Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Mesin eksekusi asli adalah terobosan untuk peningkatan eksekusi pekerjaan Apache Spark di Microsoft Fabric. Mesin vektorisasi ini mengoptimalkan performa dan efisiensi kueri Spark Anda dengan menjalankannya langsung pada infrastruktur lakehouse Anda. Integrasi yang mulus dari mesin ini berarti tidak memerlukan modifikasi kode dan menghindari ketergantungan pada vendor. Ini mendukung API Apache Spark dan kompatibel dengan Runtime 1.3 (Apache Spark 3.5) dan Runtime 2.0 (Apache Spark 4.0), dan berfungsi dengan format Parquet, Delta, dan CSV. Terlepas dari lokasi data Anda di OneLake, atau jika Anda mengakses data melalui pintasan, mesin eksekusi asli memaksimalkan efisiensi dan performa.
Mesin eksekusi asli secara signifikan meningkatkan performa kueri sambil meminimalkan biaya operasional. Hasil aktual bervariasi menurut karakteristik dan konfigurasi beban kerja. Mesin ini mahir mengelola berbagai skenario pemrosesan data, mulai dari penyerapan data rutin, pekerjaan batch, dan tugas ETL (ekstrak, transformasi, muat), hingga analitik ilmu data yang kompleks dan kueri interaktif responsif. Pengguna mendapat manfaat dari waktu pemrosesan yang dipercepat, throughput yang lebih tinggi, dan pemanfaatan sumber daya yang dioptimalkan.
Native Execution Engine didasarkan pada dua komponen OSS utama: Velox, pustaka akselerasi database C++ yang diperkenalkan oleh Meta, dan Apache Gluten (inkubating), lapisan tengah yang bertanggung jawab untuk membongkar eksekusi mesin SQL berbasis JVM ke mesin asli yang diperkenalkan oleh Intel.
Operator-operator yang didukung dipindahkan dari Spark berbasis JVM ke jalur eksekusi C++ yang vektorisasi, menyediakan pemrosesan kolumnar yang terakselerasi oleh SIMD dengan dukungan langsung untuk format Parquet dan Delta. Mesin bawaan mempertahankan pengoptimalan kueri utama Fabric Spark, termasuk eksekusi kueri adaptif (AQE), penulisan ulang berbasis biaya, pemangkasan kolom, dan pemindahan predikat, sehingga perilaku pengoptimal ini tetap sepenuhnya aktif saat operator dilepaskan. Mesin ini juga mendukung pemuatan snapshot Delta secara paralel dan mempercepat operasi yang mendapat manfaat dari pengurutan Z dan Pengelompokan Cairan pada tabel Delta, memberikan keuntungan performa lebih lanjut untuk tata letak data terorganisir.
Kapan menggunakan mesin eksekusi asli
Mesin eksekusi asli menawarkan solusi untuk menjalankan kueri pada himpunan data skala besar; ini mengoptimalkan performa dengan menggunakan kemampuan asli sumber data yang mendasarinya dan meminimalkan overhead yang biasanya terkait dengan pergerakan dan serialisasi data di lingkungan Spark tradisional. Mesin mendukung berbagai operator dan jenis data, termasuk agregat hash rollup, menyiarkan gabungan perulangan berlapis (BNLJ), dan format tanda waktu yang tepat. Namun, untuk sepenuhnya mendapat manfaat dari kemampuan mesin, Anda harus mempertimbangkan kasus penggunaan optimalnya:
- Mesin ini efektif saat bekerja dengan data dalam format Parquet dan Delta, yang dapat diproses secara asli dan efisien.
- Kueri yang melibatkan transformasi dan agregasi yang rumit mendapat manfaat secara signifikan dari kemampuan pemrosesan dan vektorisasi kolom mesin.
- Peningkatan performa paling penting dalam skenario di mana kueri tidak memicu mekanisme fallback dengan menghindari fitur atau ekspresi yang tidak didukung.
- Mesin ini sangat cocok untuk kueri yang intensif secara komputasi, daripada sederhana atau tergantung pada I/O.
Untuk informasi tentang operator dan fungsi yang didukung oleh mesin eksekusi asli, lihat dokumentasi Apache Gluten.
Mengaktifkan mesin eksekusi asli
Untuk menggunakan kemampuan penuh mesin eksekusi asli selama fase pratinjau, konfigurasi tertentu diperlukan. Prosedur berikut menunjukkan cara mengaktifkan fitur ini untuk notebook, definisi pekerjaan Spark, dan seluruh lingkungan.
Penting
Mesin eksekusi asli mendukung Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2) dan Runtime 2.0 (Apache Spark 4.0, Delta Lake 4.0). Dengan rilis mesin eksekusi asli di Runtime 1.3, dukungan untuk versi sebelumnya, Runtime 1.2 (Apache Spark 3.4, Delta Lake 2.4), dihentikan. Kami mendorong semua pelanggan untuk meningkatkan ke Runtime 1.3 terbaru. Jika Anda menggunakan Native Execution Engine pada Runtime 1.2, akselerasi asli akan dinonaktifkan.
Aktifkan di tingkat lingkungan
Untuk memastikan peningkatan performa seragam, aktifkan mesin eksekusi asli di semua pekerjaan dan notebook yang terkait dengan lingkungan Anda:
Arahkan ke ruang kerja yang berisi lingkungan Anda dan pilih lingkungan tersebut. Jika Anda tidak memiliki lingkungan yang dibuat, lihat Membuat, mengonfigurasi, dan menggunakan lingkungan di Fabric.
Di bawah Komputasi Spark pilih Akselerasi.
Centang kotak berlabel Aktifkan mesin eksekusi asli.
Simpan dan Terbitkan perubahan.
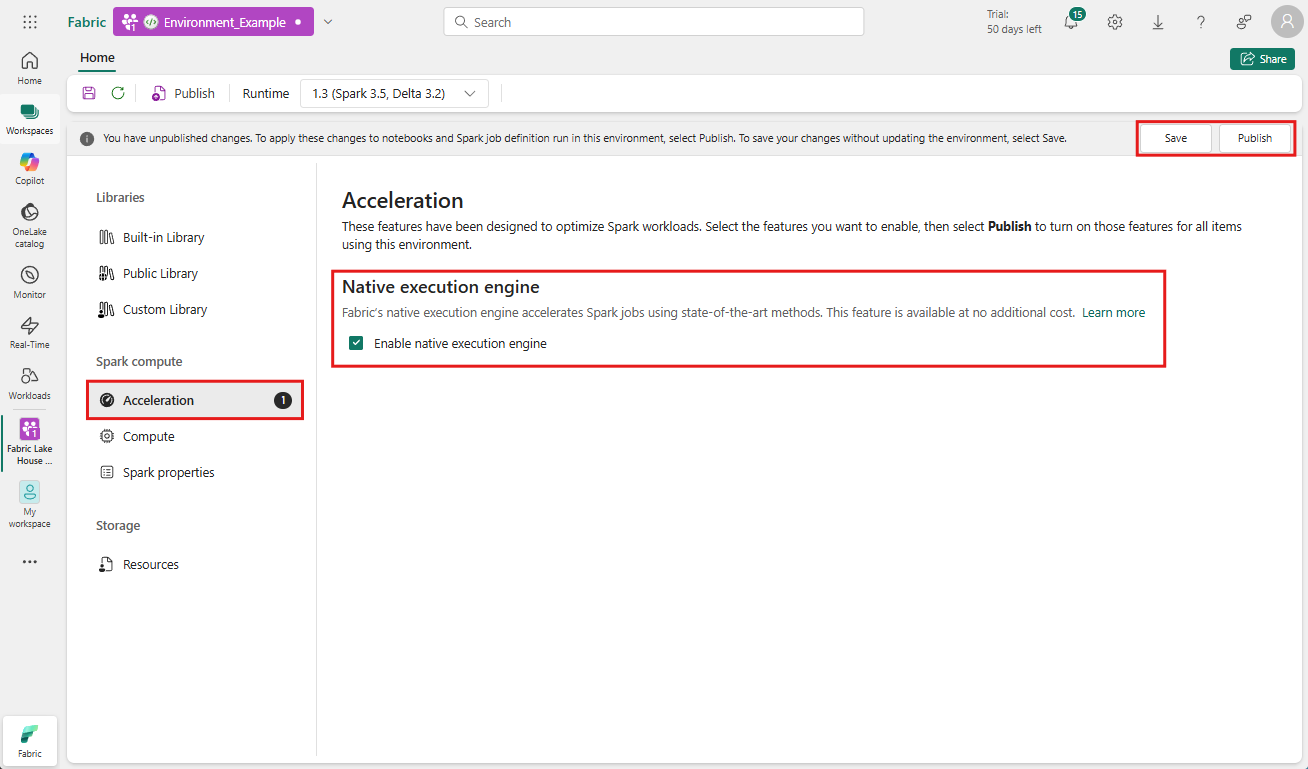

Saat diaktifkan di tingkat lingkungan, semua pekerjaan dan notebook berikutnya mewarisi pengaturan. Pewarisan ini memastikan bahwa sesi atau sumber daya baru yang dibuat di lingkungan secara otomatis mendapat manfaat dari kemampuan eksekusi yang ditingkatkan.
Penting
Sebelumnya, mesin eksekusi asli diaktifkan melalui pengaturan Spark dalam konfigurasi lingkungan. Mesin eksekusi asli sekarang dapat diaktifkan dengan lebih mudah menggunakan tombol di tab Akselerasi pengaturan lingkungan. Untuk terus menggunakannya, buka tab Akselerasi dan aktifkan tombol. Anda juga dapat mengaktifkannya melalui properti Spark jika diinginkan.
Aktifkan untuk notebook atau definisi tugas Spark
Anda juga dapat mengaktifkan mesin eksekusi asli untuk satu notebook atau definisi pekerjaan Spark, Anda harus menggabungkan konfigurasi yang diperlukan di awal skrip eksekusi Anda:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
Untuk buku catatan, sisipkan perintah konfigurasi yang diperlukan di sel pertama. Untuk definisi kerja Spark, sertakan konfigurasi di garis depan definisi kerja Spark Anda. Native Execution Engine terintegrasi dengan pool langsung, jadi setelah Anda mengaktifkan fitur tersebut, fitur tersebut akan langsung berlaku tanpa mengharuskan Anda memulai sesi baru.
Kontrol di tingkat kueri
Mekanisme untuk mengaktifkan Native Execution Engine di tingkat penyewa, ruang kerja, dan lingkungan, terintegrasi dengan UI dengan mulus, sedang dalam pengembangan aktif. Sementara itu, Anda dapat menonaktifkan mesin eksekusi asli untuk kueri tertentu, terutama jika melibatkan operator yang saat ini tidak didukung (lihat batasan). Untuk menonaktifkan, atur konfigurasi Spark spark.native.enabled ke false untuk sel tertentu yang berisi kueri Anda.
%%sql
SET spark.native.enabled=FALSE;

Setelah menjalankan kueri di mana mesin eksekusi asli dinonaktifkan, Anda harus mengaktifkannya kembali untuk sel berikutnya dengan mengatur spark.native.enabled ke true. Langkah ini diperlukan karena Spark menjalankan sel kode secara berurutan.
%%sql
SET spark.native.enabled=TRUE;
Mengidentifikasi operasi yang dijalankan oleh mesin
Ada beberapa metode untuk menentukan apakah operator dalam pekerjaan Apache Spark Anda diproses menggunakan mesin eksekusi asli.
Spark UI dan server riwayat Spark
Akses UI Spark atau server riwayat Spark untuk menemukan kueri yang perlu Anda periksa. Untuk mengakses antarmuka pengguna web Spark, navigasikan ke Definisi Pekerjaan Spark Anda dan jalankan. Dari tab Jalankan, pilih ... di samping Nama aplikasi dan pilih Buka UI web Spark. Anda juga dapat mengakses Spark UI dari monitor tab di ruang kerja. Dari halaman pemantauan, pilih buku catatan atau alur, terdapat tautan langsung ke Spark UI untuk pekerjaan aktif.

Dalam rencana kueri yang ditampilkan dalam antarmuka Spark UI, cari nama node apa pun yang diakhiri dengan akhiran Transformer, *NativeFileScan, atau VeloxColumnarToRowExec. Akhiran menunjukkan bahwa mesin eksekusi bawaan menjalankan operasi. Misalnya, simpul mungkin diberi label sebagai RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer, atau BroadcastNestedLoopJoinExecTransformer. Untuk sumber data CSV, pemindaian asli mungkin muncul sebagai pemindaian file asli atau simpul transformator di UI Spark, mirip dengan node pemindaian Parquet dan Delta.

Penjelasan DataFrame
Atau, Anda dapat menjalankan df.explain() perintah di buku catatan Anda untuk menampilkan rencana eksekusi. Dalam output, cari Transformer yang sama, *NativeFileScan, atau akhiran VeloxColumnarToRowExec. Metode ini menyediakan cara cepat untuk mengonfirmasi apakah operasi tertentu sedang ditangani oleh mesin eksekusi asli.

Pemberitahuan Fabric Spark Advisor
Fabric Spark Advisor memberikan visibilitas fallback real time selama eksekusi sel notebook. Ketika operator atau segmen rencana kembali ke Spark berbasis JVM alih-alih jalur asli, Advisor memunculkan peringatan langsung dalam output sel notebook, membantu Anda mengidentifikasi operator atau konfigurasi yang tidak didukung dengan cepat tanpa meninggalkan lingkungan notebook. Anda dapat menggunakan pemberitahuan ini untuk mendiagnosis kapan offload asli tidak diterapkan dan untuk memutuskan apakah akan menyesuaikan kueri atau konfigurasi Anda.
Mekanisme cadangan
Dalam beberapa kasus, mesin eksekusi asli mungkin tidak dapat menjalankan kueri karena alasan seperti fitur yang tidak didukung. Dalam kasus ini, operasi beralih kembali ke mesin Spark tradisional. Mekanisme fallback otomatis ini memastikan bahwa tidak ada gangguan pada alur kerja Anda.


Memantau Kueri dan DataFrame yang dijalankan oleh mesin
Untuk lebih memahami bagaimana mesin eksekusi asli diterapkan pada kueri SQL dan operasi DataFrame, serta untuk menganalisis secara mendalam hingga tingkat tahap dan operator, Anda dapat merujuk ke Spark UI dan Spark History Server untuk informasi lebih rinci tentang eksekusi mesin asli.
Tab Mesin Eksekusi Bawaan
Anda dapat menuju tab 'Gluten SQL / DataFrame' baru untuk melihat informasi pembuatan Gluten dan detail eksekusi kueri. Tabel kueri memberikan wawasan tentang jumlah simpul yang berjalan pada mesin Native dan yang beralih kembali ke JVM untuk setiap kueri.

Grafik Pelaksanaan Kueri
Anda juga dapat memilih deskripsi kueri untuk visualisasi rencana eksekusi kueri Apache Spark. Grafik eksekusi menyediakan detail eksekusi asli di seluruh tahap dan operasi masing-masing. Warna latar belakang membedakan mesin eksekusi: hijau mewakili Native Execution Engine, sementara biru muda menunjukkan bahwa operasi berjalan pada Mesin JVM default.

Batasan
Meskipun Native Execution Engine (NEE) di Microsoft Fabric secara signifikan meningkatkan performa untuk pekerjaan Apache Spark, saat ini memiliki batasan berikut:
Batasan yang ada
Fitur Spark yang tidak kompatibel: Mesin eksekusi asli saat ini tidak mendukung fungsi yang ditentukan pengguna (UDF),
array_containsfungsi, atau streaming terstruktur. Jika fungsi-fungsi ini atau fitur yang tidak didukung digunakan baik secara langsung atau melalui pustaka yang diimpor, Spark akan kembali ke mesin defaultnya.Format file yang tidak didukung: Kueri terhadap
JSONformat danXMLtidak dipercepat oleh mesin eksekusi asli. Default ini kembali ke mesin Spark JVM reguler untuk eksekusi. CSV sekarang didukung melalui parser CSV vektorisasi.Mode ANSI tidak didukung: Mesin eksekusi asli tidak mendukung mode ANSI SQL. Jika diaktifkan, eksekusi kembali ke mesin Spark bawaan.
Ketidakcocokan jenis filter tanggal: Untuk mendapatkan manfaat dari akselerasi mesin eksekusi asli, pastikan bahwa kedua sisi perbandingan tanggal memiliki jenis data yang sama. Misalnya, alih-alih membandingkan kolom
DATETIMEdengan literal string, ubah tipe secara eksplisit seperti yang ditunjukkan:CAST(order_date AS DATE) = '2024-05-20'
Pertimbangan dan batasan lainnya
Ketidakcocokan casting Desimal ke Float: Saat pengubahan tipe dari
DECIMALkeFLOAT, Spark mempertahankan presisi dengan mengonversi ke string dan mem-parse-nya. NEE (melalui Velox) melakukan "cast" langsung dari representasi internalint128_t, yang bisa menyebabkan ketidakakuratan pembulatan.Kesalahan konfigurasi zona waktu : Mengatur zona waktu yang tidak dikenal di Spark menyebabkan pekerjaan gagal di bawah NEE, sedangkan Spark JVM menanganinya dengan anggun. Contohnya:
"spark.sql.session.timeZone": "-08:00" // May cause failure under NEEPerilaku pembulatan yang tidak konsisten: Fungsi
round()berperilaku berbeda di NEE karena keandalan padastd::round, yang tidak mereplikasi logika pembulatan Spark. Ini dapat menyebabkan inkonsistensi numerik dalam hasil pembulatan.Fungsi pemeriksaan
map()kunci duplikat hilang: Saatspark.sql.mapKeyDedupPolicydiatur ke EXCEPTION, Spark melemparkan kesalahan untuk kunci duplikat. NEE saat ini melewati pemeriksaan ini dan memungkinkan kueri berhasil dengan tidak benar.
Contoh:SELECT map(1, 'a', 1, 'b'); -- Should fail, but returns {1: 'b'}Mengurutkan varians dalam
collect_list()dengan pengurutan: Saat menggunakanDISTRIBUTE BYdanSORT BY, Spark mempertahankan urutan elemen dicollect_list(). NEE mungkin mengembalikan nilai dalam urutan yang berbeda karena perbedaan acak, yang dapat mengakibatkan harapan yang tidak cocok untuk logika peka urutan.Ketidakcocokan jenis menengah untuk
collect_list()/collect_set(): Spark menggunakanBINARYsebagai jenis perantara untuk agregasi ini, sedangkan NEE menggunakan .ARRAYKetidakcocokan ini dapat menyebabkan masalah kompatibilitas selama perencanaan atau eksekusi kueri.Diperlukan titik akhir privat terkelola untuk akses penyimpanan: Ketika Native Execution Engine (NEE) diaktifkan, dan jika pekerjaan spark mencoba mengakses akun penyimpanan menggunakan titik akhir privat terkelola, pengguna harus mengonfigurasi titik akhir privat terkelola yang terpisah untuk titik akhir Blob (blob.core.windows.net) dan DFS / Sistem File (dfs.core.windows.net), bahkan jika keduanya menunjuk ke akun penyimpanan yang sama. Satu titik akhir tidak dapat digunakan kembali untuk keduanya. Ini adalah batasan saat ini dan mungkin memerlukan konfigurasi jaringan tambahan saat mengaktifkan mesin eksekusi native di ruang kerja yang memiliki titik akhir privat yang dikelola untuk akun penyimpanan.