Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Petunjuk / Saran
Konten ini adalah kutipan dari eBook, Merancang Aplikasi .NET Cloud Native untuk Azure, tersedia di .NET Docs atau sebagai PDF gratis yang dapat diunduh yang dapat dibaca secara offline.

Relasional (SQL) dan non-relasional (NoSQL) adalah dua jenis sistem database yang umumnya diterapkan di aplikasi cloud-native. Keduanya dibangun secara berbeda, menyimpan data secara berbeda, dan diakses secara berbeda. Di bagian ini, kita akan melihat keduanya. Nantinya dalam bab ini, kita akan melihat teknologi database yang muncul yang disebut NewSQL.
Database hubungan telah menjadi teknologi yang banyak digunakan selama beberapa dekade. Database ini lengkap, terbukti, dan diimplementasikan secara luas. Berbagai produk, perkakas, dan keahlian database yang bersaing. Database hubungan menyediakan penyimpanan tabel data terkait. Tabel ini memiliki skema tetap, menggunakan SQL (Bahasa Permintaan Terstruktur) untuk mengelola data, dan mendukung jaminan ACID: atomitas, konsistensi, isolasi, dan durabilitas.
Database NoSQL mengacu pada penyimpanan data non-relasional berkinerja tinggi. Database tersebut unggul dalam hal kemudahan penggunaan, skalabilitas, ketahanan, dan ketersediaan. Sebagai ganti menggabungkan tabel data yang dinormalisasi, NoSQL menyimpan data yang tidak terstruktur atau semi terstruktur, sering kali dalam pasangan kunci-nilai atau dokumen JSON. Database NoSQL biasanya tidak memberikan jaminan ACID di luar cakupan partisi database tunggal. Layanan volume tinggi yang memerlukan waktu respons sekian mili detik mendukung datastore NoSQL.
Dampak teknologi NoSQL untuk sistem cloud-native terdistribusi tidak dapat dilebih-lebihkan. Proliferasi teknologi data baru di ruang ini telah mengganggu solusi yang setelah secara eksklusif bergantung pada database hubungan.
Database NoSQL mencakup beberapa model berbeda untuk mengakses dan mengelola data, masing-masing cocok untuk kasus penggunaan tertentu. Gambar 5-9 menyajikan empat model umum.
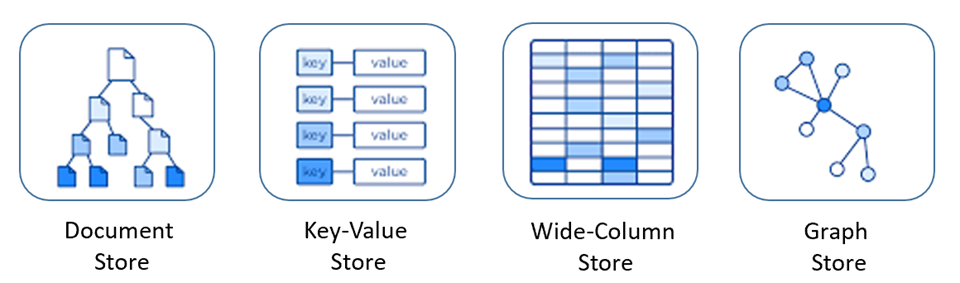
Gambar 5-9: Model data untuk database NoSQL
| Modél | Karakteristik |
|---|---|
| Model Document Store | Data dan metadata disimpan secara hierarkis dalam dokumen berbasis JSON di dalam database. |
| Penyimpanan Nilai Kunci | Database NoSQL yang paling sederhana, data direpresentasikan sebagai kumpulan pasangan nilai kunci. |
| Penyimpanan Kolom Lebar | Data terkait disimpan sebagai set pasangan kunci/nilai berlapis dalam satu kolom. |
| Penyimpanan Grafik | Data disimpan dalam struktur grafik sebagai properti node, edge, dan data. |
Teori CAP dan PACELC
Sebagai cara untuk memahami perbedaan antara jenis database ini, pertimbangkan teorema CAP, serangkaian prinsip yang diterapkan pada sistem terdistribusi yang menyimpan status. Gambar 5-10 menunjukkan tiga properti teorema CAP.
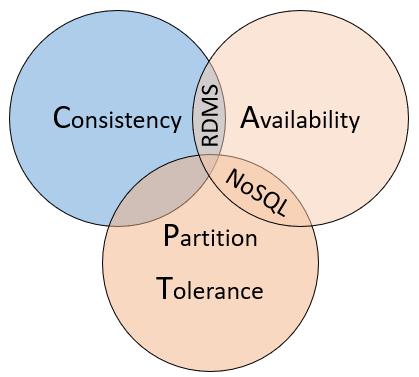
Gambar 5-10. Teorema CAP
Teorema tersebut menyatakan bahwa sistem data terdistribusi akan menawarkan trade-off antara konsistensi, ketersediaan, dan toleransi partisi. Selain itu, bahwa database apa pun hanya dapat menjamin dua dari tiga properti:
Konsistensi. Setiap node dalam kluster merespons dengan data terbaru, bahkan jika sistem harus memblokir permintaan sampai semua replika diperbarui. Jika Anda mengkueri "sistem konsisten" untuk item yang saat ini diperbarui, Anda akan menunggu respons tersebut hingga semua replika berhasil diperbarui. Namun, Anda akan menerima data terbaru. Harus dipahami bahwa istilah "konsistensi" seperti yang digunakan dalam konteks teori CAP memiliki arti teknis yang berbeda dari cara "konsistensi" didefinisikan dalam konteks jaminan ACID.
