Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini berisi rekomendasi untuk mendesain tabel terdistribusi hash dan round robin di kumpulan SQL khusus.
Artikel ini mengasumsikan Anda terbiasa dengan konsep distribusi data dan perpindahan data di kumpulan SQL khusus. Untuk informasi selengkapnya, lihat Arsitektur Azure Synapse Analytics.
Apa itu tabel terdistribusi?
Tabel terdistribusi muncul sebagai tabel tunggal, tetapi baris benar-benar disimpan di 60 distribusi. Baris didistribusikan dengan algoritme hash atau round-robin.
Distribusi hash meningkatkan performa kueri pada tabel fakta besar, dan merupakan fokus dari artikel ini. Distribusi round-robin berguna untuk meningkatkan kecepatan pemuatan. Pilihan desain ini memiliki efek signifikan pada peningkatan performa kueri dan pemuatan.
Opsi penyimpanan tabel lainnya adalah mereplikasi tabel kecil di semua simpul Komputasi. Untuk informasi selengkapnya, lihat Panduan desain untuk tabel yang direplikasi. Untuk memilih di antara tiga opsi dengan cepat, lihat Tabel terdistribusi di ringkasan tabel.
Sebagai bagian dari desain tabel, pahami sebanyak mungkin tentang data Anda dan bagaimana data dikueri. Misalnya, pertimbangkan pertanyaan-pertanyaan ini:
- Seberapa besar tabelnya?
- Seberapa sering tabel diperbarui?
- Apakah saya memiliki tabel fakta dan dimensi di kumpulan SQL khusus?
Distribusi Hash
Tabel yang didistribusikan secara hash mendistribusikan baris tabel di seluruh simpul komputasi menggunakan fungsi hash deterministik untuk menetapkan setiap baris ke satu distribusi.
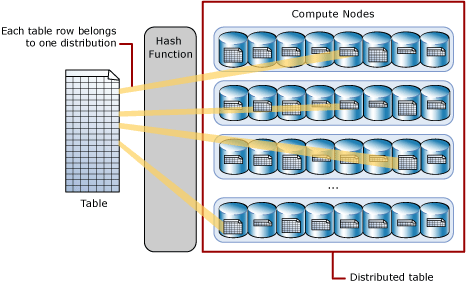
Karena nilai identik selalu di-hash ke distribusi yang sama, SQL Analytics memiliki pengetahuan bawaan tentang lokasi baris. Dalam kumpulan SQL khusus, pengetahuan ini digunakan untuk meminimalkan pergerakan data selama kueri, yang meningkatkan performa kueri.
Tabel terdistribusi hash bekerja dengan baik untuk tabel fakta besar dalam skema bintang. Tabel dapat memiliki sejumlah baris yang sangat besar dan tetap mencapai kinerja tinggi. Ada beberapa pertimbangan desain yang membantu Anda untuk mendapatkan performa sistem terdistribusi dirancang untuk menyediakan. Memilih kolom distribusi yang tepat adalah salah satu pertimbangan yang dijelaskan dalam artikel ini.
Pertimbangkan untuk menggunakan tabel terdistribusi hash saat:
- Ukuran tabel pada disk lebih dari 2 GB.
- Tabel ini sering mengalami operasi penyisipan, pembaruan, dan penghapusan.
Distribusi round-robin
Tabel terdistribusi tipe round-robin mendistribusikan baris tabel secara merata di semua bagian distribusi. Penugasan baris ke distribusi bersifat acak. Tidak seperti tabel terdistribusi hash, baris dengan nilai yang sama tidak dijamin untuk ditempatkan pada distribusi yang sama.
Akibatnya, sistem terkadang perlu menjalankan operasi pemindahan data untuk mengatur data Anda dengan lebih baik sebelum dapat menyelesaikan kueri. Langkah ekstra ini dapat memperlambat kueri Anda. Misalnya, penggabungan tabel round-robin biasanya membutuhkan perombakan baris, yang berdampak pada performa.
Pertimbangkan untuk menggunakan distribusi round-robin untuk tabel Anda dalam skenario berikut:
- Saat memulai, gunakan titik awal yang sederhana karena ini adalah titik masuk default.
- Jika tidak ada kunci bergabung yang jelas
- Jika tidak ada kolom kandidat yang baik untuk mendistribusikan tabel secara hash
- Jika tabel tidak berbagi kunci gabungan umum dengan tabel lain
- Jika gabungan kurang signifikan dibandingkan gabungan lainnya dalam kueri
- Ketika tabel adalah tabel penahapan sementara
Tutorial Memuat data taksi New York memberikan contoh cara memuat data ke dalam tabel tahap round-robin.
Pilih kolom distribusi
Tabel terdistribusi hash memiliki kolom distribusi yang atau kumpulan kolom yang merupakan kunci hash. Misalnya, kode berikut membuat tabel terdistribusi hash dengan ProductKey sebagai kolom distribusi.
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey])
);
Distribusi hash dapat diterapkan pada beberapa kolom untuk distribusi tabel dasar yang lebih merata. Distribusi multi-kolom memungkinkan Anda memilih hingga delapan kolom untuk distribusi. Ini tidak hanya mengurangi penyimpangan data dari waktu ke waktu tetapi juga meningkatkan performa kueri. Contoh:
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey], [OrderDateKey], [CustomerKey] , [PromotionKey])
);
Catatan
Distribusi multi-kolom di Azure Synapse Analytics dapat diaktifkan dengan mengubah tingkat kompatibilitas database menjadi 50 dengan perintah ini.
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; Untuk informasi lebih lanjut tentang mengatur tingkat kompatibilitas database, lihat ALTER DATABASE SCOPED CONFIGURATION. Untuk informasi selengkapnya tentang distribusi multi-kolom, lihat MEMBUAT TAMPILAN TERHIMPUN, MEMBUAT TABEL, atau MEMBUAT TABEL SEBAGAI SELECT.
Data yang disimpan dalam kolom distribusi dapat diperbarui. Pembaruan pada data dalam kolom distribusi dapat mengakibatkan operasi pengacakan data.
Memilih kolom distribusi adalah keputusan desain penting karena nilai dalam kolom hash menentukan bagaimana baris didistribusikan. Pilihan terbaik tergantung pada beberapa faktor, dan biasanya melibatkan pertukaran. Setelah kolom distribusi atau kumpulan kolom dipilih, Anda tidak dapat mengubahnya. Jika Anda tidak memilih kolom terbaik untuk pertama kalinya, Anda dapat menggunakan CREATE TABLE AS SELECT (CTAS) untuk membuat ulang tabel dengan kunci hash distribusi yang diinginkan.
Pilih kolom distribusi dengan data yang terdistribusi secara merata
Untuk performa terbaik, semua distribusi harus memiliki jumlah baris yang kira-kira sama. Ketika satu atau beberapa distribusi memiliki jumlah baris yang tidak proporsional, beberapa distribusi menyelesaikan bagian kueri paralelnya sebelum yang lain. Karena kueri tidak dapat diselesaikan hingga semua distribusi selesai diproses, setiap kueri hanya secepat distribusi yang paling lambat.
- Ketidakseimbangan data mengindikasikan data tidak didistribusikan secara merata di seluruh rentang distribusi.
- Pemrosesan ketidakseimbangan berarti bahwa beberapa distribusi data membutuhkan waktu lebih lama daripada yang lain saat menjalankan kueri secara paralel. Ini bisa terjadi ketika data tidak merata.
Untuk menyeimbangkan pemrosesan paralel, pilih kolom distribusi atau kumpulan kolom yang:
- Memiliki banyak nilai unik. Satu atau beberapa kolom distribusi dapat memiliki nilai duplikat. Semua baris dengan nilai yang sama ditetapkan ke distribusi yang sama. Karena ada 60 distribusi, beberapa distribusi dapat memiliki > 1 nilai unik sementara yang lain dapat berakhir dengan nilai nol.
- Tidak mengandung nilai NULL, atau hanya mengandung sedikit nilai NULL. Untuk contoh ekstrem, jika semua nilai dalam kolom distribusi adalah NULL, semua baris ditetapkan ke distribusi yang sama. Hasilnya, pemrosesan kueri condong ke satu distribusi, dan tidak mendapat manfaat dari pemrosesan paralel.
