Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Petunjuk / Saran
Konten ini adalah kutipan dari eBook, Merancang Aplikasi .NET Cloud Native untuk Azure, tersedia di .NET Docs atau sebagai PDF gratis yang dapat diunduh yang dapat dibaca secara offline.

Seperti yang telah kita lihat di seluruh buku ini, pendekatan cloud-native mengubah cara Anda merancang, menyebarkan, dan mengelola aplikasi. Ini juga mengubah cara Anda mengelola dan menyimpan data.
Gambar 5-1 membedakan perbedaan.
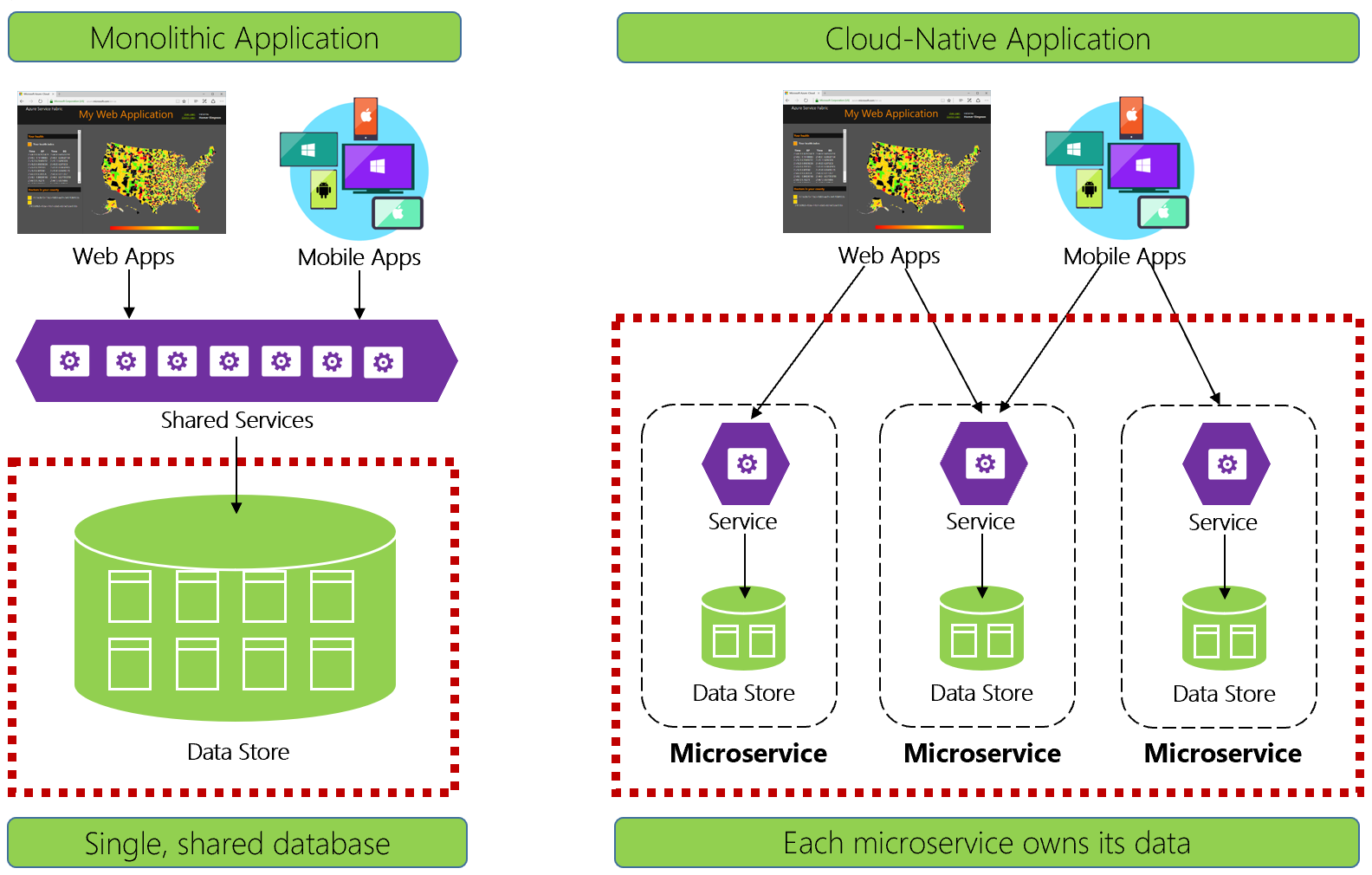
Gambar 5-1. Manajemen data dalam aplikasi cloud-native
Pengembang berpengalaman akan dengan mudah mengenali arsitektur di sisi kiri gambar 5-1. Dalam aplikasi monolitik ini, komponen layanan bisnis berkolokasi bersama dalam tingkat layanan bersama, berbagi data dari database relasional tunggal.
Dalam banyak hal, satu database membuat manajemen data tetap sederhana. Mengkueri data di beberapa tabel sangat mudah. Perubahan pada pembaruan data dilakukan bersamaan atau semuanya dikembalikan. Transaksi ACID menjamin konsistensi yang kuat dan langsung.
Saat mendesain untuk lingkungan cloud-native, kami mengambil pendekatan yang berbeda. Di sisi kanan Gambar 5-1, perhatikan bagaimana fungsionalitas bisnis dipisahkan menjadi layanan mikro kecil dan independen. Setiap layanan mikro merangkum kemampuan bisnis tertentu dan datanya sendiri. Database monolitik terurai ke dalam model data terdistribusi dengan banyak database yang lebih kecil, masing-masing selaras dengan layanan mikro. Ketika asap bersih, kami muncul dengan desain yang mengekspos database per layanan mikro.
Database per layanan mikro, mengapa demikian?
Database per layanan mikro ini memberikan banyak manfaat, terutama untuk sistem yang harus berkembang dengan cepat dan mendukung skala besar. Dengan model ini...
- Data domain dienkapsulasi dalam layanan
- Skema data dapat berkembang tanpa berdampak langsung pada layanan lain
- Setiap penyimpanan data dapat menskalakan secara independen
- Kegagalan penyimpanan data dalam satu layanan tidak akan berdampak langsung pada layanan lain
Memisahkan data juga memungkinkan setiap layanan mikro untuk mengimplementasikan jenis penyimpanan data yang paling baik dioptimalkan untuk beban kerja, kebutuhan penyimpanan, dan pola baca/tulisnya. Pilihannya termasuk penyimpanan data relasional, dokumen, nilai kunci, dan bahkan berbasis grafik.
Gambar 5-2 menyajikan prinsip persistensi poliglot dalam sistem cloud-native.
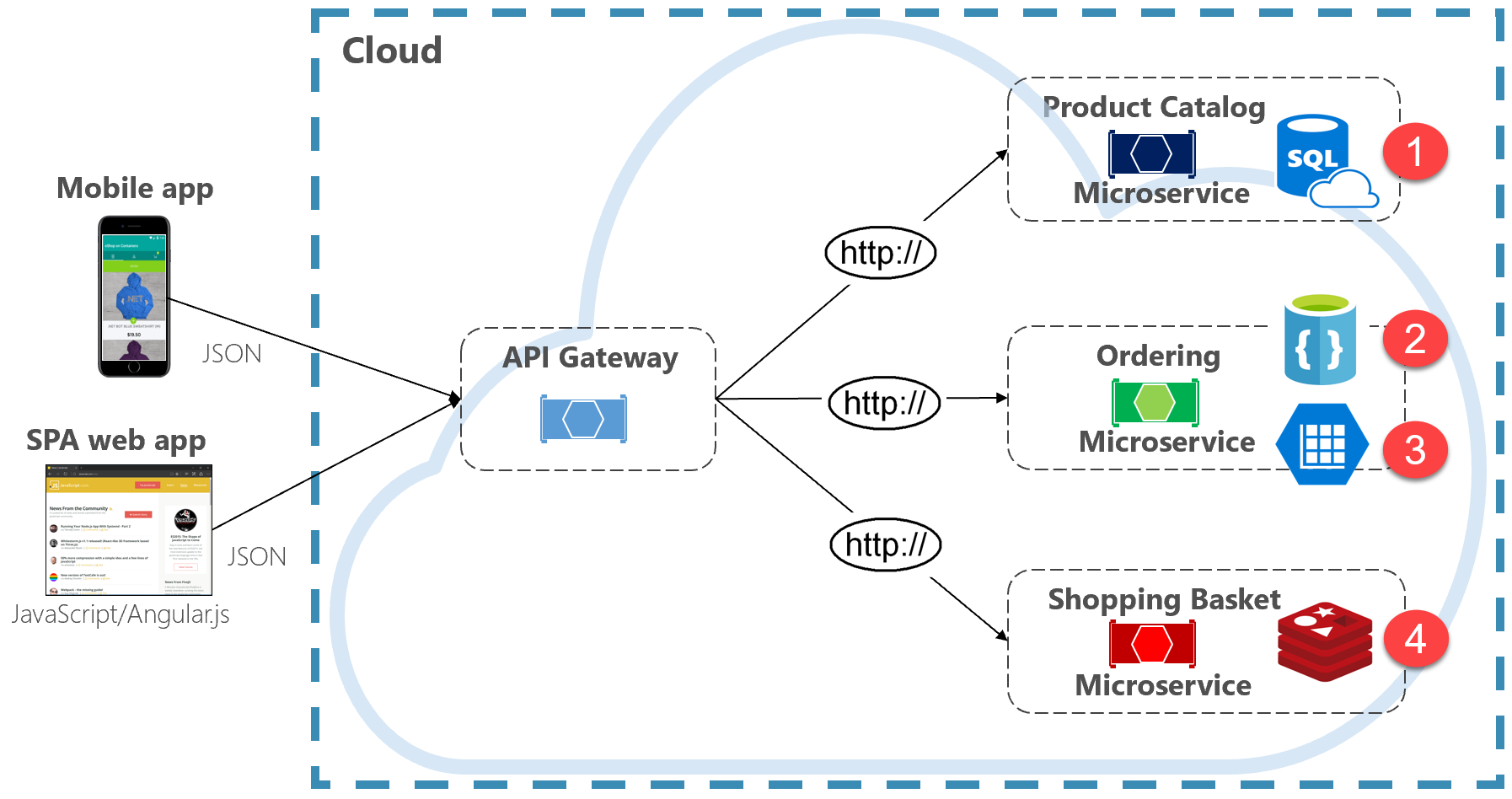
Gambar 5-2. Data Persisten Poliglot
Perhatikan pada gambar sebelumnya bagaimana setiap layanan mikro mendukung jenis penyimpanan data yang berbeda.
- Layanan mikro katalog produk menggunakan database relasional untuk mengakomodasi struktur relasional yang kaya dari data yang mendasarnya.
- Layanan mikro keranjang belanja mengonsumsi cache terdistribusi yang mendukung penyimpanan data kunci-nilai yang sederhana.
- Layanan mikro pemesanan mengonsumsi database dokumen NoSql untuk operasi penulisan, serta penyimpanan kunci/nilai yang sangat terdenormalisasi untuk mendukung volume tinggi operasi pembacaan.
Meskipun database relasional tetap relevan untuk layanan mikro dengan data yang kompleks, database NoSQL telah mendapatkan popularitas yang cukup besar. Mereka memberikan skala besar dan ketersediaan tinggi. Sifat tanpa skema mereka memungkinkan pengembang untuk menjauh dari arsitektur kelas data yang diketik dan ORM yang membuat perubahan mahal dan memakan waktu. Kami membahas database NoSQL nanti dalam bab ini.
Meskipun merangkum data menjadi layanan mikro terpisah dapat meningkatkan kelincahan, performa, dan skalabilitas, itu juga menghadirkan banyak tantangan. Di bagian berikutnya, kita membahas tantangan ini bersama dengan pola dan praktik untuk membantu mengatasinya.
Kueri antar layanan
Meskipun layanan mikro independen dan berfokus pada kemampuan fungsional tertentu, seperti persediaan, pengiriman, atau pemesanan, mereka sering memerlukan integrasi dengan layanan mikro lainnya. Seringkali integrasi melibatkan satu layanan mikro yang mengkueri yang lain untuk data. Gambar 5-3 menunjukkan skenario.
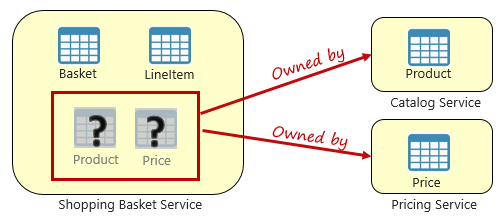
Gambar 5-3. Mengkueri di seluruh layanan mikro
Pada gambar sebelumnya, kita melihat layanan mikros keranjang belanja yang menambahkan barang ke dalam keranjang belanja pengguna. Meskipun penyimpanan data untuk layanan mikro ini berisi data keranjang dan item baris, penyimpanan ini tidak menyimpan data produk maupun harga. Sebaliknya, item data tersebut dimiliki oleh katalog dan layanan mikro harga. Aspek ini menghadirkan masalah. Bagaimana layanan mikro keranjang belanja dapat menambahkan produk ke keranjang belanja pengguna ketika tidak memiliki data produk atau harga di dalam databasenya?
Salah satu opsi yang dibahas dalam Bab 4 adalah panggilan HTTP langsung dari keranjang belanja ke katalog dan layanan mikro penentuan harga. Namun, pada bab 4, kami mengatakan panggilan HTTP sinkron menghubungkan layanan mikro bersama-sama, mengurangi otonomi mereka dan mengurangi keuntungan arsitektur mereka.
Kami juga dapat menerapkan pola balasan permintaan dengan antrean masuk dan keluar terpisah untuk setiap layanan. Namun, pola ini rumit dan memerlukan pipa untuk menghubungkan pesan permintaan dan respons. Meskipun memisahkan panggilan layanan mikro backend, layanan panggilan masih harus secara sinkron menunggu panggilan selesai. Kemacetan jaringan, kesalahan sementara, atau layanan mikro yang kelebihan beban dan dapat mengakibatkan operasi yang berjalan lama dan bahkan gagal.
Sebaliknya, pola yang diterima secara luas untuk menghapus dependensi lintas layanan adalah Pola Tampilan Terwujud, yang ditunjukkan pada Gambar 5-4.
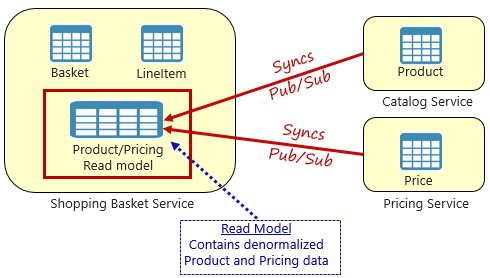
Gambar 5-4. Pola Tampilan Materialisasi
Dengan pola ini, Anda menempatkan tabel data lokal (dikenal sebagai model baca) di layanan keranjang belanja. Tabel ini berisi salinan data yang tidak dinormalisasi yang diperlukan dari layanan mikro produk dan harga. Menyalin data langsung ke layanan mikros keranjang belanja menghilangkan kebutuhan panggilan lintas layanan yang mahal. Dengan data lokal ke layanan, Anda meningkatkan waktu respons dan keandalan layanan. Selain itu, memiliki salinan datanya sendiri membuat layanan keranjang belanja lebih tahan banting. Jika layanan katalog menjadi tidak tersedia, hal tersebut tidak akan berdampak langsung pada layanan keranjang belanja. Keranjang belanja dapat terus beroperasi dengan data dari tokonya sendiri.
