Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tidyverse adalah kumpulan paket R yang biasanya digunakan oleh ilmuwan data dalam analisis data sehari-hari. Ini termasuk paket untuk impor data (readr), visualisasi data (ggplot2), manipulasi data (dplyr, tidyr), pemrograman fungsi (purrr), dan pembuatan model (tidymodels) dll. Paket di tidyverse dirancang untuk bekerja sama dengan mulus dan mengikuti serangkaian prinsip desain yang konsisten.
Microsoft Fabric mendistribusikan versi tidyverse stabil terbaru dengan setiap rilis runtime. Impor dan mulai gunakan paket R anda yang sudah dikenal.
Prasyarat
Dapatkan langganan Microsoft Fabric. Atau, daftar untuk uji coba Microsoft Fabric gratis.
Masuk ke Microsoft Fabric.
Gunakan pengalih pengalaman di sisi kiri bawah halaman beranda Anda untuk beralih ke Fabric.

Buka atau buat buku catatan. Untuk mempelajari caranya, lihat Cara menggunakan notebook Microsoft Fabric.
Atur opsi bahasa ke SparkR (R) untuk mengubah bahasa utama.
Lampirkan buku catatan Anda ke lakehouse. Di sisi kiri, pilih Tambahkan untuk menambahkan lakehouse yang ada atau untuk membuat lakehouse.
Muat tidyverse
# load tidyverse
library(tidyverse)
Impor data
readr adalah paket R yang menyediakan alat untuk membaca file data persegi panjang seperti file CSV, TSV, dan lebar tetap.
readr menyediakan cara yang cepat dan ramah untuk membaca file data persegi panjang seperti menyediakan fungsi read_csv() dan read_tsv() untuk membaca file CSV dan TSV masing-masing.
Mari kita pertama-tama buat R data.frame, tulis ke lakehouse menggunakan readr::write_csv() dan baca kembali dengan readr::read_csv().
Catatan
Untuk mengakses file Lakehouse menggunakan readr, Anda perlu menggunakan jalur File API. Di penjelajah Lakehouse, klik kanan pada file atau folder yang ingin Anda akses dan salin jalur API File-nya dari menu kontekstual.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
Kemudian mari kita tulis data ke lakehouse menggunakan jalur File API.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Baca data dari lakehouse.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Merapikan data
tidyr adalah paket R yang menyediakan alat untuk bekerja dengan data berantakan. Fungsi utama di tidyr dirancang untuk membantu Anda membentuk ulang data menjadi format yang rapi. Data rapi memiliki struktur tertentu di mana setiap variabel adalah kolom dan setiap pengamatan adalah baris, yang memudahkan untuk bekerja dengan data di R dan alat lainnya.
Misalnya, gather() fungsi di tidyr dapat digunakan untuk mengonversi data lebar menjadi data panjang. Berikut contohnya:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
Konsep pemrograman fungsional
purrr adalah paket R yang meningkatkan toolkit pemrograman fungsional R dengan menyediakan serangkaian alat yang lengkap dan konsisten untuk bekerja dengan fungsi dan vektor. Tempat terbaik untuk memulai adalah purrr keluarga map() fungsi yang memungkinkan Anda mengganti banyak untuk perulangan dengan kode yang lebih succinct dan lebih mudah dibaca. Berikut adalah contoh penggunaan map() untuk menerapkan fungsi ke setiap elemen daftar:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Manipulasi data
dplyr adalah paket R yang menyediakan sekumpulan kata kerja yang konsisten yang membantu Anda memecahkan masalah manipulasi data yang paling umum, seperti memilih variabel berdasarkan nama, memilih kasus berdasarkan nilai, mengurangi beberapa nilai ke satu ringkasan, dan mengubah urutan baris dll. Berikut adalah beberapa contoh:
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Visualisasi data
ggplot2 adalah paket R untuk membuat grafik secara deklaratif, berdasarkan Tata Bahasa Grafis. Anda menyediakan data, memberi tahu ggplot2 cara memetakan variabel ke estetika, primitif grafis apa yang akan digunakan, dan mengurus detailnya. Berikut adalah beberapa contoh:
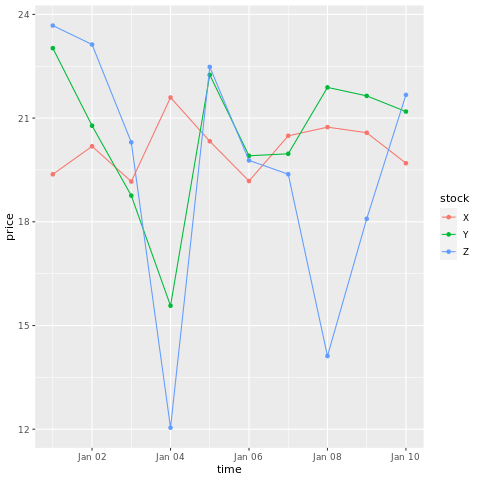
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
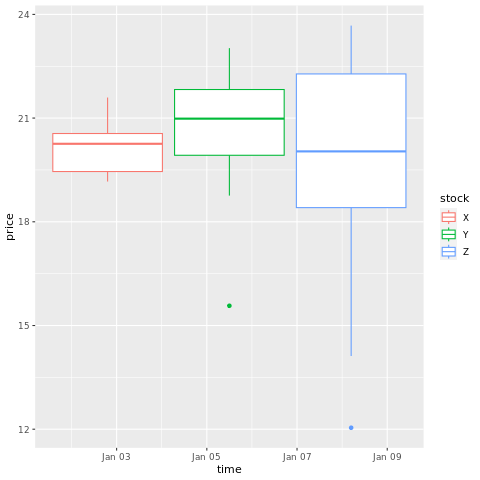
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
Bangunan model
tidymodels Kerangka kerja adalah kumpulan paket untuk pemodelan dan pembelajaran mesin menggunakan tidyverse prinsip- prinsip. Ini mencakup daftar paket inti untuk berbagai tugas pembuatan model, seperti rsample untuk pemisahan sampel himpunan data pelatihan/pengujian, parsnip untuk spesifikasi model, recipes untuk praproses data, workflows untuk pemodelan alur kerja, tune untuk penyetelan hiperparameter, yardstick untuk evaluasi model, broom untuk output model pengikatan, dan dials untuk mengelola parameter penyetelan. Anda dapat mempelajari lebih lanjut tentang paket dengan mengunjungi situs web tidymodels. Berikut adalah contoh membangun model regresi linier untuk memprediksi mil per galon (mpg) mobil berdasarkan beratnya (wt):
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
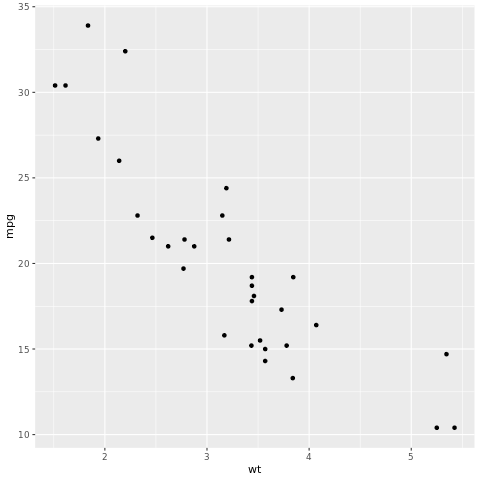
Dari sebaran, hubungan terlihat kira-kira linier dan varian terlihat konstan. Mari kita coba model ini menggunakan regresi linier.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Terapkan model regresi linier untuk memprediksi pada himpunan data pengujian.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
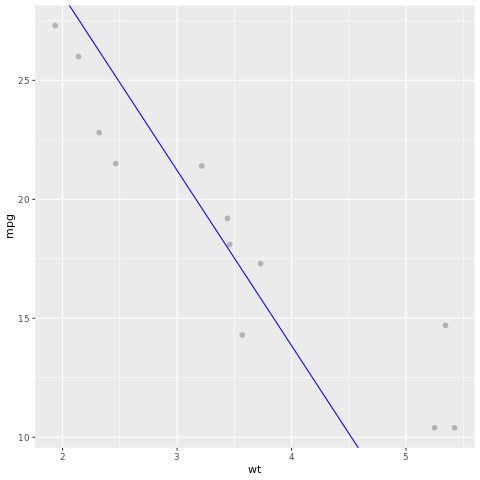
Mari kita lihat hasil model. Kita dapat menggambar model sebagai bagan garis dan data kebenaran dasar pengujian sebagai titik pada bagan yang sama. Modelnya terlihat bagus.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")