- Bukan kolom tanggal. Semua data untuk tanggal yang sama terletak dalam distribusi yang sama, atau akan mengkategorikan catatan berdasarkan tanggal. Jika beberapa pengguna semuanya memfilter pada tanggal yang sama (seperti tanggal hari ini), maka hanya 1 dari 60 distribusi yang melakukan semua pekerjaan pemrosesan.
Pilih kolom distribusi yang meminimalkan perpindahan data
Untuk mendapatkan hasil kueri yang benar, kueri mungkin akan memindahkan data dari satu node komputasi ke node lainnya. Perpindahan data biasanya terjadi ketika kueri memiliki gabungan dan agregasi pada tabel terdistribusi. Memilih kolom distribusi atau kumpulan kolom yang membantu meminimalkan perpindahan data adalah salah satu strategi terpenting untuk mengoptimalkan performa kumpulan SQL khusus Anda.
Untuk meminimalkan perpindahan data, pilih kolom distribusi atau kumpulan kolom yang:
- Digunakan dalam klausul
JOIN,GROUP BY,DISTINCT,OVER, danHAVING. Saat dua tabel fakta besar memiliki gabungan yang sering, performa kueri meningkat saat Anda mendistribusikan kedua tabel di salah satu kolom gabungan. Saat tabel tidak digunakan dalam gabungan, pertimbangkan untuk mendistribusikan tabel pada kolom atau kumpulan kolom yang sering berada di klausulGROUP BY. -
tidak digunakan dalam klausul
WHERE. Saat klausul kueriWHEREdan kolom distribusi tabel berada di kolom yang sama, kueri dapat mengalami penyimpangan data tinggi, yang mengarah ke beban pemrosesan yang jatuh hanya pada beberapa distribusi. Ini berdampak pada performa kueri, idealnya banyak distribusi berbagi beban pemrosesan. -
Bukan kolom tanggal. Klausa
WHEREsering disaring berdasarkan tanggal. Ketika ini terjadi, semua pemrosesan hanya dapat berjalan pada beberapa distribusi yang memengaruhi performa kueri. Idealnya, banyak distribusi berbagi beban pemrosesan.
Setelah Anda mendesain tabel terdistribusi hash, langkah selanjutnya adalah memuat data ke dalam tabel. Untuk melihat panduan memuat, lihat Panduan Memuat.
Cara mengetahui apakah distribusi Anda adalah pilihan yang tepat
Setelah data dimuat ke dalam tabel terdistribusi hash, periksa untuk melihat seberapa merata baris terdistribusi di 60 distribusi. Baris per distribusi dapat bervariasi hingga 10% tanpa dampak nyata pada performa.
Pertimbangkan cara berikut untuk mengevaluasi kolom distribusi Anda.
Menentukan apakah tabel memiliki penyimpangan data
Cara cepat untuk memeriksa kecondongan data adalah dengan menggunakan DBCC PDW_SHOWSPACEUSED. Kode SQL berikut mengembalikan jumlah baris tabel yang disimpan di masing-masing dari 60 distribusi. Untuk performa yang seimbang, baris dalam tabel terdistribusi Anda harus tersebar secara merata di semua distribusi.
-- Find data skew for a distributed table
DBCC PDW_SHOWSPACEUSED('dbo.FactInternetSales');
Untuk mengidentifikasi tabel mana yang memiliki penyimpangan data lebih dari 10%:
- Buat tampilan
dbo.vTableSizesyang ditampilkan dalam artikel Ringkasan tabel. - Jalankan kueri berikut:
select *
from dbo.vTableSizes
where two_part_name in
(
select two_part_name
from dbo.vTableSizes
where row_count > 0
group by two_part_name
having (max(row_count * 1.000) - min(row_count * 1.000))/max(row_count * 1.000) >= .10
)
order by two_part_name, row_count;
Periksa rencana kueri untuk perpindahan data
Kumpulan kolom distribusi yang baik memungkinkan gabungan dan agregasi dengan perpindahan data yang minimal. Ini memengaruhi cara penulisan penggabungan. Untuk mendapatkan perpindahan data minimal dalam gabungan pada dua tabel yang didistribusikan menggunakan hash, salah satu kolom gabungan harus ada dalam kolom distribusi atau kolom-kolom. Ketika dua tabel terdistribusi hash bergabung pada kolom distribusi dengan jenis data yang sama, penggabungan tersebut tidak memerlukan perpindahan data. Gabungan dapat menggunakan kolom tambahan tanpa menimbulkan perpindahan data.
Untuk menghindari perpindahan data selama bergabung:
- Tabel yang terlibat dalam bergabung harus didistribusikan hash pada salah satu kolom yang berpartisipasi dalam bergabung.
- Jenis data kolom gabungan harus cocok di antara kedua tabel.
- Kolom harus digabungkan dengan operator yang sama.
- Jenis gabungan tidak boleh berupa
CROSS JOIN.
Untuk melihat apakah kueri mengalami perpindahan data, Anda bisa melihat rencana kueri.
Mengatasi masalah kolom distribusi
Tidak perlu menyelesaikan semua kasus penyimpangan data. Mendistribusikan data adalah masalah menemukan keseimbangan yang tepat antara meminimalkan penyimpangan data dan perpindahan data. Meminimalkan penyimpangan data dan perpindahan data tidak selalu memungkinkan. Terkadang, manfaat memiliki pergerakan data yang minimal mungkin lebih besar daripada efek memiliki ketimpangan data.
Untuk memutuskan apakah Anda harus mengatasi penyimpangan data dalam tabel, Anda harus memahami sebanyak mungkin tentang volume data dan kueri dalam beban kerja Anda. Anda bisa menggunakan langkah-langkah dalam artikel Pemantauan kueri untuk memantau efek condong pada performa kueri. Secara khusus, cari berapa lama waktu yang dibutuhkan untuk menyelesaikan kueri besar pada distribusi individual.
Karena Anda tidak dapat mengubah kolom distribusi pada tabel yang sudah ada, cara umum untuk mengatasi penyimpangan data adalah dengan membuat ulang tabel dengan kolom distribusi yang berbeda.
Membuat ulang tabel dengan kumpulan kolom distribusi baru
Contoh ini menggunakan CREATE TABLE AS SELECT untuk membuat ulang tabel dengan kolom distribusi hash yang berbeda.
Pertama gunakan CREATE TABLE AS SELECT (CTAS) tabel baru dengan kunci baru. Kemudian buat ulang statistik dan akhirnya, tukar tabel dengan mengganti namanya.
CREATE TABLE [dbo].[FactInternetSales_CustomerKey]
WITH ( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([CustomerKey])
, PARTITION ( [OrderDateKey] RANGE RIGHT FOR VALUES ( 20000101, 20010101, 20020101, 20030101
, 20040101, 20050101, 20060101, 20070101
, 20080101, 20090101, 20100101, 20110101
, 20120101, 20130101, 20140101, 20150101
, 20160101, 20170101, 20180101, 20190101
, 20200101, 20210101, 20220101, 20230101
, 20240101, 20250101, 20260101, 20270101
, 20280101, 20290101
)
)
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
OPTION (LABEL = 'CTAS : FactInternetSales_CustomerKey')
;
--Create statistics on new table
CREATE STATISTICS [ProductKey] ON [FactInternetSales_CustomerKey] ([ProductKey]);
CREATE STATISTICS [OrderDateKey] ON [FactInternetSales_CustomerKey] ([OrderDateKey]);
CREATE STATISTICS [CustomerKey] ON [FactInternetSales_CustomerKey] ([CustomerKey]);
CREATE STATISTICS [PromotionKey] ON [FactInternetSales_CustomerKey] ([PromotionKey]);
CREATE STATISTICS [SalesOrderNumber] ON [FactInternetSales_CustomerKey] ([SalesOrderNumber]);
CREATE STATISTICS [OrderQuantity] ON [FactInternetSales_CustomerKey] ([OrderQuantity]);
CREATE STATISTICS [UnitPrice] ON [FactInternetSales_CustomerKey] ([UnitPrice]);
CREATE STATISTICS [SalesAmount] ON [FactInternetSales_CustomerKey] ([SalesAmount]);
--Rename the tables
RENAME OBJECT [dbo].[FactInternetSales] TO [FactInternetSales_ProductKey];
RENAME OBJECT [dbo].[FactInternetSales_CustomerKey] TO [FactInternetSales];
Konten terkait
Untuk membuat tabel terdistribusi, gunakan salah satu pernyataan berikut: