Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menunjukkan cara men-debug aplikasi yang menggunakan C++ Accelerated Massive Parallelism (C++ AMP) untuk memanfaatkan unit pemrosesan grafis (GPU). Ini menggunakan program pengurangan paralel yang menjumlahkan sejumlah besar bilangan bulat. Panduan ini mengilustrasikan tugas-tugas berikut:
- Meluncurkan debugger GPU.
- Memeriksa utas GPU di jendela Utas GPU.
- Menggunakan jendela Parallel Stacks untuk mengamati tumpukan panggilan dari beberapa utas GPU secara bersamaan.
- Menggunakan jendela Parallel Watch untuk memeriksa nilai ekspresi tunggal di beberapa utas secara bersamaan.
- Menandai, membekukan, mencairkan, dan mengelompokkan utas GPU.
- Menjalankan semua utas petak menuju lokasi tertentu dalam kode.
Prasyarat
Sebelum Anda memulai panduan ini:
Nota
Header AMP C++ tidak digunakan lagi dimulai dengan Visual Studio 2022 versi 17.0.
Menyertakan header AMP apa pun akan menghasilkan kesalahan build. Tentukan _SILENCE_AMP_DEPRECATION_WARNINGS sebelum menyertakan header AMP apa pun untuk membungkam peringatan.
- Baca Gambaran Umum C++ AMP.
- Pastikan nomor baris ditampilkan di editor teks. Untuk informasi selengkapnya, lihat Cara: Menampilkan nomor baris di editor.
- Pastikan Anda menggunakan minimal Windows 8 atau Windows Server 2012 untuk mendukung debugging pada emulator perangkat lunak.
Nota
Komputer Anda mungkin menampilkan nama atau lokasi yang berbeda untuk beberapa elemen antarmuka pengguna Visual Studio dalam instruksi berikut. Edisi Visual Studio yang Anda miliki dan pengaturan yang Anda gunakan menentukan elemen-elemen ini. Untuk informasi selengkapnya, lihat Mempersonalisasi IDE.
Untuk membuat proyek sampel
Instruksi untuk membuat proyek bervariasi tergantung pada versi Visual Studio mana yang Anda gunakan. Pastikan Anda memiliki versi dokumentasi yang benar yang dipilih di atas daftar isi pada halaman ini.
Untuk membuat proyek sampel di Visual Studio
Pada bilah menu, pilih File>New>Project untuk membuka kotak dialog Create a New Project.
Di bagian atas dialog, atur Bahasa ke C++, atur Platform ke Windows, dan atur jenis Project ke Konsol.
Dari daftar jenis proyek yang difilter, pilih Aplikasi Konsol lalu pilih Berikutnya. Di halaman berikutnya, masukkan
AMPMapReducedi kotak Nama untuk menentukan nama proyek, dan tentukan lokasi proyek jika Anda menginginkan yang berbeda.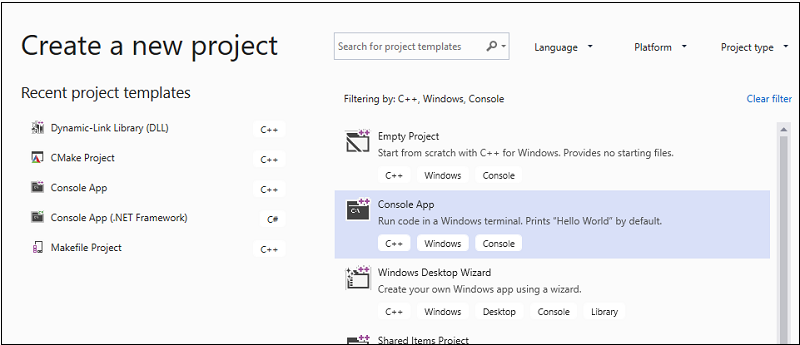
Pilih tombol Buat untuk membuat proyek klien.
Berikutnya:
Buka AMPMapReduce.cpp dan ganti kontennya dengan kode berikut.
// AMPMapReduce.cpp defines the entry point for the program. // The program performs a parallel-sum reduction that computes the sum of an array of integers. #include <stdio.h> #include <tchar.h> #include <amp.h> const int BLOCK_DIM = 32; using namespace concurrency; void sum_kernel_tiled(tiled_index<BLOCK_DIM> t_idx, array<int, 1> &A, int stride_size) restrict(amp) { tile_static int localA[BLOCK_DIM]; index<1> globalIdx = t_idx.global * stride_size; index<1> localIdx = t_idx.local; localA[localIdx[0]] = A[globalIdx]; t_idx.barrier.wait(); // Aggregate all elements in one tile into the first