Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tip
Microsoft Fabric Data Warehouse adalah gudang relasional skala perusahaan pada fondasi data lake, dengan arsitektur siap masa depan, AI bawaan, dan fitur baru. Jika Anda baru menggunakan pergudangan data, mulailah dengan Fabric Data Warehouse. Beban kerja kumpulan SQL terdedikasi yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik waktu nyata, dan pelaporan.
Dalam artikel ini, Anda akan mempelajari cara mengkueri satu file CSV menggunakan kumpulan SQL tanpa server di Azure Synapse Analytics. File CSV mungkin memiliki format yang berbeda:
- Dengan dan tanpa baris judul
- Nilai yang dipisahkan oleh koma dan tab
- Akhir baris bergaya Windows dan Unix
- Nilai yang tidak dikutip dan dikutip, serta karakter escape
Semua variasi di atas akan dibahas di bawah ini.
Contoh Panduan Cepat Memulai
Fungsi OPENROWSET memungkinkan Anda untuk membaca konten file CSV dengan menyediakan URL ke file Anda.
Membaca file CSV
Cara termudah untuk melihat konten file CSV Anda adalah dengan menyediakan URL file ke fungsi OPENROWSET dan menentukan csv FORMAT, dan 2.0 PARSER_VERSION. Jika file tersedia untuk umum atau jika identitas Microsoft Entra Anda dapat mengakses file ini, Anda akan dapat melihat konten file menggunakan kueri seperti yang diperlihatkan dalam contoh berikut:
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
Opsi firstrow digunakan untuk melewati baris pertama dalam file CSV yang mewakili header dalam kasus ini. Pastikan Anda bisa mengakses file ini. Jika file Anda dilindungi dengan kunci SAS atau identitas kustom, Anda harus menyiapkan kredensial tingkat server untuk masuk sql.
Penting
Jika file CSV Anda berisi karakter UTF-8, pastikan Anda menggunakan kolatasi database UTF-8 (misalnya Latin1_General_100_CI_AS_SC_UTF8).
Ketidakcocokan antara pengkodean teks dalam file dan kolase dapat menyebabkan kesalahan konversi yang tidak terduga.
Anda dapat dengan mudah mengubah kolase default database saat ini menggunakan pernyataan T-SQL berikut: alter database current collate Latin1_General_100_CI_AI_SC_UTF8
Penggunaan sumber data
Contoh sebelumnya menggunakan jalur lengkap ke file. Sebagai alternatif, Anda dapat membuat sumber data eksternal dengan lokasi yang menunjuk ke folder akar penyimpanan:
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
Setelah Anda membuat sumber data, Anda bisa menggunakan sumber data tersebut dan jalur relatifnya ke file di fungsi OPENROWSET:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
Jika sumber data dilindungi dengan kunci SAS atau identitas khusus, Anda bisa mengonfigurasi sumber data dengan kredensial yang dibatasi lingkupnya di database.
Secara eksplisit menentukan skema
OPENROWSET memungkinkan Anda secara eksplisit menentukan kolom apa yang ingin Anda baca dari file menggunakan klausul WITH:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
Angka-angka setelah jenis data dalam klausul WITH mewakili indeks kolom dalam file CSV.
Penting
Jika file CSV Anda berisi karakter UTF-8, pastikan Anda secara eksplisit menentukan beberapa kolase UTF-8 (misalnya Latin1_General_100_CI_AS_SC_UTF8) untuk semua kolom dalam WITH klausa atau atur beberapa kolase UTF-8 di tingkat database.
Ketidakcocokan antara pengkodean teks dalam file dan kolase dapat menyebabkan kesalahan konversi yang tidak terduga.
Anda dapat dengan mudah mengubah kolase default database saat ini menggunakan pernyataan T-SQL berikut:
alter database current collate Latin1_General_100_CI_AI_SC_UTF8 Anda dapat dengan mudah mengatur kolase pada jenis kolom menggunakan definisi berikut: geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
Di bagian berikut ini Anda bisa melihat cara mengkueri berbagai jenis file CSV.
Prasyarat
Langkah pertama Anda adalah membuat database di mana tabel akan dibuat. Kemudian menginisialisasi objek dengan mengeksekusi skrip penyiapan pada database itu. Skrip penyetelan ini akan membuat sumber data, info masuk lingkup database, dan format file eksternal yang digunakan dalam sampel ini.
