Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tip
Microsoft Fabric Data Warehouse adalah gudang relasional skala perusahaan pada fondasi data lake, dengan arsitektur siap masa depan, AI bawaan, dan fitur baru. Jika Anda baru menggunakan pergudangan data, mulailah dengan Fabric Data Warehouse. Beban kerja kumpulan SQL terdedikasi yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik waktu nyata, dan pelaporan.
Fungsi OPENROWSET(BULK...) memungkinkan Anda mengakses file di Azure Storage. Fungsi OPENROWSET membaca konten sumber data jauh (misalnya file) dan mengembalikan konten sebagai kumpulan baris. Dalam sumber daya kumpulan SQL tanpa server, penyedia kumpulan baris massal OPENROWSET diakses dengan memanggil fungsi OPENROWSET dan menentukan opsi BULK.
Fungsi OPENROWSET dapat direferensikan dalam klausa FROM kueri seolah-olah merupakan nama tabel OPENROWSET. Ini mendukung operasi massal melalui penyedia BULK bawaan yang memungkinkan data dari file dibaca dan dikembalikan sebagai kumpulan baris.
Catatan
Fungsi OPENROWSET tidak didukung dalam kumpulan SQL khusus.
Sumber data
Fungsi OPENROWSET di Synapse SQL membaca konten file dari sumber data. Sumber data adalah akun Azure storage dan sumber ini dapat secara eksplisit direferensikan dalam fungsi OPENROWSET atau dapat disimpulkan secara dinamis dari URL file yang ingin Anda baca.
Fungsi OPENROWSET secara opsional dapat berisi parameter DATA_SOURCE untuk menentukan sumber data yang berisi file.
OPENROWSETtanpaDATA_SOURCEdapat digunakan untuk langsung membaca konten file dari lokasi URL yang ditentukan sebagai opsiBULK:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
Ini adalah cara cepat dan mudah untuk membaca konten file tanpa prakonfigurasi. Opsi ini memungkinkan Anda menggunakan autentikasi dasar untuk mengakses penyimpanan dengan opsi koneksi langsung Microsoft Entra untuk login ke Microsoft Entra dan penggunaan token SAS untuk otentikasi login SQL.
OPENROWSETdenganDATA_SOURCEdapat digunakan untuk mengakses file pada akun penyimpanan tertentu:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]Opsi ini memungkinkan Anda mengonfigurasi lokasi akun penyimpanan di sumber data dan menentukan metode autentikasi yang harus digunakan untuk mengakses penyimpanan.
Penting
OPENROWSETtanpaDATA_SOURCEmenyediakan cara yang cepat dan mudah untuk mengakses file penyimpanan, tetapi menawarkan opsi autentikasi terbatas. Sebagai contoh, perwakilan Microsoft Entra hanya dapat mengakses file menggunakan identitas Microsoft Entra atau file yang tersedia untuk umum. Jika Anda memerlukan opsi autentikasi yang lebih kuat, gunakan opsiDATA_SOURCEdan tentukan kredensial yang ingin Anda gunakan untuk mengakses penyimpanan.
Keamanan
Pengguna database harus memiliki izin ADMINISTER BULK OPERATIONS untuk menggunakan fungsi OPENROWSET tersebut.
Administrator penyimpanan juga harus memungkinkan pengguna untuk mengakses file dengan menyediakan token SAS yang valid atau mengaktifkan perwakilan Microsoft Entra untuk mengakses file penyimpanan. Pelajari selengkapnya tentang kontrol akses penyimpanan di artikel ini.
