Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tip
Microsoft Fabric Data Warehouse adalah gudang relasional skala perusahaan pada fondasi data lake, dengan arsitektur siap masa depan, AI bawaan, dan fitur baru. Jika Anda baru menggunakan pergudangan data, mulailah dengan Fabric Data Warehouse. Beban kerja kumpulan SQL terdedikasi yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik waktu nyata, dan pelaporan.
Di bagian ini, Anda akan mempelajari cara membuat dan menggunakan views untuk membungkus kueri kumpulan SQL tanpa server. Tampilan akan memungkinkan Anda untuk menggunakan kembali kueri tersebut. Tampilan juga diperlukan jika Anda ingin menggunakan alat, seperti Power BI, bersama dengan kumpulan SQL tanpa server.
Prasyarat
Langkah pertama Anda adalah membuat database di mana tampilan akan dibuat dan menginisialisasi objek yang diperlukan untuk mengautentikasi penyimpanan Azure dengan mengeksekusi skrip pengaturan pada database tersebut. Semua kueri dalam artikel ini akan dieksekusi pada database sampel Anda.
Tampilan atas data eksternal
Anda dapat membuat tampilan dengan cara yang sama seperti Anda membuat tampilan SQL Server reguler. Kueri berikut ini membuat tampilan yang membaca file population.csv.
Catatan
Mengubah baris pertama dalam kueri, yaitu [mydbname], sehingga Anda menggunakan database yang Anda buat.
USE [mydbname];
GO
DROP VIEW IF EXISTS populationView;
GO
CREATE VIEW populationView AS
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r];
Tampilan menggunakan EXTERNAL DATA SOURCE dengan URL akar dari penyimpanan Anda sebagai DATA_SOURCE dan menambahkan jalur file relatif ke file.
Tampilan Delta Lake
Jika Anda membuat tampilan di atas folder Delta Lake, Anda perlu menentukan lokasi ke folder akar setelah BULK opsi alih-alih menentukan jalur file.
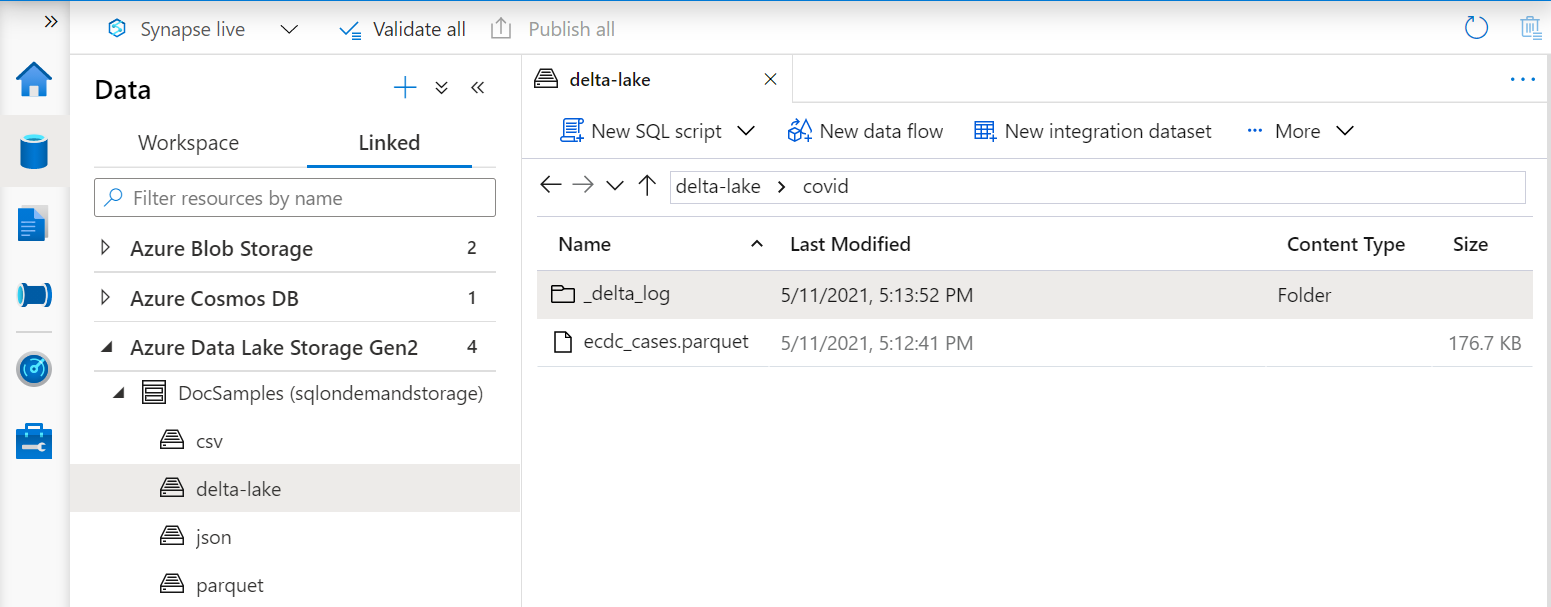
Fungsi OPENROWSET yang membaca data dari folder Delta Lake akan memeriksa struktur folder dan secara otomatis mengidentifikasi lokasi file.
