Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Copilot di Microsoft Fabric adalah teknologi bantuan AI generatif yang bertujuan untuk meningkatkan pengalaman analitik data di platform Fabric. Artikel ini membantu Anda memahami cara kerja Copilot in Fabric dan memberikan beberapa panduan dan pertimbangan tingkat tinggi tentang cara terbaik Anda menggunakannya.
Nota
Kemampuan copilot berkembang dari waktu ke waktu. Jika Anda berencana untuk menggunakan Copilot, pastikan Anda tetap mendapatkan informasi terbaru tentang pembaruan bulanan untuk Fabric dan perubahan atau pengumuman apa pun pada pengalaman Copilot.
Artikel ini membantu Anda memahami cara kerja Copilot in Fabric, termasuk arsitektur dan biayanya. Informasi dalam artikel ini dimaksudkan untuk memandu Anda dan organisasi Anda untuk menggunakan dan mengelola Copilot secara efektif. Artikel ini terutama ditargetkan pada:
Direktur atau manajer BI dan analitik: Pembuat keputusan yang bertanggung jawab untuk mengawasi program dan strategi BI, dan yang memutuskan apakah akan mengaktifkan dan menggunakan Copilot di Fabric atau alat AI lainnya.
Administrator fabric: Orang-orang di organisasi yang mengawasi Microsoft Fabric dan berbagai beban kerjanya. Administrator Fabric mengawasi siapa yang dapat menggunakan Copilot di Fabric untuk setiap beban kerja ini dan memantau bagaimana penggunaan Copilot memengaruhi kapasitas Fabric yang tersedia.
Arsitek data: Orang-orang yang bertanggung jawab untuk merancang, membangun, dan mengelola platform dan arsitektur yang mendukung data dan analitik dalam organisasi. Arsitek data mempertimbangkan penggunaan Copilot dalam desain arsitektur.
Tim Center of Excellence (COE), IT, dan BI: Tim yang bertanggung jawab untuk memfasilitasi adopsi dan penggunaan platform data yang sukses seperti Fabric dalam organisasi. Tim dan individu ini mungkin menggunakan alat AI seperti Copilot sendiri, tetapi juga mendukung dan mentor pengguna layanan mandiri di organisasi untuk mendapatkan manfaat dari mereka juga.
Gambaran umum cara kerja Copilot in Fabric
Copilot in Fabric berfungsi mirip dengan Microsoft Copilots lainnya, seperti Microsoft 365 Copilot, Microsoft Security Copilot, dan Copilots dan AI generatif di Power Platform. Namun, ada beberapa aspek yang khusus untuk cara kerja Copilot in Fabric.
Diagram gambaran umum proses
Diagram berikut menggambarkan gambaran umum tentang cara kerja Copilot in Fabric.
Nota
Diagram berikut menggambarkan arsitektur umum Copilot pada Fabric. Namun, tergantung pada beban kerja dan pengalaman tertentu, mungkin ada penambahan atau perbedaan.
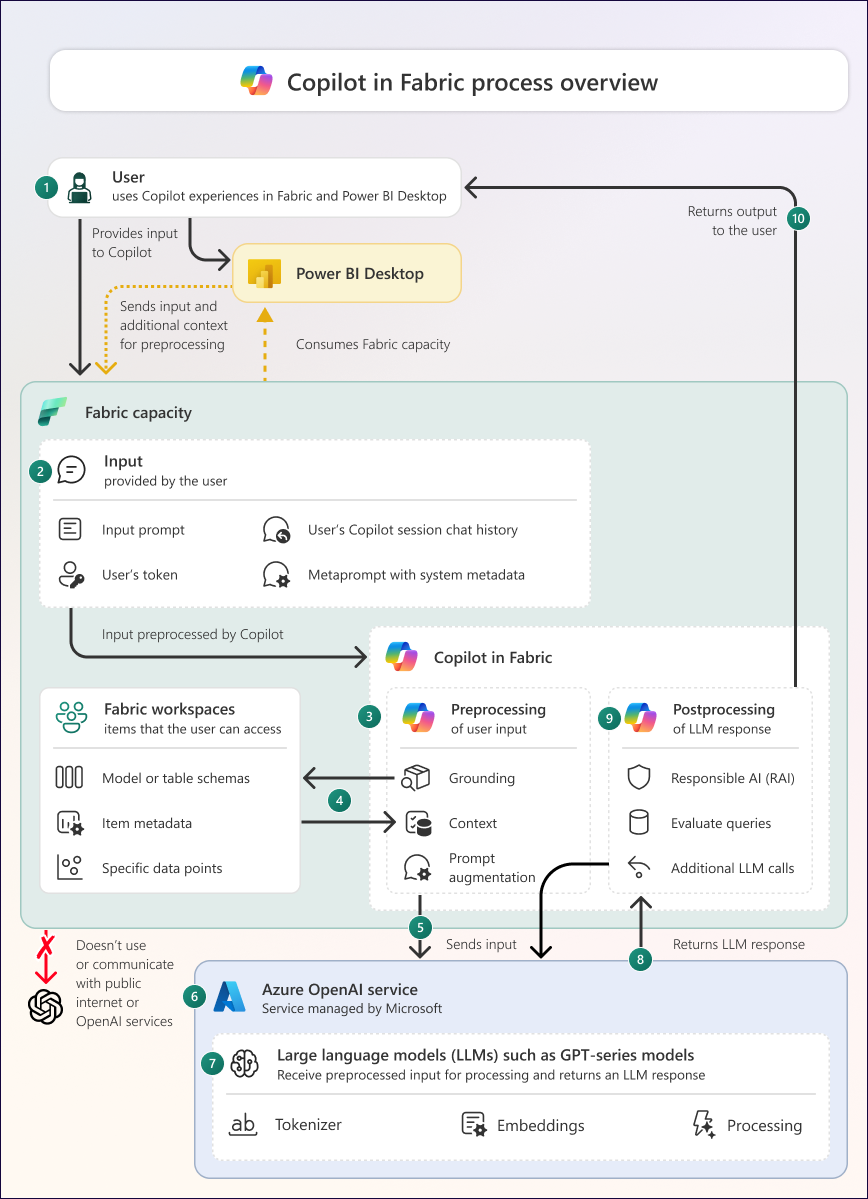
Diagram terdiri dari bagian dan proses berikut:
| Benda | Deskripsi |
|---|---|
| 1 | Pengguna menyediakan input ke Copilot di Fabric, Power BI Desktop, atau aplikasi seluler Power BI. Input dapat berupa perintah tertulis atau interaksi lain yang menghasilkan perintah. Semua interaksi dengan Copilot bersifat khusus pengguna. |
| 2 | Input berisi informasi yang mencakup prompt, token pengguna, dan konteks seperti riwayat obrolan sesi Copilot pengguna dan meta-prompt lengkap dengan metadata sistem, termasuk lokasi pengguna dan aktivitas yang sedang dilakukan di Fabric atau Power BI Desktop. |
| 3 | Copilot menangani prapemrosesan dan pascapemrosesan input pengguna dan respons model bahasa besar (LLM), masing-masing. Langkah-langkah spesifik tertentu yang dilakukan selama praproses dan pascaproses bergantung pada pengalaman Copilot mana yang digunakan seseorang. Copilot harus diaktifkan oleh administrator Fabric di pengaturan penyewa untuk menggunakannya. |
| 4 | Selama pra-pemrosesan, Copilot melakukan grounding untuk mengambil informasi kontekstual tambahan untuk meningkatkan kekhususan dan kegunaan respons LLM akhirnya. Data grounding mungkin mencakup metadata (seperti skema dari lakehouse atau model semantik) atau titik data dari item di ruang kerja, atau riwayat obrolan dari sesi Copilot saat ini. Copilot hanya mengambil data landasan yang dapat diakses oleh pengguna. |
| 5 | Pra-pemrosesan menghasilkan input akhir: permintaan akhir dan data grounding. Data mana yang dikirim tergantung pada pengalaman Copilot tertentu dan apa yang diminta pengguna. |
| 6 | Copilot mengirimkan input ke Azure OpenAI Service. Layanan ini dikelola oleh Microsoft dan tidak dapat dikonfigurasi oleh pengguna. Azure OpenAI tidak melatih model dengan data Anda. Jika Azure OpenAI tidak tersedia di area geografis Anda dan Anda telah mengaktifkan pengaturan penyewa Data yang dikirim ke Azure OpenAI dapat diproses di luar wilayah geografis kapasitas Anda, batas kepatuhan, atau instans cloud nasional, maka Copilot mungkin mengirim data Anda di luar area geografis ini. |
