Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk: ✔️ Mesin virtual Linux ✔️ Mesin virtual Windows ✔️ Set skala fleksibel ✔️ Set skala seragam
Message Passing Interface (MPI) adalah pustaka terbuka dan standar defacto untuk paralelisasi memori terdistribusi. Ini umumnya digunakan di banyak beban kerja HPC. Beban kerja HPC pada VM seri HB dan seri N berkemampuanRDMA dapat menggunakan MPI untuk berkomunikasi melalui latensi rendah dan jaringan InfiniBand bandwidth tinggi.
- Ukuran VM yang diaktifkan SR-IOV di Azure memungkinkan hampir semua rasa MPI digunakan dengan Mellanox OFED.
- Pada VM yang diaktifkan non-SR-IOV, implementasi MPI yang didukung menggunakan antarmuka Microsoft Network Direct (ND) untuk berkomunikasi antar VM. Oleh karena itu, hanya Microsoft MPI (MS-MPI) 2012 R2 atau yang lebih baru dan versi Intel MPI 5.x yang didukung. Versi yang lebih baru (2017, 2018) dari library runtime Intel MPI mungkin atau mungkin tidak kompatibel dengan driver Azure RDMA.
Untuk VM berkemampuan RDMA berkemampuan SR-IOV, gambar VM Ubuntu-HPC dan gambar VM AlmaLinux-HPC cocok. Gambar VM ini dioptimalkan dan dimuat sebelumnya dengan driver OFED untuk RDMA dan berbagai pustaka MPI yang umum digunakan dan paket komputasi ilmiah dan merupakan cara term mudah untuk memulai.
Meskipun contoh di sini adalah untuk RHEL, tetapi langkah-langkahnya umum dan dapat digunakan untuk sistem operasi Linux yang kompatibel seperti Ubuntu (18.04, 20.04, 22.04) dan SLES (12 SP4 dan 15 SP4). Lebih banyak contoh untuk mengatur implementasi MPI lainnya pada distro lain ada pada repo gambar azhpc.
Catatan
Menjalankan pekerjaan MPI pada VM yang diaktifkan SR-IOV dengan library MPI tertentu (seperti Platform MPI) mungkin memerlukan pengaturan kunci partisi (p-keys) di seluruh penyewa untuk isolasi dan keamanan. Ikuti langkah-langkah di bagian Temukan kunci partisi untuk detail tentang menentukan nilai p-key dan mengaturnya dengan benar untuk pekerjaan MPI dengan perpustakaan MPI tersebut.
Catatan
Cuplikan kode di bawah ini adalah contoh. Sebaiknya gunakan versi stabil terbaru dari paket, atau mengacu pada repo gambar azhpc.
Memilih pustaka MPI
Jika aplikasi HPC merekomendasikan pustaka MPI tertentu, coba versi tersebut terlebih dahulu. Jika Anda memiliki fleksibilitas mengenai MPI mana yang dapat Anda pilih, dan Anda menginginkan performa terbaik, coba HPC-X. Secara keseluruhan, HPC-X MPI menampilkan yang terbaik dengan menggunakan kerangka kerja UCX untuk antarmuka InfiniBand, dan memanfaatkan semua kemampuan perangkat keras dan perangkat lunak Mellanox InfiniBand. Selain itu, HPC-X dan OpenMPI kompatibel dengan ABI, sehingga Anda dapat menjalankan aplikasi HPC secara dinamis dengan HPC-X yang dibangun dengan OpenMPI. Demikian pula, Intel MPI, MVAPICH, dan MPICH yang kompatibel dengan ABI.
Gambar berikut menggambarkan arsitektur untuk perpustakaan MPI yang populer.
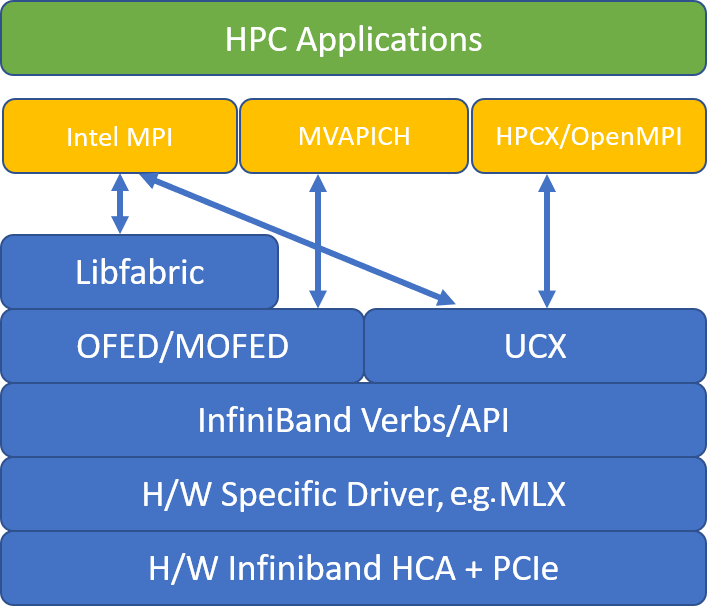
HPC-X
Peralatan perangkat lunak HPC-X berisi UCX dan HCOLL dan dapat dibangun melawan UCX.