OPENROWSET menggunakan aturan berikut untuk menentukan cara mengautentikasi ke penyimpanan:
- Di
OPENROWSETtanpaDATA_SOURCE, mekanisme autentikasi tergantung pada tipe pemanggil.- Pengguna apa pun dapat menggunakan
OPENROWSETtanpaDATA_SOURCEuntuk membaca file yang tersedia untuk umum di Azure storage. - Login Microsoft Entra dapat mengakses file yang dilindungi menggunakan identitas Microsoft Entra mereka sendiri jika penyimpanan Azure memungkinkan pengguna Microsoft Entra untuk mengakses file dasar (misalnya, jika pemanggil memiliki
Storage Readerizin pada penyimpanan Azure). - Login SQL juga dapat menggunakan
OPENROWSETtanpaDATA_SOURCEuntuk mengakses file yang tersedia untuk umum, file yang dilindungi menggunakan token SAS, atau Identitas Terkelola ruang kerja Synapse. Anda akan perlu membuat kredensial yang dicakup server untuk mengizinkan akses ke file penyimpanan.
- Pengguna apa pun dapat menggunakan
- Di
OPENROWSETdenganDATA_SOURCE, mekanisme autentikasi ditentukan dalam kredensial yang ada dalam cakupan database, yang ditetapkan pada sumber data yang direferensikan. Opsi ini memungkinkan Anda mengakses penyimpanan yang tersedia untuk umum, atau mengakses penyimpanan menggunakan token SAS, Identitas Terkelola ruang kerja, atau identitas Pemanggil Microsoft Entra (jika penelepon adalah perwakilan Microsoft Entra). JikaDATA_SOURCEmerujuk Azure storage yang bukan publik, Anda harus membuat kredensial yang dicakup database dan mereferensikannya diDATA SOURCEuntuk mengizinkan akses ke file penyimpanan.
Pemanggil harus memiliki izin REFERENCES pada kredensial guna menggunakannya untuk mengautentikasi ke penyimpanan.
Sintaks
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
Argumen
Anda memiliki tiga pilihan untuk berkas masukan yang berisi data target untuk keperluan query. Nilai yang valid adalah:
'CSV' - Menyertakan file teks yang dibatasi dengan pemisah baris/kolom. Karakter apa pun dapat digunakan sebagai pemisah bidang, seperti TSV: FIELDTERMINATOR = tab.
'PARQUET' - File biner dalam format Parquet.
'DELTA' - Sekumpulan file Parquet yang diatur dalam format Delta Lake (pratinjau).
Nilai dengan spasi kosong tidak valid. Misalnya, 'CSV ' bukan nilai yang valid.
'unstructured_data_path'
Jalur data_tidak_terstruktur yang menetapkan jalur menuju data bisa berupa jalur absolut atau relatif:
- Jalur absolut dalam format
\<prefix>://\<storage_account_path>/\<storage_path>memungkinkan pengguna untuk membaca file secara langsung. - Jalur relatif dalam format
<storage_path>yang harus digunakan dengan parameterDATA_SOURCEdan harus menjelaskan pola file dalam lokasi <storage_account_path> yang ditentukan diEXTERNAL DATA SOURCE.
Di bawah ini Anda akan menemukan nilai <jalur akun penyimpanan> yang relevan yang akan ditautkan ke sumber data eksternal tertentu.
| Sumber Data Eksternal | Awalan | Jalur akun penyimpanan |
|---|---|---|
| Azure Blob Storage | http[s] | < >storage_account.blob.core.windows.net/path/file |
| Azure Blob Storage | wasb[s] | <container>@<storage_account.blob.core.windows.net/path/file> |
| Azure Data Lake Store Gen1 | http[s] | < >storage_account.azuredatalakestore.net/webhdfs/v1 |
| Azure Data Lake Store Gen2 | http[s] | < >storage_account.dfs.core.windows.net/path/file |
| Azure Data Lake Store Gen2 | abfs[s] | < |
'<jalur_penyimpanan>'
Menentukan jalur di dalam penyimpanan Anda yang menunjuk ke folder atau file yang ingin Anda baca. Jika jalur menunjuk ke kontainer atau folder, semua file akan dibaca dari kontainer atau folder tertentu tersebut. File dalam subfolder tidak akan disertakan.