| 7 | Azure OpenAI menghosting LLM seperti seri model GPT. Azure OpenAI tidak menggunakan layanan publik atau API OpenAI, dan OpenAI tidak memiliki akses ke data Anda. LLM ini tokenisasi input dan menggunakan penyematan dari data pelatihan mereka untuk memproses input menjadi respons. LLM terbatas dalam cakupan dan skala data pelatihan mereka. Azure OpenAI berisi konfigurasi yang menentukan bagaimana LLM memproses input dan respons mana yang dikembalikannya. Pelanggan tidak dapat melihat atau mengubah konfigurasi ini. Panggilan ke Layanan OpenAI dilakukan melalui Azure, dan bukan melalui internet publik. |
| 8 | Respons LLM dikirim dari Azure OpenAI ke Copilot di Fabric. Respons ini terdiri dari teks, yang mungkin merupakan bahasa, kode, atau metadata alami. Respons mungkin mencakup informasi yang tidak akurat atau berkualitas rendah. Ini juga tidak deterministik, yang berarti bahwa respons yang berbeda mungkin dikembalikan untuk input yang sama. |
| 9 | Copilot pascaproses respons LLM. Postprocessing mencakup pemfilteran untuk AI yang bertanggung jawab, tetapi juga melibatkan penanganan respons LLM dan menghasilkan output Copilot akhir. Langkah-langkah spesifik yang diambil selama pascaproscessing tergantung pada Pengalaman Copilot penggunaan individu. |
| 10 | Copilot mengembalikan output akhir kepada pengguna. Pengguna memeriksa output sebelum digunakan, karena output tidak berisi indikasi keandalan, akurasi, atau keterpercayaan. |
Bagian berikutnya menjelaskan lima langkah dalam proses Copilot yang digambarkan dalam diagram sebelumnya. Langkah-langkah ini menjelaskan secara rinci bagaimana Copilot beralih dari input pengguna ke output pengguna.
Langkah 1: Pengguna menyediakan input ke Copilot
Untuk menggunakan Copilot, pengguna harus terlebih dahulu mengirimkan input. Input ini dapat berupa perintah tertulis yang dikirimkan pengguna sendiri, atau dapat berupa permintaan yang dihasilkan oleh Copilot ketika pengguna memilih elemen interaktif di UI. Bergantung pada beban kerja Fabric, item, dan pengalaman Copilot tertentu yang digunakan seseorang, mereka memiliki cara berbeda untuk memberikan input ke Copilot.
Bagian berikut menjelaskan beberapa contoh bagaimana pengguna dapat memberikan input ke Copilot.
Input melalui panel obrolan Copilot
Dengan banyak pengalaman Copilot di Fabric, Anda dapat memperluas panel obrolan Copilot untuk berinteraksi dengan Copilot menggunakan bahasa alami seperti yang Anda lakukan dengan chatbot atau layanan olahpesan. Di panel obrolan Copilot, Anda dapat menulis perintah bahasa alami yang menjelaskan tindakan yang Anda inginkan untuk diambil Copilot. Atau, panel obrolan Copilot mungkin berisi tombol dengan perintah yang disarankan yang dapat Anda pilih. Berinteraksi dengan tombol ini menyebabkan Copilot menghasilkan prompt yang sesuai.
Gambar berikut ini memperlihatkan contoh penggunaan panel obrolan Copilot untuk mengajukan pertanyaan data tentang laporan Power BI.

Nota
Jika Anda menggunakan browser Microsoft Edge, Anda mungkin juga memiliki akses ke Copilot di sana. Copilot di Edge juga dapat membuka panel obrolan Copilot (atau bilah samping) di browser Anda. Copilot di Edge tidak dapat berinteraksi dengan atau menggunakan salah satu pengalaman Copilot di Fabric. Meskipun kedua Copilot memiliki pengalaman pengguna yang sama, Copilot di Edge benar-benar terpisah dari Copilot di Fabric.
Input melalui jendela pop-up tergantung konteks
Dalam pengalaman tertentu, Anda dapat memilih ikon Copilot untuk memicu jendela pop-up untuk berinteraksi dengan Copilot. Contohnya termasuk saat Anda menggunakan Copilot dalam tampilan kueri DAX atau dalam tampilan pembuatan skrip TMDL Power BI Desktop. Jendela pop-up ini berisi area bagi Anda untuk memasukkan prompt bahasa alami (mirip dengan panel obrolan Copilot) serta tombol khusus konteks yang dapat menghasilkan prompt untuk Anda. Jendela ini mungkin juga berisi informasi output, seperti penjelasan tentang kueri atau konsep DAX saat menggunakan Copilot dalam tampilan kueri DAX.
Gambar berikut ini memperlihatkan contoh seseorang yang menggunakan pengalaman Copilot dalam tampilan kueri DAX untuk menjelaskan kueri yang mereka buat dengan menggunakan Copilot di Power BI.

Jenis input pengguna
Input Copilot dapat berasal dari perintah tertulis atau tombol di antarmuka pengguna.
Perintah tertulis: Pengguna dapat menulis permintaan di panel obrolan Copilot, atau di pengalaman Copilot lainnya, seperti tampilan kueri DAX di Power BI Desktop. Perintah tertulis mengharuskan pengguna menjelaskan instruksi atau pertanyaan untuk Copilot secara memadai. Misalnya, pengguna dapat mengajukan pertanyaan tentang model semantik atau laporan saat menggunakan Copilot di Power BI.
Tombol: Pengguna dapat memilih tombol di panel obrolan Copilot atau pengalaman Copilot lainnya untuk memberikan input. Copilot kemudian menghasilkan prompt berdasarkan pilihan pengguna. Tombol-tombol ini dapat menjadi input awal ke Copilot, seperti saran di panel obrolan Copilot. Namun, tombol-tombol ini mungkin juga muncul selama sesi ketika Copilot membuat saran atau meminta klarifikasi. Perintah yang dihasilkan Copilot tergantung pada konteksnya, seperti riwayat obrolan sesi saat ini. Contoh input tombol adalah ketika Anda meminta Copilot untuk menyarankan sinonim untuk bidang model, atau deskripsi untuk ukuran model.
Selain itu, Anda dapat memberikan input dalam layanan atau aplikasi yang berbeda:
Fabric: Anda dapat menggunakan Copilot di Fabric dari browser web Anda. Ini adalah satu-satunya cara untuk menggunakan Copilot untuk item apa pun yang Anda buat, kelola, dan konsumsi secara eksklusif di Fabric.
Power BI Desktop: Anda bisa menggunakan Copilot di Power BI Desktop dengan model dan laporan semantik. Ini mencakup pengalaman mengembangkan dan menggunakan Copilot pada beban kerja Power BI di Fabric.
Aplikasi seluler Power BI: Anda bisa menggunakan Copilot di aplikasi seluler Power BI jika laporan berada di ruang kerja yang didukung (atau aplikasi yang tersambung ke ruang kerja tersebut) dengan Copilot diaktifkan.
Nota
Untuk menggunakan Copilot dengan Power BI Desktop, Anda harus mengonfigurasi Power BI Desktop untuk menggunakan konsumsi Copilot dari ruang kerja yang didukung oleh kapasitas Fabric. Kemudian Anda dapat menggunakan Copilot dengan model semantik yang diterbitkan ke ruang kerja apa pun, termasuk ruang kerja Pro dan PPU.
Meskipun Anda tidak dapat mengubah perintah yang dihasilkan Copilot saat memilih tombol dengan perintah tertulis, Anda dapat mengajukan pertanyaan dan memberikan instruksi menggunakan bahasa alami. Salah satu cara terpenting untuk meningkatkan hasil yang Anda dapatkan dengan Copilot adalah dengan menulis perintah yang jelas dan deskriptif yang secara akurat menyampaikan ingin Anda lakukan.
Meningkatkan perintah tertulis untuk Copilot
Kejelasan dan kualitas permintaan yang dikirimkan pengguna ke Copilot dapat memengaruhi kegunaan output yang diterima pengguna. Apa yang merupakan perintah tertulis yang baik tergantung pada pengalaman Copilot tertentu yang Anda gunakan; namun, ada beberapa teknik yang dapat Anda terapkan ke semua pengalaman untuk meningkatkan permintaan Anda secara umum.
Berikut adalah beberapa cara untuk meningkatkan perintah yang Anda kirimkan ke Copilot:
Gunakan perintah bahasa Inggris: Saat ini, fitur Copilot berfungsi paling baik dalam bahasa Inggris. Itu karena korpus data pelatihan untuk LLM ini sebagian besar berbahasa Inggris. Bahasa lain mungkin tidak berfungsi juga. Anda dapat mencoba menulis perintah dalam bahasa lain, tetapi untuk hasil terbaik, kami sarankan Anda menulis dan mengirimkan perintah bahasa Inggris.
Bersikaplah spesifik: Hindari ambiguitas atau ketidakjelasan dalam pertanyaan dan instruksi. Sertakan detail yang memadai untuk menjelaskan tugas yang Anda inginkan untuk dilakukan Copilot, dan apa output yang Anda harapkan.
Berikan konteks: Jika perlu, berikan konteks yang relevan untuk permintaan Anda, termasuk apa yang ingin Anda lakukan atau pertanyaan apa yang ingin Anda jawab dengan output. Misalnya, komponen kunci untuk prompt yang baik dapat mencakup:
- Tujuan: Output apa yang Anda inginkan untuk dicapai Copilot.
- Konteks: Apa yang ingin Anda lakukan dengan output tertentu dan mengapa.
- Harapan: Seperti apa output yang Anda harapkan.
- Sumber: Data atau bidang apa yang harus digunakan Copilot.
Gunakan kata kerja: Merujuk secara eksplisit pada tindakan tertentu yang ingin Anda dilakukan oleh Copilot, seperti "buat halaman laporan" atau "memfilter akun kunci pelanggan".
Gunakan terminologi yang benar dan relevan: Lihat secara eksplisit istilah yang sesuai dalam perintah Anda, seperti nama fungsi, bidang, atau tabel, jenis visual, atau terminologi teknis. Hindari kesalahan ejaan, akronim, atau singkatan, serta tata bahasa yang berlebihan, atau karakter atipikal seperti karakter unicode atau emoji.
Iterasi dan pemecahan masalah: Ketika Anda tidak mendapatkan hasil yang diharapkan, coba sesuaikan permintaan Anda dan kirim ulang untuk melihat apakah ini meningkatkan output. Beberapa pengalaman Copilot juga menyediakan tombol Coba Lagi untuk mengirimkan kembali permintaan yang sama dan memeriksa hasil yang berbeda.
Penting
Pertimbangkan untuk melatih pengguna dalam membuat prompt yang baik sebelum Anda mengaktifkan Copilot bagi mereka. Pastikan bahwa pengguna memahami perbedaan antara perintah yang jelas yang dapat menghasilkan hasil yang berguna, dan perintah yang tidak jelas yang tidak.
Selain itu, Copilot dan banyak alat LLM lainnya tidak deterministik. Ini berarti bahwa dua pengguna yang mengirimkan permintaan yang sama yang menggunakan data grounding yang sama dapat memperoleh hasil yang berbeda. Non-determinisme ini melekat pada teknologi dasar AI generatif, dan merupakan pertimbangan penting ketika Anda mengharapkan atau membutuhkan hasil deterministik, seperti jawaban atas pertanyaan data, seperti "Apa penjualan pada Agustus 2021?"
Informasi input lain yang digunakan Copilot dalam pra-pemrosesan
Selain input yang disediakan pengguna, Copilot juga mengambil informasi tambahan yang digunakannya dalam praproses selama langkah berikutnya. Informasi ini mencakup:
Token pengguna. Copilot tidak beroperasi di bawah akun atau otoritas sistem. Semua informasi yang dikirim ke dan digunakan oleh Copilot adalah spesifik untuk pengguna; Copilot tidak dapat mengizinkan pengguna untuk melihat atau mengakses item atau data yang belum mereka miliki izin untuk melihatnya.
Riwayat obrolan sesi Copilot untuk sesi saat ini. Untuk pengalaman obrolan atau panel obrolan Copilot, Copilot selalu menyediakan riwayat Obrolan untuk digunakan dalam pra-pemrosesan sebagai bagian dari konteks data grounding. Copilot tidak mengingat atau menggunakan riwayat obrolan dari sesi sebelumnya.
