Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Diterapkan pada:✅ Gudang di Microsoft Fabric
Artikel ini menyoroti fitur dan inovasi dalam arsitektur Fabric Data Warehouse yang mendukung performa, skalabilitas, dan efisiensi biayanya.
Fabric Data Warehouse berjalan pada arsitektur siap masa depan dalam platform data yang terkonvergensi. Dengan format penyimpanan Delta terbuka dan integrasi OneLake, data Anda di Fabric Data Warehouse siap untuk dianalisis.
Arsitektur tingkat tinggi

Fabric Data Warehouse dibuat khusus untuk analitik dalam skala besar dengan blok penyusun berikut:
| Blok penyusun | Deskripsi |
|---|---|
| Pengoptimal kueri terpadu | Menghasilkan rencana eksekusi yang optimal untuk lingkungan cloud terdistribusi, terlepas dari kualitas kueri SQL yang ditulis pengguna. |
| Pemrosesan kueri terdistribusi | Mendukung eksekusi kueri paralel skala besar dengan infrastruktur cloud penskalaan otomatis yang cepat, yang secara langsung menyediakan sumber daya komputasi yang dibutuhkan untuk kueri. Beban kerja SELECT dan DML yang terpisah menggunakan pool yang berbeda untuk eksekusi yang efisien dan terisolasi. |
| Mesin Eksekusi Kueri | Mesin berbasis SQL untuk mengeksekusi kueri analitik pada sejumlah besar data dengan performa cepat dan konkurensi tinggi. |
| Metadata dan manajemen transaksi | Metadata berada di frontend, backend, serta pada cache SSD lokal dan penyimpanan OneLake jarak jauh. Mendukung transaksi simultan dan memastikan kepatuhan ACID. |
| Penyimpanan di OneLake | Tabel Terstruktur Log diimplementasikan menggunakan format tabel Delta terbuka, model lakehouse dengan penyimpanan terbuka yang aman. |
| Fabric Platform | Platform Fabric menyediakan model autentikasi dan keamanan terpadu, pemantauan, dan audit. Gudang Data Fabric Anda secara otomatis tersedia untuk layanan platform Fabric lainnya untuk memenuhi kebutuhan bisnis, termasuk Power BI, alur data di Data Factory, Real-Time Intelligence, dan banyak lagi. |
Mesin pengoptimal kueri terpadu
Pengoptimal kueri terpadu di Fabric Data Warehouse adalah mesin yang memutuskan cara terpandai untuk menjalankan kueri SQL Anda.
Saat Anda mengirimkan kueri, pengoptimal kueri terpadu melihat kemungkinan cara untuk menjalankannya: cara menggabungkan tabel, tempat memindahkan data, dan cara menggunakan sumber daya seperti CPU, memori, dan jaringan. Pengoptimal kueri terpadu tidak hanya memilih opsi pertama, ia memilih rencana paling optimal dalam waktu yang diizinkan dengan mengevaluasi biaya di seluruh faktor-faktor ini dan metadata dan statistik yang tersedia.
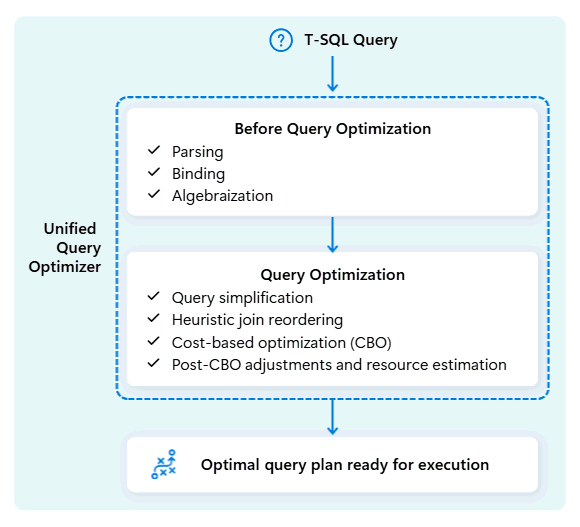
Saat mengoptimalkan rencana eksekusi kueri, pengoptimal kueri terpadu mempertimbangkan semuanya dalam sekali jalan: bentuk kueri Anda, distribusi data tabel Anda, dan biaya pemindahan data vs. pemrosesan secara lokal. Pengoptimal kueri terpadu dapat membuat kompromi cerdas seperti memutuskan apakah menyebarkan tabel kecil lebih murah daripada mengalihkan data besar. Ini berarti lebih sedikit pengacakan data yang tidak perlu, penggunaan komputasi yang lebih baik, dan performa yang lebih cepat, bahkan untuk kueri T-SQL yang kompleks atau kurang ditulis.