Masalah dengan pendekatan ini adalah bahwa Anda sekarang memiliki data yang diduplikasi dalam sistem Anda. Namun, menduplikasi data secara strategis dalam sistem cloud-native adalah praktik yang mapan dan tidak dianggap sebagai anti-pola, atau praktik buruk. Perlu diingat bahwa satu dan hanya satu layanan yang dapat memiliki himpunan data dan memiliki otoritas atasnya. Anda perlu menyinkronkan model pembaca saat sistem catatan diperbarui. Sinkronisasi biasanya diimplementasikan melalui olahpesan asinkron dengan pola terbitkan/berlangganan, seperti yang ditunjukkan pada Gambar 5.4.
Transaksi terdistribusi
Meskipun mengkueri data di seluruh layanan mikro sulit, menerapkan transaksi di beberapa layanan mikro bahkan lebih kompleks. Tantangan melekat pada mempertahankan konsistensi data di seluruh sumber data independen di layanan mikro yang berbeda tidak dapat dianggap remeh. Kurangnya transaksi terdistribusi dalam aplikasi cloud-native berarti Anda harus mengelola transaksi terdistribusi secara terprogram. Anda berpindah dari dunia konsistensi langsung ke konsistensi akhir.
Gambar 5-5 menunjukkan masalahnya.
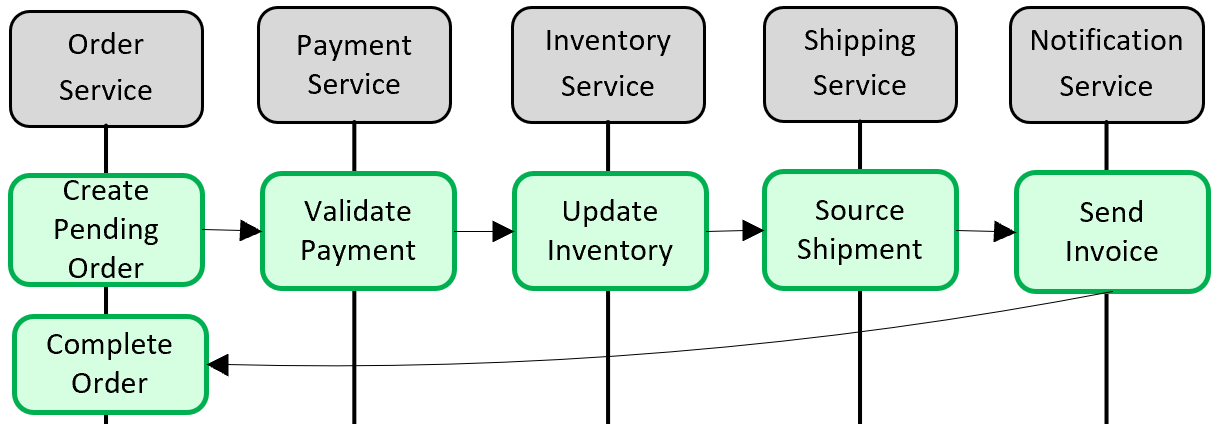
Gambar 5-5. Menerapkan transaksi di seluruh layanan mikro
Pada gambar sebelumnya, lima layanan mikro independen berpartisipasi dalam transaksi terdistribusi yang membuat pesanan. Setiap layanan mikro mempertahankan penyimpanan datanya sendiri dan menerapkan transaksi lokal untuk penyimpanannya. Untuk membuat pesanan, transaksi lokal untuk setiap layanan mikro individu harus berhasil, atau semua harus menggagalkan dan membatalkan operasi. Meskipun dukungan transaksional bawaan tersedia di dalam masing-masing layanan mikro, tidak ada dukungan untuk transaksi terdistribusi yang akan mencakup kelima layanan untuk menjaga data tetap konsisten.
Sebagai gantinya, Anda harus membangun transaksi terdistribusi ini secara terprogram.
Pola populer untuk menambahkan dukungan transaksi terdistribusi adalah pola Saga. Ini diimplementasikan dengan mengelompokkan transaksi lokal bersama-sama secara terprogram dan secara berurutan memanggil masing-masing transaksi. Jika salah satu transaksi lokal gagal, Saga membatalkan operasi dan memanggil serangkaian transaksi kompensasi. Transaksi kompensasi membatalkan perubahan yang dilakukan oleh transaksi lokal sebelumnya dan memulihkan konsistensi data. Gambar 5-6 menunjukkan transaksi yang gagal dengan pola Saga.