Meta-prompt dengan metadata sistem. Meta-prompt menyediakan konteks tambahan tentang di mana pengguna berada dan apa yang mereka lakukan di Fabric atau Power BI Desktop. Informasi meta-prompt ini digunakan selama praproses untuk menentukan keterampilan atau alat mana yang harus digunakan Copilot untuk menjawab pertanyaan pengguna.
Setelah pengguna mengirimkan input mereka, Copilot melanjutkan ke langkah berikutnya.
Langkah 2: Copilot melakukan praproses input
Sebelum mengirimkan permintaan ke Layanan Azure OpenAI, Copilot melakukan praproses . Praproses merupakan semua tindakan yang ditangani oleh Copilot antara saat menerima input dan kapan input ini diproses di Layanan Azure OpenAI. Pra-pemrosesan diperlukan untuk memastikan bahwa output Copilot spesifik dan sesuai dengan instruksi atau pertanyaan Anda.
Anda tidak dapat memengaruhi bagaimana prapemrosesan dilakukan oleh Copilot. Namun, penting untuk memahami pra-pemrosesan sehingga Anda tahu data apa yang digunakan Copilot dan bagaimana mendapatkannya. Ini berkaitan dengan pemahaman biaya Copilot di Fabric, serta saat Anda memecahkan masalah mengapa hasilnya salah atau tidak terduga.
Petunjuk / Saran
Dalam pengalaman tertentu, Anda juga dapat membuat perubahan pada item sehingga data dasar mereka lebih terstruktur untuk digunakan oleh Copilot. Contohnya adalah melakukan pemodelan linguistik dalam model semantik, atau menambahkan sinonim dan deskripsi ke pengukuran dan kolom model semantik.
Diagram berikut menggambarkan apa yang terjadi selama praproses oleh Copilot di Fabric.
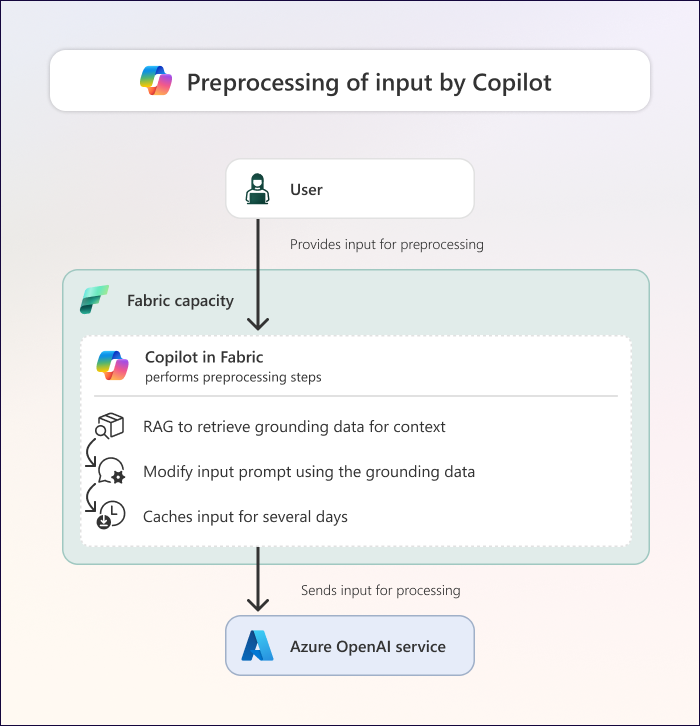
Setelah menerima input pengguna, Copilot melakukan praproses, yang melibatkan langkah-langkah berikut:
Landasan: Copilot melakukan retrieval augmented generation (RAG) untuk mengumpulkan data grounding. Data grounding terdiri dari informasi yang relevan dari konteks saat ini di mana Anda menggunakan Copilot di Fabric. Data grounding mungkin mencakup konteks seperti:
- Riwayat obrolan dari sesi saat ini dengan Copilot.
- Metadata tentang item Fabric yang Anda gunakan dengan Copilot (seperti skema model semantik atau lakehouse Anda, atau metadata dari visual laporan).
- Titik data tertentu, seperti yang ditampilkan dalam visual laporan. Metadata laporan dalam konfigurasi visual juga berisi titik data.
- Meta-prompts, yang merupakan instruksi tambahan yang disediakan untuk setiap pengalaman untuk membantu memastikan output yang lebih spesifik dan konsisten.
Augmentasi permintaan: Bergantung pada skenario, Copilot menulis ulang (atau menambah) perintah berdasarkan input dan data grounding. Prompt tertambah harus lebih baik dan lebih sadar konteks daripada permintaan input asli Anda.
Caching: Dalam skenario tertentu, Copilot menyimpan cache perintah Anda dan data grounding selama 48 jam. Penyimpanan cache untuk prompt memastikan bahwa permintaan berulang mengembalikan hasil yang sama selama dalam keadaan di-cache, bahwa hasil tersebut dikembalikan dengan lebih cepat, dan bahwa Anda tidak menghabiskan kapasitas Fabric hanya demi mengulangi permintaan dalam konteks yang sama. Penembolokan terjadi di dua tempat berbeda:
- Cache browser pengguna.
- Cache back-end pertama di wilayah asal penyewa, tempat cache disimpan untuk tujuan audit. Tidak ada data yang di-cache di Azure OpenAI Service atau lokasi GPU. Untuk informasi selengkapnya tentang caching di Fabric, lihat laporan resmi keamanan Microsoft Fabric.
Mengirim input ke Azure OpenAI: Copilot mengirimkan prompt yang ditingkatkan dan data dasar yang relevan ke Layanan Azure OpenAI.
Saat Copilot melakukan grounding, Copilot hanya mengumpulkan informasi dari data atau item yang dapat diakses pengguna secara normal. Copilot mematuhi peran di ruang kerja, izin item, dan keamanan data. Salinan juga tidak dapat mengakses data dari pengguna lain; interaksi dengan Copilot khusus untuk setiap pengguna individu.
Data yang dikumpulkan Copilot selama proses grounding dan proses Azure OpenAI tergantung pada pengalaman Copilot tertentu yang Anda gunakan. Untuk informasi selengkapnya, lihat Data apa yang digunakan Copilot dan bagaimana prosesnya?.
Setelah praproses selesai dan Copilot telah mengirim input ke Azure OpenAI, Azure OpenAI Service dapat memproses input tersebut untuk menghasilkan respons dan output yang dikirim kembali ke Copilot.
Langkah 3: Azure OpenAI memproses perintah dan menghasilkan output
Semua pengalaman Copilot didukung oleh Azure OpenAI Service.
Memahami Layanan Azure OpenAI
Copilot menggunakan Azure OpenAI—bukan layanan OpenAI yang tersedia untuk umum—untuk memproses semua data dan mengembalikan respons. Seperti disebutkan sebelumnya, respons ini diproduksi oleh LLM. LLM adalah pendekatan khusus untuk AI "sempit" yang berfokus pada penggunaan pembelajaran mendalam untuk menemukan dan mereproduksi pola dalam data yang tidak terstruktur; khususnya, teks. Teks dalam konteks ini mencakup bahasa alami, metadata, kode, dan susunan karakter lain yang bermakna secara semantik.
Copilot saat ini menggunakan kombinasi model GPT, termasuk seri model Generative Pre-trained Transformer (GPT) dari OpenAI.
Nota
Anda tidak dapat memilih atau mengubah model yang digunakan Copilot, termasuk menggunakan model fondasi lain atau model Anda sendiri. Copilot in Fabric menggunakan berbagai model. Anda juga tidak dapat mengubah atau mengonfigurasi Layanan Azure OpenAI agar berulah secara berbeda dengan Copilot di Fabric; layanan ini dikelola oleh Microsoft.
Model yang digunakan oleh Copilot di Fabric saat ini tidak menggunakan penyempurnaan apa pun. Model sebaliknya mengandalkan data dasar dan meta-prompt untuk membuat output yang lebih spesifik dan berguna.
Model yang digunakan oleh Copilot di Fabric saat ini tidak menggunakan penyempurnaan apa pun. Model sebaliknya mengandalkan data dasar dan meta-prompt untuk membuat output yang lebih spesifik dan berguna.
Microsoft menghosting model OpenAI di lingkungan Microsoft Azure dan layanan tidak berinteraksi dengan layanan publik apa pun oleh OpenAI (misalnya, ChatGPT atau API OpenAI publik). Data Anda tidak digunakan untuk melatih model dan tidak tersedia untuk pelanggan lain. Untuk informasi selengkapnya, lihat Layanan Azure OpenAI.
Memahami tokenisasi
Sangat penting bahwa Anda memahami tokenisasi karena biaya Copilot di Fabric (yaitu berapa banyak kapasitas Fabric yang dikonsumsi Copilot) ditentukan oleh jumlah token yang dihasilkan oleh input dan output Copilot Anda.
Untuk memproses input teks dari Copilot, Azure OpenAI harus terlebih dahulu mengonversi input tersebut menjadi representasi numerik. Langkah kunci dalam proses ini adalah tokenisasi, yang merupakan partisi teks input ke bagian yang berbeda dan lebih kecil, yang disebut token. Token adalah sekumpulan karakter yang terjadi bersama, dan ini adalah unit informasi terkecil yang digunakan LLM untuk menghasilkan outputnya. Setiap token memiliki ID numerik yang sesuai, yang menjadi kosakata LLM untuk mengodekan dan menggunakan teks sebagai angka. Ada berbagai cara untuk mem-tokenisasi teks, dan beragam LLM mem-tokenisasi teks masukan dengan cara yang berbeda. Azure OpenAI menggunakan Byte-Pair Encoding (BPE), yang merupakan metode tokenisasi sub-kata.
Untuk lebih memahami apa itu token dan bagaimana perintah menjadi token, pertimbangkan contoh berikut. Contoh ini menunjukkan perintah input dan tokennya, yang diperkirakan menggunakan tokenizer Platform OpenAI(untuk GPT4). Di bawah token yang disorot dalam teks perintah adalah array (atau daftar) ID token numerik.

Dalam contoh, setiap sorotan berwarna berbeda menunjukkan satu token. Seperti disebutkan sebelumnya, Azure OpenAI menggunakan tokenisasi subkata , sehingga token bukan kata, tetapi juga bukan karakter, atau jumlah karakter tetap. Misalnya "laporan" adalah token tunggal, tetapi "." juga.
Untuk menegaskan kembali, Anda harus memahami apa itu token karena biaya Copilot (atau tingkat konsumsi kapasitas Fabric-nya) ditentukan oleh token. Oleh karena itu, memahami apa itu token dan bagaimana token input dan output dibuat membantu Anda memahami dan mengantisipasi bagaimana penggunaan Copilot mengakibatkan konsumsi Fabric CUs. Untuk informasi selengkapnya tentang biaya Copilot di Fabric, lihat bagian yang sesuai nanti di artikel ini.
Copilot in Fabric menggunakan token input dan output, seperti yang digambarkan dalam diagram berikut.

Copilot membuat dua jenis token yang berbeda:
- Token masuk dihasilkan dari tokenisasi prompt akhir dan data pendukung apa pun.
- Token keluaran dihasilkan dari respons tokenisasi LLM.
Beberapa pengalaman Copilot menghasilkan beberapa panggilan LLM. Misalnya, saat mengajukan pertanyaan data tentang model dan laporan, respons LLM pertama mungkin merupakan kueri yang dievaluasi terhadap model semantik. Copilot kemudian mengirimkan hasil kueri yang dievaluasi ke Azure OpenAI lagi dan meminta ringkasan, yang dikembalikan Azure OpenAI dengan respons lain. Panggilan LLM tambahan ini mungkin ditangani dan respons LLM digabungkan selama tahap pascapemrosesan.
Nota
Dengan Copilot di Fabric, kecuali untuk perubahan pada perintah input tertulis, Anda hanya dapat mengoptimalkan token input dan output dengan menyesuaikan konfigurasi item yang relevan, seperti menyembunyikan kolom dalam model semantik atau mengurangi jumlah visual atau halaman dalam laporan. Anda tidak dapat mencegat atau memodifikasi data grounding sebelum dikirim ke Azure OpenAI by Copilot.
Memahami pemrosesan
Penting bagi Anda untuk memahami bagaimana LLM di Azure OpenAI memproses data Anda dan menghasilkan output, sehingga Anda dapat lebih memahami mengapa Anda mendapatkan output tertentu dari Copilot dan mengapa Anda harus secara kritis menilainya sebelum penggunaan atau pengambilan keputusan lebih lanjut.
Nota
Artikel ini memberikan gambaran umum tingkat tinggi yang sederhana tentang cara kerja LLM yang digunakan Copilot (seperti GPM). Untuk detail teknis dan pemahaman yang lebih mendalam tentang bagaimana model GPT memproses input untuk menghasilkan respons, atau tentang arsitekturnya, baca makalah penelitian Attention Is All You Need (2017) oleh Ashish Vaswani dan lain-lain, dan Language Models are Few-Shot Learners (2020) oleh Tom Brown dan lain-lain.
Tujuan Copilot (dan LLM secara umum) adalah untuk memberikan output yang sesuai konteks dan berguna, berdasarkan input yang disediakan pengguna dan data grounding lain yang relevan. LLM melakukan ini dengan menginterpretasikan arti token dalam konteks yang sama, seperti yang terlihat dalam data pelatihan mereka. Untuk mendapatkan pemahaman semantik yang bermakna tentang token, LLM telah dilatih pada himpunan data besar yang dianggap terdiri dari informasi domain hak cipta dan publik. Namun, data pelatihan ini terbatas dalam hal kesegaran konten, kualitas, dan cakupan, yang menciptakan batasan untuk LLM dan alat yang menggunakannya, seperti Copilot. Untuk informasi selengkapnya tentang batasan ini, lihat Memahami batasan Copilot dan LLM nanti di artikel ini.
Arti semantik dari token ditangkap dalam konstruksi matematika yang disebut sebagai penyematan, yang mengubah token menjadi vektor padat dari bilangan nyata. Dalam istilah yang lebih sederhana, embedding menyediakan LLM arti semantik dari token tertentu, berdasarkan token lain di sekitarnya. Artinya tergantung pada data pelatihan LLM. Pikirkan token seperti blok penyusun unik, sementara penyematan membantu LLM mengetahui blok apa yang akan digunakan kapan.
Menggunakan token dan representasi, LLM di Azure OpenAI memproses input Anda dan menghasilkan respons. Pemrosesan ini adalah tugas intensif komputasi yang membutuhkan sumber daya yang signifikan, di mana biaya berasal. LLM menghasilkan responsnya satu token dalam satu waktu, di mana ia memilih setiap token menggunakan probabilitas yang dihitung berdasarkan konteks input. Setiap token yang dihasilkan juga ditambahkan ke konteks yang ada sebelum menghasilkan token berikutnya. Oleh karena itu, respons akhir dari LLM harus selalu berupa teks, yang nantinya bisa diproses lanjut oleh Copilot untuk membuat output yang lebih berguna bagi pengguna.
Penting untuk memahami beberapa aspek utama tentang respons yang dihasilkan ini:
- Ini non-deterministik; input yang sama dapat menghasilkan respons yang berbeda.
- Ini dapat ditafsirkan sebagai berkualitas rendah atau salah oleh pengguna dalam konteks mereka.
- Ini didasarkan pada data pelatihan LLM, yang terbatas dan terbatas dalam cakupannya.
Memahami batasan Copilot dan LLM
Penting untuk memahami dan mengakui keterbatasan Copilot dan teknologi dasar yang digunakannya. Memahami batasan ini membantu Anda mendapatkan nilai dari Copilot sekaligus mengurangi risiko yang melekat pada penggunaannya. Untuk menggunakan Copilot in Fabric secara efektif, Anda harus memahami kasus penggunaan dan skenario yang paling sesuai dengan teknologi ini.
Penting untuk mengingat pertimbangan berikut saat Anda menggunakan Copilot di Fabric:
Copilot in Fabric tidak deterministik. Kecuali ketika perintah dan outputnya di-cache, input yang sama dapat menghasilkan output yang berbeda. Saat Anda menerima berbagai kemungkinan output—seperti halaman laporan, pola kode, atau ringkasan—ini kurang bermasalah, karena Anda dapat mentolerir dan bahkan mungkin mengharapkan variasi dalam respons. Namun, untuk skenario ketika Anda hanya mengharapkan satu jawaban yang benar, Anda mungkin ingin mempertimbangkan pendekatan alternatif untuk Copilot.
Copilot in Fabric dapat menghasilkan output berkualitas rendah atau tidak akurat: Seperti semua alat LLM, Dimungkinkan bagi Copilot untuk menghasilkan output yang mungkin tidak benar, diharapkan, atau cocok untuk skenario Anda. Ini berarti bahwa Anda harus menghindari penggunaan Copilot dalam platform Fabric dengan data sensitif atau di area berisiko tinggi. Misalnya, Anda tidak boleh menggunakan output Copilot untuk menjawab pertanyaan data tentang proses penting bisnis, atau untuk membuat solusi data yang mungkin memengaruhi kesejahteraan pribadi atau kolektif individu. Pengguna harus memeriksa dan memvalidasi output Copilot sebelum mereka menggunakannya.
Copilot tidak memiliki pemahaman tentang "akurasi" atau "kebenaran": Output yang disediakan Copilot tidak memberikan indikasi bahwa ia dapat dipercaya, diandalkan, atau hal-hal serupa. Teknologi yang mendasar melibatkan pengenalan pola dan tidak dapat mengevaluasi kualitas atau kegunaan outputnya. Pengguna harus mengevaluasi output secara kritis sebelum mereka menggunakan output ini dalam pekerjaan atau pengambilan keputusan lainnya.
Copilot tidak dapat beralasan, memahami niat Anda, atau mengetahui konteks di luar inputnya: Sementara proses grounding Copilot memastikan bahwa output lebih spesifik, grounding saja tidak dapat memberikan Copilot semua informasi yang dibutuhkan untuk menjawab pertanyaan Anda. Misalnya, jika Anda menggunakan Copilot untuk menghasilkan kode, Copilot masih tidak tahu apa yang akan Anda lakukan dengan kode tersebut. Ini berarti bahwa kode mungkin berfungsi dalam satu konteks, tetapi tidak yang lain, dan pengguna harus mengubah output atau permintaan mereka untuk mengatasi hal ini.
Output Copilot dibatasi oleh data pelatihan LLM yang digunakannya: Dalam pengalaman Copilot tertentu, misalnya seperti ketika Anda membuat kode, mungkin ingin Copilot menghasilkan kode dengan fungsi atau pola yang baru dirilis. Namun, Copilot tidak akan dapat melakukan ini secara efektif jika tidak ada contoh dalam data pelatihan model GPT yang digunakannya, yang memiliki cutoff di masa lalu. Ini juga terjadi ketika Anda mencoba menerapkan Copilot ke konteks yang jarang dalam data pelatihannya, seperti saat menggunakan Copilot dengan editor TMDL di Power BI Desktop. Dalam skenario ini, Anda harus sangat waspada dan kritis terhadap output berkualitas rendah atau tidak akurat.
Peringatan
Untuk mengurangi risiko keterbatasan dan pertimbangan ini, serta fakta bahwa Copilot, LLM, dan AI generatif adalah teknologi yang belum matang, Anda tidak boleh menggunakan Copilot di Fabric untuk proses otonom, berisiko tinggi, atau yang kritis bagi bisnis dan pengambilan keputusan.
Untuk informasi selengkapnya, lihat Panduan keamanan untuk LLM.
Setelah Azure OpenAI Service memproses input dan menghasilkan respons, azure OpenAI Service mengembalikan respons ini sebagai output ke Copilot.
Langkah 4: Copilot melakukan postprocessing pada output
Setelah menerima respons dari Azure OpenAI, Copilot melakukan postprocessing tambahan untuk memastikan bahwa responsnya sesuai. Tujuan dari postprocessing adalah untuk memfilter konten yang tidak pantas.
Untuk melakukan pascaproses, Copilot mungkin melakukan tugas berikut:
Pemeriksaan AI yang bertanggung jawab: Memastikan Copilot mematuhi standar AI yang bertanggung jawab di Microsoft. Untuk informasi selengkapnya, lihat Apa yang harus saya ketahui untuk menggunakan Copilot secara bertanggung jawab?
Pemfilteran dengan moderasi konten Azure: Memfilter respons untuk memastikan bahwa Copilot hanya mengembalikan respons yang sesuai dengan skenario dan pengalaman. Berikut adalah beberapa contoh bagaimana Copilot melakukan pemfilteran dengan moderasi konten Azure:
- Penggunaan yang tidak diinginkan atau tidak tepat: Moderasi konten memastikan bahwa Anda tidak dapat menggunakan Copilot dengan cara yang tidak diinginkan atau tidak tepat, seperti mengajukan pertanyaan tentang topik lain di luar cakupan beban kerja, item, atau pengalaman yang Anda gunakan.
- Output yang tidak pantas atau menyinggung: Copilot mencegah output yang dapat berisi bahasa, istilah, atau frasa yang tidak dapat diterima.
- Upaya injeksi prompt: Copilot mencegah injeksi perintah, di mana pengguna mencoba menyembunyikan instruksi yang mengganggu dalam data grounding, seperti dalam nama objek, deskripsi, atau komentar kode dalam model semantik.
Batasan khusus skenario: Bergantung pada pengalaman Copilot mana yang Anda gunakan, mungkin ada pemeriksaan dan penanganan tambahan respons LLM sebelum Anda menerima output. Berikut adalah beberapa contoh bagaimana Copilot memberlakukan batasan khusus skenario:
- Pengurai kode: Kode yang dihasilkan mungkin dimasukkan melalui pengurai untuk memfilter respons dan kesalahan berkualitas rendah untuk memastikan bahwa kode berjalan. Ini terjadi saat Anda membuat kueri DAX dengan menggunakan Copilot di tampilan kueri DAX Power BI Desktop.
- Validasi visual dan laporan: Copilot memeriksa apakah visual dan laporan dapat dirender sebelum mengembalikannya dalam output. Copilot tidak memvalidasi apakah hasilnya akurat atau berguna, atau apakah kueri yang dihasilkan akan kedaluwarsa waktu (dan menghasilkan kesalahan).
Menangani dan menggunakan respons: Mengambil respons dan menambahkan informasi tambahan atau menggunakannya dalam proses lain untuk memberikan output kepada pengguna. Berikut adalah beberapa contoh bagaimana Copilot dapat menangani dan menggunakan respons selama postprocessing:
- Pembuatan halaman laporan Power BI: Copilot menggabungkan respons LLM (metadata visual laporan) dengan metadata laporan lainnya, yang menghasilkan halaman membuat laporan baru. Copilot mungkin juga menerapkan tema Copilot jika Anda belum membuat visual apa pun dalam laporan. Tema ini bukan bagian dari respons LLM, dan mencakup gambar latar belakang, serta warna dan gaya visual. Jika Anda telah membuat visual, maka Copilot tidak menerapkan tema Copilot dan menggunakan tema yang sudah Anda terapkan. Saat mengubah halaman laporan, Copilot juga akan menghapus halaman yang ada dan menggantinya dengan yang baru dengan penyesuaian yang diterapkan.
- Pertanyaan data Power BI: Copilot mengevaluasi pertanyaan terhadap model semantik.
- Saran langkah transformasi Gen2 aliran data di data factory: Copilot memodifikasi metadata item untuk menyisipkan langkah baru, serta menyesuaikan kueri tersebut.
Panggilan LLM tambahan: Dalam skenario tertentu, Copilot mungkin melakukan panggilan LLM tambahan untuk memperkaya output. Misalnya, Copilot mungkin mengirimkan hasil kueri yang dievaluasi ke LLM sebagai input baru dan meminta penjelasan. Penjelasan bahasa alami ini kemudian dipaketkan bersama dengan hasil kueri dalam keluaran yang dilihat pengguna di panel obrolan Copilot.
Jika konten difilter dalam output, maka Copilot akan mengirimkan kembali permintaan baru yang dimodifikasi, atau mengembalikan respons standar.
Kirim ulang perintah baru: Ketika respons tidak memenuhi batasan khusus skenario, Copilot akan menghasilkan permintaan lain yang dimodifikasi untuk mencoba lagi. Dalam beberapa keadaan, Copilot mungkin menyarankan beberapa permintaan baru untuk dipilih pengguna sebelum mengirimkan permintaan untuk menghasilkan output baru.
Respons standar: Respons standar dalam kasus ini akan menunjukkan kesalahan umum. Bergantung pada skenarionya, Copilot mungkin memberikan informasi tambahan untuk memandu pengguna menghasilkan input lain.
Nota
Tidak dimungkinkan untuk melihat respons asli yang difilter dari Azure OpenAI, atau untuk mengubah respons standar dari atau perilaku Copilot. Ini dikelola oleh Microsoft.
Setelah pascaproscessing selesai, Copilot kemudian akan mengembalikan output kepada pengguna.
Langkah 5: Copilot mengembalikan output kepada pengguna
Output untuk pengguna dapat berbentuk bahasa, kode, atau metadata alami. Metadata ini biasanya akan dirender di UI Fabric atau Power BI Desktop, seperti ketika Copilot mengembalikan visual Power BI atau menyarankan halaman laporan. Untuk beberapa pengalaman Copilot di Power BI, pengguna dapat menyediakan input dan output ke Copilot melalui aplikasi seluler Power BI.
Secara umum, output dapat memungkinkan intervensi pengguna atau sepenuhnya otonom dan tidak memungkinkan pengguna untuk mengubah hasilnya.
Intervensi pengguna: Output ini memungkinkan pengguna untuk memodifikasi hasil sebelum dievaluasi atau ditampilkan. Beberapa contoh output yang memungkinkan intervensi pengguna meliputi:
- Pembuatan kode seperti kueri DAX atau SQL, yang dapat dipilih pengguna untuk disimpan atau dijalankan.
- Pembuatan deskripsi pengukuran dalam model semantik, yang dapat dipilih pengguna untuk menyimpan, memodifikasi, atau menghapus.
Otonom: Output ini tidak dapat diubah oleh pengguna. Kode mungkin dievaluasi langsung terhadap item Fabric, atau teks tidak dapat diedit di panel. Beberapa contoh output otonom meliputi:
- Jawaban atas pertanyaan data tentang model semantik atau laporan di panel obrolan Copilot, yang secara otomatis mengevaluasi kueri terhadap model dan menunjukkan hasilnya.
- Ringkasan atau penjelasan kode, item, atau data, yang secara otomatis memilih apa yang akan dirangkum dan dijelaskan, dan menampilkan hasilnya.
- Pembuatan halaman laporan, yang secara otomatis membuat halaman dan visual dalam laporan.
Terkadang, sebagai bagian dari output, Copilot mungkin juga menyarankan tambahan, petunjuk tindak lanjut, seperti meminta klarifikasi, atau saran lain. Ini biasanya berguna ketika pengguna ingin meningkatkan hasil atau terus mengerjakan output tertentu, seperti menjelaskan konsep untuk memahami kode yang dihasilkan.
Output dari Copilot mungkin berisi konten berkualitas rendah atau tidak akurat
Copilot tidak memiliki cara untuk mengevaluasi atau menunjukkan kegunaan atau akurasi outputnya. Dengan demikian, penting bagi pengguna untuk mengevaluasi ini sendiri setiap kali mereka menggunakan Copilot.
Untuk mengurangi risiko atau tantangan dari halusinasi LLM di Copilot, pertimbangkan saran berikut:
Latih pengguna untuk menggunakan Copilot dan alat serupa lainnya yang memanfaatkan LLM. Pertimbangkan untuk melatihnya pada topik berikut:
- Apa yang dapat dan tidak dapat dilakukan oleh Copilot.
- Kapan menggunakan Copilot dan kapan tidak menggunakannya.