element. for (int i = BLOCK_DIM / 2; i > 0; i /= 2) { if (localIdx[0] < i) { localA[localIdx[0]] += localA[localIdx[0] + i]; } t_idx.barrier.wait(); } if (localIdx[0] == 0) { A[globalIdx] = localA[0]; } } int size_after_padding(int n) { // The extent might have to be slightly bigger than num_stride to // be evenly divisible by BLOCK_DIM. You can do this by padding with zeros. // The calculation to do this is BLOCK_DIM * ceil(n / BLOCK_DIM) return ((n - 1) / BLOCK_DIM + 1) * BLOCK_DIM; } int reduction_sum_gpu_kernel(array<int, 1> input) { int len = input.extent[0]; //Tree-based reduction control that uses the CPU. for (int stride_size = 1; stride_size < len; stride_size *= BLOCK_DIM) { // Number of useful values in the array, given the current // stride size. int num_strides = len / stride_size; extent<1> e(size_after_padding(num_strides)); // The sum kernel that uses the GPU. parallel_for_each(extent<1>(e).tile<BLOCK_DIM>(), [&input, stride_size] (tiled_index<BLOCK_DIM> idx) restrict(amp) { sum_kernel_tiled(idx, input, stride_size); }); } array_view<int, 1> output = input.section(extent<1>(1)); return output[0]; } int cpu_sum(const std::vector<int> &arr) { int sum = 0; for (size_t i = 0; i < arr.size(); i++) { sum += arr[i]; } return sum; } std::vector<int> rand_vector(unsigned int size) { srand(2011); std::vector<int> vec(size); for (size_t i = 0; i < size; i++) { vec[i] = rand(); } return vec; } array<int, 1> vector_to_array(const std::vector<int> &vec) { array<int, 1> arr(vec.size()); copy(vec.begin(), vec.end(), arr); return arr; } int _tmain(int argc, _TCHAR* argv[]) { std::vector<int> vec = rand_vector(10000); array<int, 1> arr = vector_to_array(vec); int expected = cpu_sum(vec); int actual = reduction_sum_gpu_kernel(arr); bool passed = (expected == actual); if (!passed) { printf("Actual (GPU): %d, Expected (CPU): %d", actual, expected); } printf("sum: %s\n", passed ? "Passed!" : "Failed!"); getchar(); return 0; }Pada bilah menu, pilih File>Simpan Semua.
Di Penjelajah Solusi, buka menu pintasan untuk AMPMapReduce, lalu pilih Properti.
Dalam kotak dialog Halaman Properti, di bawah Properti Konfigurasi, pilih C/C++>Header yang Telah Dikompilasi Sebelumnya.
Untuk properti Header yang Telah Dikompilasi sebelumnya, pilih Tidak Menggunakan Header yang Telah Dikompilasi sebelumnya, lalu pilih tombol OK.
Pada bilah menu, pilih Bangun>Bangun Solusi.
Melakukan debugging Kode CPU
Dalam prosedur ini, Anda akan menggunakan Local Windows Debugger untuk memastikan bahwa kode CPU dalam aplikasi ini sudah benar. Segmen kode CPU dalam aplikasi ini yang sangat menarik adalah loop for dalam fungsi reduction_sum_gpu_kernel. Ini mengontrol pengurangan paralel berbasis pohon yang dijalankan pada GPU.
Untuk men-debug kode CPU
Di Penjelajah Solusi, buka menu pintasan untuk AMPMapReduce, lalu pilih Properti.
Dalam kotak dialog Halaman Properti, di bawah Properti Konfigurasi, pilih Debugging. Verifikasi bahwa Local Windows Debugger dipilih di daftar Debugger yang akan diluncurkan.
Kembali ke Editor Kode.
Atur titik henti pada baris kode yang diperlihatkan dalam ilustrasi berikut (sekitar baris 67 baris 70).

