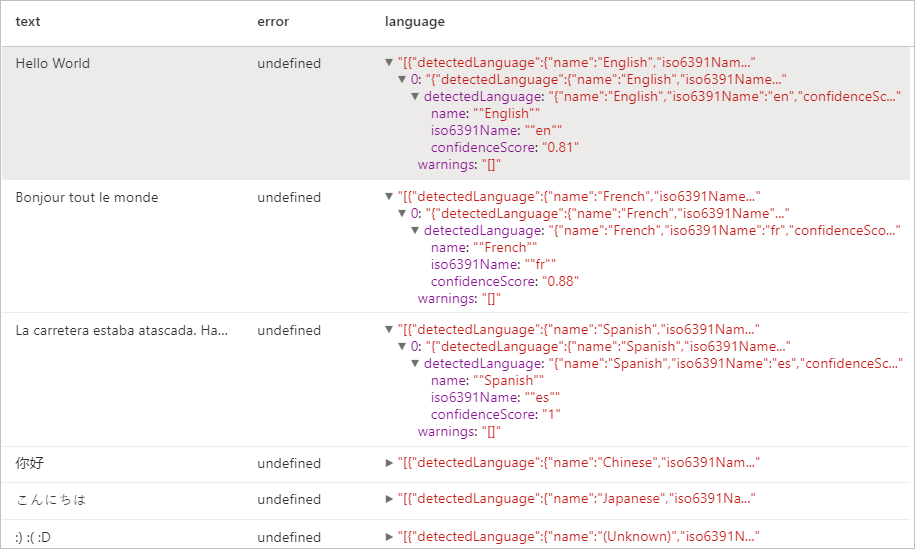
Detektor Entitas
Detektor Entitas mengembalikan daftar entitas yang diakui dengan tautan ke basis pengetahuan terkenal. Lihat bahasa yang didukung di API Analisis Teks untuk daftar bahasa yang diaktifkan.
df = spark.createDataFrame([
("1", "Microsoft released Windows 10"),
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
], ["if", "text"])
entity = (EntityDetector()
.setLinkedService(linked_service_name)
.setLanguage("en")
.setOutputCol("replies")
.setErrorCol("error"))
display(entity.transform(df).select("if", "text", col("replies").getItem("document").getItem("entities").alias("entities")))
Hasil yang diharapkan
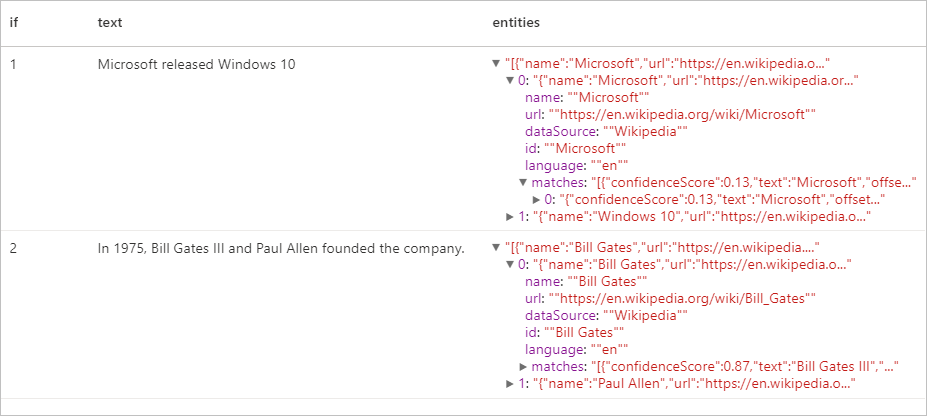
Ekstraktor Frasa Kunci
Ekstraksi Frasa Kunci mengevaluasi teks yang tidak terstruktur dan mengembalikan daftar frasa kunci. Kemampuan ini berguna jika Anda perlu dengan cepat mengidentifikasi poin utama dalam kumpulan dokumen. Lihat bahasa yang didukung di API Analisis Teks untuk daftar bahasa yang diaktifkan.
df = spark.createDataFrame([
("en", "Hello world. This is some input text that I love."),
("fr", "Bonjour tout le monde"),
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
], ["lang", "text"])
keyPhrase = (KeyPhraseExtractor()
.setLinkedService(linked_service_name)
.setLanguageCol("lang")
.setOutputCol("replies")
.setErrorCol("error"))
display(keyPhrase.transform(df).select("text", col("replies").getItem("document").getItem("keyPhrases").alias("keyPhrases")))
Hasil yang diharapkan
| text | keyPhrases |
|---|---|
| Halo dunia. Ini adalah beberapa teks input yang saya sukai. | "["Hello world","input text"]" |
| Bonjour tout le monde | "["Bonjour","monde"]" |
| La carretera estaba atascada. Había mucho tráfico el día de ayer. | "["mucho tráfico","día","carretera","ayer"]" |
Pengenalan Entitas Karakter (NER)
Pengenalan Entitas Karakter (NER) adalah kemampuan untuk mengidentifikasi entitas yang berbeda dalam teks dan mengategorikannya ke dalam kelas atau jenis yang telah ditentukan sebelumnya seperti: orang, lokasi, peristiwa, produk, dan organisasi. Lihat bahasa yang didukung di API Analisis Teks untuk daftar bahasa yang diaktifkan.
df = spark.createDataFrame([
("1", "en", "I had a wonderful trip to Seattle last week."),
("2", "en", "I visited Space Needle 2 times.")
