Cara membuat definisi kerja Apache Spark di Fabric
Dalam tutorial ini, pelajari cara membuat definisi kerja Spark di Microsoft Fabric.
Prasyarat
Sebelum memulai, Anda memerlukan:
- Akun penyewa Fabric dengan langganan aktif. Buat akun secara gratis.
Tip
Untuk menjalankan item definisi kerja Spark, Anda harus memiliki file definisi utama dan konteks lakehouse default. Jika Anda tidak memiliki lakehouse, Anda dapat membuatnya dengan mengikuti langkah-langkah di Membuat lakehouse.
Membuat definisi kerja Spark
Proses pembuatan definisi kerja Spark cepat dan sederhana; ada beberapa cara untuk memulai.
Opsi untuk membuat definisi kerja Spark
Ada beberapa cara untuk memulai proses pembuatan:
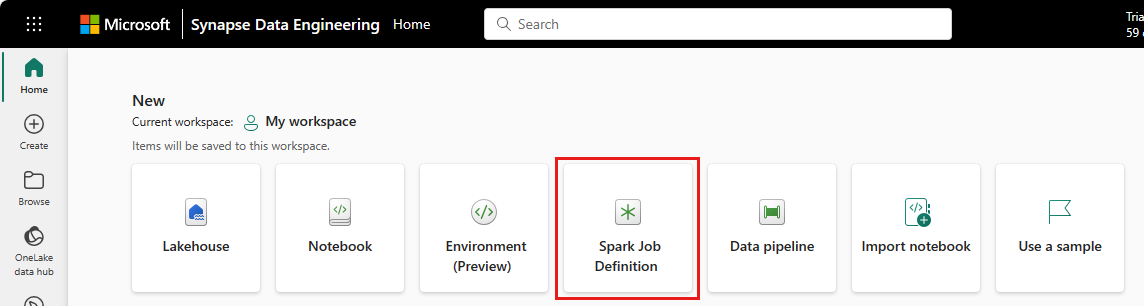
Beranda rekayasa data: Anda dapat dengan mudah membuat definisi kerja Spark melalui kartu Definisi Pekerjaan Spark di bawah bagian Baru di beranda.
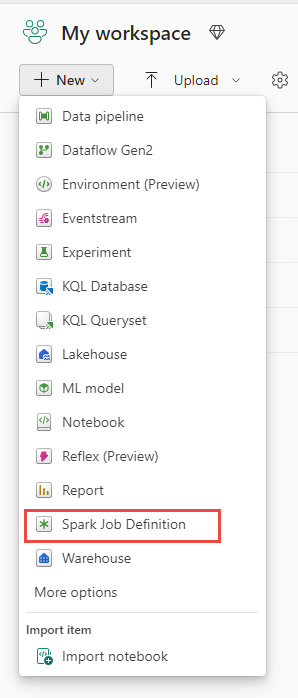
Tampilan ruang kerja: Anda juga dapat membuat definisi pekerjaan Spark melalui tampilan Ruang Kerja saat Anda berada dalam pengalaman Rekayasa Data dengan menggunakan menu dropdown Baru.
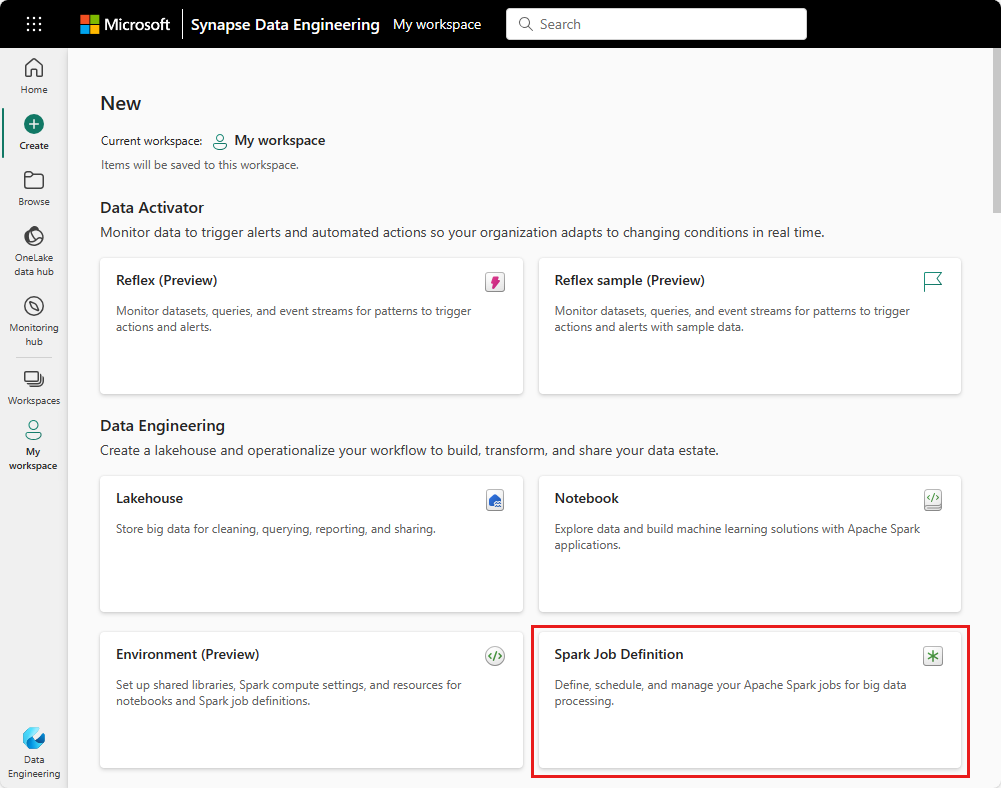
Buat tampilan: Titik entri lain untuk membuat definisi kerja Spark adalah halaman Buat di bawah Rekayasa Data.
Anda perlu memberi nama definisi pekerjaan Spark Anda saat membuatnya. Nama harus unik dalam ruang kerja saat ini. Definisi kerja Spark baru dibuat di ruang kerja Anda saat ini.
Membuat definisi kerja Spark untuk PySpark (Python)
Untuk membuat definisi kerja Spark untuk PySpark:
Unduh sampel file CSV yellow_tripdata_2022_01.csv dan unggah ke bagian file lakehouse.
Buat definisi kerja Spark baru.
Pilih PySpark (Python) dari menu dropdown Bahasa .
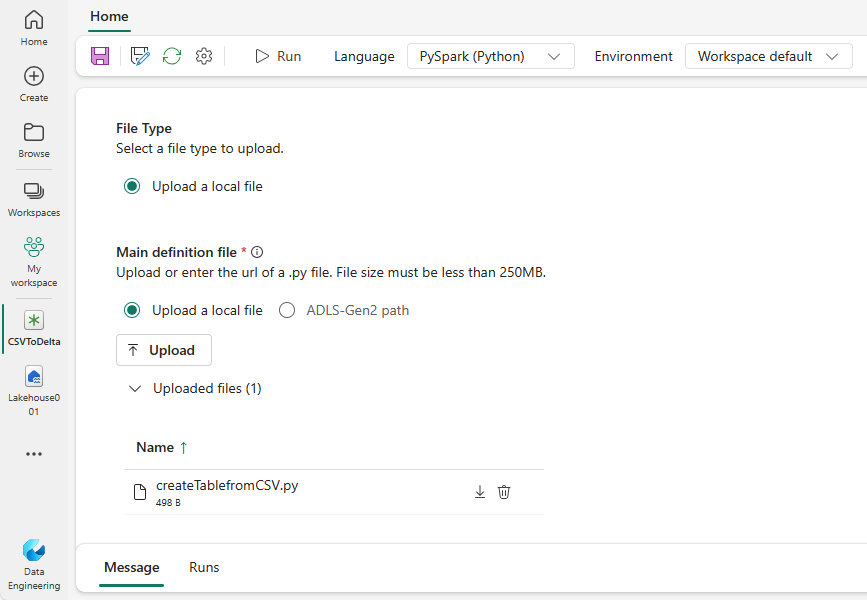
Unduh sampel createTablefromCSV.py dan unggah sebagai file definisi utama. File definisi utama (pekerjaan. Utama) adalah file yang berisi logika aplikasi dan wajib menjalankan pekerjaan Spark. Untuk setiap definisi kerja Spark, Anda hanya dapat mengunggah satu file definisi utama.
Anda dapat mengunggah file definisi utama dari desktop lokal, atau Anda dapat mengunggah dari Azure Data Lake Storage (ADLS) Gen2 yang ada dengan menyediakan jalur ABFSS lengkap file. Contohnya,
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path.Unggah file referensi sebagai file .py . File referensi adalah modul python yang diimpor oleh file definisi utama. Sama seperti file definisi utama, Anda dapat mengunggah dari desktop atau ADLS Gen2 yang ada. Beberapa file referensi didukung.
Tip
Jika Anda menggunakan jalur ADLS Gen2, untuk memastikan file dapat diakses, Anda harus memberi akun pengguna yang menjalankan pekerjaan izin yang tepat ke akun penyimpanan. Kami menyarankan dua cara berbeda untuk melakukan ini:
- Tetapkan akun pengguna peran Kontributor untuk akun penyimpanan.
- Berikan izin Baca dan Eksekusi ke akun pengguna untuk file melalui Daftar Kontrol Akses (ACL) ADLS Gen2.
Untuk eksekusi manual, akun pengguna masuk saat ini digunakan untuk menjalankan pekerjaan.
Berikan argumen baris perintah untuk pekerjaan, jika diperlukan. Gunakan spasi sebagai pemisah untuk memisahkan argumen.
Tambahkan referensi lakehouse ke pekerjaan. Anda harus memiliki setidaknya satu referensi lakehouse yang ditambahkan ke pekerjaan. Lakehouse ini adalah konteks lakehouse default untuk pekerjaan tersebut.
Beberapa referensi lakehouse didukung. Temukan nama lakehouse non-default dan URL OneLake lengkap di halaman Pengaturan Spark.
Membuat definisi kerja Spark untuk Scala/Java
Untuk membuat definisi kerja Spark untuk Scala/Java:
Buat definisi kerja Spark baru.
Pilih Spark(Scala/Java) dari menu dropdown Bahasa .
Unggah file definisi utama sebagai file .jar . File definisi utama adalah file yang berisi logika aplikasi dari pekerjaan ini dan wajib untuk menjalankan pekerjaan Spark. Untuk setiap definisi kerja Spark, Anda hanya dapat mengunggah satu file definisi utama. Berikan nama kelas Utama.
Unggah file referensi sebagai file .jar . File referensi adalah file yang direferensikan/diimpor oleh file definisi utama.
Berikan argumen baris perintah untuk pekerjaan, jika diperlukan.
Tambahkan referensi lakehouse ke pekerjaan. Anda harus memiliki setidaknya satu referensi lakehouse yang ditambahkan ke pekerjaan. Lakehouse ini adalah konteks lakehouse default untuk pekerjaan tersebut.
Membuat definisi kerja Spark untuk R
Untuk membuat definisi kerja Spark untuk SparkR(R):
Buat definisi kerja Spark baru.
Pilih SparkR(R) dari menu dropdown Bahasa .
Unggah file definisi utama sebagai . File R . File definisi utama adalah file yang berisi logika aplikasi dari pekerjaan ini dan wajib untuk menjalankan pekerjaan Spark. Untuk setiap definisi kerja Spark, Anda hanya dapat mengunggah satu file definisi utama.
Unggah file referensi sebagai . File R . File referensi adalah file yang direferensikan/diimpor oleh file definisi utama.
Berikan argumen baris perintah untuk pekerjaan, jika diperlukan.
Tambahkan referensi lakehouse ke pekerjaan. Anda harus memiliki setidaknya satu referensi lakehouse yang ditambahkan ke pekerjaan. Lakehouse ini adalah konteks lakehouse default untuk pekerjaan tersebut.
Catatan
Definisi kerja Spark akan dibuat di ruang kerja Anda saat ini.
Opsi untuk menyesuaikan definisi pekerjaan Spark
Ada beberapa opsi untuk menyesuaikan lebih lanjut eksekusi definisi kerja Spark.
- Spark Compute: Dalam tab Spark Compute , Anda dapat melihat Versi Runtime yang merupakan versi Spark yang akan digunakan untuk menjalankan pekerjaan. Anda juga dapat melihat pengaturan konfigurasi Spark yang akan digunakan untuk menjalankan pekerjaan. Anda dapat menyesuaikan pengaturan konfigurasi Spark dengan mengklik tombol Tambahkan .
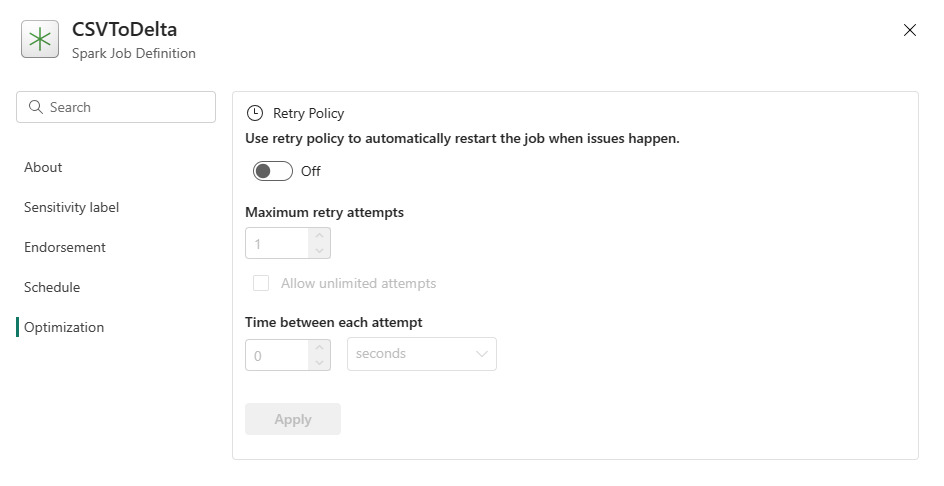
Pengoptimalan: Pada tab Pengoptimalan , Anda dapat mengaktifkan dan menyiapkan Kebijakan Coba Lagi untuk pekerjaan tersebut. Saat diaktifkan, pekerjaan akan dicoba kembali jika gagal. Anda juga dapat mengatur jumlah maksimum percobaan ulang dan interval antara percobaan ulang. Untuk setiap upaya coba lagi, pekerjaan dimulai ulang. Pastikan pekerjaannya idempogen.
Konten terkait
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk