Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Eksperimen pembelajaran mesin adalah unit utama organisasi dan kontrol untuk semua eksekusi pembelajaran mesin terkait. Suatu run sesuai dengan satu eksekusi kode model. Dalam MLflow, pelacakan didasarkan pada eksperimen dan percobaan.
Eksperimen pembelajaran mesin memungkinkan ilmuwan data untuk mencatat parameter, versi kode, metrik, dan file output saat menjalankan kode pembelajaran mesin mereka. Eksperimen juga memungkinkan Anda memvisualisasikan, mencari, dan membandingkan eksekusi, serta mengunduh file dan metadata eksekusi untuk analisis di alat lain.
Dalam artikel ini, Anda mempelajari lebih lanjut tentang bagaimana ilmuwan data dapat berinteraksi dan menggunakan eksperimen pembelajaran mesin untuk mengatur proses pengembangan mereka dan melacak beberapa eksekusi.
Prasyarat
Dapatkan langganan Microsoft Fabric. Atau, daftar uji coba Microsoft Fabric gratis.
Masuk ke Microsoft Fabric.
Beralih ke Fabric dengan menggunakan pengalih pengalaman di sisi kiri bawah halaman beranda Anda.

Membuat eksperimen
Anda dapat membuat eksperimen pembelajaran mesin langsung dari antarmuka pengguna (UI) Fabric atau dengan menulis kode yang menggunakan API MLflow.
Membuat eksperimen menggunakan UI
Untuk membuat eksperimen pembelajaran mesin dari UI:
Buat ruang kerja baru atau pilih ruang kerja yang sudah ada.
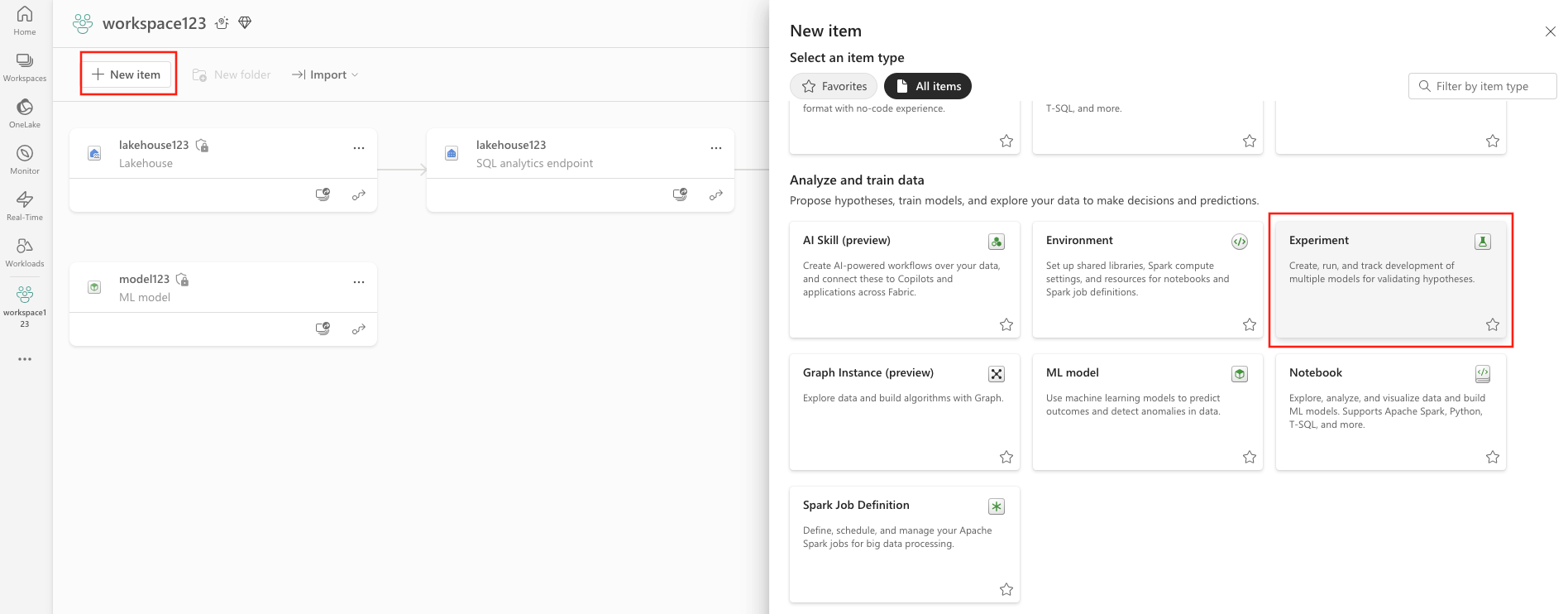
Di kiri atas ruang kerja Anda, pilih Item baru. Di bawah Analisis dan latih data, pilih Eksperimen .
 ATAU
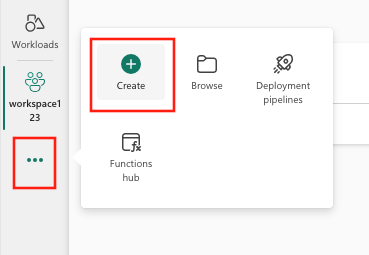
ATAUPilih Buat, yang dapat ditemukan di ... dari menu vertikal.
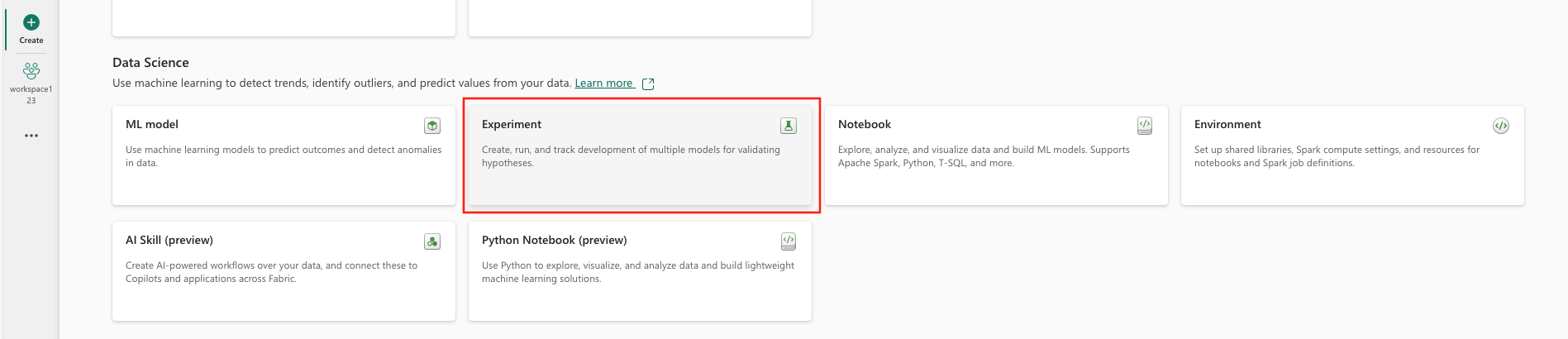
Di bawah Ilmu Data, pilih Eksperimen.
Berikan nama eksperimen dan pilih Buat. Tindakan ini membuat eksperimen kosong dalam ruang kerja Anda.



Setelah membuat eksperimen, Anda dapat mulai menambahkan eksekusi untuk melacak metrik dan parameter eksekusi.
Membuat eksperimen menggunakan MLflow API
Anda juga dapat membuat eksperimen pembelajaran mesin langsung dari pengalaman penulisan Anda menggunakan mlflow.create_experiment() API atau mlflow.set_experiment() . Dalam kode berikut, ganti <EXPERIMENT_NAME> dengan nama eksperimen Anda.
import mlflow
# This will create a new experiment with the provided name.
mlflow.create_experiment("<EXPERIMENT_NAME>")
# This will set the given experiment as the active experiment.
# If an experiment with this name does not exist, a new experiment with this name is created.
mlflow.set_experiment("<EXPERIMENT_NAME>")
Mengelola percobaan dalam eksperimen
Eksperimen pembelajaran mesin berisi kumpulan eksekusi untuk pelacakan dan perbandingan yang disederhanakan. Dalam eksperimen, seorang ilmuwan data dapat menavigasi di berbagai eksekusi dan menjelajahi parameter dan metrik yang mendasarinya. Ilmuwan data juga dapat membandingkan eksekusi dalam eksperimen pembelajaran mesin untuk mengidentifikasi subset parameter mana yang menghasilkan performa model yang diinginkan.
Untuk melihat eksekusi eksperimen, pilih Jalankan daftar dari tampilan eksperimen.

Dari daftar eksekusi, Anda dapat menavigasi ke detail eksekusi tertentu dengan memilih nama eksekusi.
Melacak detail operasi
Pembelajaran mesin berjalan sesuai dengan satu eksekusi kode model. Anda dapat melacak informasi berikut untuk setiap pelaksanaan:

Setiap putaran menyertakan informasi berikut:
- Sumber: Nama notebook yang membuat proses.
- Versi Terdaftar: Menunjukkan apakah eksekusi disimpan sebagai model pembelajaran mesin.
- Tanggal mulai: Waktu mulai proses.
- Status: Kemajuan proses.
- Hyperparameter: Hyperparameter disimpan sebagai pasangan kunci-nilai. Kunci dan nilai adalah berjenis string.
- Metrik: Jalankan metrik yang disimpan sebagai pasangan kunci-nilai. Nilainya adalah numerik.
- File keluaran: File keluaran dalam format apa pun. Misalnya, Anda dapat merekam gambar, lingkungan, model, dan file data.
- Tag: Metadata sebagai pasangan kunci-nilai untuk proses menjalankan.
Lihat daftar pelaksanaan
Anda dapat melihat semua pelaksanaan dalam eksperimen dalam tampilan Daftar Jalankan. Tampilan ini memungkinkan Anda melacak aktivitas terbaru, dengan cepat melompat ke aplikasi Spark terkait, dan menerapkan filter berdasarkan status eksekusi.
Membandingkan dan memfilter jalur
Untuk membandingkan dan mengevaluasi kualitas eksekusi pembelajaran mesin, Anda dapat membandingkan parameter, metrik, dan metadata antara eksekusi yang dipilih dalam eksperimen.
Terapkan tag untuk dijalankan
Penandaan MLflow untuk eksekusi eksperimen memungkinkan pengguna untuk menambahkan metadata kustom dalam bentuk pasangan kunci-nilai ke eksekusi mereka. Tag ini membantu mengategorikan, memfilter, dan mencari eksekusi berdasarkan atribut tertentu, sehingga lebih mudah untuk mengelola dan menganalisis eksperimen dalam platform MLflow. Pengguna dapat menggunakan tag untuk melabeli eksekusi dengan informasi seperti jenis model, parameter, atau pengidentifikasi yang relevan, meningkatkan organisasi keseluruhan dan keterlacakan eksperimen.
Cuplikan kode ini memulai eksekusi MLflow, mencatat beberapa parameter dan metrik, dan menambahkan tag untuk mengategorikan dan menyediakan konteks tambahan untuk eksekusi.
import mlflow
import mlflow.sklearn
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.datasets import fetch_california_housing
# Autologging
mlflow.autolog()
# Load the California housing dataset
data = fetch_california_housing(as_frame=True)
X = data.data
y = data.target
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Start an MLflow run
with mlflow.start_run() as run:
# Train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Predict and evaluate
y_pred = model.predict(X_test)
# Add tags
mlflow.set_tag("model_type", "Linear Regression")
mlflow.set_tag("dataset", "California Housing")
mlflow.set_tag("developer", "Bob")
Setelah tag diterapkan, Anda kemudian dapat melihat hasilnya langsung dari widget MLflow bawaan atau dari halaman rincian eksekusi.

Peringatan
Peringatan: Batasan Penerapan Tag ke Eksperimen MLflow dalam Fabric
- Tag Tidak Kosong: Nama atau nilai tag tidak boleh kosong. Jika Anda mencoba menerapkan tag dengan nama atau nilai kosong, operasi akan gagal.
- Nama Tag: Panjang nama tag bisa hingga 250 karakter.
- Nilai Tag: Nilai tag dapat memiliki panjang hingga 5000 karakter.
-
Nama Tag Terbatas: Nama tag yang dimulai dengan awalan tertentu tidak didukung. Secara khusus, nama tag yang dimulai dengan
synapseml,mlflow, atautridentdibatasi dan tidak akan diterima.
Membandingkan performa secara visual
Anda dapat membandingkan dan memfilter eksekusi secara visual dalam eksperimen yang ada. Perbandingan visual memungkinkan Anda untuk dengan mudah menavigasi antara beberapa pengulangan dan mengurutkannya.

Untuk membandingkan percobaan:
- Pilih eksperimen pembelajaran mesin yang ada yang berisi beberapa eksekusi.
- Pilih tab Tampilan lalu masuk ke tampilan Jalankan daftar . Atau, Anda dapat memilih opsi untuk Lihat daftar eksekusi langsung dari tampilan Detail eksekusi.
- Kustomisasi kolom dalam tabel dengan memperluas panel Kustomisasi kolom . Di sini, Anda dapat memilih properti, metrik, tag, dan hiperparameter yang ingin Anda lihat.
- Perluas panel Filter untuk mempersempit hasil Anda berdasarkan kriteria tertentu yang dipilih.
- Pilih beberapa eksekusi untuk membandingkan hasilnya di panel perbandingan metrik. Dari panel ini, Anda bisa mengkustomisasi bagan dengan mengubah judul bagan, jenis visualisasi, sumbu X, sumbu Y, dan lainnya.
Membandingkan eksekusi menggunakan API MLflow
Ilmuwan data juga dapat menggunakan MLflow untuk mengkueri dan mencari di antara eksekusi dalam eksperimen. Anda dapat menjelajahi lebih banyak API MLflow untuk mencari, memfilter, dan membandingkan eksekusi dengan mengunjungi dokumentasi MLflow.
Dapatkan semua eksekusi
Anda dapat menggunakan API mlflow.search_runs() pencarian MLflow untuk mendapatkan semua eksekusi dalam eksperimen dengan mengganti <EXPERIMENT_NAME> dengan nama eksperimen Anda atau <EXPERIMENT_ID> dengan ID eksperimen Anda dalam kode berikut:
import mlflow
# Get runs by experiment name:
mlflow.search_runs(experiment_names=["<EXPERIMENT_NAME>"])
# Get runs by experiment ID:
mlflow.search_runs(experiment_ids=["<EXPERIMENT_ID>"])
Petunjuk / Saran
Anda dapat mencari di beberapa eksperimen dengan memberikan daftar ID eksperimen ke experiment_ids parameter . Demikian pula, menyediakan daftar nama eksperimen ke experiment_names parameter akan memungkinkan MLflow untuk mencari di beberapa eksperimen. Ini dapat berguna jika Anda ingin membandingkan di antara beberapa kali eksekusi pada eksperimen yang berbeda-beda.
Eksekusi pesanan dan batas
max_results Gunakan parameter dari search_runs untuk membatasi jumlah eksekusi yang dikembalikan. Parameter order_by memungkinkan Anda untuk mencantumkan kolom untuk diurutkan berdasarkan dan dapat berisi opsional DESC atau ASC nilai. Misalnya, contoh berikut mengembalikan percobaan yang terakhir dijalankan.
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["start_time DESC"])
Membandingkan jalankan dalam buku catatan Fabric
Anda dapat menggunakan widget penulisan MLFlow dalam buku catatan Fabric untuk melacak eksekusi MLflow yang dihasilkan dalam setiap sel buku catatan. Widget memungkinkan Anda melacak eksekusi, metrik, parameter, dan properti terkait langsung ke tingkat sel individual.
Untuk mendapatkan perbandingan visual, Anda juga dapat beralih ke tampilan Jalankan perbandingan . Tampilan ini menyajikan data secara grafis, membantu identifikasi cepat pola atau penyimpangan di berbagai eksekusi.

Simpan hasil sebagai model pembelajaran mesin
Setelah eksekusi menghasilkan hasil yang diinginkan, Anda dapat menyimpan eksekusi sebagai model untuk pelacakan model yang ditingkatkan dan untuk penyebaran model dengan memilih Simpan sebagai model ML.

Memantau Eksperimen Pembelajaran Mesin (pratinjau)
Eksperimen ML diintegrasikan langsung ke Monitor. Fungsionalitas ini dirancang untuk memberikan lebih banyak wawasan tentang aplikasi Spark Anda dan eksperimen ML yang dihasilkan, sehingga lebih mudah untuk mengelola dan men-debug proses ini.
Lacak jalannya dari monitor
Pengguna dapat melacak eksekusi eksperimen langsung dari pemantauan, memberikan tampilan terpadu dari semua aktivitas mereka. Integrasi ini mencakup opsi pemfilteran, memungkinkan pengguna untuk fokus pada eksperimen atau eksekusi yang dibuat dalam 30 hari terakhir atau periode tertentu lainnya.

Lacak jalannya eksperimen ML terkait dari aplikasi Spark Anda
Eksperimen ML terintegrasi langsung ke Monitor, tempat Anda dapat memilih aplikasi Spark tertentu dan mengakses Rekam Jepret Item. Di sini, Anda akan menemukan daftar semua eksperimen dan eksekusi yang dihasilkan oleh aplikasi tersebut.