Titik henti pemrosesan CPUPada bilah menu, pilih Debug>Mulai Debugging.
Di jendela Lokal, amati nilai untuk
stride_sizehingga titik henti pada baris 70 tercapai.Pada bilah menu, pilih Debug>Hentikan Debug.
Melacak Kesalahan Kode GPU
Bagian ini menunjukkan cara men-debug kode GPU, yang merupakan kode yang terkandung dalam sum_kernel_tiled fungsi . Kode GPU menghitung jumlah bilangan bulat untuk setiap "blok" secara paralel.
Untuk men-debug kode GPU
Di Penjelajah Solusi, buka menu pintasan untuk AMPMapReduce, lalu pilih Properti.
Dalam kotak dialog Halaman Properti, di bawah Properti Konfigurasi, pilih Debugging.
Di daftar Debugger yang akan diluncurkan, pilih Debugger Windows Lokal.
Di daftar Jenis Debugger, verifikasi bahwa Otomatis dipilih.
Otomatis adalah nilai default. Dalam versi sebelum Windows 10, GPU Saja adalah nilai yang diperlukan alih-alih Otomatis.
Pilih tombol OK.
Atur titik henti di baris 30, seperti yang diperlihatkan dalam ilustrasi berikut.

Titik pemberhentian GPUPada bilah menu, pilih Debug>Mulai Debugging. Titik henti dalam kode CPU pada baris 67 dan 70 tidak dieksekusi selama penelusuran kesalahan GPU karena baris kode tersebut berjalan pada CPU.
Untuk menggunakan jendela Thread GPU
Untuk membuka jendela Utas GPU, pada bilah menu, pilih Debug>, Windows>, Utas GPU.
Anda dapat memeriksa status utas GPU di jendela Utas GPU yang muncul.
Dock jendela Threads GPU di bagian bawah Visual Studio. Pilih tombol Perluas Sakelar Utas untuk menampilkan kotak teks tile dan utas. Jendela Utas GPU menampilkan jumlah total utas GPU yang aktif dan yang diblokir, sebagaimana ditunjukkan pada ilustrasi berikut.

Jendela Utas GPU313 petak dialokasikan untuk komputasi ini. Setiap ubin berisi 32 utas. Karena penelusuran kesalahan GPU lokal terjadi pada emulator perangkat lunak, ada empat utas GPU aktif. Empat utas menjalankan instruksi secara bersamaan dan kemudian melanjutkan bersama-sama ke instruksi berikutnya.
Di jendela Utas GPU, ada empat utas GPU aktif dan 28 utas GPU yang diblokir di pernyataan tile_barrier::wait yang ditentukan pada sekitar baris 21 (
t_idx.barrier.wait();). Semua 32 utas GPU termasuk dalam petak pertama,tile[0]. Panah menunjuk ke baris yang memuat utas saat ini. Untuk beralih ke utas yang berbeda, gunakan salah satu metode berikut:Di baris untuk utas yang akan dialihkan di jendela Utas GPU, buka menu pintasan dan pilih Beralih Ke Utas. Jika baris mewakili lebih dari satu utas, Anda akan beralih ke utas pertama sesuai dengan koordinat utas.
Masukkan nilai ubin dan utas utas dalam kotak teks terkait lalu pilih tombol Alihkan Utas .
Jendela Call Stack menampilkan stack panggilan dari utas GPU saat ini.
Untuk menggunakan jendela Tumpukan Paralel
Untuk membuka jendela Parallel Stacks, pada bilah menu, pilih Debug>Windows>Parallel Stacks.
Anda dapat menggunakan jendela Parallel Stacks untuk secara bersamaan memeriksa bingkai tumpukan dari beberapa utas GPU.
Dock jendela Parallel Stacks di bagian bawah Visual Studio.
Pastikan bahwa Utas dipilih dalam daftar di sudut kiri atas. Dalam ilustrasi berikut, jendela Tumpukan Paralel memperlihatkan tampilan yang berfokus pada tumpukan panggilan dari utas GPU, seperti yang Anda lihat di jendela Utas GPU.

Jendela Tumpukan Paralel32 utas berpindah dari
_kernel_stubke pernyataan lambda dalam panggilan fungsiparallel_for_eachdan kemudian kesum_kernel_tiledfungsi, di mana pengurangan paralel terjadi. 28 dari 32 utas telah maju ke pernyataantile_barrier::waitdan tetap diblokir pada baris 22, sementara empat utas lainnya tetap aktif pada fungsisum_kernel_tileddi baris 30.Anda dapat memeriksa properti utas GPU. Mereka tersedia di jendela Utas GPU di Tip Data kaya jendela Tumpukan Paralel. Untuk melihatnya, arahkan penunjuk ke bingkai tumpukan
sum_kernel_tiled. Ilustrasi berikut menunjukkan DataTip.
Keterangan Data Utas GPUUntuk informasi selengkapnya tentang jendela Tumpukan Paralel, lihat Menggunakan Jendela Tumpukan Paralel.
Untuk menggunakan jendela Parallel Watch
Untuk membuka jendela Parallel Watch, pada bilah menu, pilih Debug>Windows>Parallel Watch 1.
Anda dapat menggunakan jendela Parallel Watch untuk memeriksa nilai ekspresi di beberapa utas.
Dock jendela Parallel Watch 1 ke bagian bawah Visual Studio. Ada 32 baris dalam tabel jendela Parallel Watch . Masing-masing sesuai dengan utas GPU yang muncul di jendela Utas GPU dan jendela Paralel Stacks. Sekarang, Anda dapat memasukkan ekspresi yang nilainya ingin Anda periksa di semua 32 utas GPU.
Pilih header tambahkan kolom Watch, masukkan
localIdx, lalu pilih tombol Enter.Pilih header kolom Tambahkan Watch lagi, ketik
globalIdx, lalu pilih tombol Enter.Pilih header kolom Tambahkan Watch lagi, ketik
localA[localIdx[0]], lalu pilih tombol Enter.Anda dapat mengurutkan menurut ekspresi tertentu dengan memilih header kolom yang sesuai.
Pilih judul kolom localA[localIdx[0]] untuk mengurutkan kolom. Ilustrasi berikut menunjukkan hasil pengurutan menurut localA[localIdx[0]].

Hasil pengurutanAnda bisa mengekspor konten di jendela Parallel Watch ke Excel dengan memilih tombol Excel lalu memilih Buka di Excel. Jika Anda memiliki Excel yang terinstal di komputer pengembangan Anda, tombol akan membuka lembar kerja Excel yang berisi isi.
Di sudut kanan atas jendela Parallel Watch , ada kontrol filter yang dapat Anda gunakan untuk memfilter konten dengan menggunakan ekspresi Boolean. Masukkan
localA[localIdx[0]] > 20000dalam kotak teks kontrol filter lalu pilih tombol Enter .Jendela sekarang hanya berisi utas di mana nilai
localA[localIdx[0]]melebihi 20000. Konten masih diurutkan menurutlocalA[localIdx[0]]kolom, yang merupakan tindakan pengurutan yang Anda pilih sebelumnya.
Menandai Utas GPU
Anda dapat menandai utas GPU tertentu dengan menandainya di jendela Utas GPU, jendela Parallel Watch , atau DataTip di jendela Tumpukan Paralel. Jika baris di jendela Utas GPU berisi lebih dari satu utas, menandai baris tersebut menandai semua utas yang terkandung dalam baris.
Untuk menandai utas GPU
Pilih header kolom [Utas] di jendela Parallel Watch 1 untuk mengurutkan menurut indeks petak peta dan indeks utas.
Pada bilah menu, pilih Debug>Lanjutkan, yang membuat empat thread yang sedang aktif bergerak ke hambatan berikutnya (didefinisikan pada baris 32 AMPMapReduce.cpp).
Pilih simbol bendera di sisi kiri baris yang berisi empat utas yang sekarang aktif.
Ilustrasi berikut menunjukkan empat utas aktif yang ditandai di jendela Utas GPU.

Thread aktif di jendela Thread GPUJendela Parallel Watch dan jendela Parallel Stacks DataTip keduanya menunjukkan utas yang ditandai.
Jika Anda ingin fokus pada empat utas yang Anda tandai, Anda dapat memilih untuk hanya menampilkan utas yang ditandai. Ini membatasi apa yang Anda lihat di GPU Threads, Parallel Watch, dan Parallel Stacks window.
Pilih tombol Perlihatkan Hanya yang Ditandai di salah satu jendela atau pada toolbar Debug Location. Berikut adalah ilustrasi tombol Tampilkan Hanya yang Ditandai pada toolbar Debug Lokasi.

Tampilkan Hanya yang DitandaiSekarang jendela Utas GPU, Parallel Watch, dan Parallel Stacks hanya menampilkan utas yang ditandai.
Pembekuan dan Pencairan Utas GPU
Anda dapat membekukan (menangguhkan) dan mencairkan (melanjutkan) utas GPU dari jendela Utas GPU atau jendela Parallel Watch. Anda dapat membekukan dan mencairkan utas prosesor dengan cara yang sama; untuk informasi, lihat Cara: Menggunakan Jendela Utas.
Untuk membekukan dan mencairkan utas GPU
Pilih tombol Perlihatkan Yang Ditandai Saja untuk menampilkan semua utas.
Pada bilah menu, pilih Debug>Lanjutkan.
Buka menu pintasan untuk baris aktif lalu pilih Bekukan.
Ilustrasi jendela Utas GPU berikut menunjukkan bahwa keempat utas dibekukan.

Utas beku di jendela Utas GPUDemikian juga, jendela Parallel Watch menunjukkan bahwa keempat utas dibekukan.
Pada bilah menu, pilih Debug>Lanjutkan untuk memungkinkan empat utas GPU berikutnya untuk maju melewati pembatas pada baris 22 dan untuk mencapai titik henti pada baris 30. Jendela Utas GPU menunjukkan bahwa empat utas yang sebelumnya dibekukan tetap beku dan dalam keadaan aktif.
Pada bilah menu, pilih Debug, Lanjutkan.
Dari jendela Parallel Watch, Anda juga dapat mengaktifkan kembali utas GPU secara individual atau lebih dari satu.
Untuk mengelompokkan utas GPU
Pada menu pintasan untuk salah satu utas di jendela Utas GPU, pilih Kelompokkan Menurut, Alamat.
Utas di jendela Utas GPU dikelompokkan menurut alamat. Alamat sesuai dengan instruksi dalam pembongkaran tempat setiap grup utas berada. 24 utas berada pada baris 22 tempat method tile_barrier::wait dieksekusi. 12 thread menjalankan instruksi pada barrier di baris 32. Empat utas ini ditandai. Delapan utas berada di titik henti pada baris 30. Empat utas ini dibekukan. Ilustrasi berikut menunjukkan utas yang dikelompokkan di jendela Utas GPU.

Utas yang dikelompokkan di jendela Utas GPUAnda juga dapat melakukan operasi Kelompokkan Menurut dengan membuka menu pintasan untuk kisi data jendela Parallel Watch . Pilih Kelompokkan Menurut, lalu pilih item menu yang sesuai dengan cara Anda ingin mengelompokkan threads.
Menjalankan Semua Utas ke Lokasi Tertentu di dalam Kode
Anda menjalankan semua utas dalam petak peta tertentu ke baris yang berisi kursor dengan menggunakan Jalankan Petak Peta Saat Ini Ke Kursor.
Untuk menjalankan semua thread ke lokasi yang ditandai oleh kursor
Pada menu pintasan untuk utas beku, pilih Cairkan.
Di Editor kode, letakkan kursor di baris 30.
Pada menu pintasan untuk Editor Kode, pilih Jalankan Kode Sekarang Ke Kursor.
24 utas yang sebelumnya diblokir pada penghalang di baris 21 telah maju ke baris 32. Ini ditampilkan di jendela GPU Threads.
Baca juga
Gambaran umum C++ AMP
Debugging kode GPU
Cara Menggunakan Jendela Utas GPU
Cara: Menggunakan jendela Parallel Watch
Menganalisis kode AMP C++ dengan Concurrency Visualizer