Anda dapat menggunakan wildcard untuk menargetkan beberapa file atau folder. Penggunaan beberapa wildcard tidak berurutan diperbolehkan.
Di bawah ini adalah contoh yang membaca semua file csv yang dimulai dengan populasi dari semua folder yang dimulai dengan /csv/population:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
Jika Anda menentukan unstructured_data_path folder menjadi folder, kueri kumpulan SQL tanpa server akan mengambil file dari folder tersebut.
Anda dapat menginstruksikan kumpulan SQL tanpa server untuk melintasi folder dengan menentukan /* di akhir jalur seperti dalam contoh: https://sqlondemandstorage.blob.core.windows.net/csv/population/**
Catatan
Tidak seperti Hadoop dan PolyBase, kumpulan SQL tanpa server tidak mengembalikan subfolder kecuali Anda menentukan /** di akhir jalur. Sama seperti Hadoop dan PolyBase, ini tidak mengembalikan file yang nama filenya dimulai dengan garis bawah (_) atau titik (.).
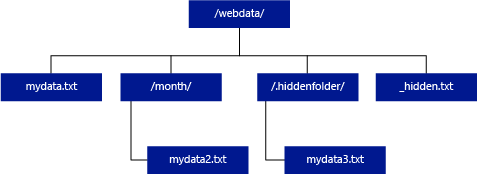
Dalam contoh di bawah ini, jika unstructured_data_path=https://mystorageaccount.dfs.core.windows.net/webdata/, kueri kumpulan SQL tanpa server akan mengembalikan baris dari mydata.txt. Ini tidak akan mengembalikan mydata2.txt dan mydata3.txt karena keduanya terletak di subfolder.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
Klausa WITH memungkinkan Anda menentukan kolom yang ingin Anda baca dari file.
Untuk file data CSV, untuk membaca semua kolom, beri nama kolom dan jenis datanya. Jika Anda menginginkan subset kolom, gunakan nomor urut untuk memilih kolom dari file data asal berdasarkan urutan. Kolom akan terikat oleh penunjukan ordinal. Jika HEADER_ROW = TRUE digunakan, pengikatan kolom dilakukan berdasarkan nama kolom bukan posisi urutan.
Tip
Anda juga dapat menghilangkan klausa WITH untuk file CSV. Jenis data akan disimpulkan secara otomatis dari konten file. Anda dapat menggunakan argumen HEADER_ROW untuk menentukan keberadaan baris header yang dalam hal ini, nama kolom akan dibaca dari baris header. Untuk detailnya, periksa penemuan skema otomatis.
Untuk file Parquet atau Delta Lake, beri nama kolom yang sesuai dengan nama kolom di file data asal. Kolom akan dikaitkan berdasarkan nama dan peka terhadap huruf besar/kecil. Jika klausa WITH dihilangkan, semua kolom dari file Parquet akan dikembalikan.
Penting
Nama kolom dalam file Parquet dan Delta Lake peka terhadap huruf besar/kecil. Jika Anda menentukan nama kolom dengan kapitalisasi yang berbeda dari kapitalisasi nama kolom dalam file, nilai
NULLakan dikembalikan untuk nama kolom tersebut.
column_name = Nama untuk kolom output. Jika disediakan, nama ini akan menggantikan nama kolom dalam file sumber dan nama kolom yang disediakan di jalur JSON jika ada. Jika json_path tidak disediakan, json_path akan ditambahkan secara otomatis sebagai '$.column_name'. Periksa argumen json_path untuk melihat perilakunya.
column_type = Jenis data untuk kolom output. Konversi jenis data implisit akan berlangsung di sini.
column_ordinal = Nomor urut kolom dalam file sumber. Argumen ini diabaikan untuk file Parquet karena pengikatan dilakukan berdasarkan nama. Contoh berikut akan mengembalikan kolom kedua hanya dari file CSV:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = Ekspresi jalur JSON untuk kolom atau properti lapis. Mode jalur default adalah longgar.