create or alter view CovidDeltaLake
as
select *
from openrowset(
bulk 'covid',
data_source = 'DeltaLakeStorage',
format = 'delta'
) with (
date_rep date,
cases int,
geo_id varchar(6)
) as rows
Untuk informasi selengkapnya, tinjau halaman swabantu SQL pool serverless Synapse dan masalah yang diketahui Azure Synapse Analytics.
Tampilan terpartisi
Jika Anda memiliki sekumpulan file yang dipartisi dalam struktur folder hierarki, Anda dapat menjelaskan pola partisi menggunakan wildcard di jalur file. Gunakan fungsi FILEPATH untuk mengekspos bagian jalur folder sebagai kolom pemartisi.
CREATE VIEW TaxiView
AS SELECT *, nyc.filepath(1) AS [year], nyc.filepath(2) AS [month]
FROM
OPENROWSET(
BULK 'parquet/taxi/year=*/month=*/*.parquet',
DATA_SOURCE = 'sqlondemanddemo',
FORMAT='PARQUET'
) AS nyc
Tampilan yang dipartisi dapat meningkatkan performa kueri Anda dengan melakukan eliminasi partisi saat Anda mengkuerinya dengan filter pada kolom partisi. Namun, tidak semua kueri mendukung penghapusan partisi, jadi penting untuk mengikuti beberapa praktik terbaik.
Untuk memastikan penghapusan partisi, hindari menggunakan subkueri dalam filter, karena dapat mengganggu kemampuan untuk menghilangkan partisi. Sebagai gantinya, teruskan hasil subkueri sebagai variabel ke filter.
Saat menggunakan JOIN dalam kueri SQL, deklarasikan predikat filter sebagai NVARCHAR untuk mengurangi kompleksitas rencana kueri dan meningkatkan probabilitas penghapusan partisi yang benar. Kolom partisi biasanya disimpulkan sebagai NVARCHAR(1024), jadi menggunakan jenis yang sama untuk predikat menghindari kebutuhan akan cast implisit, yang dapat meningkatkan kompleksitas rencana kueri.
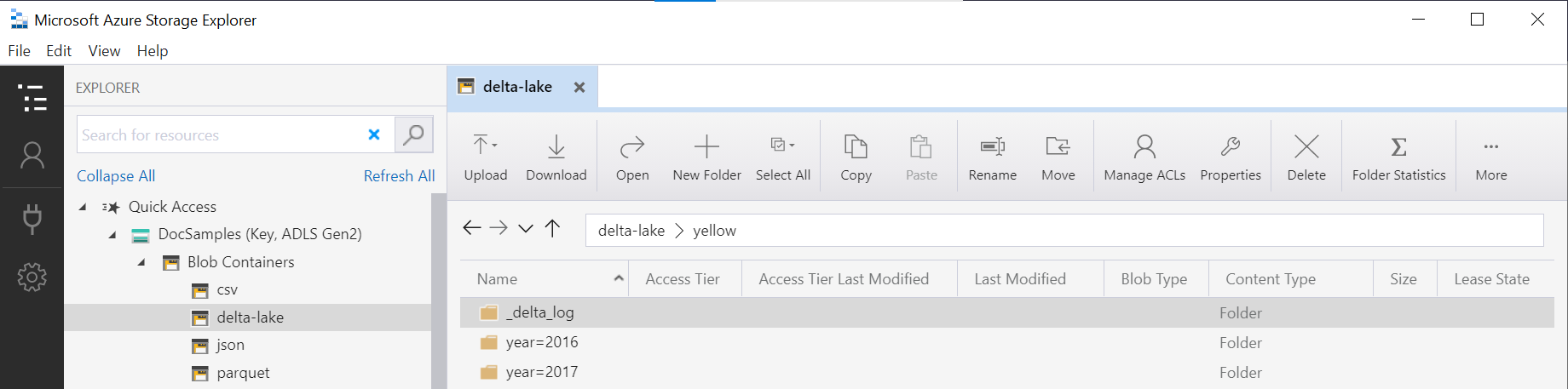
Tampilan Delta Lake terpartisi
Jika Anda membuat tampilan yang dipartisi di atas penyimpanan Delta Lake, Anda dapat hanya menentukan folder root Delta Lake, dan tidak perlu secara eksplisit mengekspos kolom partisi menggunakan fungsi FILEPATH.