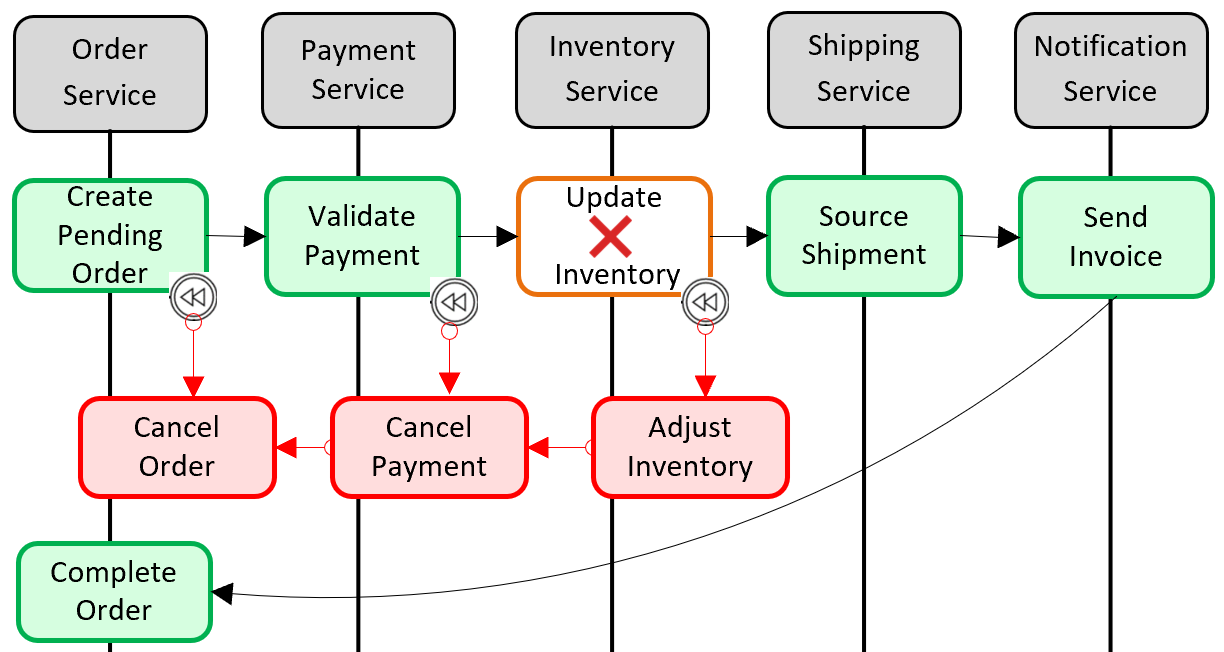
Gambar 5-6. Mengembalikan transaksi
Pada gambar sebelumnya, operasi Perbarui Inventory telah gagal dalam layanan mikro Inventori. Saga memanggil sekumpulan transaksi kompensasi (dalam warna merah) untuk menyesuaikan jumlah inventori, membatalkan pembayaran dan pesanan, dan mengembalikan data untuk setiap layanan mikro kembali ke keadaan yang konsisten.
Pola Saga biasanya dikoreografi sebagai serangkaian peristiwa terkait, atau diorkestrasi sebagai sekumpulan perintah terkait. Dalam Bab 4, kami membahas pola agregator layanan yang akan menjadi fondasi untuk implementasi saga yang diorkestrasi. Kami juga membahas pengelolaan acara bersama dengan tema Azure Service Bus dan Azure Event Grid yang akan menjadi fondasi untuk implementasi saga yang terskenario.
Volume data tinggi
Aplikasi cloud-native besar sering mendukung persyaratan data volume tinggi. Dalam skenario ini, teknik penyimpanan data tradisional dapat menyebabkan hambatan. Untuk sistem kompleks yang disebarkan dalam skala besar, Pemisahan Tanggung Jawab Perintah dan Kueri (CQRS) dan Sumber Peristiwa dapat meningkatkan performa aplikasi.
CQRS
CQRS, adalah pola arsitektur yang dapat membantu memaksimalkan performa, skalabilitas, dan keamanan. Pola memisahkan operasi yang membaca data dari operasi yang menulis data.
Untuk skenario normal, model entitas dan objek repositori data yang sama digunakan untuk operasi baca dan tulis.
Namun, skenario data volume tinggi dapat memperoleh manfaat dari model dan tabel data terpisah untuk baca dan tulis. Untuk meningkatkan performa, operasi baca dapat meminta representasi data yang sangat denormalisasi untuk menghindari gabungan tabel berulang yang mahal dan kunci tabel. Operasi tulis, yang dikenal sebagai perintah, akan diperbarui menggunakan representasi data yang sepenuhnya dinormalisasi untuk menjamin konsistensi. Anda kemudian perlu menerapkan mekanisme untuk menjaga kedua representasi tetap sinkron. Biasanya, setiap kali tabel tulis dimodifikasi, tabel tersebut menerbitkan peristiwa yang mereplikasi modifikasi ke tabel baca.
Gambar 5-7 menunjukkan implementasi pola CQRS.
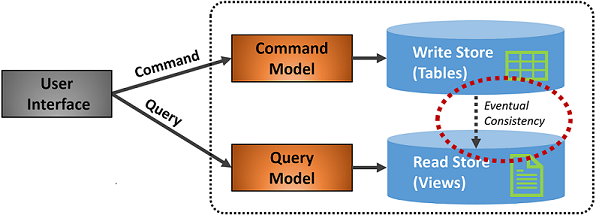
Gambar 5-7. Implementasi CQRS
Pada gambar sebelumnya, model perintah dan kueri yang terpisah diimplementasikan. Setiap operasi penulisan data disimpan ke penyimpanan tulis lalu disebarluaskan ke penyimpanan baca. Perhatikan dengan cermat bagaimana proses penyebaran data beroperasi berdasarkan prinsip konsistensi akhir. Model baca akhirnya disinkronkan dengan model tulis, tetapi mungkin ada beberapa jeda dalam prosesnya. Kami membahas konsistensi akhir di bagian berikutnya.
Pemisahan ini memungkinkan pembacaan dan penulisan untuk diskalakan secara independen. Operasi baca menggunakan skema yang dioptimalkan untuk kueri, sementara penulisan menggunakan skema yang dioptimalkan untuk pembaruan. Permintaan pembacaan menggunakan data yang tidak dinormalisasi, sementara logika bisnis yang kompleks dapat diterapkan pada model penulisan. Selain itu, Anda mungkin memberlakukan keamanan yang lebih ketat pada operasi tulis daripada yang mengekspos bacaan.
Menerapkan CQRS dapat meningkatkan performa aplikasi untuk layanan cloud-native. Namun, itu menghasilkan desain yang lebih kompleks. Terapkan prinsip ini dengan hati-hati dan strategis ke bagian aplikasi cloud-native Anda yang akan mendapat manfaat darinya. Untuk informasi selengkapnya tentang CQRS, lihat buku Microsoft .NET Microservices: Architecture for Containerized .NET Applications.
Sumber peristiwa
Pendekatan lain untuk mengoptimalkan skenario data volume tinggi melibatkan Event Sourcing.
Sistem biasanya menyimpan status entitas data saat ini. Jika pengguna mengubah nomor telepon mereka, misalnya, catatan pelanggan diperbarui dengan nomor baru. Kita selalu tahu status entitas data saat ini, tetapi setiap pembaruan menimpa status sebelumnya.
Dalam kebanyakan kasus, model ini berfungsi dengan baik. Namun, dalam sistem volume tinggi, overhead dari penguncian transaksi dan operasi pembaruan yang sering dapat memengaruhi performa database, responsivitas, dan membatasi skalabilitas.