Gaya baris baru Windows
Kueri berikut menunjukkan cara membaca file CSV tanpa baris header, dengan baris baru bergaya Windows, dan kolom yang berbatas koma.
Pratinjau berkas
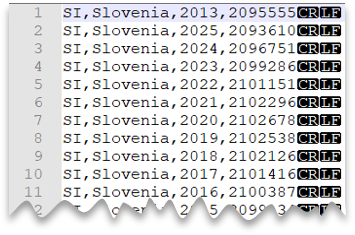
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Baris baru gaya Unix
Kueri berikut menunjukkan cara membaca file tanpa baris header, dengan baris baru bergaya Unix, dan kolom yang berbatas koma. Perhatikan lokasi file yang berbeda dibandingkan dengan contoh lainnya.
Pratinjau berkas
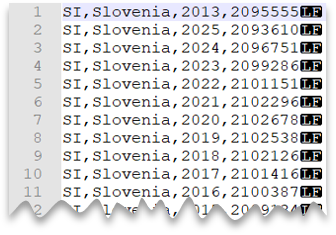
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Baris kepala
Kueri berikut menunjukkan cara membaca file tanpa baris header, dengan baris baru bergaya Unix, dan kolom yang berbatas koma. Perhatikan lokasi file yang berbeda dibandingkan dengan contoh lainnya.
Pratinjau berkas
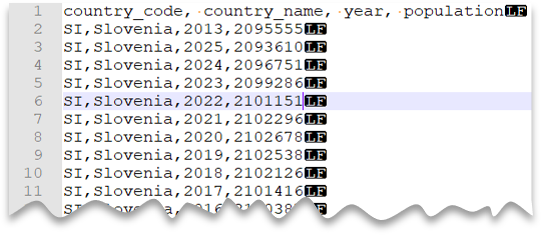
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
Opsi HEADER_ROW = TRUE akan menjalankan proses membaca nama kolom dari baris header dalam file. Ini bagus untuk tujuan eksplorasi ketika Anda tidak terbiasa dengan konten file. Untuk performa terbaik, lihat Bagian Menggunakan jenis data yang sesuai di Praktik terbaik. Selain itu, Anda dapat membaca lebih lanjut tentang sintaksis OPENROWSET di sini.
Karakter kutipan khusus
Kueri berikut menunjukkan cara membaca file dengan baris header, dengan baris baru bergaya Unix, kolom yang berbatas koma, dan nilai yang diapit tanda petik. Perhatikan lokasi file yang berbeda dibandingkan dengan contoh lainnya.
Pratinjau berkas
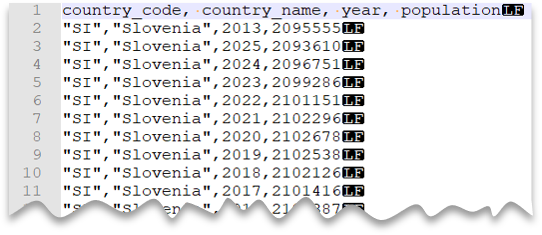
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Catatan
Kueri ini akan mengembalikan hasil yang sama jika Anda menghilangkan parameter FIELDQUOTE karena nilai default untuk FIELDQUOTE adalah kutipan ganda.
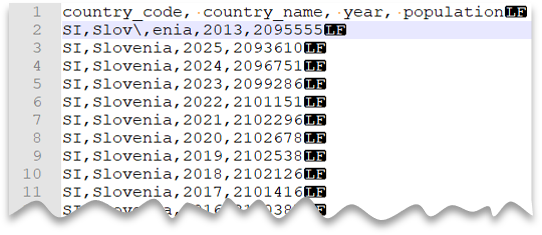
Karakter pembatalan
Kueri berikut ini memperlihatkan cara membaca file dengan baris header, dengan baris baru bergaya Unix, kolom yang dipisahkan oleh koma, dan karakter escape yang digunakan untuk pemisah bidang (koma) dalam nilai. Perhatikan lokasi file yang berbeda dibandingkan dengan contoh lainnya.
Pratinjau berkas
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Catatan
Kueri ini akan gagal jika ESCAPECHAR tidak ditentukan karena koma di "Slov,enia" akan diperlakukan sebagai pemisah bidang alih-alih bagian dari nama negara/wilayah. "Slov,enia" akan diperlakukan sebagai dua kolom. Oleh karena itu, baris tersebut akan memiliki satu kolom lebih banyak daripada baris lainnya, dan satu kolom lebih dari yang Anda tentukan dalam klausul WITH.
