Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Fitur ini sedang dalam tahap pratinjau.
Fabric Runtime memberikan integrasi yang mulus dalam ekosistem Microsoft Fabric, menawarkan lingkungan yang kuat untuk proyek rekayasa data dan ilmu data yang didukung oleh Apache Spark.
Artikel ini memperkenalkan Fabric Runtime 2.0 dalam Pratinjau Umum, versi runtime terbaru yang dirancang khusus untuk komputasi big data di Microsoft Fabric. Ini menyoroti fitur dan komponen utama yang membuat rilis ini menjadi langkah maju yang signifikan untuk analitik yang dapat diskalakan dan beban kerja tingkat lanjut.
Fabric Runtime 2.0 menggabungkan komponen dan peningkatan berikut yang dirancang untuk meningkatkan kemampuan pemrosesan data Anda:
- Apache Spark 4.0
- Sistem Operasi: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.12
- Danau Delta: 4.0
- R: 4.5.2
Petunjuk / Saran
Fabric Runtime 2.0 mencakup dukungan untuk Native Execution Engine, yang dapat secara signifikan meningkatkan performa tanpa lebih banyak biaya. Anda dapat mengaktifkan mesin eksekusi asli di tingkat lingkungan sehingga semua pekerjaan dan notebook secara otomatis mewarisi kemampuan performa yang ditingkatkan.
Mengaktifkan Runtime 2.0
Anda dapat mengaktifkan Runtime 2.0 di tingkat ruang kerja atau tingkat item lingkungan. Gunakan pengaturan ruang kerja untuk menerapkan Runtime 2.0 sebagai default untuk semua beban kerja Spark di ruang kerja Anda. Atau, buat komponen lingkungan dengan Runtime 2.0 untuk digunakan dengan definisi pekerjaan Spark atau notebook tertentu, yang mengganti default ruang kerja.
Mengaktifkan Runtime 2.0 di pengaturan Ruang Kerja
Untuk mengatur Runtime 2.0 sebagai default untuk seluruh ruang kerja Anda:
Navigasi ke halaman Pengaturan ruang kerja dalam ruang kerja Fabric Anda.
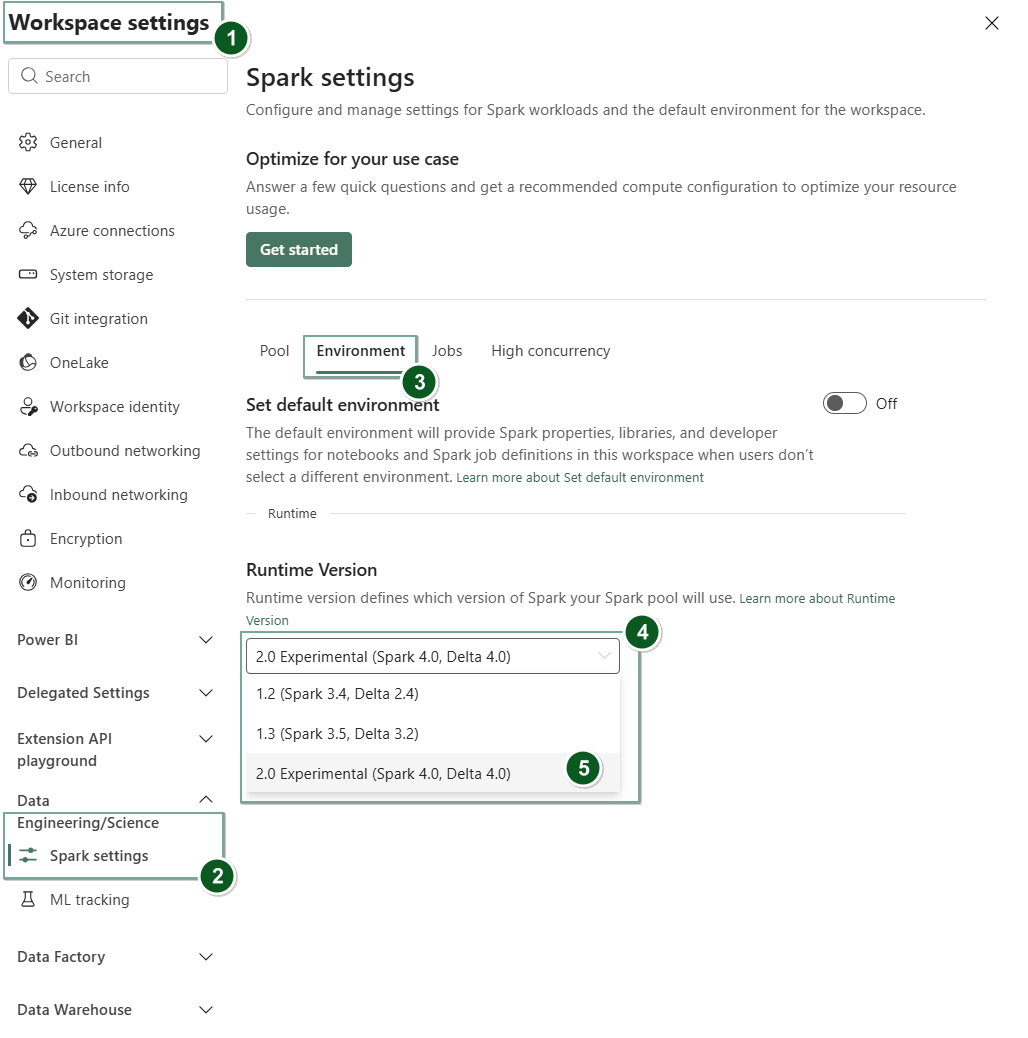
Pilih tab Rekayasa/Sains Data lalu pilih Pengaturan Spark.
Pilih tabLingkungan.
Di bawah menu dropdown Versi runtime , pilih Pratinjau Umum 2.0 (Spark 4.0, Delta 4.0) dan simpan perubahan Anda.
Runtime 2.0 diatur sebagai runtime default untuk ruang kerja Anda.

Mengaktifkan Runtime 2.0 dalam item Lingkungan
Untuk menggunakan Runtime 2.0 dengan notebook tertentu atau definisi kerja Spark:
Buat item Lingkungan baru atau buka item yang sudah ada.
Di bawah menu dropdown Runtime , pilih Pratinjau Umum 2.0 (Spark 4.0, Delta 4.0),
SavedanPublishperubahan Anda.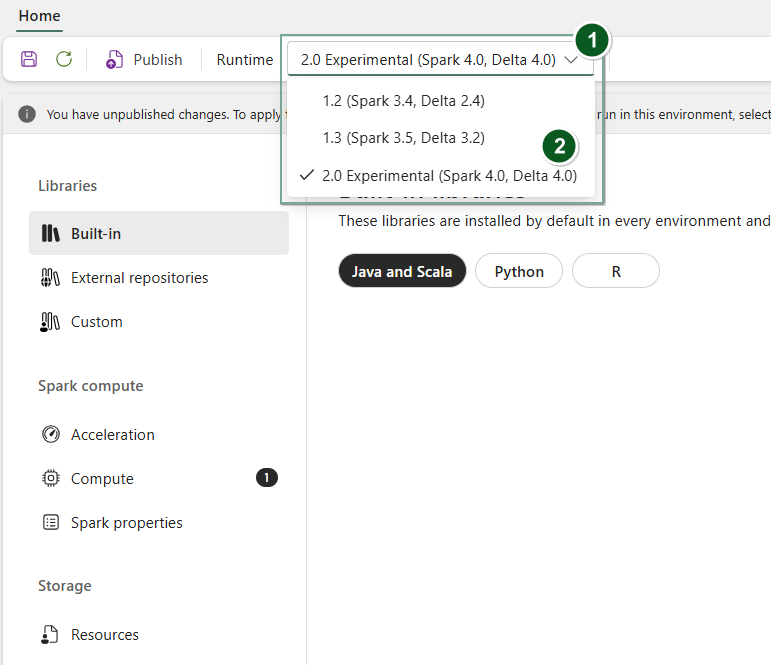
Selanjutnya, Anda dapat menggunakan item Lingkungan ini dengan
NotebookatauSpark Job Definition.

Anda sekarang dapat mulai bereksperimen dengan peningkatan dan fungsionalitas terbaru yang diperkenalkan dalam Fabric Runtime 2.0 (Spark 4.0 dan Delta Lake 4.0).
Petunjuk / Saran
Pemrosesan awal sesi Spark untuk Runtime 2.0 mungkin memerlukan waktu beberapa menit selama pratinjau publik. Untuk mengurangi penundaan cold-start, gunakan Kumpulan Langsung Aktif Kustom (pratinjau) untuk memanaskan kumpulan Spark terlebih dahulu, atau atur Profil Sumber Daya untuk mengalokasikan sumber daya di muka.
Nota
Protokol WASB untuk akun Azure Storage Tujuan Umum v2 (GPv2) tidak digunakan lagi. Anda harus menggunakan protokol ABFS terbaru sebagai gantinya untuk membaca dari dan menulis ke akun penyimpanan GPv2.
Pratinjau umum
Tahap pratinjau publik Fabric Runtime 2.0 memberi Anda akses ke fitur dan API baru dari Spark 4.0 dan Delta Lake 4.0. Pratinjau ini memungkinkan Anda menggunakan peningkatan berbasis Spark dan Delta terbaru segera serta memastikan persiapan dan transisi yang mulus untuk perubahan yang diperbarui dan ditingkatkan seperti versi terbaru dari Java, Scala, dan Python.
Petunjuk / Saran
Untuk informasi terbaru, daftar perubahan terperinci, dan catatan rilis spesifik mengenai runtime Fabric, lihat dan berlangganan Rilis dan Pembaruan Runtime Spark.
Sorotan utama
Peningkatan performa dan mesin eksekusi
Fabric Runtime 2.0 mencakup Native Execution Engine, yang memberikan peningkatan performa yang signifikan dibandingkan Spark sumber terbuka. Mesin menggunakan pemrosesan vektorisasi untuk mempercepat kueri Spark pada infrastruktur lakehouse tanpa memerlukan perubahan kode.
Fitur performa utama di Runtime 2.0:
- Hingga enam kali lebih cepat: Tolok ukur menunjukkan hingga enam kali lebih cepat dibandingkan dengan Spark open-source pada beban kerja TPC-DS.
- Penguraian CSV vektorisasi: Mesin eksekusi asli mencakup pengurai CSV vektorisasi yang mempercepat penyerapan CSV dan beban kerja kueri. Penguraian JSON vektorisasi dan dukungan Spark Structured Streaming direncanakan untuk pembaruan di masa mendatang.
Untuk mengaktifkan mesin eksekusi asli, lihat Mesin eksekusi asli untuk Fabric Data Engineering.
Apache Spark 4.0
Apache Spark 4.0 menandai tonggak penting sebagai rilis perdana dalam seri 4.x, mewujudkan upaya kolektif komunitas sumber terbuka yang semarak.
Dalam versi ini, Spark SQL secara signifikan diperkaya dengan fitur baru yang kuat yang dirancang untuk meningkatkan ekspresif dan fleksibilitas untuk beban kerja SQL, seperti dukungan jenis data VARIAN, fungsi yang ditentukan pengguna SQL, variabel sesi, sintaks pipa, dan kolase string. PySpark melihat dedikasi berkelanjutan terhadap cakupan fungsional dan pengalaman pengembang secara keseluruhan, menghadirkan API plotting asli, API Sumber Data Python baru, dukungan untuk UDTF Python, dan profilering terpadu untuk UDF PySpark, serta banyak peningkatan lainnya. Streaming Terstruktur berevolusi dengan penambahan utama yang memberikan kontrol dan kemudahan penelusuran kesalahan yang lebih besar, terutama pengenalan Api Status Arbitrer v2 untuk manajemen status yang lebih fleksibel dan Sumber Data Status untuk penelusuran kesalahan yang lebih mudah.
Anda dapat memeriksa daftar lengkap dan perubahan terperinci di sini: https://spark.apache.org/releases/spark-release-4-0-0.html.
Nota
Di Spark 4.0, SparkR tidak digunakan lagi dan mungkin dihapus dalam versi mendatang.
Danau Delta 4.0
Delta Lake 4.0 menandai komitmen kolektif untuk membuat Delta Lake dapat dioperasikan di seluruh format, lebih mudah dikerjakan, dan lebih berkinerja. Delta 4.0 adalah rilis tonggak pencapaian yang dikemas dengan fitur baru yang kuat, pengoptimalan performa, dan peningkatan dasar untuk masa depan data lakehouse terbuka.
Anda dapat memeriksa daftar lengkap dan perubahan terperinci yang diperkenalkan dengan Delta Lake 3.3 dan 4.0 di sini: https://github.com/delta-io/delta/releases/tag/v3.3.0. https://github.com/delta-io/delta/releases/tag/v4.0.0.
Tata letak dan pengoptimalan data
Runtime 2.0 mendukung tata letak data dan fitur pengoptimalan untuk tabel Delta:
- Urutan Z: Menata data dalam file tabel Delta dengan kolom tertentu untuk meningkatkan performa kueri untuk kueri yang difilter.
- Pengklusteran Cairan: Pendekatan pengklusteran fleksibel yang secara otomatis mengoptimalkan tata letak data tanpa pemeliharaan manual.
- Pemuatan rekam jepret Delta paralel: Mesin eksekusi asli memuat rekam jepret tabel Delta secara paralel, mengurangi waktu mulai kueri untuk tabel besar.
Penting
Fitur khusus Delta Lake 4.0 bersifat eksperimental dan hanya berfungsi pada pengalaman Spark, seperti Notebook dan Definisi Pekerjaan Spark. Jika Anda perlu menggunakan tabel Delta Lake yang sama di beberapa beban kerja Microsoft Fabric, jangan aktifkan fitur tersebut. Untuk mempelajari selengkapnya tentang versi dan fitur protokol mana yang kompatibel di semua pengalaman Microsoft Fabric, baca interoperabilitas format tabel Delta Lake.
Manajemen komputasi dalam Runtime 2.0
Runtime 2.0 mendukung fitur manajemen komputasi berikut:
- Profil sumber daya: Konfigurasikan alokasi sumber daya yang telah ditentukan sebelumnya untuk sesi Spark agar sesuai dengan persyaratan beban kerja dan biaya kontrol.
- Kumpulan langsung kustom (pratinjau): Buat kumpulan Spark khusus yang telah dihangatkan sebelumnya yang mengurangi waktu mulai sesi. Kumpulan aktif kustom tersedia dalam tahap pratinjau untuk beban kerja Runtime 2.0.
Batasan dan catatan
- Fitur khusus Delta Lake 4.0 bersifat eksperimental dan hanya berfungsi pada pengalaman Spark, seperti notebook dan definisi pekerjaan Spark. Jika Anda perlu menggunakan tabel Delta Lake yang sama di beberapa beban kerja Fabric, jangan aktifkan fitur tersebut. Untuk informasi selengkapnya, lihat Interoperabilitas format tabel Delta Lake.
- Runtime 2.0 berada dalam pratinjau publik. Beberapa fitur dan API dapat berubah sebelum ketersediaan umum.
- Ekstensi Visual Studio Code untuk Fabric Spark mendukung Runtime 2.0 untuk pengembangan definisi kerja notebook dan Spark.
Konten terkait
- Apache Spark Runtimes in Fabric - Gambaran Umum, Penerapan Versi, dan Dukungan Beberapa Runtime
- Panduan migrasi Spark Core
- Panduan migrasi SQL, Himpunan Data, dan DataFrame
- Panduan migrasi Streaming Terstruktur
- Panduan migrasi MLlib (Pembelajaran Mesin)
- Panduan migrasi PySpark (Python on Spark)
- Panduan migrasi SparkR (R on Spark)