Event Sourcing menggunakan pendekatan berbeda dalam pendataan. Setiap operasi yang memengaruhi data disimpan ke log peristiwa. Alih-alih memperbarui status rekaman data, kami menambahkan setiap perubahan ke daftar berurutan peristiwa sebelumnya - mirip dengan ledger akuntan. Event Store menjadi sistem pencatatan untuk data. Ini digunakan untuk menyebarkan berbagai tampilan materialisasi dalam konteks terikat layanan mikro. Gambar 5.8 menunjukkan polanya.
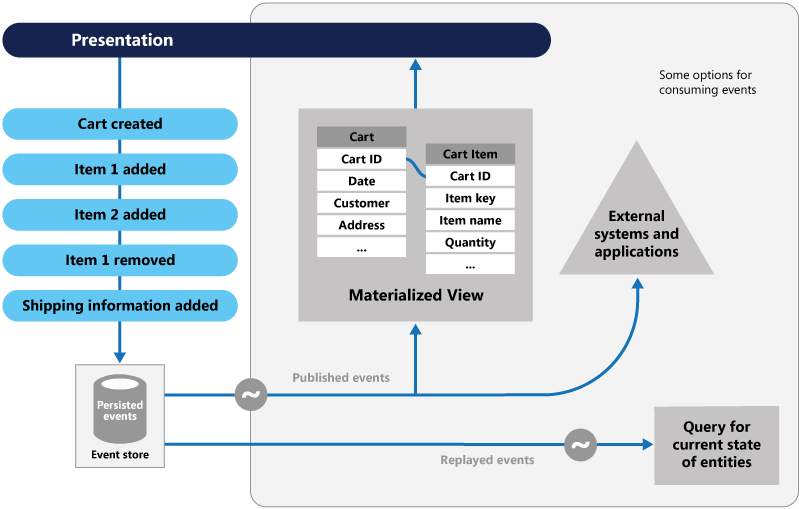
Gambar 5-8. Sumber Peristiwa
Pada gambar sebelumnya, perhatikan bagaimana setiap entri (berwarna biru) untuk keranjang belanja pengguna dipasangkan ke penyimpanan acara yang mendasarinya. Dalam tampilan materialisasi yang berdampingan, sistem memproyeksikan status saat ini dengan mereka ulang semua kejadian yang terkait dengan setiap keranjang belanja. Tampilan ini, atau model baca, kemudian diekspos kembali ke antarmuka pengguna. Peristiwa juga dapat diintegrasikan dengan sistem dan aplikasi eksternal atau dikueri untuk menentukan status entitas saat ini. Dengan pendekatan ini, Anda mempertahankan sejarah. Anda tidak hanya tahu status entitas saat ini, tetapi juga bagaimana Anda mencapai status ini.
Secara mekanis, penyusunan kejadian menyederhanakan model perekaman. Tidak ada pembaruan atau penghapusan. Menambahkan setiap entri data sebagai peristiwa yang tidak dapat diubah meminimalkan konflik ketidakcocokan, penguncian, dan konkurensi yang terkait dengan database relasional. Membangun model baca dengan pola tampilan materialisasi memungkinkan Anda memisahkan tampilan dari model tulis dan memilih penyimpanan data terbaik untuk mengoptimalkan kebutuhan UI aplikasi Anda.
Untuk pola ini, pertimbangkan penyimpanan data yang secara langsung mendukung pemodelan peristiwa. Azure Cosmos DB, MongoDB, Cassandra, CouchDB, dan RavenDB adalah kandidat yang baik.
Seperti semua pola dan teknologi, terapkan secara strategis dan bila diperlukan. Meskipun pendataan peristiwa dapat memberikan peningkatan performa dan skalabilitas, hal ini memerlukan pengorbanan berupa kompleksitas dan kurva pembelajaran.
Berkolaborasi dengan kami di GitHub
Sumber untuk konten ini dapat ditemukan di GitHub, yang juga dapat Anda gunakan untuk membuat dan meninjau masalah dan menarik permintaan. Untuk informasi selengkapnya, lihat panduan kontributor kami.