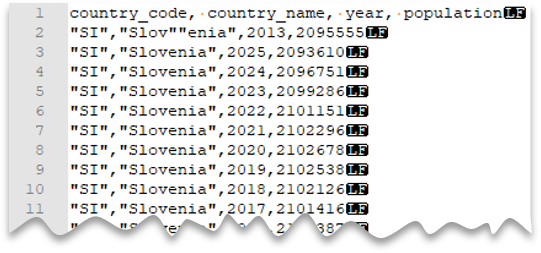
Karakter kutipan escape
Kueri berikut ini memperlihatkan cara membaca file dengan baris header, dengan baris baru bergaya Unix, kolom yang dipisahkan oleh koma, dan karakter kutip ganda yang di-escape dalam nilai. Perhatikan lokasi file yang berbeda dibandingkan dengan contoh lainnya.
Pratinjau berkas
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Catatan
Karakter kutipan harus diloloskan dengan karakter kutipan lain. Karakter kutipan dapat muncul dalam nilai kolom hanya jika nilainya dibungkus dengan karakter kutipan.
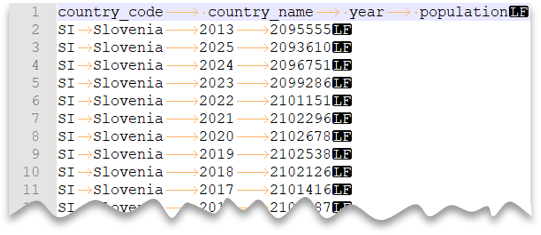
File dengan pembatas tab
Kueri berikut menunjukkan cara membaca berkas yang memiliki baris header, menggunakan karakter baris baru gaya Unix, dan kolom yang dipisahkan tab. Perhatikan lokasi file yang berbeda dibandingkan dengan contoh lainnya.
Pratinjau berkas
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
Mengembalikan bagian dari kolom
Sejauh ini, Anda telah menentukan skema file CSV menggunakan WITH dan mencantumkan semua kolom. Anda hanya bisa menentukan kolom yang sebenarnya Anda butuhkan dalam kueri Anda dengan menggunakan nomor urut untuk setiap kolom yang diperlukan. Anda juga akan menghilangkan kolom yang tidak menarik.
Kueri berikut mengembalikan jumlah nama negara/kawasan yang berbeda dalam file, dan menentukan kolom yang diperlukan saja:
Catatan
Lihat klausul WITH dalam kueri di bawah ini dan perhatikan bahwa ada "2" (tanpa tanda kutip) di akhir baris di mana Anda tentukan kolom [country_name]. Ini berarti bahwa kolom [country_name] adalah kolom kedua dalam file. Kueri akan mengabaikan semua kolom dalam file kecuali yang kedua.
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
Meminta file yang dapat ditambahkan
File CSV yang digunakan dalam kueri tidak boleh diubah saat kueri sedang berjalan. Dalam kueri yang sudah berjalan lama, kumpulan SQL dapat mencoba membaca kembali, membaca sebagian file, atau bahkan membaca file beberapa kali. Perubahan konten file akan menyebabkan hasil yang salah. Oleh karena itu, kumpulan SQL pool akan gagal memproses kueri jika mendeteksi bahwa waktu modifikasi file apa pun telah diubah selama eksekusi kueri.
Dalam beberapa skenario, Anda mungkin ingin membaca file yang terus ditambahkan. Untuk menghindari kegagalan kueri karena file yang terus ditambahkan, Anda dapat mengizinkan fungsi OPENROWSET untuk mengabaikan pembacaan yang berpotensi tidak konsisten menggunakan pengaturan ROWSET_OPTIONS.
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
Opsi baca ALLOW_INCONSISTENT_READS akan menonaktifkan pemeriksaan waktu modifikasi file selama siklus hidup kueri dan membaca apa pun yang tersedia dalam file. Dalam file yang dapat ditambahkan, konten yang ada tidak diperbarui, dan hanya baris baru yang ditambahkan. Oleh karena itu, probabilitas hasil yang salah diminimalisir dibandingkan dengan file yang dapat diperbarui. Opsi ini dapat memungkinkan Anda membaca file yang sering ditambahkan tanpa menangani kesalahan. Dalam sebagian besar skenario, SQL pool hanya akan mengabaikan beberapa baris yang ditambahkan ke file saat eksekusi kueri.
Konten terkait
Artikel berikutnya akan menunjukkan kepada Anda cara: