Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dalam tutorial ini, Anda membuat aplikasi MSTest untuk mengevaluasi respons obrolan model OpenAI. Aplikasi pengujian menggunakan pustaka Microsoft.Extensions.AI.Evaluation untuk melakukan evaluasi, menyimpan dalam cache respons model, dan membuat laporan. Tutorial ini menggunakan evaluator bawaan dan kustom. Evaluator kualitas bawaan (dari Microsoft. Extensions.AI.Evaluation.Quality package) menggunakan LLM untuk melakukan evaluasi; evaluator kustom tidak menggunakan AI.
Prasyarat
Mengonfigurasi layanan AI
Untuk menyediakan Azure OpenAI service dan model menggunakan portal Azure, selesaikan langkah-langkah dalam artikel Buat dan sebarkan sumber daya Azure OpenAI Service. Dalam langkah "Sebarkan model", pilih model gpt-5.
Membuat aplikasi pengujian
Selesaikan langkah-langkah berikut untuk membuat proyek MSTest yang tersambung ke model AI.
Di jendela terminal, navigasikan ke direktori tempat Anda ingin membuat aplikasi, dan buat aplikasi MSTest baru dengan
dotnet newperintah :dotnet new mstest -o TestAIWithReportingNavigasi ke direktori
TestAIWithReporting, dan tambahkan paket yang diperlukan ke aplikasi Anda:dotnet add package Azure.AI.OpenAI dotnet add package Azure.Identity dotnet add package Microsoft.Extensions.AI.Abstractions dotnet add package Microsoft.Extensions.AI.Evaluation dotnet add package Microsoft.Extensions.AI.Evaluation.Quality dotnet add package Microsoft.Extensions.AI.Evaluation.Reporting dotnet add package Microsoft.Extensions.AI.OpenAI dotnet add package Microsoft.Extensions.Configuration dotnet add package Microsoft.Extensions.Configuration.UserSecretsJalankan perintah berikut untuk menambahkan rahasia app untuk titik akhir OpenAI dan ID penyewa Azure Anda:
dotnet user-secrets init dotnet user-secrets set AZURE_OPENAI_ENDPOINT <your-Azure-OpenAI-endpoint> dotnet user-secrets set AZURE_TENANT_ID <your-tenant-ID>(Tergantung pada lingkungan Anda, ID penyewa mungkin tidak diperlukan. Dalam hal ini, hapus dari kode yang membuat instans DefaultAzureCredential.)
Buka aplikasi baru di editor pilihan Anda.
Menambahkan kode aplikasi pengujian
Ganti nama file Test1.cs menjadi MyTests.cs, lalu buka file dan ganti nama kelas menjadi
MyTests. Hapus metode kosongTestMethod1.Tambahkan arahan yang diperlukan
usingke bagian atas file.using Azure.AI.OpenAI; using Azure.Identity; using Microsoft.Extensions.AI.Evaluation; using Microsoft.Extensions.AI; using Microsoft.Extensions.Configuration; using Microsoft.Extensions.AI.Evaluation.Reporting.Storage; using Microsoft.Extensions.AI.Evaluation.Reporting; using Microsoft.Extensions.AI.Evaluation.Quality;Tambahkan properti TestContext ke kelas.
// The value of the TestContext property is populated by MSTest. public TestContext? TestContext { get; set; }Tambahkan metode
GetAzureOpenAIChatConfiguration, yang membuat IChatClient yang digunakan evaluator untuk berkomunikasi dengan model.private static ChatConfiguration GetAzureOpenAIChatConfiguration() { IConfigurationRoot config = new ConfigurationBuilder().AddUserSecrets<MyTests>().Build(); string endpoint = config["AZURE_OPENAI_ENDPOINT"]; string tenantId = config["AZURE_TENANT_ID"]; string model = "gpt-5"; // Get an instance of Microsoft.Extensions.AI's <see cref="IChatClient"/> // interface for the selected LLM endpoint. AzureOpenAIClient azureClient = new( new Uri(endpoint), new DefaultAzureCredential(new DefaultAzureCredentialOptions() { TenantId = tenantId })); IChatClient client = azureClient.GetChatClient(deploymentName: model).AsIChatClient(); // Create an instance of <see cref="ChatConfiguration"/> // to communicate with the LLM. return new ChatConfiguration(client); }Siapkan fungsionalitas pelaporan.
