Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Runtime Fabric menawarkan integrasi yang mulus dengan Azure. Ini menyediakan lingkungan canggih untuk proyek rekayasa data dan ilmu data yang menggunakan Apache Spark. Artikel ini memberikan gambaran umum tentang fitur dan komponen penting Fabric Runtime 1.3.
Microsoft Fabric Runtime 1.3 adalah versi runtime GA yang menggabungkan komponen dan peningkatan berikut yang dirancang untuk meningkatkan kemampuan pemrosesan data Anda:
Apache Spark 3.5
Sistem Operasi: Mariner 2.0
Java: 11
Scala: 2.12.17
Python: 3.11
Danau Delta: 3.2
R: 4.4.1
Petunjuk / Saran
Fabric Runtime 1.3 mencakup dukungan untuk Native Execution Engine, yang dapat secara signifikan meningkatkan performa tanpa lebih banyak biaya. Untuk mengaktifkan mesin eksekusi asli di semua pekerjaan dan buku catatan di lingkungan Anda, navigasikan ke pengaturan lingkungan Anda, pilih Komputasi Spark, buka tab Akselerasi, dan centang Aktifkan mesin eksekusi asli. Setelah Anda menyimpan dan menerbitkan, pengaturan ini diterapkan di seluruh lingkungan, sehingga semua pekerjaan dan buku catatan baru secara otomatis mewarisi dan mendapatkan manfaat dari kemampuan performa yang ditingkatkan.
Mengintegrasikan Runtime 1.3
Nota
Untuk informasi tentang semua runtime Fabric yang tersedia dan statusnya saat ini, lihat Apache Spark Runtimes di Fabric.
Gunakan instruksi berikut untuk mengintegrasikan runtime 1.3 ke ruang kerja Anda dan gunakan fitur barunya:
Navigasi ke tab Pengaturan ruang kerja dalam ruang kerja Fabric Anda.
Buka tab Rekayasa Data/Sains dan pilih Pengaturan Spark.
Pilih tabLingkungan.
Di bawah Versi Runtime perluas menu dropdown.
Pilih 1.3 (Spark 3.5, Delta 3.2) dan simpan perubahan Anda. Tindakan ini menetapkan 1.3 sebagai runtime default untuk ruang kerja Anda.
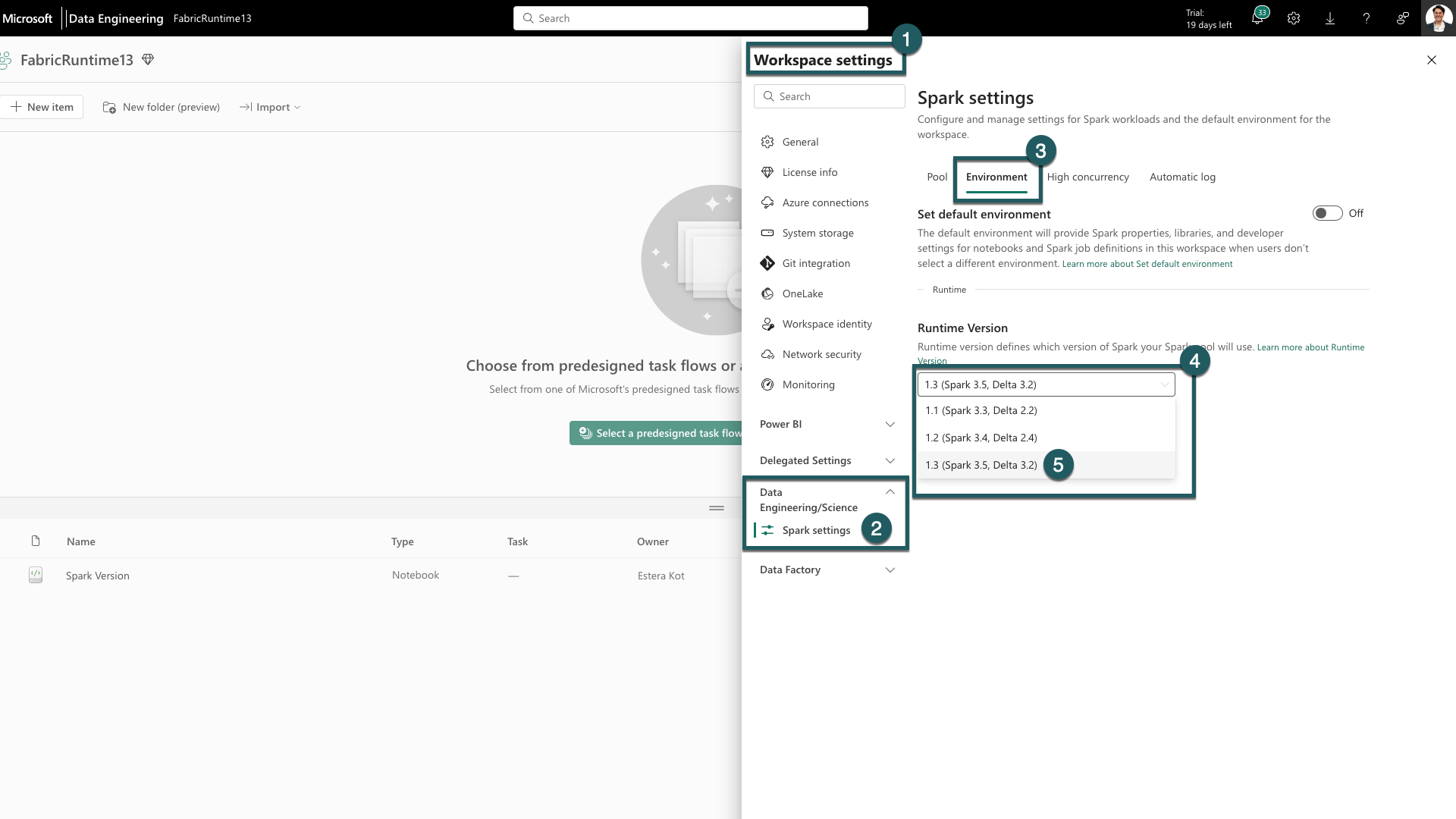

Anda sekarang dapat mulai bekerja dengan peningkatan terbaru dan fungsionalitas yang diperkenalkan dalam fabric runtime 1.3 (Spark 3.5 dan Delta Lake 3.2).
Pelajari tentang Apache Spark 3.5
Apache Spark 3.5.0 adalah versi keenam dalam seri 3.x. Versi ini adalah produk kolaborasi ekstensif dalam komunitas sumber terbuka, mengatasi lebih dari 1.300 masalah seperti yang dicatat di Jira.
Dalam versi ini, ada peningkatan kompatibilitas untuk streaming terstruktur. Selain itu, rilis ini memperluas fungsionalitas dalam PySpark dan SQL. Ini menambahkan fitur seperti klausa pengenal SQL, argumen bernama dalam pemanggilan fungsi SQL, dan penyertaan fungsi SQL untuk agregasi perkiraan menggunakan HyperLogLog.
Kemampuan baru lainnya juga termasuk fungsi tabel Python yang didefinisikan pengguna, penyederhanaan pelatihan tersebar melalui DeepSpeed, dan kemampuan streaming terstruktur baru seperti propagasi penanda air dan operasi dropDuplicatesWithinWatermark.
Anda dapat memeriksa daftar lengkap dan perubahan terperinci di sini: Rilis Spark 3.5.0.
Pelajari tentang Delta Spark
Delta Lake 3.2 menandai komitmen kolektif untuk membuat Delta Lake dapat dioperasikan di seluruh format, lebih mudah dikerjakan, dan lebih berkinerja. Delta Spark 3.2 dibangun di atas Apache Spark™ 3.5. Artefak maven Delta Spark diganti namanya dari delta-core menjadi delta-spark.
Anda dapat memeriksa daftar lengkap dan perubahan terperinci di sini: https://docs.delta.io/index.html.
Komponen dan Pustaka
Untuk informasi terbaru, daftar perubahan terperinci, dan catatan rilis spesifik untuk runtime Spark, periksa dan berlangganan Rilis dan Pembaruan Spark Runtimes.
Nota
EventHubConnector tidak digunakan lagi dalam Fabric Runtime 1.3 (Spark 3.5) dan akan dihapus dari versi Fabric Runtime di masa mendatang. Pelanggan didorong untuk menggunakan Kafka Spark Connector sebagai gantinya karena Azure Event Hubs sudah kompatibel dengan Kafka. Anda dapat menemukan informasi selengkapnya tentang menggunakan Kafka Spark Connector dengan Event Hubs di sini: Tutorial Event Hubs Kafka Spark
Konten terkait
- Baca tentang Apache Spark Runtimes di Fabric - Gambaran Umum, Pengelolaan Versi, Dukungan Banyak Runtime, dan Peningkatan Protokol Delta Lake
- Panduan migrasi Spark Core
- Panduan migrasi SQL, Himpunan Data, dan DataFrame
- Panduan migrasi Streaming Terstruktur
- Panduan migrasi MLlib (Pembelajaran Mesin)
- Panduan migrasi PySpark (Python on Spark)
- Panduan migrasi SparkR (R on Spark)