Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Shift right adalah praktik memindahkan beberapa pengujian nanti dalam proses DevOps untuk diuji dalam produksi. Pengujian dalam produksi menggunakan penyebaran nyata untuk memvalidasi dan mengukur perilaku dan performa aplikasi di lingkungan produksi.
Salah satu cara tim DevOps dapat meningkatkan kecepatan adalah dengan strategi uji shift-left . Shift left mendorong sebagian besar pengujian sebelumnya di alur DevOps, untuk mengurangi jumlah waktu kode baru untuk mencapai produksi dan beroperasi dengan andal.
Tetapi meskipun banyak jenis pengujian, seperti pengujian unit, dapat dengan mudah bergeser ke kiri, beberapa kelas pengujian tidak dapat berjalan tanpa menyebarkan sebagian atau semua solusi. Menyebarkan ke QA atau layanan penahapan dapat mensimulasikan lingkungan yang sebanding, tetapi tidak ada pengganti penuh untuk lingkungan produksi. Teams menemukan bahwa jenis pengujian tertentu perlu terjadi dalam produksi.
Pengujian dalam produksi menyediakan:
- Luas penuh dan keragaman lingkungan produksi.
- Beban kerja nyata lalu lintas pelanggan.
- Profil dan perilaku saat permintaan produksi berevolusi dari waktu ke waktu.
Lingkungan produksi terus berubah. Bahkan jika aplikasi tidak berubah, infrastruktur yang diandalkannya terus-menerus berubah. Pengujian dalam produksi memvalidasi kesehatan dan kualitas penyebaran produksi tertentu dan lingkungan produksi yang terus berubah.
Mengalihkan hak untuk menguji dalam produksi sangat penting untuk skenario berikut:
Penyebaran layanan mikro
Solusi berbasis layanan mikro dapat memiliki sejumlah besar layanan mikro yang dikembangkan, disebarkan, dan dikelola secara independen. Menggeser hak pengujian sangat penting untuk proyek-proyek ini, karena versi dan konfigurasi yang berbeda dapat mencapai produksi dalam banyak cara. Terlepas dari cakupan pengujian pra-produksi, perlu untuk menguji kompatibilitas dalam produksi.
Memastikan kualitas pasca-penyebaran
Merilis ke produksi hanya setengah dari pengiriman perangkat lunak. Setengah lainnya memastikan kualitas dalam skala besar dengan beban kerja nyata dalam produksi. Karena lingkungan terus berubah, tim tidak pernah dilakukan dengan pengujian dalam produksi.
Data pengujian dari produksi secara harfiah adalah hasil pengujian dari beban kerja pelanggan nyata. Pengujian dalam produksi mencakup pemantauan, pengujian failover, dan injeksi kesalahan. Pengujian ini melacak kegagalan, pengecualian, metrik performa, dan peristiwa keamanan. Telemetri pengujian juga membantu mendeteksi anomali.
Tingkat penyebaran
Untuk melindungi lingkungan produksi, tim dapat meluncurkan perubahan dengan cara yang progresif dan terkontrol dengan menggunakan penyebaran berbasis tingkat dan bendera fitur. Misalnya, lebih baik menangkap bug yang mencegah pembeli menyelesaikan pembelian mereka ketika kurang dari 1% pelanggan berada di tingkat penyebaran itu, daripada setelah mengalihkan semua pelanggan sekaligus. Nilai fitur dengan kegagalan yang terdeteksi harus melebihi kerugian bersih dari kegagalan tersebut, diukur dengan cara yang bermakna untuk bisnis tertentu.
Tingkat pertama harus menjadi ukuran terkecil yang diperlukan untuk menjalankan rangkaian integrasi standar. Pengujian mungkin mirip dengan yang sudah berjalan sebelumnya di alur terhadap lingkungan lain, tetapi pengujian memvalidasi bahwa perilakunya sama di lingkungan produksi. Tingkat ini mengidentifikasi kesalahan yang jelas, seperti kesalahan konfigurasi, sebelum berdampak pada pelanggan mana pun.
Setelah tingkat awal divalidasi, tingkat berikutnya dapat diperluas untuk menyertakan subset pengguna nyata untuk uji coba. Jika semuanya terlihat baik, penyebaran dapat berkembang melalui tingkatan dan pengujian lebih lanjut sampai semua orang menggunakannya. Penyebaran penuh tidak berarti bahwa pengujian berakhir. Melacak telemetri sangat penting untuk pengujian dalam produksi.
Injeksi kesalahan
Tim sering menggunakan injeksi kesalahan dan rekayasa kekacauan untuk melihat bagaimana sistem berulah dalam kondisi kegagalan. Praktik ini membantu:
- Validasi bahwa mekanisme ketahanan yang diterapkan benar-benar berfungsi.
- Validasi bahwa kegagalan dalam satu subsistem terkandung dalam subsistem tersebut dan tidak berjenjang untuk menghasilkan pemadaman besar.
- Buktikan bahwa pekerjaan perbaikan untuk insiden sebelumnya memiliki efek yang diinginkan, tanpa harus menunggu insiden lain terjadi.
- Buat latihan pelatihan yang lebih realistis untuk teknisi situs langsung sehingga mereka dapat mempersiapkan diri dengan lebih baik untuk menangani insiden.
Ini adalah praktik yang baik untuk mengotomatiskan eksperimen injeksi kesalahan, karena mereka adalah tes mahal yang harus berjalan pada sistem yang terus berubah.
Rekayasa chaos dapat menjadi alat yang efektif, tetapi harus terbatas pada lingkungan kenari yang memiliki sedikit atau tanpa dampak pelanggan.
Pengujian failover
Salah satu bentuk injeksi kesalahan adalah pengujian failover untuk mendukung kelangsungan bisnis dan pemulihan bencana (BCDR). Teams harus memiliki rencana failover untuk semua layanan dan subsistem. Paket harus mencakup:
- Penjelasan yang jelas tentang dampak bisnis dari layanan yang turun.
- Peta semua dependensi dalam hal platform, teknologi, dan orang yang menyusun rencana BCDR.
- Dokumentasi formal prosedur pemulihan bencana.
- Irama untuk secara teratur menjalankan latihan pemulihan bencana.
Pengujian kesalahan pemutus sirkuit
Mekanisme pemutus arus memotong komponen tertentu dari sistem yang lebih besar, biasanya untuk mencegah kegagalan dalam komponen tersebut menyebar di luar batas-batasnya. Anda dapat dengan sengaja memicu pemutus arus untuk menguji skenario berikut:
Apakah fallback berfungsi saat pemutus sirkuit terbuka. Fallback mungkin bekerja dengan pengujian unit, tetapi satu-satunya cara untuk mengetahui apakah itu akan bertingkah seperti yang diharapkan dalam produksi adalah dengan menyuntikkan kesalahan untuk memicunya.
Apakah pemutus sirkuit memiliki ambang sensitivitas yang tepat untuk dibuka ketika perlu. Injeksi kesalahan dapat memaksa latensi atau memutuskan dependensi untuk mengamati responsivitas pemutus. Penting untuk memverifikasi bahwa perilaku yang benar tidak hanya terjadi, tetapi juga terjadi dengan cukup cepat.
Contoh: Menguji pemutus sirkuit cache Redis
Cache Redis meningkatkan performa produk dengan mempercepat akses ke data yang umum digunakan. Pertimbangkan skenario yang mengambil dependensi non-kritis pada Redis. Jika Redis tidak berfungsi, sistem harus terus berfungsi, karena dapat kembali menggunakan sumber data asli untuk permintaan. Untuk mengonfirmasi bahwa kegagalan Redis memicu pemutus sirkuit dan bahwa fallback berfungsi dalam produksi, jalankan pengujian secara berkala terhadap perilaku ini.
Diagram berikut menunjukkan pengujian untuk perilaku fallback pemutus sirkuit Redis. Tujuannya adalah untuk memastikan bahwa ketika pemutus terbuka, panggilan pada akhirnya masuk ke SQL.