private string ScenarioName => $"{TestContext!.FullyQualifiedTestClassName}.{TestContext.TestName}"; private static string ExecutionName => $"{DateTime.Now:yyyyMMddTHHmmss}"; private static readonly ReportingConfiguration s_defaultReportingConfiguration = DiskBasedReportingConfiguration.Create( storageRootPath: "C:\\TestReports", evaluators: GetEvaluators(), chatConfiguration: GetAzureOpenAIChatConfiguration(), enableResponseCaching: true, executionName: ExecutionName);Nama skenario
Nama skenario diatur ke nama yang sepenuhnya memenuhi syarat dari metode pengujian saat ini. Namun, Anda dapat mengaturnya ke string apa pun saat memanggil CreateScenarioRunAsync(String, String, IEnumerable<String>, IEnumerable<String>, CancellationToken). Pertimbangkan faktor-faktor ini saat memilih nama skenario:
- Saat menggunakan penyimpanan berbasis disk, nama skenario digunakan sebagai nama folder tempat hasil evaluasi yang sesuai disimpan. Jadi ada baiknya untuk menjaga nama cukup pendek dan menghindari karakter apa pun yang tidak diizinkan dalam nama file dan direktori.
- Secara default, laporan evaluasi yang dihasilkan membagi nama
.skenario sehingga hasilnya ditampilkan dalam tampilan hierarkis dengan pengelompokan, berlapis, dan agregasi yang sesuai. Tampilan hierarki sangat berguna ketika nama skenario adalah nama lengkap dari metode pengujian yang sesuai, karena mengelompokkan hasil menurut namespace dan nama kelas dalam hierarki. Namun, Anda juga dapat memanfaatkan fitur ini dengan menyertakan titik (.) dalam nama skenario kustom Anda sendiri untuk membuat hierarki pelaporan yang paling sesuai untuk skenario Anda.
Nama eksekusi
Nama eksekusi digunakan untuk mengelompokkan hasil evaluasi yang merupakan bagian dari eksekusi evaluasi yang sama (atau uji coba) saat hasil evaluasi disimpan. Jika Anda tidak memberikan nama eksekusi saat membuat ReportingConfiguration, semua evaluasi berjalan menggunakan nama eksekusi default yang sama dari
Default. Dalam hal ini, hasil dari satu eksekusi ditimpa oleh eksekusi berikutnya, dan Anda kehilangan kemampuan untuk membandingkan hasil di berbagai eksekusi.Contoh ini menggunakan tanda waktu sebagai nama eksekusi. Jika Anda memiliki lebih dari satu pengujian dalam proyek Anda, pastikan bahwa hasil dikelompokkan dengan benar dengan menggunakan nama eksekusi yang sama di semua konfigurasi pelaporan yang digunakan di seluruh pengujian.
Dalam skenario dunia yang lebih nyata, Anda mungkin juga ingin berbagi nama eksekusi yang sama di seluruh pengujian evaluasi yang hidup di beberapa rakitan yang berbeda dan yang dijalankan dalam proses pengujian yang berbeda. Dalam kasus seperti itu, Anda dapat menggunakan skrip untuk memperbarui variabel lingkungan dengan nama eksekusi yang sesuai (seperti nomor build saat ini yang ditetapkan oleh sistem CI/CD Anda) sebelum menjalankan pengujian. Atau, jika sistem build Anda menghasilkan versi file rakitan yang meningkat secara monoton, Anda dapat membaca AssemblyFileVersionAttribute dari dalam kode pengujian dan menggunakannya sebagai nama eksekusi untuk membandingkan hasil di berbagai versi produk.
Konfigurasi pelaporan
ReportingConfiguration Ini mengidentifikasi:
- Sekumpulan evaluator yang harus digunakan untuk setiap ScenarioRun yang dibuat dengan memanggil CreateScenarioRunAsync(String, String, IEnumerable<String>, IEnumerable<String>, CancellationToken).
- Titik akhir LLM yang perlu digunakan oleh evaluator (lihat ReportingConfiguration.ChatConfiguration).
- Bagaimana dan di mana hasil untuk skenario berjalan harus disimpan.
- Bagaimana respons LLM yang terkait dengan eksekusi skenario harus di-cache.
- Nama eksekusi yang harus digunakan saat melaporkan hasil untuk skenario yang dijalankan.
Pengujian ini menggunakan konfigurasi pelaporan berbasis disk.
Dalam file terpisah, tambahkan
WordCountEvaluatorkelas , yang merupakan evaluator kustom yang mengimplementasikan IEvaluator.using System.Text.RegularExpressions; using Microsoft.Extensions.AI; using Microsoft.Extensions.AI.Evaluation; namespace TestAIWithReporting; public class WordCountEvaluator : IEvaluator { public const string WordCountMetricName = "Words"; public IReadOnlyCollection<string> EvaluationMetricNames => [WordCountMetricName]; /// <summary> /// Counts the number of words in the supplied string. /// </summary> private static int CountWords(string? input) { if (string.IsNullOrWhiteSpace(input)) { return 0; } MatchCollection matches = Regex.Matches(input, @"\b\w+\b"); return matches.Count; } /// <summary> /// Provides a default interpretation for the supplied <paramref name="metric"/>. /// </summary> private static void Interpret(NumericMetric metric) { if (metric.Value is null) { metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Unknown, failed: true, reason: "Failed to calculate word count for the response."); } else { if (metric.Value <= 100 && metric.Value > 5) metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Good, reason: "The response was between 6 and 100 words."); else metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Unacceptable, failed: true, reason: "The response was either too short or greater than 100 words."); } } public ValueTask<EvaluationResult> EvaluateAsync( IEnumerable<ChatMessage> messages, ChatResponse modelResponse, ChatConfiguration? chatConfiguration = null, IEnumerable<EvaluationContext>? additionalContext = null, CancellationToken cancellationToken = default) { // Count the number of words in the supplied <see cref="modelResponse"/>. int wordCount = CountWords(modelResponse.Text); string reason = $"This {WordCountMetricName} metric has a value of {wordCount} because " + $"the evaluated model response contained {wordCount} words."; // Create a <see cref="NumericMetric"/> with value set to the word count. // Include a reason that explains the score. var metric = new NumericMetric(WordCountMetricName, value: wordCount, reason); // Attach a default <see cref="EvaluationMetricInterpretation"/> for the metric. Interpret(metric); return new ValueTask<EvaluationResult>(new EvaluationResult(metric)); } }WordCountEvaluatormenghitung jumlah kata yang terdapat dalam respons. Tidak seperti beberapa evaluator, itu tidak didasarkan pada AI. MetodeEvaluateAsyncmengembalikan objek EvaluationResult yang menyertakan NumericMetric yang berisi jumlah kata.Metode ini
EvaluateAsyncjuga melampirkan interpretasi default ke metrik. Interpretasi default menganggap metrik menjadi baik (dapat diterima) jika jumlah kata yang terdeteksi adalah antara 6 dan 100. Jika tidak, metrik dianggap gagal. Pemanggil dapat mengambil alih interpretasi default ini jika diperlukan.Kembali ke
MyTests.cs, tambahkan metode untuk mengumpulkan evaluator yang akan digunakan dalam evaluasi.private static IEnumerable<IEvaluator> GetEvaluators() { IEvaluator relevanceEvaluator = new RelevanceEvaluator(); IEvaluator coherenceEvaluator = new CoherenceEvaluator(); IEvaluator wordCountEvaluator = new WordCountEvaluator(); return [relevanceEvaluator, coherenceEvaluator, wordCountEvaluator]; }Tambahkan metode untuk menambahkan permintaan ChatMessagesistem , tentukan opsi obrolan, dan minta model untuk respons terhadap pertanyaan tertentu.
private static async Task<(IList<ChatMessage> Messages, ChatResponse ModelResponse)> GetAstronomyConversationAsync( IChatClient chatClient, string astronomyQuestion) { const string SystemPrompt = """ You're an AI assistant that can answer questions related to astronomy. Keep your responses concise and under 100 words. Use the imperial measurement system for all measurements in your response. """; IList<ChatMessage> messages = [ new ChatMessage(ChatRole.System, SystemPrompt), new ChatMessage(ChatRole.User, astronomyQuestion) ]; var chatOptions = new ChatOptions { Temperature = 0.0f, ResponseFormat = ChatResponseFormat.Text }; ChatResponse response = await chatClient.GetResponseAsync(messages, chatOptions); return (messages, response); }Tes dalam tutorial ini mengevaluasi respons LLM terhadap pertanyaan astronomi. Karena penyimpanan sementara respons telah diaktifkan, dan karena IChatClient yang disediakan selalu diambil dari ScenarioRun yang dibuat menggunakan konfigurasi pelaporan ini, respons LLM untuk pengujian disimpan sementara dan digunakan kembali. Respons digunakan kembali sampai entri cache yang sesuai kedaluwarsa (dalam 14 hari secara default), atau sampai parameter permintaan apa pun, seperti titik akhir LLM atau pertanyaan yang diajukan, berubah.
Tambahkan metode untuk memvalidasi respons.
/// <summary> /// Runs basic validation on the supplied <see cref="EvaluationResult"/>. /// </summary> private static void Validate(EvaluationResult result) { // Retrieve the score for relevance from the <see cref="EvaluationResult"/>. NumericMetric relevance = result.Get<NumericMetric>(RelevanceEvaluator.RelevanceMetricName); Assert.IsFalse(relevance.Interpretation!.Failed, relevance.Reason); Assert.IsTrue(relevance.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); // Retrieve the score for coherence from the <see cref="EvaluationResult"/>. NumericMetric coherence = result.Get<NumericMetric>(CoherenceEvaluator.CoherenceMetricName); Assert.IsFalse(coherence.Interpretation!.Failed, coherence.Reason); Assert.IsTrue(coherence.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); // Retrieve the word count from the <see cref="EvaluationResult"/>. NumericMetric wordCount = result.Get<NumericMetric>(WordCountEvaluator.WordCountMetricName); Assert.IsFalse(wordCount.Interpretation!.Failed, wordCount.Reason); Assert.IsTrue(wordCount.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); Assert.IsFalse(wordCount.ContainsDiagnostics()); Assert.IsTrue(wordCount.Value > 5 && wordCount.Value <= 100); }Petunjuk / Saran
Metrik masing-masing menyertakan
Reasonproperti yang menjelaskan alasan skor. Alasannya disertakan dalam laporan yang dihasilkan dan dapat dilihat dengan mengklik ikon informasi pada kartu metrik yang sesuai.Terakhir, tambahkan metode pengujian itu sendiri.
[TestMethod] public async Task SampleAndEvaluateResponse() { // Create a <see cref="ScenarioRun"/> with the scenario name // set to the fully qualified name of the current test method. await using ScenarioRun scenarioRun = await s_defaultReportingConfiguration.CreateScenarioRunAsync( ScenarioName, additionalTags: ["Moon"]); // Use the <see cref="IChatClient"/> that's included in the // <see cref="ScenarioRun.ChatConfiguration"/> to get the LLM response. (IList<ChatMessage> messages, ChatResponse modelResponse) = await GetAstronomyConversationAsync( chatClient: scenarioRun.ChatConfiguration!.ChatClient, astronomyQuestion: "How far is the Moon from the Earth at its closest and furthest points?"); // Run the evaluators configured in <see cref="s_defaultReportingConfiguration"/> against the response. EvaluationResult result = await scenarioRun.EvaluateAsync(messages, modelResponse); // Run some basic validation on the evaluation result. Validate(result); }Metode pengujian ini:
Membuat ScenarioRun.