HPCX_VERSION="v2.6.0"
HPCX_DOWNLOAD_URL=https://azhpcstor.blob.core.windows.net/azhpc-images-store/hpcx-v2.6.0-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
wget --retry-connrefused --tries=3 --waitretry=5 $HPCX_DOWNLOAD_URL
tar -xvf hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
mv hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64 ${INSTALL_PREFIX}
HPCX_PATH=${INSTALL_PREFIX}/hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64
Perintah berikut ini mengilustrasikan beberapa argumen mpirun yang direkomendasikan untuk HPC-X dan OpenMPI.
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
di mana:
| Parameter | Deskripsi |
|---|---|
NPROCS |
Menentukan jumlah proses MPI. Misalnya: -n 16. |
$HOSTFILE |
Menentukan file yang berisi nama host atau alamat IP, untuk menunjukkan lokasi tempat proses MPI berjalan. Misalnya: --hostfile hosts. |
$NUMBER_PROCESSES_PER_NUMA |
Menentukan jumlah proses MPI yang berjalan di setiap domain NUMA. Misalnya, untuk menentukan empat proses MPI per NUMA, Anda menggunakan --map-by ppr:4:numa:pe=1. |
$NUMBER_THREADS_PER_PROCESS |
Menentukan jumlah utas per proses MPI. Misalnya, untuk menentukan satu proses MPI dan empat utas per NUMA, Anda menggunakan --map-by ppr:1:numa:pe=4. |
-report-bindings |
Mencetak MPI memproses pemetaan ke core, yang berguna untuk memastikan bahwa penyematan proses MPI Anda sudah benar. |
$MPI_EXECUTABLE |
Menentukan penautan bawaan yang dapat dieksekusi MPI di pustaka MPI. Wrapper pengompilasi MPI melakukan ini secara otomatis. Sebagai contoh: mpicc atau mpif90. |
Contoh menjalankan tolok ukur mikro latensi OSU adalah sebagai berikut:
${HPCX_PATH}mpirun -np 2 --map-by ppr:2:node -x UCX_TLS=rc ${HPCX_PATH}/ompi/tests/osu-micro-benchmarks-5.3.2/osu_latency
Mengoptimalkan kolektif MPI
Primitif komunikasi kolektif MPI menawarkan cara portabel yang fleksibel untuk menerapkan operasi komunikasi kelompok. Aplikasi ini banyak digunakan di berbagai aplikasi paralel ilmiah dan berdampak signifikan pada performa aplikasi secara keseluruhan. Lihat artikel TechCommunity untuk detail tentang parameter konfigurasi untuk mengoptimalkan kinerja komunikasi kolektif menggunakan perpustakaan HPC-X dan HCOLL untuk komunikasi kolektif.
Sebagai contoh, jika Anda mencurigai aplikasi MPI Anda yang digabungkan dengan ketat melakukan komunikasi kolektif dalam jumlah berlebihan, Anda dapat mencoba mengaktifkan kolektif hierarkis (HCOLL). Untuk mengaktifkan fitur tersebut, gunakan parameter berikut.
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Catatan
Dengan HPC-X 2.7.4+, mungkin perlu untuk secara eksplisit lulus LD_LIBRARY_PATH jika versi UCX pada MOFED vs. yang di HPC-X berbeda.
OpenMPI
Pasang UCX seperti yang dijelaskan di atas. HCOLL adalah bagian dari toolkit perangkat lunak HPC-X dan tidak memerlukan penginstalan khusus.
OpenMPI dapat dipasang dari paket yang tersedia di repo.
sudo yum install –y openmpi
Sebaiknya bangun OpenMPI terbaru yang stabil dengan UCX.
OMPI_VERSION="4.0.3"
OMPI_DOWNLOAD_URL=https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-${OMPI_VERSION}.tar.gz
wget --retry-connrefused --tries=3 --waitretry=5 $OMPI_DOWNLOAD_URL
tar -xvf openmpi-${OMPI_VERSION}.tar.gz
cd openmpi-${OMPI_VERSION}
./configure --prefix=${INSTALL_PREFIX}/openmpi-${OMPI_VERSION} --with-ucx=${UCX_PATH} --with-hcoll=${HCOLL_PATH} --enable-mpirun-prefix-by-default --with-platform=contrib/platform/mellanox/optimized && make -j$(nproc) && make install
Untuk kinerja optimal, jalankan OpenMPI dengan ucx dan hcoll. Lihat juga contohnya dengan HPC-X.
${INSTALL_PREFIX}/bin/mpirun -np 2 --map-by node --hostfile ~/hostfile -mca pml ucx --mca btl ^vader,tcp,openib -x UCX_NET_DEVICES=mlx5_0:1 -x UCX_IB_PKEY=0x0003 ./osu_latency
Periksa kunci partisi Anda seperti disebutkan di atas.
Intel MPI
Unduh versi intel MPI pilihan Anda. Rilis Intel MPI 2019 beralih dari kerangka kerja Open Fabrics Alliance (OFA) ke kerangka kerja Open Fabrics Interfaces (OFI), dan saat ini mendukung libfabric. Ada dua penyedia untuk dukungan InfiniBand: mlx dan kata kerja. Ubah variabel I_MPI_FABRICS tergantung pada versinya.
- Intel MPI 2019 dan 2021: gunakan
I_MPI_FABRICS=shm:ofi,I_MPI_OFI_PROVIDER=mlx.mlxPenyedia menggunakan UCX. Penggunaan kata kerja telah ditemukan tidak stabil dan kurang berperforma. Lihat artikel TechCommunity untuk info lebih lengkap. - Intel MPI 2018: gunakan
I_MPI_FABRICS=shm:ofa - Intel MPI 2016: gunakan
I_MPI_DAPL_PROVIDER=ofa-v2-ib0
Berikut adalah beberapa argumen mpirun yang disarankan untuk Intel MPI 2019 update 5+.
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
di mana:
| Parameter | Deskripsi |
|---|---|
FI_PROVIDER |
Menentukan penyedia libfabric mana yang akan digunakan, yang akan mempengaruhi API, protokol, dan jaringan yang digunakan. kata kerja adalah pilihan lain, tetapi umumnya campuran memberi Anda performa yang lebih baik. |
I_MPI_DEBUG |
Menentukan tingkat output debug ekstra, yang dapat memberikan detail tentang di mana proses disematkan, dan protokol dan jaringan mana yang digunakan. |
I_MPI_PIN_DOMAIN |
Menentukan bagaimana Anda ingin menyematkan proses Anda. Misalnya, Anda dapat menyematkan ke core, soket, atau domain NUMA. Dalam contoh ini, Anda mengatur variabel lingkungan ini ke numa, yang berarti proses akan disematkan ke domain simpul NUMA. |
Mengoptimalkan kolektif MPI
Ada beberapa opsi lain yang dapat Anda coba, terutama jika operasi kolektif memakan waktu yang signifikan. Intel MPI 2019 update 5+ mendukung mlx yang tersedia dan menggunakan kerangka kerja UCX untuk berkomunikasi dengan InfiniBand. Ini juga mendukung HCOLL.
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
VM Non SR-IOV
Untuk VM non SR-IOV, contoh pengunduhan versi evaluasi gratis runtime 5.x adalah sebagai berikut:
wget http://registrationcenter-download.intel.com/akdlm/irc_nas/tec/9278/l_mpi_p_5.1.3.223.tgz
Untuk langkah-langkah penginstalan, lihat Panduan Instalasi Perpustakaan Intel MPI. Secara opsional, Anda mungkin ingin mengaktifkan ptrace untuk proses non-debugger non-root (diperlukan untuk versi terbaru Intel MPI).
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
Linux SUSE
Untuk versi gambar SUSE Linux Enterprise Server VM - SLES 12 SP3 untuk HPC, SLES 12 SP3 untuk HPC (Premium), SLES 12 SP1 untuk HPC, SLES 12 SP1 untuk HPC (Premium), SLES 12 SP4 dan SLES 15, driver RDMA diinstal dan paket Intel MPI didistribusikan pada VM. Instal Intel MPI dengan menjalankan perintah berikut:
sudo rpm -v -i --nodeps /opt/intelMPI/intel_mpi_packages/*.rpm
MVAPICH
Berikut ini adalah contoh membangun MVAPICH2. Perhatikan versi yang lebih baru mungkin tersedia daripada yang digunakan di bawah ini.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/mv2/mvapich2-2.3.tar.gz
tar -xv mvapich2-2.3.tar.gz
cd mvapich2-2.3
./configure --prefix=${INSTALL_PREFIX}
make -j 8 && make install
Contoh menjalankan tolok ukur mikro latensi OSU adalah sebagai berikut:
${INSTALL_PREFIX}/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=48 ./osu_latency
Daftar berikut ini berisi beberapa argumen mpirun yang direkomendasikan.
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
di mana:
| Parameter | Deskripsi |
|---|---|
MV2_CPU_BINDING_POLICY |
Menentukan kebijakan pengikatan mana yang akan digunakan, yang akan mempengaruhi bagaimana proses disematkan ke ID core. Dalam hal ini, Anda menentukan scatter, sehingga proses tersebar merata di antara domain NUMA. |
MV2_CPU_BINDING_LEVEL |
Menentukan di mana harus menyematkan proses. Dalam hal ini, Anda mengaturnya ke numanoda, yang berarti proses disematkan ke unit domain NUMA. |
MV2_SHOW_CPU_BINDING |
Menentukan apakah Anda ingin mendapatkan informasi debug tentang di mana proses disematkan. |
MV2_SHOW_HCA_BINDING |
Menentukan apakah Anda ingin mendapatkan informasi debug tentang adaptor saluran host mana yang digunakan setiap proses. |
MPI Platform
Instal paket yang diperlukan untuk Platform MPI Edisi Komunitas.
sudo yum install libstdc++.i686
sudo yum install glibc.i686
Download platform MPI at https://www.ibm.com/developerworks/downloads/im/mpi/index.html
sudo ./platform_mpi-09.01.04.03r-ce.bin
Ikuti proses penginstalan.
MPICH
Pasang UCX seperti yang dijelaskan di atas. Bangun MPICH.
wget https://www.mpich.org/static/downloads/3.3/mpich-3.3.tar.gz
tar -xvf mpich-3.3.tar.gz
cd mpich-3.3
./configure --with-ucx=${UCX_PATH} --prefix=${INSTALL_PREFIX} --with-device=ch4:ucx
make -j 8 && make install
Menjalankan MPICH.
${INSTALL_PREFIX}/bin/mpiexec -n 2 -hostfile ~/hostfile -env UCX_IB_PKEY=0x0003 -bind-to hwthread ./osu_latency
Periksa kunci partisi Anda seperti disebutkan di atas.
Tolok Ukur OSU MPI
Unduh Tolok Ukur OSU MPI dan untar.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.5.tar.gz
tar –xvf osu-micro-benchmarks-5.5.tar.gz
cd osu-micro-benchmarks-5.5
Buat Tolok Ukur menggunakan pustake MPI tertentu:
CC=<mpi-install-path/bin/mpicc>CXX=<mpi-install-path/bin/mpicxx> ./configure
make
Tolok Ukur MPI berada di bawah mpi/ folder.
Temukan tombol partisi
Temukan tombol partisi (p-key) untuk berkomunikasi dengan VM lain dalam penyewa yang sama (Set Ketersediaan atau Set Skala Komputer Virtual).
/sys/class/infiniband/mlx5_0/ports/1/pkeys/0
/sys/class/infiniband/mlx5_0/ports/1/pkeys/1
Yang lebih besar dari keduanya adalah kunci penyewa yang harus digunakan dengan MPI. Contoh: Jika berikut ini adalah tombol p, 0x800b harus digunakan dengan MPI.
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/0
0x800b
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/1
0x7fff
Antarmuka catatan dinamai seperti mlx5_ib* di dalam gambar HPC VM.
Perhatikan juga bahwa selama penyewa (Set Ketersediaan atau Set Skala Komputer Virtual) ada, PKEYs tetap sama. Ini benar bahkan ketika node ditambahkan/dihapus. Penyewa baru mendapatkan PKEY yang berbeda.
Menyiapkan batas pengguna untuk MPI
Menyiapkan batas pengguna untuk MPI.
cat << EOF | sudo tee -a /etc/security/limits.conf
* hard memlock unlimited
* soft memlock unlimited
* hard nofile 65535
* soft nofile 65535
EOF
Menyiapkan kunci SSH untuk MPI
Siapkan kunci SSH untuk jenis MPI yang memerlukannya.
ssh-keygen -f /home/$USER/.ssh/id_rsa -t rsa -N ''
cat << EOF > /home/$USER/.ssh/config
Host *
StrictHostKeyChecking no
EOF
cat /home/$USER/.ssh/id_rsa.pub >> /home/$USER/.ssh/authorized_keys
chmod 600 /home/$USER/.ssh/authorized_keys
chmod 644 /home/$USER/.ssh/config
Sintaks di atas mengasumsikan direktori rumah bersama, direktori lain .ssh harus disalin ke setiap simpul.
Langkah berikutnya
- Pelajari tentang VM seri HB dan seri N yang diaktifkanInfiniBand.
- Tinjau gambaran umum seri-HBv3 dan gambaran umum seri-HC.
- Baca Penempatan proses MPI yang optimal untuk VM seri HB.
- Membaca tentang pengumuman terbaru, contoh beban kerja HPC, dan hasil performa di Blog Komunitas Teknologi Azure Compute.
- Untuk tampilan arsitektur tingkat yang lebih tinggi dari beban kerja HPC yang berjalan, lihat Komputasi Kinerja Tinggi (HPC) pada Azure.