], ["id", "language", "text"])
ner = (NER()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(ner.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Hasil yang diharapkan
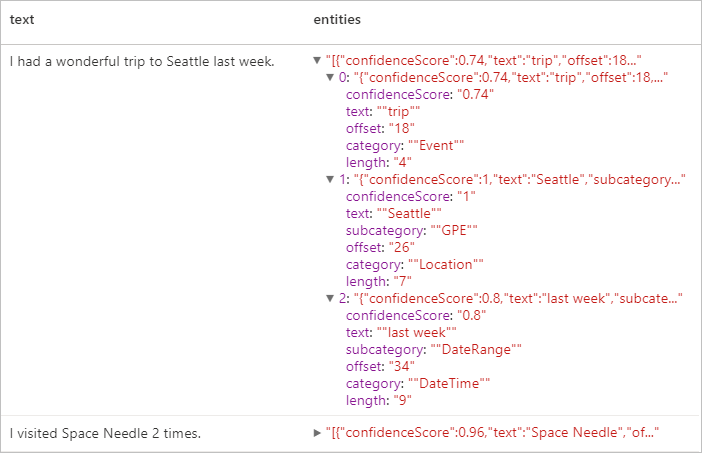
Informasi Pengidentifikasi Pribadi (PII) V3.1
Fitur PII adalah bagian dari NER dan dapat mengidentifikasi dan meredaksi entitas sensitif dalam teks yang terkait dengan orang perorangan seperti: nomor telepon, alamat email, alamat surat, nomor paspor. Lihat bahasa yang didukung di API Analisis Teks untuk daftar bahasa yang diaktifkan.
df = spark.createDataFrame([
("1", "en", "My SSN is 859-98-0987"),
("2", "en", "Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
], ["id", "language", "text"])
pii = (PII()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(pii.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Hasil yang diharapkan
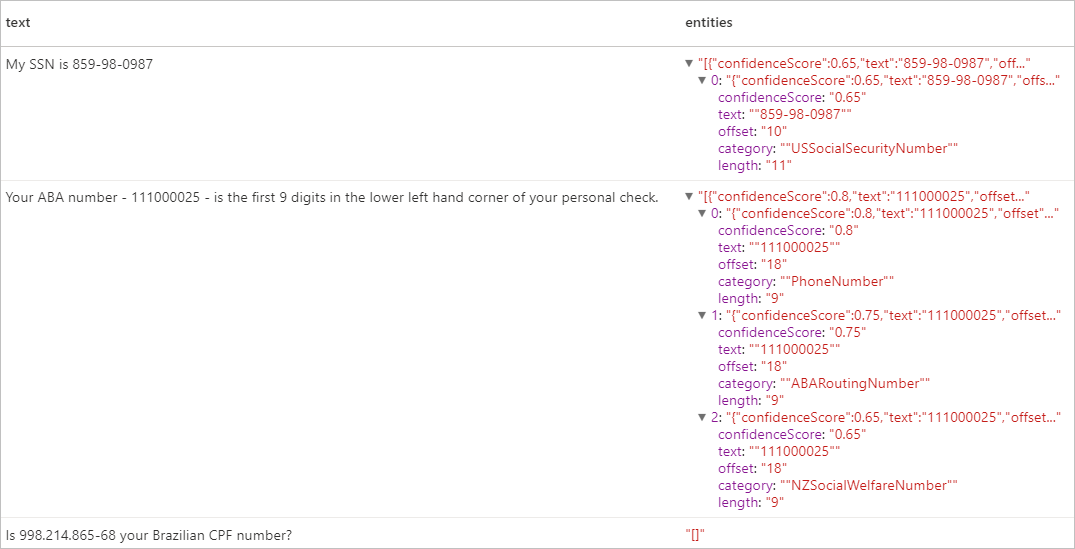
Membersihkan sumber daya
Untuk memastikan instans Spark dimatikan, akhiri semua sesi yang tersambung (notebook). Kumpulan dimatikan ketika waktu siaga yang ditentukan di kumpulan Apache Spark tercapai. Anda juga dapat memilih hentikan sesi dari bilah status di kanan atas buku catatan.