await usingmemastikan pembuanganScenarioRunyang benar dan persistensi hasil evaluasi yang benar ke penyimpanan hasil.Mendapatkan respons LLM terhadap pertanyaan astronomi tertentu. Pengujian meneruskan objek yang sama IChatClient yang digunakan untuk evaluasi ke metode
GetAstronomyConversationAsyncuntuk mendapatkan penyimpanan cache respons untuk respons LLM utama yang sedang dievaluasi. (Menggunakan klien yang sama juga memungkinkan penyimpanan cache untuk giliran LLM yang digunakan evaluator untuk melakukan evaluasi mereka secara internal.) Dengan penyimpanan cache respons, respons LLM diambil baik:- Langsung dari titik akhir LLM dalam eksekusi pertama pengujian saat ini, atau dalam eksekusi berikutnya jika entri yang di-cache telah kedaluwarsa (14 hari, secara default).
- Dari cache respons (berbasis disk) yang dikonfigurasi dalam
s_defaultReportingConfigurationdalam pengujian yang dijalankan berikutnya.
Menjalankan pengujian evaluator terhadap jawaban. Seperti respons LLM, eksekusi berikutnya mengambil evaluasi dari cache respons (berbasis disk) yang dikonfigurasi di
s_defaultReportingConfiguration.Menjalankan beberapa validasi dasar pada hasil evaluasi.
Langkah ini bersifat opsional dan terutama untuk tujuan demonstrasi. Dalam evaluasi dunia nyata, Anda mungkin tidak ingin memvalidasi hasil individual karena respons LLM dan skor evaluasi dapat berubah dari waktu ke waktu saat produk Anda (dan model yang digunakan) berevolusi. Anda mungkin tidak ingin pengujian evaluasi individual "gagal" dan memblokir pembangunan di alur CI/CD Anda ketika hasilnya berubah. Sebaliknya, mungkin lebih baik mengandalkan laporan yang dihasilkan dan memantau tren keseluruhan dari skor evaluasi di berbagai skenario sepanjang waktu (dan hanya menggagalkan build individu ketika terdapat penurunan skor evaluasi yang signifikan di berbagai tes yang berbeda). Dengan demikian, ada beberapa nuansa di sini dan pilihan apakah akan memvalidasi hasil individu atau tidak dapat bervariasi tergantung pada kasus penggunaan tertentu.
Setelah metode selesai, objek
scenarioRundibuang dan hasil dari evaluasi disimpan ke penyimpanan hasil berbasis disk yang dikonfigurasi dalams_defaultReportingConfiguration.
Menjalankan pengujian/evaluasi
Jalankan pengujian menggunakan alur kerja pengujian pilihan Anda, misalnya, dengan menggunakan perintah dotnet test CLI atau melalui Test Explorer.
Membuat laporan
Pasang alat .NET Microsoft.Extensions.AI.Evaluation.Console dengan menjalankan perintah berikut dari jendela terminal:
dotnet tool install --create-manifest-if-needed Microsoft.Extensions.AI.Evaluation.ConsoleBuat laporan dengan menjalankan perintah berikut:
dotnet tool run aieval report --path <path\to\your\cache\storage> --output report.htmlBuka file
report.html. Laporan ini terlihat mirip dengan cuplikan layar berikut.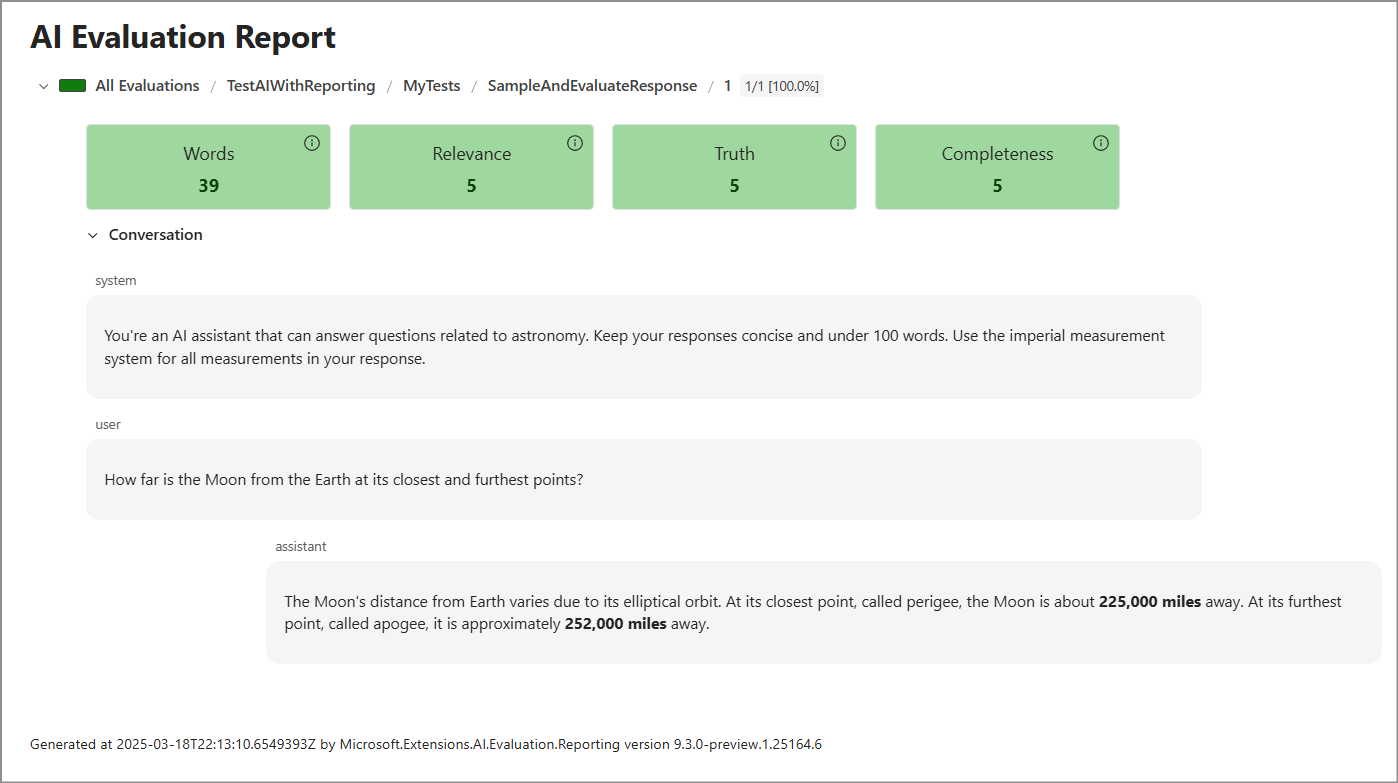
Langkah selanjutnya
- Navigasi ke direktori tempat hasil pengujian disimpan (yaitu
C:\TestReports, kecuali Anda memodifikasi lokasi saat Anda membuat ReportingConfiguration). Di subdirektoriresults, perhatikan bahwa ada folder untuk setiap eksekusi pengujian bernama dengan tanda waktu (ExecutionName). Di dalam setiap folder tersebut adalah folder untuk setiap nama skenario—dalam hal ini, hanya metode pengujian tunggal dalam proyek. Folder tersebut berisi file JSON dengan semua data termasuk pesan, respons, dan hasil evaluasi. - Perluas evaluasi. Berikut adalah beberapa ide:
- Tambahkan evaluator kustom lain, seperti evaluator yang menggunakan AI untuk menentukan sistem pengukuran yang digunakan dalam respons.
- Tambahkan metode pengujian lain, misalnya, metode yang mengevaluasi beberapa respons dari LLM. Karena setiap respons bisa berbeda, ada baiknya untuk mengambil sampel dan mengevaluasi setidaknya beberapa respons terhadap pertanyaan. Dalam hal ini, Anda menentukan nama iterasi setiap kali Anda memanggil CreateScenarioRunAsync(String, String, IEnumerable<String>, IEnumerable<String>, CancellationToken).
Berkolaborasi dengan kami di GitHub
Sumber untuk konten ini dapat ditemukan di GitHub, yang juga dapat Anda gunakan untuk membuat dan meninjau masalah dan menarik permintaan. Untuk informasi selengkapnya, lihat panduan kontributor kami.