Catatan
Dalam mode ketat, kueri akan gagal dengan kesalahan jika jalur yang disediakan tidak ada. Dalam mode lax, kueri akan berhasil dan ekspresi jalur JSON akan dievaluasi menjadi NULL.
<opsi_massal>
FIELDTERMINATOR ='field_terminator'
Menentukan pemisah bidang yang akan digunakan. Pemisah bidang default adalah koma (",").
ROWTERMINATOR ='row_terminator'
Menentukan terminator baris yang akan digunakan. Jika penghenti baris tidak ditentukan, maka akan digunakan salah satu penghenti bawaan. Terminator default untuk PARSER_VERSION = '1.0' adalah \r\n, \n, dan \r. Terminator default untuk PARSER_VERSION = '2.0' adalah \r\n dan \n.
Catatan
Ketika Anda menggunakan PARSER_VERSION='1.0' dan menentukan \n (baris baru) sebagai terminator baris, maka akan secara otomatis diawali dengan karakter \r (carriage return), yang menghasilkan terminator baris \r\n.
ESCAPE_CHAR = 'char'
Menentukan karakter dalam file yang digunakan untuk melepaskan karakter tersebut dan semua nilai pemisah dalam file. Jika karakter escape diikuti oleh nilai selain nilainya sendiri, atau salah satu nilai pembatas, karakter escape akan dihilangkan saat membaca nilai.
Parameter ESCAPE_CHAR akan diterapkan terlepas dari apakah FIELDQUOTE diaktifkan atau tidak. Parameter ini tidak akan digunakan untuk mengabaikan karakter tanda kutip. Karakter kutipan harus diloloskan dengan karakter kutipan lain. Karakter kutipan dapat muncul dalam nilai kolom hanya jika nilai dikurung dengan menggunakan karakter kutipan.
FIRSTROW = 'first_row'
Menentukan jumlah baris pertama yang akan dimuat. Defaultnya adalah 1 dan menunjukkan baris pertama dalam file data yang ditentukan. Jumlah nomor baris ditentukan dengan menghitung terminator baris. FIRSTROW diasumsikan berbasis 1.
FIELDQUOTE = 'field_quote'
Menentukan karakter yang akan digunakan sebagai karakter kuotasi dalam file CSV. Jika tidak ditentukan, karakter kuotasi (") akan digunakan.
DATA_COMPRESSION = 'data_compression_method'
Menentukan metode pemadatan. Hanya didukung dalam PARSER_VERSION='1.0'. Metode pemadatan berikut didukung:
- GZIP
PARSER_VERSION = 'parser_version'
Menentukan versi parser yang akan digunakan ketika membaca file. Versi parser CSV yang saat ini didukung adalah 1.0 dan 2.0:
- PARSER_VERSION = '1.0'
- PARSER_VERSION = '2.0'
Parser CSV versi 1.0 adalah default dan kaya akan fitur. Versi 2.0 dibangun untuk performa dan tidak mendukung semua opsi dan pengodean.
Spesifikasi parser CSV versi 1.0:
- Opsi berikut tidak didukung: HEADER_ROW.
- Terminator yang default adalah \r\n, \n, dan \r.
- Jika Anda menentukan \n (newline) sebagai pemisah baris, maka secara otomatis akan diawali dengan karakter \r (carriage return), sehingga menghasilkan pemisah baris \r\n.
Spesifikasi parser CSV versi 2.0:
- Tidak semua jenis data didukung.
- Panjang kolom karakter maksimum adalah 8000.
- Batas ukuran baris maksimum adalah 8 MB.
- Opsi berikut tidak didukung: DATA_COMPRESSION.
- String kosong yang dikutip ("") ditafsirkan sebagai string kosong.
- Opsi SET DATEFORMAT tidak dihormati.