Performa yang konsisten tidak mengharuskan pengembang untuk menghabiskan waktu untuk penyetelan kueri T-SQL manual. Misalnya, Anda tidak perlu menentukan urutan terbaik JOIN dalam kueri secara manual. Jika SQL Anda mencantumkan tabel besar terlebih dahulu dan tabel data yang lebih kecil dan sangat selektif kedua, pengoptimal dapat secara otomatis mengalihkan posisinya untuk performa yang lebih baik. Ini akan menggunakan tabel yang lebih kecil sebagai titik awal untuk baris yang cocok (sisi "build") dan tabel yang lebih besar sebagai tempat pencarian (sisi "probe", diperiksa kecocokan). Pendekatan ini meminimalkan penggunaan memori, mengurangi pergerakan data, dan meningkatkan paralelisme, sambil tetap memberikan hasil yang akurat.
Pengoptimal kueri terpadu terus belajar dari eksekusi kueri sebelumnya saat beban kerja berkembang, menyempurnakan algoritma pengoptimalannya untuk memberikan performa terbaik. Pengguna mendapat manfaat dari eksekusi kueri cepat secara otomatis, terlepas dari kompleksitas dan tanpa perlu campur tangan.
Mesin pemrosesan kueri terdistribusi
Di Fabric Data Warehouse, mesin pemrosesan kueri terdistribusi mengalokasikan sumber daya komputasi ke tugas dalam rencana kueri. Mesin pemrosesan kueri terdistribusi dapat menjadwalkan tugas di seluruh simpul komputasi sehingga setiap simpul menjalankan bagian dari rencana kueri, memungkinkan eksekusi paralel untuk performa yang lebih cepat. Laporan kompleks tentang himpunan data besar dapat memperoleh manfaat dari pemrosesan kueri terdistribusi.
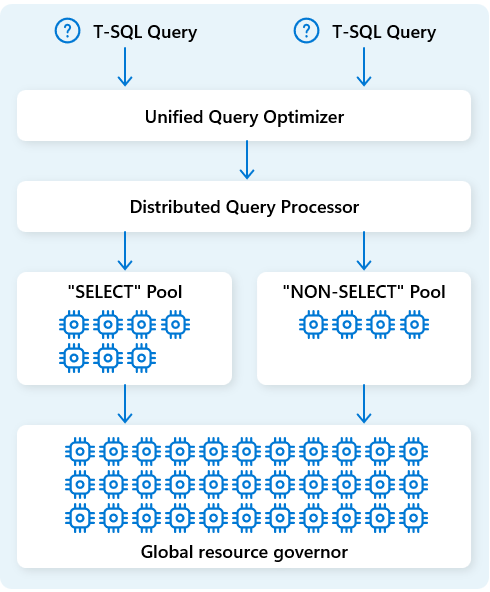
Untuk mengoptimalkan sumber daya lebih lanjut, mesin pemrosesan kueri terdistribusi memisahkan sumber daya komputasi menjadi dua kumpulan: untuk SELECT kueri dan untuk tugas penyerapan data (NON-SELECT kueri). Setiap beban kerja menerima sumber daya khusus sesuai kebutuhan. Ini berarti, misalnya, bahwa pekerjaan ETL malam Anda tidak akan menunda dasbor pagi.
Dengan provisi simpul cepat di cloud, mesin pemrosesan kueri terdistribusi secara otomatis menskalakan sumber daya komputasi ke atas atau ke bawah sebagai respons terhadap perubahan volume kueri, ukuran data, dan kompleksitas kueri. Fabric Data Warehouse memiliki kemampuan pemrosesan paralel untuk himpunan data atau data kecil pada skala multi-petabyte.
Mesin eksekusi kueri
Mesin eksekusi kueri adalah proses yang menjalankan bagian dari rencana eksekusi terdistribusi yang ditetapkan ke simpul komputasi individual. Mesin eksekusi kueri didasarkan pada mesin yang sama dengan yang digunakan oleh SQL Server dan Azure SQL Database untuk mengimplementasikan eksekusi mode batch dan format data kolumnar, guna memastikan analitik efisien pada big data dengan biaya yang optimal.
Mesin eksekusi kueri membaca data langsung dari file Delta Parquet yang disimpan di Fabric OneLake, dan memanfaatkan beberapa lapisan penembolokan (memori dan SSD) untuk mempercepat performa kueri dan memastikan kueri dijalankan dengan kecepatan optimal. Mesin eksekusi kueri memproses data dalam memori dan, jika perlu, mengambil data tambahan dari cache SSD atau penyimpanan OneLake.
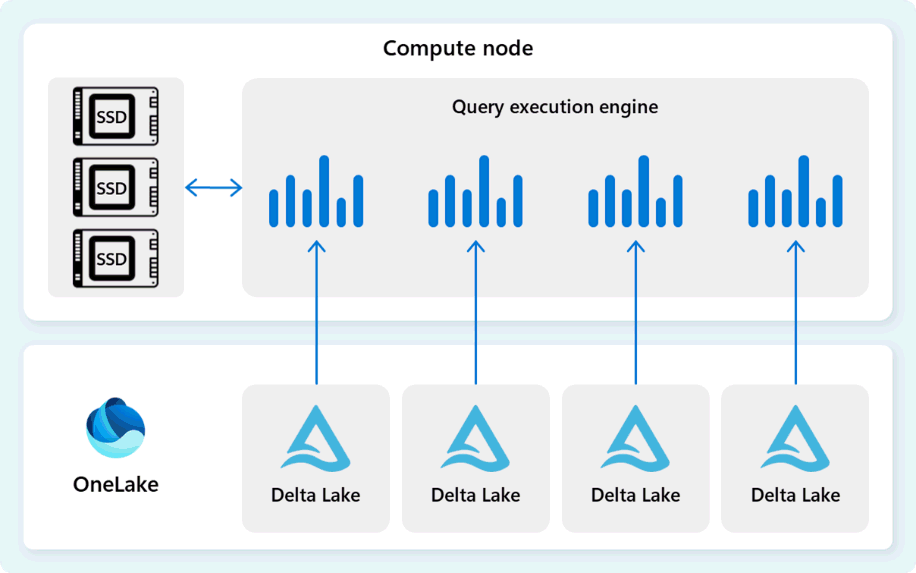
Saat memproses data, mesin eksekusi kueri melakukan eliminasi grup kolom dan baris untuk melewati segmen yang tidak relevan dengan kueri. Pengoptimalan ini mengurangi jumlah data yang dipindai dari file dan cache memori, membantu meminimalkan penggunaan sumber daya dan meningkatkan waktu eksekusi keseluruhan.
Mesin eksekusi kueri unggul dalam memfilter dan menggabungkan miliaran baris, mendukung pola analitik data generik yang digunakan dalam solusi gudang data modern. Eksekusi mode batch memanfaatkan kemampuan CPU modern untuk memproses beberapa baris secara paralel, mengurangi overhead secara dramatis dan membuat kueri berjalan hingga ratusan kali lebih cepat dibandingkan dengan eksekusi baris demi baris tradisional.
Metadata dan manajemen transaksi
Mesin gudang menggunakan metadata untuk menjelaskan skema tabel, organisasi file, riwayat versi, dan status transaksional. Metadata ini memungkinkan mesin gudang mengelola dan mengkueri data secara efisien. Fabric Data Warehouse menawarkan metadata dan arsitektur manajemen transaksi yang kuat dan komprehensif, memperluas manajer transaksi OLTP untuk mengatur operasi metadata yang sangat bersamaan dan memastikan kepatuhan ACID.
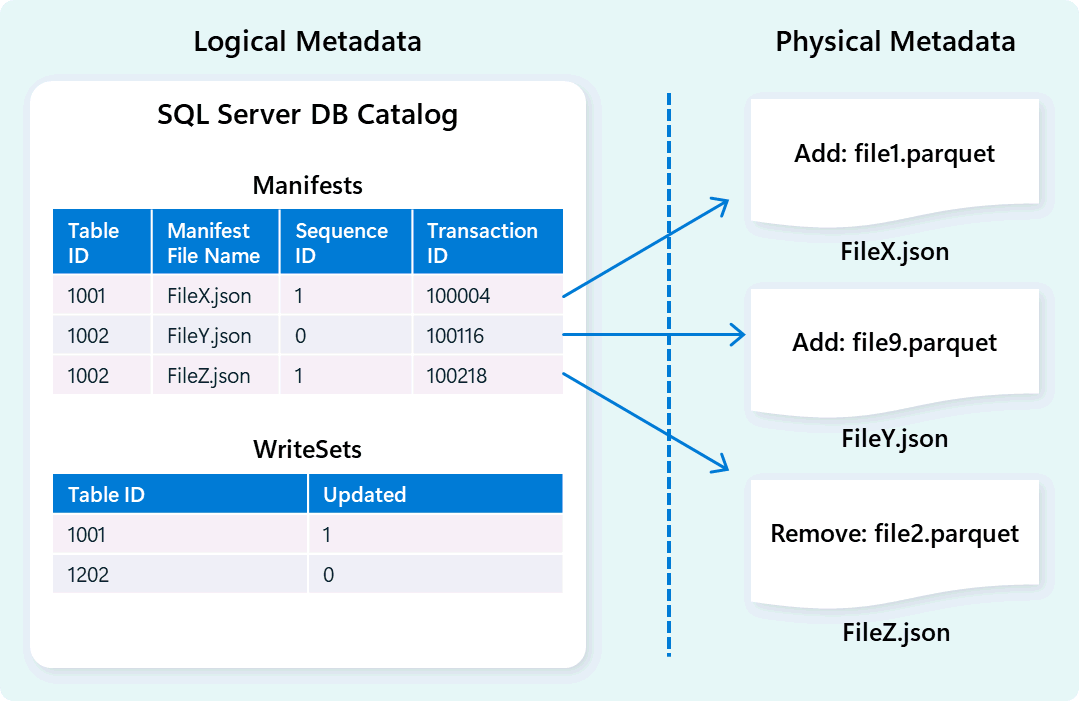
Desain ini memungkinkan navigasi status transaksi yang cepat dan andal, mendukung beban kerja dengan konkurensi tinggi sambil memastikan konsistensi.
Penyimpanan dan penyerapan data
Fabric Data Warehouse menggunakan arsitektur lakehouse dengan format Delta sumber terbuka untuk penyimpanan berkinerja tinggi yang dapat diskalakan, aman, dan berkinerja tinggi. Format tabel Delta mendukung versi data, memungkinkan akses instan ke cuplikan historis melalui perjalanan waktu dan kloning tanpa salinan untuk operasi pengujian dan pengembalian ulang yang aman. Data pengguna disimpan dalam OneLake, memungkinkan semua mesin Fabric mengakses data bersama secara efisien tanpa redundansi.
Dibangun di atas fondasi ini, Fabric Data Warehouse dirancang untuk memberikan performa penyerapan data yang optimal dengan fokus pada kesederhanaan dan fleksibilitas. Mesin secara efisien mengelola penyimpanan data tabel melalui pemadatan data otomatis, yang mengonsolidasikan file terfragmentasi di latar belakang untuk mengurangi pemindaian data yang tidak perlu. Metode distribusi data cerdasnya membagi dan mengatur data menjadi sel yang dipartisi mikro untuk meningkatkan pemrosesan paralel dan meningkatkan hasil kueri. Kemampuan ini berfungsi secara otonom, tanpa perlu penyesuaian manual.