Arsitektur kumpulan SQL khusus (formerly SQL DW) pada Azure Synapse Analytics
Azure Synapse Analytics adalah layanan analitik yang menyatukan pergudangan data perusahaan dan analitik Big Data. Layanan ini memberi Anda kebebasan untuk melakukan kueri data sesuai keinginan Anda.
Catatan
Untuk informasi lebih lanjut tentang Azure Synapse Analytics, tonton video ini menjelaskan Peningkatan Pergerakan Data.
Komponen arsitektur Synapse SQL
Kumpulan SQL khusus (sebelumnya SQL DW) memanfaatkan arsitektur peluasan skala untuk mendistribusikan pemrosesan data komputasi pada beberapa simpul. Unit skala adalah abstraksi daya komputasi yang dikenal sebagai unit gudang data. Komputasi dilakukan terpisah dari penyimpanan, yang memungkinkan Anda menskalakan komputasi secara independen dari data dalam sistem Anda.
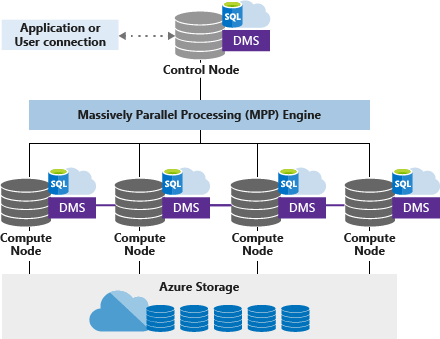
Kumpulan SQL khusus (sebelumnya SQL DW) menggunakan arsitektur berbasis simpul. Aplikasi menyambungkan dan mengeluarkan perintah T-SQL kepada Simpul control. Simpul kontrol menjadi host untuk mesin kueri terdistribusi, yang mengoptimalkan kueri untuk pemrosesan paralel, dan kemudian meneruskan operasi ke Simpul komputasi agar pekerjaan dapat dilakukan secara paralel.
Simpul komputasi menyimpan semua data pengguna pada Azure Storage dan menjalankan kueri paralel. Layanan Pergerakan Data (Data Movement Service/DMS) adalah layanan internal tingkat sistem yang memindahkan data ke seluruh simpul sesuai kebutuhan untuk menjalankan kueri secara paralel dan mengembalikan hasil yang akurat.
Dengan penyimpanan dan komputasi yang dipisahkan, kumpulan SQL khusus (sebelumnya SQL DW) dapat digunakan untuk:
- Daya komputasi ukuran independen terlepas dari kebutuhan penyimpanan Anda.
- Menumbuhkan atau menyusutkan daya komputasi, di dalam kumpulan SQL khusus (sebelumnya SQL DW), tanpa memindahkan data.
- Jeda kapasitas komputasi sambil membiarkan data tetap utuh sehingga Anda hanya membayar penyimpanan.
- Lanjutkan kapasitas komputasi selama jam operasional.
Azure Storage
Kumpulan SQL khusus SQL (sebelumnya SQL DW) memanfaatkan Azure Storage untuk menjaga keamanan data pengguna Anda. Karena data Anda disimpan dan dikelola oleh Azure Storage, ada biaya terpisah untuk konsumsi penyimpanan Anda. Data tersebut dipecah ke dalam distribusi untuk mengoptimalkan performa sistem. Anda dapat memilih pola pemecahan yang akan digunakan untuk mendistribusikan data saat Anda menentukan tabel. Pola pemecahan ini didukung oleh:
- Hash
- Round Robin
- REPLIKASI
Simpul Kontrol
Simpul Kontrol adalah otak dari arsitektur. Simpul ini adalah bagian pertama yang berinteraksi dengan semua aplikasi dan koneksi. Mesin kueri terdistribusi berjalan pada Simpul kontrol untuk mengoptimalkan dan mengoordinasikan kueri paralel. Saat Anda mengirimkan kueri T-SQL, Simpul kontrol mengubahnya menjadi kueri yang berjalan terhadap setiap distribusi secara paralel.
Simpul komputasi
Simpul Komputasi menyediakan daya komputasi. Peta distribusi dikirim ke simpul Komputasi untuk diproses. Saat Anda membayar lebih banyak untuk sumber daya komputasi, distribusi dipetakan ulang ke Simpul komputasi yang tersedia. Jumlah simpul komputasi berkisar antara 1 hingga 60, dan ditentukan oleh tingkat layanan untuk Synapse SQL.
Setiap simpul Komputasi memiliki ID simpul yang terlihat dalam tampilan sistem. Anda dapat melihat ID simpul Komputasi dengan mencari kolom simpul_id dalam tampilan sistem dengan nama awal sys.pdw_nodes. Untuk daftar tampilan sistem ini, lihat Tampilan sistem Synapse SQL.
Layanan pemindahan data (Data Movement Service)
Data Movement Service (DMS) adalah teknologi pengangkut data yang mengoordinasikan pergerakan data di antara Simpul komputasi. Beberapa kueri memerlukan pergerakan data untuk memastikan kueri paralel memberikan hasil yang akurat. Ketika pergerakan data diperlukan, DMS memastikan data yang tepat sampai ke lokasi yang tepat.
Distribusi
Distribusi adalah pelajaran penyimpanan dan pemrosesan dasar untuk kueri paralel yang berjalan pada data terdistribusi. Ketika Synapse SQL menjalankan kueri, tugas tersebut dibagi menjadi 60 kueri yang lebih kecil dan berjalan secara paralel.
Setiap 60 kueri yang lebih kecil tersebut berjalan pada salah satu distribusi data. Setiap simpul Komputasi mengelola satu atau sebagian dari 60 distribusi tersebut. Kumpulan SQL khusus (sebelumnya SQL DW) dengan sumber daya komputasi maksimum memiliki satu distribusi per Simpul komputasi. Kumpulan SQL khusus (sebelumnya SQL DW) dengan sumber daya komputasi minimum memiliki semua distribusi pada satu simpul komputasi.
Catatan
Untuk rekomendasi tentang strategi distribusi tabel terbaik untuk digunakan berdasarkan beban kerja Anda, lihat Azure Synapse SQL Distribution Advisor.
Tabel terdistribusi hash
Tabel terdistribusi hash dapat menjalankan performa kueri tertinggi untuk gabungan dan agregasi pada tabel besar.
Untuk memecah data ke dalam tabel yang didistribusikan hash, fungsi hash digunakan untuk menetapkan setiap baris secara deterministik ke satu distribusi. Dalam definisi tabel, salah satu kolom ditetapkan sebagai kolom distribusi. Fungsi hash menggunakan nilai dalam kolom distribusi untuk menetapkan setiap baris ke distribusi.
Diagram berikut ini menggambarkan bagaimana tabel lengkap (tabel tidak didistribusikan) disimpan sebagai tabel yang didistribusikan hash.

- Setiap baris adalah bagian dari satu distribusi.
- Algoritma hash deterministik menetapkan setiap baris untuk satu distribusi.
- Jumlah baris tabel per distribusi bervariasi seperti yang diperlihatkan oleh berbagai ukuran tabel.
Ada pertimbangan performa untuk pilihan kolom distribusi, seperti perbedaan, kecondongan data, dan tipe kueri yang berjalan pada sistem.
Tabel terdistribusi round-robin
Tabel round-robin adalah tabel paling sederhana yang mudah dibuat serta memberikan performa cepat ketika digunakan sebagai meja penahapan pada beban.
Tabel terdistribusi round robin mendistribusikan data secara merata ke seluruh tabel, tetapi tanpa pengoptimalan lebih lanjut. Sebuah distribusi pertama kali dipilih secara acak dan kemudian buffer baris ditetapkan ke distribusi secara berurutan. Data dimuat ke dalam tabel round-robin dengan cepat, tetapi performa kueri biasanya lebih baik dengan tabel terdistribusi hash. Gabungan pada tabel round-robin memerlukan perubahan pada data sehingga membutuhkan waktu tambahan.
Tabel yang Direplikasi
Tabel yang direplikasi menyediakan performa kueri tercepat untuk tabel kecil.
Tabel yang direplikasi menyimpan salinan lengkap tabel di setiap node komputasi. Sebagai hasilnya, dengan mereplikasi tabel, tidak perlu mentransfer data di antara simpul komputasi sebelum gabungan atau agregasi. Tabel yang direplikasi paling baik digunakan dengan tabel kecil. Penyimpanan ekstra diperlukan dan ada overhead tambahan yang dikeluarkan saat menulis data sehingga membuat tabel besar tidak praktis.
Diagram di bawah ini memperlihatkan tabel yang direplikasi dan dilakukan cache pada distribusi pertama di setiap simpul komputasi.

Langkah berikutnya
Sekarang setelah Anda tahu sedikit tentang Azure Synapse, pelajari cara cepat membuat kumpulan SQL khusus (sebelumnya SQL DW) dan memuat data sampel. Jika Anda baru menggunakan Azure, glosarium Azure akan sangat bermanfaat bagi Anda ketika menemukan terminologi baru. Atau lihat beberapa Sumber Daya Azure Synapse lainnya.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk