Tutorial: Menggunakan R untuk memprediksi penundaan penerbangan
Tutorial ini menyajikan contoh end-to-end dari alur kerja Ilmu Data Synapse di Microsoft Fabric. Ini menggunakan data nycflights13 , dan R, untuk memprediksi apakah pesawat terlambat datang lebih dari 30 menit atau tidak. Kemudian menggunakan hasil prediksi untuk membangun dasbor Power BI interaktif.
Dalam tutorial ini, Anda akan mempelajari cara:
- Menggunakan paket tidymodels (resep, parsnip, rsample, alur kerja) untuk memproses data dan melatih model pembelajaran mesin
- Menulis data output ke lakehouse sebagai tabel delta
- Buat laporan visual Power BI untuk mengakses data secara langsung di lakehouse tersebut
Prasyarat
Dapatkan langganan Microsoft Fabric. Atau, daftar untuk uji coba Microsoft Fabric gratis.
Masuk ke Microsoft Fabric.
Gunakan pengalih pengalaman di sisi kiri halaman beranda Anda untuk beralih ke pengalaman Ilmu Data Synapse.

Buka atau buat buku catatan. Untuk mempelajari caranya, lihat Cara menggunakan notebook Microsoft Fabric.
Atur opsi bahasa ke SparkR (R) untuk mengubah bahasa utama.
Lampirkan buku catatan Anda ke lakehouse. Di sisi kiri, pilih Tambahkan untuk menambahkan lakehouse yang ada atau untuk membuat lakehouse.
Memasang paket
Instal paket nycflights13 untuk menggunakan kode dalam tutorial ini.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
Menjelajahi data
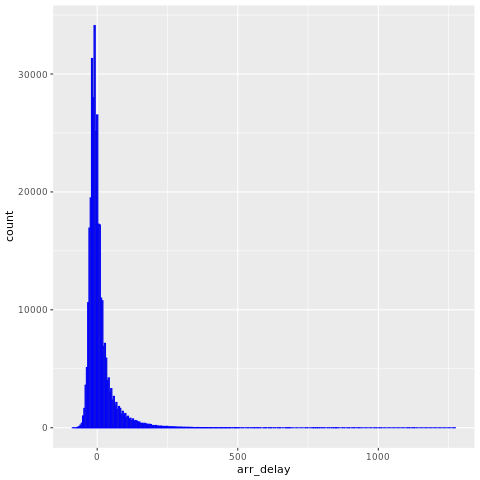
Data ini nycflights13 memiliki informasi tentang 325.819 penerbangan yang tiba di dekat New York City pada tahun 2013. Pertama, lihat distribusi keterlambatan penerbangan. Grafik ini menunjukkan bahwa distribusi penundaan kedatangan tepat condong. Ini memiliki ekor panjang dalam nilai-nilai tinggi.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
Muat data, dan buat beberapa perubahan pada variabel:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Sebelum kita membangun model, pertimbangkan beberapa variabel tertentu yang penting untuk praproscesing dan pemodelan.
Variabel arr_delay adalah variabel faktor. Untuk pelatihan model regresi logistik, penting bahwa variabel hasil adalah variabel faktor.
glimpse(flight_data)
Sekitar 16% dari penerbangan dalam himpunan data ini tiba lebih dari 30 menit terlambat.
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
Fitur ini dest memiliki 104 tujuan penerbangan.
unique(flight_data$dest)
Ada 16 operator berbeda.
unique(flight_data$carrier)
Pisahkan data
Pisahkan himpunan data tunggal menjadi dua set: set pelatihan dan set pengujian. Simpan sebagian besar baris dalam himpunan data asli (sebagai subset yang dipilih secara acak) dalam himpunan data pelatihan. Gunakan himpunan data pelatihan agar sesuai dengan model, dan gunakan himpunan data pengujian untuk mengukur performa model.
rsample Gunakan paket untuk membuat objek yang berisi informasi tentang cara membagi data. Kemudian, gunakan dua fungsi lagi rsample untuk membuat DataFrames untuk set pelatihan dan pengujian:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Membuat resep dan peran
Buat resep untuk model regresi logistik sederhana. Sebelum melatih model, gunakan resep untuk membuat prediktor baru, dan lakukan pra-pemrosesan yang diperlukan model.
update_role() Gunakan fungsi sehingga resep tahu bahwa flight dan time_hour merupakan variabel, dengan peran kustom yang disebut ID. Peran dapat memiliki nilai karakter apa pun. Rumus mencakup semua variabel dalam set pelatihan, selain arr_delay, sebagai prediktor. Resep menyimpan dua variabel ID ini tetapi tidak menggunakannya sebagai hasil atau prediktor.
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Untuk melihat kumpulan variabel dan peran saat ini, gunakan summary() fungsi :
summary(flights_rec)
Membuat fitur
Lakukan beberapa rekayasa fitur untuk meningkatkan model Anda. Tanggal penerbangan mungkin memiliki efek yang wajar pada kemungkinan keterlambatan kedatangan.
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Ini mungkin membantu menambahkan istilah model yang berasal dari tanggal yang berpotensi memiliki kepentingan untuk model. Dapatkan fitur yang bermakna berikut dari variabel tanggal tunggal:
- Hari dalam sepekan
- Month
- Apakah tanggal sesuai dengan hari libur atau tidak
Tambahkan tiga langkah ke resep Anda:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Paskan model dengan resep
Gunakan regresi logistik untuk memodelkan data penerbangan. Pertama, bangun spesifikasi model dengan parsnip paket:
lr_mod <-
logistic_reg() %>%
set_engine("glm")
workflows Gunakan paket untuk memaketkan model Anda parsnip (lr_mod) dengan resep Anda (flights_rec):
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Melatih model
Fungsi ini dapat menyiapkan resep, dan melatih model dari prediktor yang dihasilkan:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
Gunakan fungsi xtract_fit_parsnip() pembantu dan extract_recipe() untuk mengekstrak objek model atau resep dari alur kerja. Dalam contoh ini, tarik objek model yang dipasang, lalu gunakan broom::tidy() fungsi untuk mendapatkan tibble rapi koefisien model:
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Memprediksi hasil
Satu panggilan untuk predict() menggunakan alur kerja terlatih (flights_fit) untuk membuat prediksi dengan data pengujian yang tidak jelas. Metode ini predict() menerapkan resep ke data baru, lalu meneruskan hasilnya ke model yang dipasang.
predict(flights_fit, test_data)
Dapatkan output dari predict() untuk mengembalikan kelas yang diprediksi: late versus on_time. Namun, untuk probabilitas kelas yang diprediksi untuk setiap penerbangan, gunakan augment() dengan model, dikombinasikan dengan data pengujian, untuk menyimpannya bersama-sama:
flights_aug <-
augment(flights_fit, test_data)
Tinjau data:
glimpse(flights_aug)
Evaluasi model
Kita sekarang memiliki tibble dengan probabilitas kelas yang diprediksi. Dalam beberapa baris pertama, model memprediksi lima penerbangan tepat waktu dengan benar (nilai .pred_on_time adalah p > 0.50). Namun, kita memiliki total 81.455 baris untuk diprediksi.
Kami memerlukan metrik yang memberi tahu seberapa baik model memprediksi keterlambatan kedatangan, dibandingkan dengan status sebenarnya dari variabel hasil Anda, arr_delay.
Gunakan Area di bawah Karakteristik Operasi Penerima Kurva (AUC-ROC) sebagai metrik. Komputasi dengan roc_curve() dan roc_auc(), dari yardstick paket:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Menyusun laporan Power BI
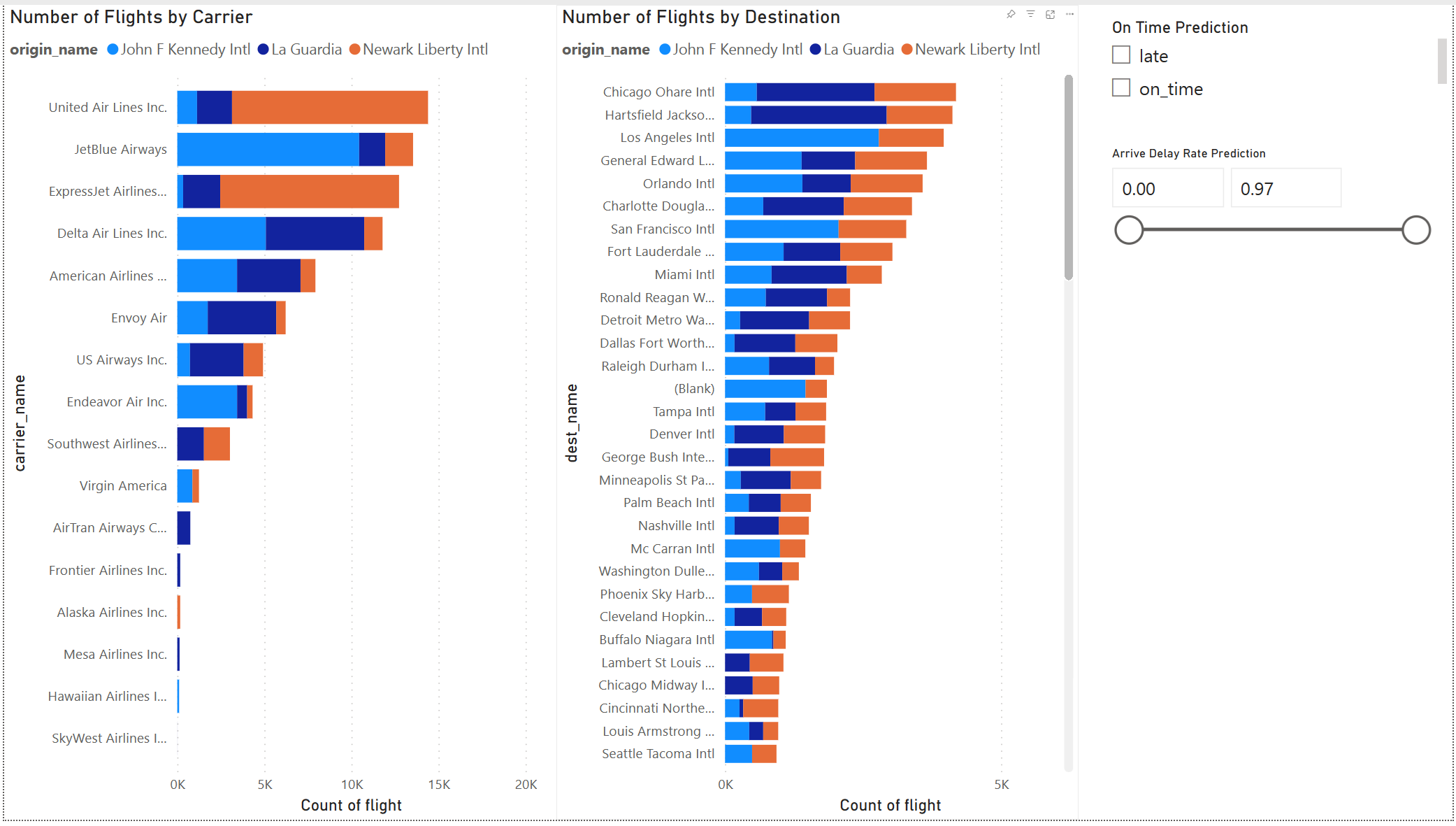
Hasil model terlihat bagus. Gunakan hasil prediksi penundaan penerbangan untuk membangun dasbor Power BI interaktif. Dasbor menunjukkan jumlah penerbangan berdasarkan operator, dan jumlah penerbangan berdasarkan tujuan. Dasbor dapat memfilter berdasarkan hasil prediksi penundaan.
Sertakan nama operator dan nama bandara dalam himpunan data hasil prediksi:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Tinjau data:
glimpse(flights_clean)
Konversikan data ke Spark DataFrame:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Tulis data ke dalam tabel delta di lakehouse Anda:
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
Gunakan tabel delta untuk membuat model semantik.
Di sebelah kiri, pilih hub data OneLake
Pilih lakehouse yang Anda lampirkan ke buku catatan Anda
Pilih Buka
Pilih Model semantik baru
Pilih nycflight13 untuk model semantik baru Anda, lalu pilih Konfirmasi
Model semantik Anda dibuat. Pilih Laporan baru
Pilih atau seret bidang dari panel Data dan Visualisasi ke kanvas laporan untuk menyusun laporan Anda
Untuk membuat laporan yang diperlihatkan di awal bagian ini, gunakan visualisasi dan data ini:
 Bagan batang bertumpuk dengan:
Bagan batang bertumpuk dengan: - Sumbu Y: carrier_name
- Sumbu X: penerbangan. Pilih Hitung untuk agregasi
- Legenda: origin_name
- Bagan batang bertumpuk dengan:
- Sumbu Y: dest_name
- Sumbu X: penerbangan. Pilih Hitung untuk agregasi
- Legenda: origin_name
 Pemotong dengan:
Pemotong dengan: - Bidang: _pred_class
- Pemotong dengan:
- Bidang: _pred_late