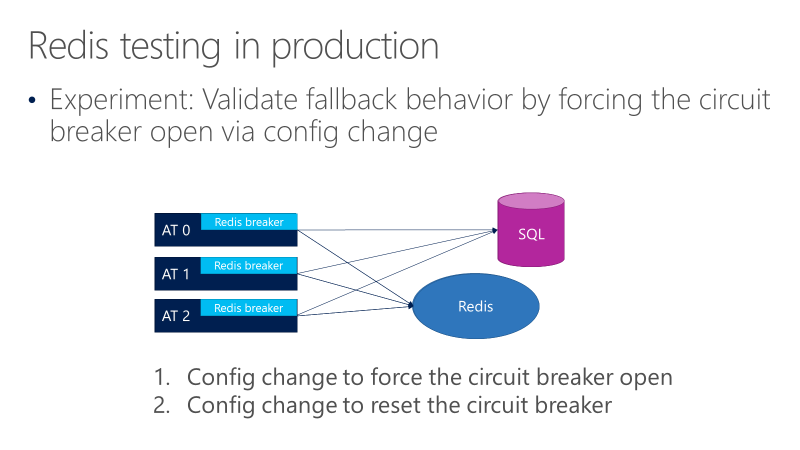
Diagram sebelumnya menunjukkan tiga ATs, dengan pemecah di depan panggilan ke Redis. Satu pengujian memaksa pemutus sirkuit untuk membuka melalui perubahan konfigurasi, dan kemudian mengamati apakah panggilan masuk ke SQL. Pengujian lain kemudian memeriksa perubahan konfigurasi yang berlawanan, dengan menutup pemutus sirkuit untuk mengonfirmasi bahwa panggilan kembali ke Redis.
Pengujian ini memvalidasi bahwa perilaku fallback berfungsi saat pemutus terbuka, tetapi tidak memvalidasi bahwa konfigurasi pemutus sirkuit membuka pemutus kapan harus. Menguji perilaku tersebut memerlukan simulasi kegagalan aktual.
Agen kesalahan dapat memperkenalkan kesalahan dalam panggilan masuk ke Redis. Diagram berikut menunjukkan pengujian dengan injeksi kesalahan.
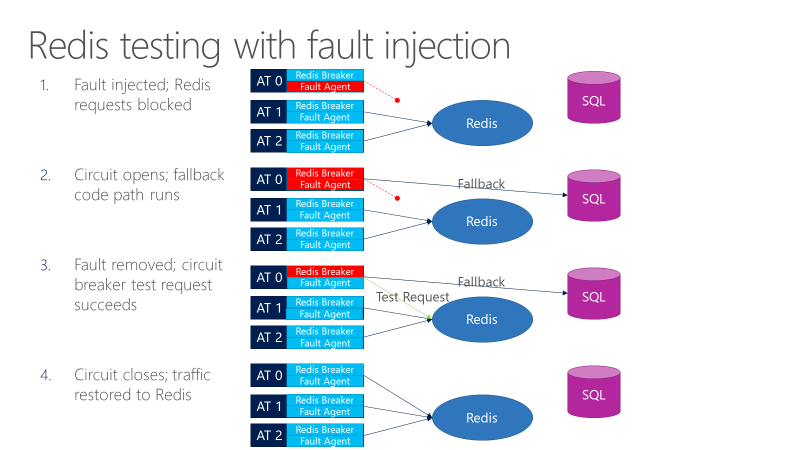
- Injektor kesalahan memblokir permintaan Redis.
- Pemutus sirkuit terbuka, dan pengujian dapat mengamati apakah fallback berfungsi.
- Kesalahan dihapus, dan pemutus sirkuit mengirimkan permintaan pengujian ke Redis.
- Jika permintaan berhasil, panggilan kembali ke Redis.
Langkah-langkah lebih lanjut dapat menguji sensitivitas pemutus, apakah ambang batas terlalu tinggi atau terlalu rendah, dan apakah batas waktu sistem lainnya mengganggu perilaku pemutus sirkuit.
Dalam contoh ini, jika pemutus tidak membuka atau menutup seperti yang diharapkan, itu dapat menyebabkan insiden situs langsung (LSI). Tanpa pengujian injeksi kesalahan, masalahnya mungkin tidak terdeteksi, karena sulit untuk melakukan jenis pengujian ini di lingkungan lab.
Langkah selanjutnya
- [Shift pengujian kiri dengan pengujian unit]shift-left
- Apa itu layanan mikro?
- Menjalankan failover pengujian (latihan pemulihan bencana) ke Azure
- Praktik penyebaran yang aman
- Apa itu pemantauan?
- Apa itu rekayasa platform?