CREATE OR ALTER VIEW YellowTaxiView
AS SELECT *
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
Fungsi OPENROWSET ini akan memeriksa struktur folder Delta Lake yang mendasarinya dan secara otomatis mengidentifikasi dan mengekspos kolom partisi. Penghapusan partisi akan dilakukan secara otomatis jika Anda meletakkan kolom partisi dalam WHERE klausa kueri.
Nama folder dalam OPENROWSET fungsi (dalam yellow contoh ini) yang digabungkan dengan LOCATION URI yang ditentukan dalam sumber data DeltaLakeStorage harus mereferensikan folder Delta Lake root yang berisi subfolder yang disebut _delta_log.
Untuk informasi selengkapnya, tinjau halaman bantuan mandiri kumpulan SQL tanpa server Synapse dan masalah yang diketahui Azure Synapse Analytics.
Tampilan JSON
Tampilan adalah pilihan yang baik jika Anda perlu melakukan beberapa pemrosesan tambahan di atas kumpulan hasil yang diambil dari file. Salah satu contohnya mungkin mengurai file JSON di mana kita perlu menerapkan fungsi JSON untuk mengekstrak nilai dari dokumen JSON:
CREATE OR ALTER VIEW CovidCases
AS
select
*
from openrowset(
bulk 'latest/ecdc_cases.jsonl',
data_source = 'covid',
format = 'csv',
fieldterminator ='0x0b',
fieldquote = '0x0b'
) with (doc nvarchar(max)) as rows
cross apply openjson (doc)
with ( date_rep datetime2,
cases int,
fatal int '$.deaths',
country varchar(100) '$.countries_and_territories')
Fungsi OPENJSON mengurai setiap baris dari file JSONL yang berisi satu dokumen JSON per baris dalam format tekstual.
Tampilan Azure Cosmos DB pada kontainer
Tampilan dapat dibuat di atas kontainer Azure Cosmos DB jika penyimpanan analitik Azure Cosmos DB diaktifkan pada kontainer. Nama akun, nama database, dan nama kontainer Azure Cosmos DB harus ditambahkan sebagai bagian dari tampilan, dan kunci akses baca-saja harus ditempatkan dalam kredensial cakupan database yang direferensikan tampilan.
Contoh skrip ini menggunakan database dan kontainer yang dapat Anda siapkan dengan mengikuti instruksi ini.
Penting
Dalam skrip, ganti nilai-nilai ini dengan nilai Anda sendiri:
- your-cosmosdb - nama akun Cosmos DB Anda
- access-key - kunci akun Cosmos DB Anda
CREATE DATABASE SCOPED CREDENTIAL MyCosmosDbAccountCredential
WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = 'access-key';
GO
CREATE OR ALTER VIEW Ecdc
AS SELECT *
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=your-cosmosdb;Database=covid',
OBJECT = 'Ecdc',
CREDENTIAL = 'MyCosmosDbAccountCredential'
) with ( date_rep varchar(20), cases bigint, geo_id varchar(6) ) as rows
Untuk informasi selengkapnya, lihat Kueri data Azure Cosmos DB dengan kumpulan SQL tanpa server di Azure Synapse Link.
Menggunakan pandangan
Anda bisa menggunakan tampilan dalam kueri Anda dengan cara yang sama seperti Anda menggunakan tampilan dalam kueri SQL Server.
Kueri berikut ini menunjukkan cara menggunakan tampilan population_csv yang kami buat di Buat lapisan. Ini mengembalikan nama negara/wilayah dengan populasi mereka pada tahun 2019 dalam urutan menurun.
Catatan
Mengubah baris pertama dalam kueri, yaitu [mydbname], sehingga Anda menggunakan database yang Anda buat.
USE [mydbname];
GO
SELECT
country_name, population
FROM populationView
WHERE
[year] = 2019
ORDER BY
[population] DESC;
Saat Anda mengkueri tampilan, Anda mungkin mengalami kesalahan atau hasil yang tidak terduga. Ini mungkin berarti bahwa tampilan mereferensikan kolom atau objek yang dimodifikasi atau tidak ada lagi. Anda perlu menyesuaikan definisi tampilan secara manual agar selaras dengan perubahan skema yang mendasar.
Konten terkait
Untuk informasi tentang cara mengkueri berbagai jenis file, silakan merujuk pada artikel kueri file CSV tunggal,file Parquet, dan file JSON.