Ketersediaan. Setiap permintaan yang diterima oleh node yang tidak gagal dalam sistem harus menghasilkan respons. Sederhananya, jika Anda mengkueri "sistem yang tersedia" untuk item yang diperbarui, Anda akan mendapatkan jawaban terbaik yang dapat diberikan layanan pada saat itu. Tetapi perhatikan bahwa "ketersediaan" seperti yang didefinisikan oleh teori CAP secara teknis berbeda dari "ketersediaan tinggi" karena secara konvensional dikenal untuk sistem terdistribusi.
Toleransi Partisi. Menjamin sistem terus beroperasi meskipun node data yang direplikasi gagal atau kehilangan konektivitas dengan node data lain yang direplikasi.
Teorema CAP menjelaskan tradeoff yang terkait dengan pengelolaan konsistensi dan ketersediaan selama partisi jaringan; namun tradeoff sehubungan dengan konsistensi dan performa juga ada tanpa partisi jaringan.
Catatan
Bahkan jika Anda memilih ketersediaan daripada konsistensi, pada saat partisi jaringan, ketersediaan akan menderita. Sistem CAP yang tersedia lebih tersedia untuk beberapa kliennya tetapi belum tentu "sangat tersedia" untuk semua kliennya.
Teorema CAP sering diperluas lebih lanjut ke PACELC untuk menjelaskan tradeoff secara lebih komprehensif. Teori CAP sangat relevan di lingkungan yang terhubung secara terputus-putus, seperti yang terkait dengan Internet of Things (IoT), pemantauan lingkungan, dan aplikasi seluler. Dalam konteks ini, perangkat dapat menjadi dipartisi karena kondisi fisik yang menantang, seperti pemadaman listrik atau saat memasuki ruang terbatas seperti lift. Untuk sistem terdistribusi, seperti aplikasi cloud, lebih tepat untuk menggunakan teori PACELC, yang lebih komprehensif dan mempertimbangkan trade-off seperti latensi dan konsistensi bahkan tanpa adanya partisi jaringan.
Database hubungan biasanya memberikan konsistensi dan ketersediaan, tetapi bukan toleransi partisi. Ini biasanya disediakan untuk satu server dan diskalakan secara vertikal dengan menambahkan lebih banyak sumber daya ke komputer.
Banyak sistem database hubungan mendukung fitur replikasi bawaan di mana salinan database utama dapat dilakukan ke instans server sekunder lainnya. Operasi tulis dilakukan ke instans utama dan direplikasi ke masing-masing sekunder. Setelah kegagalan, instans utama dapat melakukan failover ke sekunder untuk memberikan ketersediaan tinggi. Sekunder juga dapat digunakan untuk mendistribusikan operasi baca. Meskipun operasi tulis selalu bertentangan dengan replika utama, operasi baca dapat dirutekan ke salah satu sekunder untuk mengurangi beban sistem.
Data juga dapat dipartisi secara horizontal di beberapa node, seperti dengan sharding. Tetapi, sharding secara dramatis meningkatkan overhead operasional dengan memisahkan data di berbagai bagian yang tidak dapat dengan mudah berkomunikasi. Ini mungkin mahal dan memakan waktu untuk dikelola. Fitur relasional yang mencakup gabungan tabel, transaksi, dan integritas referensial memerlukan penalti performa yang tajam dalam penyebaran yang dipecah.
Konsistensi replikasi dan tujuan titik pemulihan dapat disetel dengan mengonfigurasi apakah replikasi terjadi secara sinkron atau asinkron. Jika replika data kehilangan konektivitas jaringan dalam kluster database hubungan yang "sangat konsisten" atau sinkron, Anda tidak akan dapat menulis ke database. Sistem akan menolak operasi tulis karena tidak dapat mereplikasi perubahan tersebut ke replika data lainnya. Setiap replika data harus diperbarui sebelum transaksi dapat selesai.
Database NoSQL biasanya mendukung ketersediaan tinggi dan toleransi partisi. Ini melakukan penskalaan secara horizontal, seringkali di seluruh server komoditas. Pendekatan ini memberikan ketersediaan yang luar biasa, baik di dalam maupun di seluruh wilayah geografis dengan biaya lebih hemat. Anda mempartisi dan mereplikasi data di seluruh komputer ini, atau node, dengan memberikan redundansi dan toleransi kesalahan. Konsistensi biasanya disetel melalui protokol konsesi atau mekanisme kuorum. Mereka memberikan kontrol lebih saat menavigasi tradeoff antara penyetelan replikasi sinkron versus asinkron dalam sistem relasional.
Jika replika data kehilangan konektivitas dalam kluster database NoSQL "sangat tersedia", Anda masih dapat menyelesaikan operasi tulis ke database. Kluster database akan memungkinkan operasi tulis dan memperbarui setiap replika data saat tersedia. Database NoSQL yang mendukung beberapa replika yang dapat ditulis dapat semakin memperkuat ketersediaan tinggi dengan menghindari kebutuhan akan failover saat mengoptimalkan tujuan waktu pemulihan.
Database NoSQL modern biasanya menerapkan kemampuan partisi sebagai fitur desain sistemnya. Manajemen partisi sering kali bawaan ke database, dan perutean dicapai melalui petunjuk penempatan - sering disebut kunci partisi. Model data yang fleksibel memungkinkan database NoSQL menurunkan beban manajemen skema dan meningkatkan ketersediaan saat menyebarkan pembaruan aplikasi yang memerlukan perubahan model data.
Ketersediaan tinggi dan skalabilitas besar kerap lebih penting bagi bisnis daripada gabungan tabel relasional dan integritas referensial. Pengembang dapat menerapkan teknik dan pola seperti Saga, CQRS, dan olahpesan asinkron untuk meraih konsistensi akhir.
Saat ini perlu berhati-hati dalam mempertimbangkan batasan teorema CAP. Jenis database baru, yang disebut NewSQL, telah muncul yang mana akan memperluas mesin database hubungan untuk mendukung skalabilitas horizontal dan performa sistem NoSQL yang dapat diskalakan.
Pertimbangan untuk sistem relasional vs. NoSQL
Berdasarkan persyaratan data tertentu, layanan mikro berbasis cloud-native dapat mengimplementasikan datastore NoSQL relasional atau keduanya.
| Pertimbangkan datastore NoSQL saat: | Pertimbangkan database hubungan saat: |
|---|---|
| Anda memiliki beban kerja volume tinggi yang memerlukan latensi yang dapat diprediksi dalam skala besar (misalnya, latensi yang diukur dalam milidetik sambil melakukan jutaan transaksi per detik) | Volume beban kerja Anda umumnya cocok dalam ribuan transaksi per detik |
| Data Anda bersifat dinamis dan sering berubah | Data Anda sangat terstruktur dan memerlukan integritas referensial |
| Hubungan dapat berupa model data yang dinormalisasi | Hubungan dinyatakan melalui gabungan tabel pada model data yang dinormalisasi |
| Pengambilan datanya sederhana dan dinyatakan tanpa gabungan tabel | Anda bekerja dengan kueri dan laporan yang kompleks |
| Data biasanya direplikasi di seluruh geografis dan memerlukan kontrol yang lebih baik atas konsistensi, ketersediaan, dan performa | Data biasanya terpusat, atau dapat direplikasi secara asinkron |
| Aplikasi Anda akan disebarkan ke perangkat keras komoditas, seperti dengan cloud publik | Aplikasi Anda akan disebarkan ke perangkat keras kelas atas yang besar |
Di bagian berikutnya, kita akan menjelajahi opsi yang tersedia di cloud Azure untuk menyimpan dan mengelola data cloud-native Anda.
Basis Data sebagai Layanan
Untuk memulai, Anda dapat menyediakan komputer virtual Azure dan menginstal database pilihan Anda untuk setiap layanan. Meskipun Anda akan memiliki kontrol penuh atas lingkungan, Anda akan melewati berbagai fitur bawaan platform cloud. Anda juga akan bertanggung jawab untuk mengelola mesin virtual dan database untuk setiap layanan. Pendekatan ini dapat memakan waktu dan mahal dengan cepat.
Sebaliknya, aplikasi cloud-native mendukung layanan data yang diekspos sebagai Database as a Service (DBaaS). Dikelola penuh oleh vendor cloud, layanan ini menyediakan keamanan, skalabilitas, dan pemantauan bawaan. Anda cukup menggunakannya sebagai layanan cadangan, bukan memiliki layanan tersebut. Penyedia mengoperasikan sumber daya dalam skala besar dan bertanggung jawab atas performa dan pemeliharaan.
Mereka dapat dikonfigurasi di seluruh zona dan wilayah ketersediaan cloud untuk mencapai ketersediaan tinggi. Semuanya mendukung kapasitas just-in-time dan model bayar sesuai penggunaan. Azure menampilkan berbagai jenis opsi layanan data terkelola, masing-masing dengan manfaat tertentu.
Pertama-tama kita akan melihat layanan DBaaS relasional yang tersedia di Azure. Anda akan mengetahui bahwa database SQL Server unggulan Microsoft tersedia bersama dengan beberapa opsi sumber terbuka. Kemudian, kita akan berbicara tentang layanan data NoSQL di Azure.
Database hubungan Azure
Untuk layanan mikro cloud-native yang memerlukan data relasional, Azure menawarkan empat penawaran database hubungan terkelola sebagai layanan (DBaaS), yang ditunjukkan pada Gambar 5-11.

Gambar 5-11. Database hubungan terkelola yang tersedia di Azure
Dalam gambar sebelumnya, perhatikan bagaimana masing-masing berada di atas infrastruktur DBaaS umum yang menampilkan kemampuan utama tanpa biaya tambahan.
Fitur-fitur ini sangat penting bagi organisasi yang menyediakan sejumlah besar database, tetapi memiliki sumber daya terbatas untuk mengelolanya. Anda dapat menyediakan database Azure dalam hitungan menit dengan memilih jumlah inti pemrosesan, memori, dan penyimpanan yang mendasar. Anda dapat menskalakan database dengan cepat dan menyesuaikan sumber daya secara dinamis dengan sedikit atau tanpa waktu henti.
Database Azure SQL
Tim pengembangan dengan keahlian dalam Microsoft SQL Server harus mempertimbangkan Azure SQL Database. Ini adalah database hubungan sebagai layanan (DBaaS) yang dikelola penuh berdasarkan Mesin Database Microsoft SQL Server. Layanan ini berbagi banyak fitur yang ditemukan dalam versi SQL Server lokal dan menjalankan versi stabil terbaru dari Mesin Database SQL Server.
Untuk penggunaan dengan layanan mikro cloud-native, Azure SQL Database tersedia dengan tiga opsi penyebaran:
Database Tunggal mewakili SQL Database yang dikelola penuh yang beroperasi pada server Azure SQL Database di cloud Azure. Database dianggap berisi karena tidak memiliki dependensi konfigurasi pada server database yang mendasar.
Managed Instance adalah instans terkelola penuh dari Mesin Database Microsoft SQL Server yang menyediakan kompatibilitas nyaris 100% dengan SQL Server lokal. Opsi ini mendukung database yang lebih besar, hingga 35 TB dan ditempatkan di Azure Virtual Network untuk isolasi yang lebih baik.
Azure SQL Database tanpa server adalah tier komputasi untuk database tunggal yang secara otomatis melakukan penskalaan berdasarakan permintaan beban kerja. Biaya yang dibebankan hanya sejumlah komputasi yang digunakan per detik. Layanan ini sangat cocok untuk beban kerja dengan pola penggunaan yang terputus-putus dan tidak dapat diprediksi, diselingi dengan periode tidak aktif. Tingkat komputasi tanpa server juga secara otomatis menjeda database selama periode tidak aktif sehingga hanya penyimpanan yang ditagih yang dibebankan. Ini secara otomatis melanjutkan ketika aktivitas kembali.
Di luar tumpukan Microsoft SQL Server tradisional, Azure juga menampilkan versi terkelola dari tiga database sumber terbuka populer.
Database sumber terbuka di Azure
Database hubungan sumber terbuka telah menjadi pilihan populer untuk aplikasi cloud-native. Banyak perusahaan lebih memilihnya daripada produk database komersial, terutama demi penghematan biaya. Banyak tim pengembangan menikmati fleksibilitasnya, pengembangan yang didukung komunitas, dan ekosistem alat dan ekstensi. Database sumber terbuka dapat disebarkan di beberapa penyedia cloud, membantu meminimalkan kekhawatiran "penguncian vendor."
Pengembang dapat dengan mudah menghost sendiri database sumber terbuka mana pun di VM Azure. Selagi memberikan kontrol penuh, pendekatan memberi komitmen kepada Anda atas manajemen, pemantauan, dan pemeliharaan database dan VM.
Namun, Microsoft melanjutkan komitmennya untuk mempertahankan Azure sebagai "platform terbuka" dengan menawarkan beberapa database sumber terbuka populer sebagai layanan DBaaS yang dikelola penuh.
Azure Database untuk MySQL
MySQL adalah database hubungan sumber terbuka dan pilar bagi aplikasi yang dibuat di tumpukan perangkat lunak LAMP. Banyak dipilih untuk beban kerja baca berat, ini digunakan oleh banyak organisasi besar, termasuk Facebook, Twitter, dan YouTube. Edisi komunitas tersedia secara gratis, sementara edisi perusahaan memerlukan pembelian lisensi. Awalnya dibuat pada tahun 1995, produk ini dibeli oleh Sun Microsystems pada tahun 2008. Oracle mengakuisisi Sun dan MySQL pada tahun 2010.
Azure Database for MySQL adalah layanan database hubungan yang terkelola berdasarkan mesin MySQL Server sumber terbuka. Ini menggunakan edisi Komunitas MySQL. Server MySQL Azure adalah titik administratif untuk layanan. Ini adalah mesin server MySQL yang sama seperti yang digunakan untuk penyebaran lokal. Mesin tersebut dapat membuat database tunggal per server atau beberapa database per server yang berbagi sumber daya. Anda dapat terus mengelola data menggunakan alat sumber terbuka yang sama tanpa harus mempelajari keterampilan baru atau mengelola mesin virtual.
Azure Database untuk MariaDB
Server MariaDB adalah server database sumber terbuka populer lainnya. Ini dibuat sebagai fork MySQL ketika Oracle membeli Sun Microsystems, yang memiliki MySQL. Tujuannya adalah untuk memastikan bahwa MariaDB tetap bersumber terbuka. Karena MariaDB adalah fork MySQL, definisi data dan tabel kompatibel, dan protokol klien, struktur, serta API, terkait erat.
MariaDB memiliki komunitas yang kuat dan digunakan oleh banyak perusahaan besar. Selagi Oracle terus mempertahankan, meningkatkan, dan mendukung MySQL, yayasan MariaDB mengelola MariaDB, memungkinkan kontribusi publik terhadap produk dan dokumentasi.
Azure Database for MariaDB adalah database hubungan yang dikelola penuh sebagai layanan dalam cloud Azure. Layanan tersebut didasarkan pada mesin server edisi komunitas MariaDB. Ini dapat menangani beban kerja misi-kritis dengan performa yang dapat diprediksi dan skalabilitas yang dinamis.
Azure Database untuk PostgreSQL
PostgreSQL adalah database hubungan sumber terbuka dengan lebih dari 30 tahun pengembangan aktif. PostgreSQL memiliki reputasi yang kuat untuk keandalan dan integritas data. Fiturnya kaya, sesuai dengan SQL, dan dianggap lebih berfungsi daripada MySQL - terutama untuk beban kerja dengan kueri kompleks dan penulisan berat. Banyak perusahaan besar termasuk Apple, Red Hat, dan Fujitsu telah membuat produk menggunakan PostgreSQL.