- Format yang didukung untuk jenis data DATE: YYYY-MM-DD
- Format yang didukung untuk jenis data TIME: HH:MM:SS[.bagian desimal detik]
- Format yang tersedia untuk tipe data DATETIME2: YYYY-MM-DD HH:MM:SS[.detik pecahan]
- Terminator default adalah \r\n dan \n.
HEADER_ROW = { BENAR | SALAH }
Menentukan apakah file CSV berisi baris header. Standarnya adalah FALSE. Didukung di PARSER_VERSION='2.0'. Jika TRUE, nama kolom akan dibaca dari baris pertama berdasarkan argumen FIRSTROW. Jika TRUE dan skema ditentukan menggunakan WITH, pengikatan nama kolom akan dilakukan berdasarkan nama kolom, bukan posisi urutan.
DATAFILETYPE = { 'char' | 'widechar' }
Menentukan pengkodean: char digunakan untuk UTF8, widechar digunakan untuk file UTF16.
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' }
Menentukan halaman kode data dalam file data. Nilai default adalah 65001 (pengodean UTF-8). Lihat detail selengkapnya tentang opsi ini di sini.
ROWSET_OPTIONS = '{"READ_OPTIONS":["IZINKAN_MEMBACA_TIDAK_KONSISTEN"]}'
Opsi ini akan menonaktifkan pemeriksaan modifikasi file selama eksekusi kueri, dan membaca file yang diperbarui saat kueri sedang berjalan. Ini adalah opsi yang berguna ketika Anda perlu membaca file yang hanya dapat ditambahkan saat kueri sedang diproses. Dalam file yang dapat ditambahkan, konten yang ada tidak diperbarui, dan hanya baris baru yang ditambahkan. Oleh karena itu, probabilitas hasil yang salah diminimalisir dibandingkan dengan file yang dapat diperbarui. Opsi ini dapat memungkinkan Anda membaca file yang sering ditambahkan tanpa menangani kesalahan. Lihat informasi selengkapnya di bagian mengkueri file CSV yang dapat ditambahkan.
Opsi Penolakan
Catatan
Fitur baris yang ditolak sedang dalam Pratinjau Umum. Harap perhatikan bahwa fitur penolakan baris berfungsi untuk file teks yang dibatasi dan PARSER_VERSION 1.0.
Anda dapat menentukan parameter penolakan yang menentukan bagaimana layanan akan menangani baris kotor yang diambilnya dari sumber data eksternal. Rekaman data dianggap 'cacat' jika jenis data sebenarnya tidak sesuai dengan definisi kolom di tabel eksternal.
Jika Anda tidak menentukan atau mengubah opsi penolakan, layanan akan menggunakan nilai default. Layanan akan menggunakan opsi penolakan untuk menentukan jumlah baris yang dapat ditolak sebelum kueri yang sebenarnya gagal. Kueri akan menampilkan hasil (parsial) sampai ambang penolakan terlampaui. Sistem ini kemudian gagal dengan pesan kesalahan yang sesuai.
MAXERRORS = reject_value
Menentukan jumlah baris yang dapat ditolak sebelum kueri gagal. MAXERRORS harus berupa bilangan bulat antara 0 dan 2.147.483.647.
ERRORFILE_DATA_SOURCE = sumber data
Tentukan sumber data tempat baris yang ditolak dan file kesalahan yang sesuai harus ditulis.
ERRORFILE_LOCATION = Lokasi Direktori
Direktori dalam DATA_SOURCE, atau ERROR_FILE_DATASOURCE jika ditentukan, akan menjadi tempat penulisan baris yang ditolak dan file kesalahan yang sesuai. Jika jalur yang ditentukan tidak ada, layanan akan membuatnya atas nama Anda. Direktori anak dibuat dengan nama "rejectedrows". Teks "" memastikan bahwa direktori tersebut dijadikan pengecualian dalam pemrosesan data lain kecuali dinamai secara eksplisit dalam parameter lokasi. Di dalam direktori ini, ada folder yang dibuat berdasarkan waktu pengiriman muatan dalam format YearMonthDay_HourMinuteSecond_StatementID (Mis. 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891). Anda dapat menggunakan id pernyataan untuk menghubungkan folder dengan kueri yang menghasilkannya. Dalam folder ini, dua file ditulis: file error.json dan file data.
File error.json berisi array json dengan kesalahan yang dialami terkait baris yang ditolak. Setiap elemen yang menunjukkan kesalahan berisi atribut berikut:
| Atribut | Deskripsi |
|---|---|
| Kesalahan | Alasan mengapa baris ditolak. |
| Baris | Nomor urut baris yang ditolak dalam file. |
| Kolom | Nomor ordinal kolom yang ditolak. |
| Nilai | Nilai kolom yang ditolak. Jika nilainya lebih besar dari 100 karakter, hanya 100 karakter pertama yang akan ditampilkan. |
| File | Jalur ke file tempat baris terletak. |
Penguraian cepat teks yang dibatasi
Ada dua versi parser teks yang dibatasi yang dapat Anda gunakan. Parser CSV versi 1.0 adalah default dan kaya akan fitur, sementara parser versi 2.0 dibangun untuk performa. Peningkatan performa dalam parser 2.0 berasal dari teknik parsing mutakhir dan penggunaan multi-utas. Perbedaan kecepatan akan lebih besar seiring bertambahnya ukuran file.
Penemuan skema otomatis
Anda dapat dengan mudah mengueri file CSV dan Parquet tanpa mengetahui atau menentukan skema dengan menghilangkan klausa WITH. Nama kolom dan jenis data akan diambil dari file.
File parquet berisi metadata kolom yang akan dibaca, pemetaan jenis dapat ditemukan dalam pemetaan jenis untuk Parquet. Periksa membaca file Parquet tanpa menentukan skema untuk contoh.
Untuk file CSV, nama kolom dapat dibaca dari baris header. Anda dapat menentukan apakah ada baris header menggunakan argumen HEADER_ROW. Jika HEADER_ROW = FALSE, nama kolom umum akan digunakan: C1, C2, ... Cn dengan n adalah jumlah kolom dalam file. Jenis data akan diambil dari 100 baris data pertama. Periksa cara membaca file CSV tanpa menentukan skema sebagai contoh.
Perlu diingat bahwa jika Anda membaca beberapa file sekaligus, skema akan disimpulkan dari file pertama yang diambil layanan dari penyimpanan. Ini dapat berarti bahwa beberapa kolom yang diharapkan dihilangkan, semua karena file yang digunakan oleh layanan untuk menentukan skema tidak berisi kolom ini. Dalam hal ini, gunakan perintah OPENROWSET WITH.
Penting
Ada kasus ketika jenis data yang sesuai tidak dapat diambil karena kurangnya informasi dan sebagai gantinya, jenis data yang lebih besar akan digunakan. Ini mengakibatkan overhead kinerja dan sangat penting untuk kolom karakter yang akan diinterpretasikan sebagai varchar(8000). Untuk performa optimal, periksa jenis data yang disimpulkan dan gunakan jenis data yang sesuai.
Pemetaan tipe untuk Parquet
File Parquet dan Delta Lake berisi deskripsi jenis untuk setiap kolom. Tabel berikut menjelaskan cara jenis Parquet dipetakan ke tipe data SQL asli.