Azure Database for PostgreSQL adalah layanan database hubungan yang dikelola penuh, berdasarkan komputer database Postgres sumber terbuka. Layanan ini mendukung berbagai platform pengembangan, termasuk C++, Java, Python, Node, C#, dan PHP. Anda dapat memigrasikan database PostgreSQL ke database tersebut menggunakan alat antarmuka baris perintah atau Azure Data Migration Service.
Azure Database for PostgreSQL tersedia dengan dua opsi pengembangan:
Opsi penyebaran Server Tunggal adalah titik administratif pusat untuk beberapa database tempat Anda dapat menyebarkan berbagai database. Harga disusun per server berdasarkan inti dan penyimpanan.
Opsi Hyperscale (Citus) didukung oleh teknologi Citus Data. Ini memungkinkan performa tinggi dengan menskalakan secara horizontal database tunggal di ratusan node demi memberikan performa dan skala dengan cepat. Opsi ini memungkinkan mesin untuk menyesuaikan lebih banyak data dalam memori, menyejajarkan kueri di ratusan node, dan mengindeks data lebih cepat.
Data NoSQL di Azure
Cosmos DB adalah layanan database NoSQL yang dikelola penuh dan didistribusikan secara global di cloud Azure. Ini telah diadopsi oleh banyak perusahaan besar di seluruh dunia, termasuk Coca-Cola, Skype, ExxonMobil, dan Liberty Mutual.
Jika layanan Anda memerlukan respons cepat dari mana saja di dunia, ketersediaan tinggi, atau skalabilitas elastis, Cosmos DB adalah pilihan yang bagus. Gambar 5-12 menunjukkan Cosmos DB.
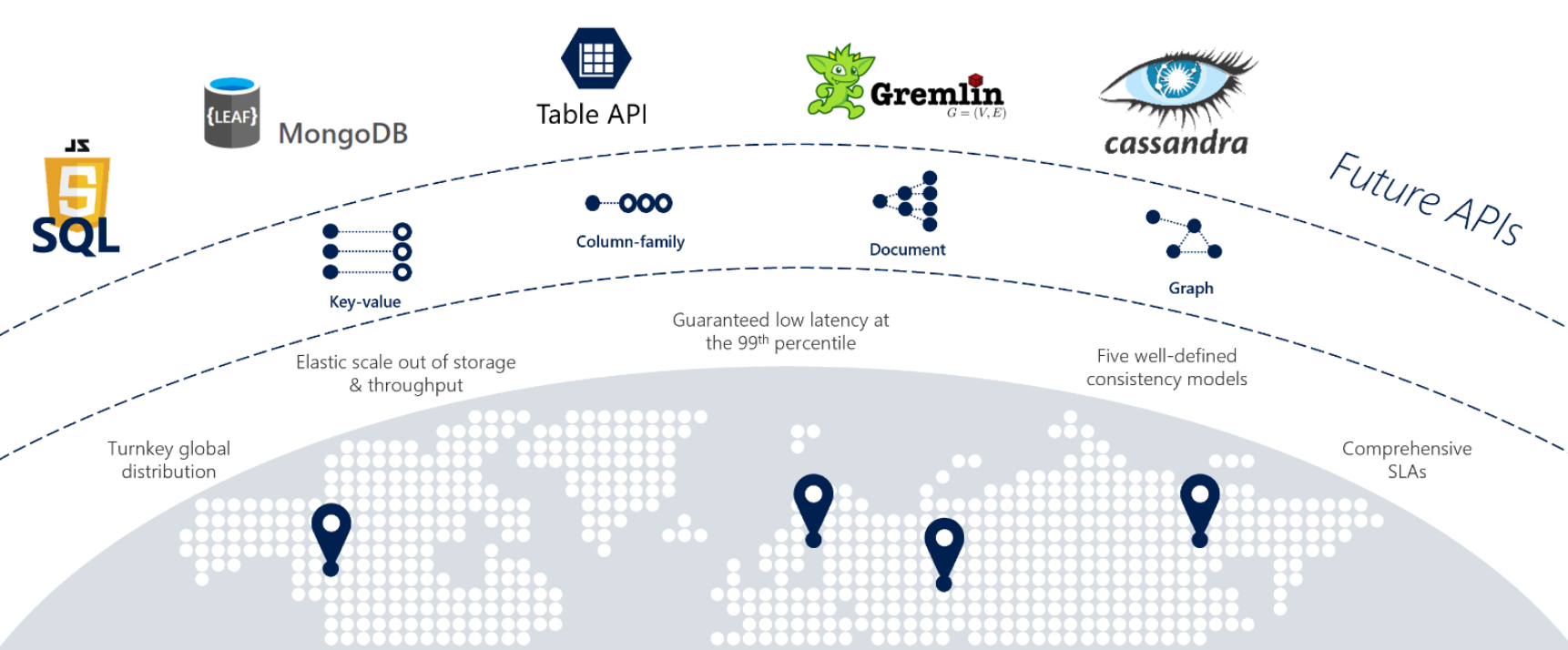
Gambar 5-12: Gambaran Umum Azure Cosmos DB
Gambar sebelumnya menyajikan berbagai kemampuan cloud-native bawaan yang tersedia di Cosmos DB. Di bagian ini, kita akan melihat secara lebih detail.
Dukungan global
Aplikasi cloud-native sering memiliki audiens global dan memerlukan skala global.
Anda dapat mendistribusikan database Cosmos di seluruh wilayah atau di seluruh dunia, menempatkan data yang dekat dengan pengguna Anda, meningkatkan waktu respons, dan mengurangi latensi. Anda dapat menambahkan atau menghapus database dari wilayah tanpa menjeda atau menyebarkan ulang layanan Anda. Di latar belakang, Cosmos DB secara transparan mereplikasi data ke setiap wilayah yang dikonfigurasi.
Cosmos DB mendukung pengklusteran aktif/aktif di tingkat global, memungkinkan Anda mengonfigurasi salah satu wilayah database Anda untuk mendukung tulis dan baca.
Protokol tulis multi-wilayah adalah fitur penting di Cosmos DB yang memungkinkan fungsionalitas berikut:
Tulis elastis dan skalabilitas baca tanpa batas.
99.999% membaca dan menulis ketersediaan di seluruh dunia.
Dijamin membaca dan menulis disajikan dalam waktu kurang dari 10 milidetik pada persentil ke-99.
Dengan API Multi-Homing Cosmos DB, layanan mikro Anda secara otomatis mengetahui wilayah Azure terdekat dan mengirim permintaan ke sana. Wilayah terdekat diidentifikasi oleh Cosmos DB tanpa perubahan konfigurasi. Jika suatu wilayah menjadi tidak tersedia, fitur Multi-Homing akan secara otomatis merutekan permintaan ke wilayah terdekat berikutnya yang tersedia.
Dukungan multi-model
Saat mereplatformasi aplikasi monolitik ke arsitektur cloud-native, tim pengembangan terkadang harus memigrasikan penyimpanan data NoSQL sumber terbuka. Cosmos DB dapat membantu Anda mempertahankan investasi Anda dalam datastore NoSQL ini dengan platform data multi-model miliknya. Tabel berikut ini memperlihatkan API kompatibilitas NoSQL yang didukung.
| Penyedia | Deskripsi |
|---|---|
| NoSQL API | API untuk NoSQL menyimpan data dalam format dokumen |
| API Mongo DB | Mendukung API Mongo DB dan dokumen JSON |
| Gremlin API | Mendukung API Gremlin dengan node berbasis grafik dan representasi data tepi |
| Cassandra API | Mendukung API Casandra untuk representasi data kolom lebar |
| API Tabel | Mendukung Azure Table Storage dengan peningkatan premium |
| PostgreSQL API | Layanan terkelola untuk menjalankan PostgreSQL dalam skala apa pun |
Tim pengembangan dapat memigrasikan database Mongo, Gremlin, atau Cassandra yang ada ke Cosmos DB dengan perubahan minimal pada data atau kode. Untuk aplikasi baru, tim pengembangan dapat memilih di antara opsi sumber terbuka atau model API SQL bawaan.
Secara internal, Cosmos menyimpan data dalam format struktur sederhana yang terdiri dari jenis data primitif. Untuk setiap permintaan, mesin database menerjemahkan data primitif ke dalam representasi model yang telah Anda pilih.
Di tabel sebelumnya, perhatikan opsi API Table. API ini adalah evolusi Azure Table Storage. Keduanya memiliki model tabel mendasar yang sama, tetapi API Table Cosmos DB menambahkan peningkatan premium yang tidak tersedia di API Azure Storage. Tabel berikut ini membedakan fitur.
| Fitur | Penyimpanan Tabel Azure | Azure Cosmos DB (layanan basis data global dari Microsoft) |
|---|---|---|
| Latensi | Cepat | Latensi milidetik satu digit untuk baca dan tulis di mana pun di dunia |
| Daya Tampung | Batas 20.000 operasi per tabel | Operasi tidak terbatas per tabel |
| Distribusi Global | Wilayah tunggal dengan wilayah baca sekunder tunggal opsional | Distribusi turnkey ke semua wilayah dengan failover otomatis |
| Pengindeksan | Hanya tersedia untuk properti kunci baris dan partisi | Pengindeksan otomatis semua properti |
| Harga | Dioptimalkan untuk beban kerja dingin (throughput rendah : rasio penyimpanan) | Dioptimalkan untuk beban kerja panas (throughput tinggi : rasio penyimpanan) |
Layanan mikro yang menggunakan Azure Table Storage dapat dengan mudah bermigrasi ke API Table Cosmos DB. Tidak ada perubahan kode yang diperlukan.
Tingkat konsistensi yang dapat disetel
Sebelumnya di bagian Relasional vs. NoSQL, kami membahas subjek konsistensi data. Konsistensi data mengacu pada integritas data Anda. Layanan cloud-native dengan data terdistribusi mengandalkan replikasi dan harus membuat tradeoff mendasar antara konsistensi baca, ketersediaan, dan latensi.
Sebagian besar database terdistribusi memungkinkan pengembang untuk memilih antara dua model konsistensi: konsistensi yang kuat dan konsistensi akhir. Konsistensi kuat adalah standar emas bagi keterprograman data. Ini menjamin bahwa kueri akan selalu mengembalikan data terbaru - bahkan jika sistem harus menimbulkan latensi yang sedang menunggu pembaruan untuk direplikasi di semua salinan database. Meskipun database yang dikonfigurasi untuk konsistensi akhir akan segera mengembalikan data, bahkan jika data tersebut bukan salinan terbaru. Opsi terakhir memungkinkan ketersediaan yang lebih tinggi, skala yang lebih besar, dan peningkatan performa.
Azure Cosmos DB menawarkan lima model konsistensi yang terdefinisi dengan baik yang ditunjukkan pada Gambar 5-13.

Gambar 5-13: Tingkat Konsistensi Cosmos DB
Opsi ini memungkinkan Anda membuat pilihan yang tepat dan tradeoff terperinci untuk konsistensi, ketersediaan, dan performa untuk data Anda. Tingkatnya disajikan dalam tabel berikut.
| Tingkat Konsistensi | Deskripsi |
|---|---|
| Peristiwa | Tidak ada jaminan pemesanan untuk pembacaan. Replika pada akhirnya akan bertemu. |
| Awalan Konstanta | Bacaan masih bersifat eventual, tetapi data dikembalikan dalam urutan penulisannya. |
| Sesi | Menjamin Anda dapat membaca data apa pun yang ditulis selama sesi saat ini. Ini adalah tingkat konsistensi default. |
| Keusangan Terikat | Jejak baca menulis berdasarkan interval yang Anda tentukan. |
| Kuat | Bacaan dijamin mengembalikan versi terbaru dari suatu item. Klien tidak pernah melihat tulisan yang belum diterapkan atau sebagian. |
Dalam artikel Di Balik 9-Ball: Penjelasan Tingkat Konsistensi Cosmos DB, Microsoft Program Manager Jeremy Likness memberikan penjelasan yang sangat jelas tentang lima model tersebut.
Partisi
Azure Cosmos DB mendukung pembuatan partisi untuk menskalakan database guna memenuhi kebutuhan performa layanan cloud-native Anda.
Anda mengelola data dalam data Cosmos DB dengan membuat database, kontainer, dan item.
Kontainer berada dalam database Cosmos DB dan mewakili pengelompokan item skema-agnostik. Item adalah data yang Anda tambahkan ke kontainer. ini direpresentasikan sebagai dokumen, baris, node, atau tepi. Semua item yang ditambahkan ke kontainer secara otomatis diindeks.
Untuk membuat partisi kontainer, item dibagi menjadi beberapa subset yang berbeda, yang disebut partisi logis. Partisi logis diisi berdasarkan nilai kunci partisi yang terkait dengan setiap item dalam kontainer. Gambar 5-14 menunjukkan dua kontainer masing-masing dengan partisi logis berdasarkan nilai kunci partisi.
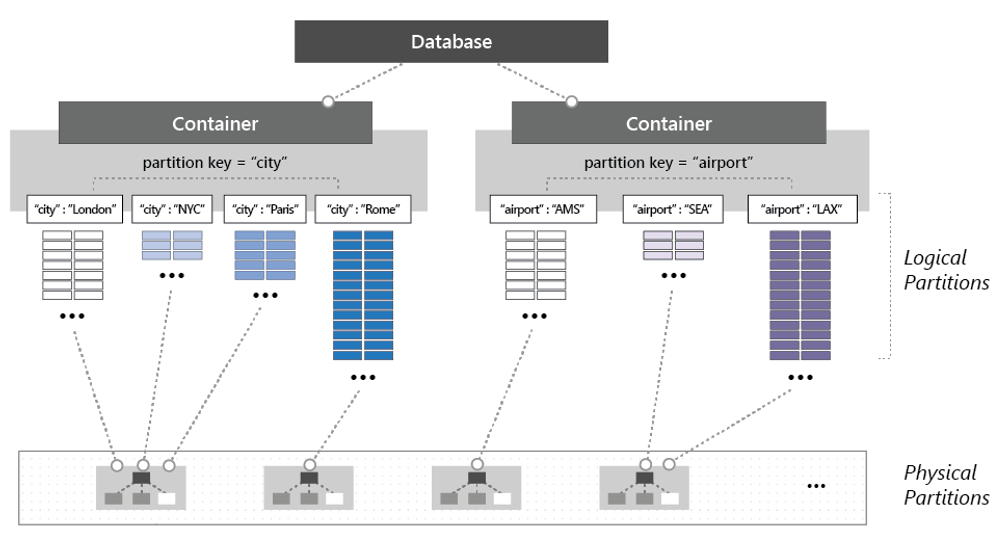
Gambar 5-14: Mekanika partisi Cosmos DB
Perhatikan pada gambar sebelumnya bagaimana setiap item menyertakan kunci partisi baik dari 'kota' atau 'bandara'. Kunci menentukan partisi logis item. Item dengan kode kota ditetapkan ke kontainer di sebelah kiri, dan item dengan kode bandara, ke kontainer di sebelah kanan. Penggabungan nilai kunci partisi dengan nilai ID akan menghasilkan indeks item, yang secara unik mengidentifikasi item tersebut.
Secara internal, Cosmos DB secara otomatis mengelola penempatan partisi logis pada partisi fisik untuk memenuhi kebutuhan skalabilitas dan performa dari kontainer. Seiring dengan meningkatnya throughput aplikasi dan kebutuhan penyimpanan, Azure Cosmos DB mendistribusikan ulang partisi logis pada banyak server. Operasi distribusi ulang dikelola oleh Cosmos DB dan dipanggil tanpa gangguan atau waktu henti.
Database NewSQL
NewSQL adalah teknologi database baru yang menggabungkan skalabilitas NoSQL terdistribusi dengan jaminan ACID dari database hubungan. Database NewSQL penting bagi sistem bisnis yang harus memproses data dalam volume tinggi, di seluruh lingkungan terdistribusi, dengan dukungan transaksional penuh dan kepatuhan ACID. Meskipun database NoSQL dapat memberikan skalabilitas besar-besaran, database tidak menjamin konsistensi data. Masalah terputus-terputus dari data yang tidak konsisten dapat memberikan beban pada tim pengembangan. Pengembang harus menyusun perlindungan ke dalam kode layanan mikro mereka untuk mengelola masalah yang disebabkan oleh data yang tidak konsisten.
Cloud Native Computing Foundation (CNCF) menampilkan beberapa proyek database NewSQL.
| Proyek | Karakteristik |
|---|---|
| Cockroach DB | Database hubungan yang mematuhi ACID yang diskalakan secara global. Tambahkan node baru ke kluster dan CockroachDB akan mengurus penyeimbangan data di seluruh instans dan geografis. Ini menciptakan, mengelola, dan mendistribusikan replika guna memastikan keandalan. Ini adalah sumber terbuka dan tersedia secara bebas. |
| TiDB | Database sumber terbuka yang mendukung beban kerja Hybrid Transactional and Analytical Processing (HTAP). Ini kompatibel dengan MySQL dan memiliki skalabilitas horizontal, konsistensi yang kuat, dan ketersediaan tinggi. TiDB bertindak seperti server MySQL. Anda dapat terus menggunakan pustaka klien MySQL yang ada, tanpa memerlukan perubahan kode yang luas pada aplikasi Anda. |
| YugabyteDB | Database SQL sumber terbuka, dengan performa tinggi, dan terdistribusi. Ini mendukung latensi kueri yang rendah, ketahanan terhadap kegagalan, dan distribusi data global. YugabyteDB kompatibel dengan PostgreSQL dan menangani beban kerja RDBMS dan OLTP skala internet. Produk ini juga mendukung NoSQL dan kompatibel dengan Cassandra. |
| Vitess | Vitess adalah solusi database untuk menyebarkan, menskalakan, dan mengelola kluster besar instans MySQL. Ini dapat berjalan dalam arsitektur cloud publik atau privat. Vitess menggabungkan dan memperluas berbagai fitur MySQL penting dan menampilkan dukungan sharding vertikal dan horizontal. Bermula dari YouTube, Vitess telah melayani semua lalu lintas database YouTube sejak 2011. |
Proyek sumber terbuka pada gambar sebelumnya tersedia dari Cloud Native Computing Foundation. Tiga penawaran yang diberikan adalah produk database lengkap, yang mencakup dukungan .NET. Yang lain, Vitess, adalah sistem pengklusteran database yang secara horizontal menskalakan kluster besar instans MySQL.
Tujuan desain utama untuk database NewSQL adalah bekerja secara native di Kubernetes, memanfaatkan ketahanan dan skalabilitas platform.
Database NewSQL dirancang agar berkembang di lingkungan cloud tempat komputer virtual yang mendasar dapat dimulai ulang atau dijadwalkan ulang pada pemberitahuan sesaat. Database dirancang agar bertahan dari kegagalan node tanpa kehilangan data atau waktu henti. CockroachDB, misalnya, mampu bertahan dari kehilangan komputer dengan mempertahankan tiga replika data yang konsisten di seluruh node dalam kluster.
Kubernetes menggunakan Konstruksi layanan untuk memungkinkan klien mengatasi sekelompok proses database NewSQL yang identik dari satu entri DNS. Dengan memisahkan instans database dari alamat layanan yang terkait dengannya, kita dapat menskalakan tanpa mengganggu instans aplikasi yang ada. Mengirim permintaan ke layanan apa pun pada waktu tertentu akan selalu menciptakan hasil yang sama.
Dalam skenario ini, semua instans database sama. Tidak ada hubungan primer atau sekunder. Teknik seperti replikasi konensus yang ditemukan dalam CockroachDB memungkinkan node database mana pun menangani permintaan apa pun. Jika node yang menerima permintaan dengan beban seimbang memiliki data yang dibutuhkan secara lokal, node tersebut akan segera merespons. Jika tidak, node menjadi gateway dan meneruskan permintaan ke node yang sesuai untuk mendapatkan jawaban yang benar. Dari perspektif klien, setiap node database sama: Node ini muncul sebagai database logis tunggal dengan jaminan konsistensi sistem komputer tunggal, meskipun memiliki puluhan atau bahkan ratusan node yang bekerja di belakang layar.
Untuk melihat secara mendetail mekanisme di balik database NewSQL, lihat artikel DASH: Empat Properti Database Kubernetes-Native.
Migrasi data ke cloud
Salah satu tugas yang lebih memakan waktu adalah memigrasikan data dari satu platform data ke platform data lainnya. Azure Data Migration Service dapat membantu mempercepat upaya tersebut. Ini dapat memigrasikan data dari beberapa sumber database eksternal ke platform Azure Data dengan waktu henti minimal. Platform target mencakup layanan berikut:
- Database Azure SQL
- Azure Database untuk MySQL
- Azure Database untuk MariaDB
- Azure Database untuk PostgreSQL
- Azure Cosmos DB (layanan basis data global dari Microsoft)
Layanan ini memberikan rekomendasi untuk memandu Anda melalui perubahan yang diperlukan untuk menjalankan migrasi, baik kecil maupun besar.
Berkolaborasi dengan kami di GitHub
Sumber untuk konten ini dapat ditemukan di GitHub, yang juga dapat Anda gunakan untuk membuat dan meninjau masalah dan menarik permintaan. Untuk informasi selengkapnya, lihat panduan kontributor kami.