| Jenis parket | Jenis logika parket (anotasi) | Tipe data SQL |
|---|---|---|
| BOOLEAN | bit | |
| BINER / BYTE_ARRAY | varbinary | |
| DOUBLE | float | |
| FLOAT | nyata | |
| INT32 | int | |
| INT64 | bigint | |
| INT96 | tanggalwaktu2 | |
| FIXED_LEN_BYTE_ARRAY | biner | |
| BINER | UTF8 | varchar *(Pengurutan UTF8) |
| BINER | STRING | varchar *(Pengurutan UTF8) |
| BINER | ENUM | varchar *(Pengurutan UTF8) |
| FIXED_LEN_BYTE_ARRAY | UUID | uniqueidentifier |
| BINER | DECIMAL | desimal |
| BINER | JSON | varchar(8000) *(kolase UTF8 ) |
| BINER | BSON | Tidak didukung |
| FIXED_LEN_BYTE_ARRAY | DECIMAL | desimal |
| BYTE_ARRAY | INTERVAL | Tidak didukung |
| INT32 | INT(8, true) | smallint |
| INT32 | INT(16, true) | smallint |
| INT32 | INT(32, true) | int |
| INT32 | INT(8, false) | tinyint |
| INT32 | INT(16, false) | int |
| INT32 | INT(32, false) | bigint |
| INT32 | TANGGAL | tanggal |
| INT32 | DECIMAL | desimal |
| INT32 | WAKTU (MILLIS) | waktu |
| INT64 | INT(64, benar) | bigint |
| INT64 | INT(64, false) | decimal(20,0) |
| INT64 | DECIMAL | desimal |
| INT64 | WAKTU (MIKRO) | waktu |
| INT64 | WAKTU (NANOS) | Tidak didukung |
| INT64 | TANDA WAKTU (dinormalisasi menjadi UTC) (MILLIS / MICROS) | tanggalwaktu2 |
| INT64 | Tanda Waktu (tidak dinormalisasi ke utc) (MILLIS / MICROS) | bigint - pastikan Anda secara eksplisit menyesuaikan nilai bigint dengan offset zona waktu sebelum mengonversinya menjadi nilai tanggal-waktu. |
| INT64 | TANDA WAKTU (NANOS) | Tidak didukung |
| Tipe Kompleks | DAFTAR | varchar(8000), diserialisasikan ke JSON |
| Tipe Kompleks | PETA | varchar(8000), diserialisasikan ke JSON |
Contoh
Membaca file CSV tanpa menentukan skema
Contoh berikut membaca file CSV yang berisi baris header tanpa menentukan nama kolom dan jenis data:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
Contoh berikut membaca file CSV yang tidak berisi baris header tanpa menentukan nama kolom dan jenis data:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
Membaca file Parquet tanpa menentukan skema
Contoh berikut mengembalikan semua kolom baris pertama dari himpunan data sensus, dalam format Parquet, dan tanpa menentukan nama kolom serta jenis data:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
Membaca file Delta Lake tanpa menentukan skema
Contoh berikut mengembalikan semua kolom baris pertama dari himpunan data sensus, dalam format Delta Lake, dan tanpa menentukan nama kolom serta jenis data:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
Membaca kolom tertentu dari file CSV
Contoh berikut hanya mengembalikan dua kolom dengan nomor urut 1 dan 4 dari file .csv populasi*. Karena tidak ada baris header dalam file, bacaan dimulai dari baris pertama:
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
Baca kolom tertentu dari file Parquet
Contoh berikut hanya mengembalikan dua kolom baris pertama dari himpunan data sensus, dalam format Parquet:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
Menentukan kolom menggunakan jalur JSON
Contoh berikut memperlihatkan cara Anda dapat menggunakan ekspresi jalur JSON dalam klausa WITH dan menunjukkan perbedaan antara mode jalur yang ketat dan longgar:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
Menentukan beberapa file/folder di jalur BULK
Contoh berikut menunjukkan cara menggunakan beberapa jalur file/folder dalam parameter BULK:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
Langkah berikutnya
Untuk sampel lainnya, lihat panduan mulai cepat penyimpanan data kueri untuk mempelajari cara menggunakan OPENROWSET untuk membaca format file CSV, PARQUET, DELTA LAKE, dan JSON. Periksa praktik terbaik untuk mencapai performa yang optimal. Anda juga dapat mempelajari cara menyimpan hasil kueri Anda ke Azure Storage menggunakan CETAS.