- Cara menulis prompt yang lebih baik.
- Cara memecahkan masalah hasil yang tidak terduga.
- Cara memvalidasi output dengan menggunakan sumber, teknik, atau sumber daya online tepercaya.
Uji item dengan Copilot sebelum Anda mengizinkan item ini digunakan dengannya. Item tertentu memerlukan tugas persiapan tertentu untuk memastikan bahwa item tersebut berfungsi dengan baik dengan Copilot.
Hindari menggunakan Copilot dalam proses pengambilan keputusan otonom, berisiko tinggi, atau penting bagi bisnis.
Penting
Selain itu, tinjau ketentuan pratinjau tambahan untuk Fabric, yang mencakup ketentuan penggunaan untuk Pratinjau Layanan AI Microsoft Generative. Meskipun Anda dapat mencoba dan bereksperimen dengan fitur pratinjau ini, kami sarankan Anda tidak menggunakan fitur Copilot dalam pratinjau dalam solusi produksi.
Privasi, keamanan, dan AI yang bertanggung jawab
Microsoft berkomitmen untuk memastikan bahwa sistem AI kami dipandu oleh prinsip AI kami dan Standar AI yang Bertanggung Jawab. Lihat Privasi, keamanan, dan penggunaan Copilot yang bertanggung jawab di Fabric untuk gambaran umum terperinci. Lihat juga Data, privasi, dan keamanan untuk Layanan Azure OpenAI untuk informasi terperinci khusus untuk Azure OpenAI.
Untuk gambaran umum khusus untuk setiap beban kerja Fabric, lihat artikel berikut:
- Penggunaan yang bertanggung jawab di Data Factory
- Penggunaan yang bertanggung jawab dalam Ilmu Data dan Rekayasa Data
- Penggunaan yang bertanggung jawab dalam Pergudangan Data
- Penggunaan yang bertanggung jawab di Power BI
- Penggunaan yang bertanggung jawab dalam Real-Time Intelligence
Biaya Copilot pada sistem Fabric
Tidak seperti Microsoft Copilots lainnya, Copilot di Fabric tidak memerlukan lisensi tambahan per pengguna atau per kapasitas. Sebaliknya, Copilot dalam Fabric menggunakan unit kapasitas Fabric (CUs) Anda yang tersedia. Tingkat konsumsi Copilot ditentukan oleh jumlah token dalam input dan output Anda saat Anda menggunakannya di berbagai pengalaman di Fabric.
Jika Anda memiliki kapasitas Fabric, Anda menggunakan instans bayar sesuai pemakaian atau yang terreservasi. Dalam kedua kasus, konsumsi Copilot berfungsi sama. Dalam skenario bayar sesuai penggunaan, Anda ditagih per detik selama kapasitas Anda aktif hingga Anda menghentikan sementara kapasitas tersebut. Tarif penagihan tidak memiliki hubungan dengan penggunaan CUs Fabric Anda; Anda membayar jumlah yang sama jika kapasitas Anda sepenuhnya digunakan atau sepenuhnya tidak digunakan. Dengan demikian, Copilot tidak memiliki biaya atau dampak langsung pada tagihan Azure Anda. Sebaliknya, Copilot mengonsumsi unit komputasi (CUs) yang tersedia, sebagaimana digunakan oleh beban kerja dan item Fabric lainnya. Jika Anda menggunakan terlalu banyak, pengguna akan mengalami penurunan performa dan pembatasan. Dimungkinkan juga untuk memasuki keadaan utang CU yang disebut carryforward, yang berarti membawa saldo utang ke periode berikutnya. Untuk informasi selengkapnya tentang pembatasan dan carryforward, lihat Pemicu pembatasan dan tahap pembatasan.
Bagian berikut ini menjelaskan secara lebih mendalam tentang cara Anda sebaiknya memahami dan mengelola penggunaan Copilot dalam Fabric.
Nota
Untuk informasi selengkapnya, lihat Copilot pada Fabric Konsumsi.
Penggunaan Copilot dalam Fabric ditentukan oleh token
Copilot mengonsumsi CUs Fabric Anda yang tersedia, juga biasa disebut sebagai kapasitas, komputasi, atau sumber daya. Konsumsi ditentukan oleh token input dan output saat Anda menggunakannya. Untuk meninjau, Anda dapat memahami token input dan output sebagai akibat dari tokenisasi berikut:
- Token masukan: Tokenisasi permintaan tertulis Anda dan data dasar.
- Token output: Tokenisasi respons Azure OpenAI, berdasarkan input. Token output tiga kali lebih mahal daripada token input.
Anda dapat membatasi jumlah token input dengan menggunakan instruksi yang lebih pendek, tetapi Anda tidak dapat mengontrol data landasan yang digunakan oleh Copilot untuk pra-pemrosesan, atau jumlah token output yang dikembalikan oleh LLM di Azure OpenAI. Misalnya, Anda dapat mengharapkan bahwa pengalaman pembuatan laporan untuk Copilot di Power BI akan memiliki tingkat konsumsi yang tinggi, karena mungkin menggunakan data landasan (seperti skema model Anda) dan mungkin menghasilkan output yang panjang (metadata laporan).
Input, output, dan data grounding dikonversi ke token
Untuk mengulangi dari bagian sebelumnya dalam artikel ini, penting untuk memahami proses tokenisasi sehingga Anda tahu jenis input dan output apa yang menghasilkan konsumsi tertinggi.
Mengoptimalkan token prompt kemungkinan tidak akan berpengaruh signifikan pada biaya Copilot Anda. Misalnya, jumlah token dalam perintah pengguna tertulis biasanya jauh lebih kecil daripada token data dan output grounding. Copilot menangani data grounding dan output secara otonom; Anda tidak dapat mengoptimalkan atau memengaruhi token ini. Misalnya, saat menggunakan Copilot di Power BI, Copilot mungkin menggunakan skema dari model semantik Anda atau metadata dari laporan Anda sebagai data dasar selama pra-pemrosesan. Metadata ini kemungkinan terdiri dari lebih banyak token daripada permintaan awal Anda.
Copilot melakukan berbagai pengoptimalan sistem untuk mengurangi token input dan output. Pengoptimalan ini bergantung pada pengalaman Copilot yang Anda gunakan. Contoh pengoptimalan sistem meliputi:
Pengurangan skema: Copilot tidak mengirim seluruh skema model semantik atau tabel lakehouse. Sebagai gantinya, ia menggunakan penyematan untuk menentukan kolom mana yang akan dikirim.
Augmentasi petunjuk: Saat menulis ulang petunjuk selama prapemrosesan, Copilot mencoba menghasilkan petunjuk akhir yang akan mengembalikan hasil yang lebih spesifik.
Selain itu, ada berbagai pengoptimalan pengguna yang dapat Anda terapkan untuk membatasi data dasar apa yang dapat diakses dan digunakan oleh Copilot. Pengoptimalan pengguna ini bergantung pada item dan pengalaman yang Anda gunakan. Beberapa contoh pengoptimalan pengguna meliputi:
Menyembunyikan bidang atau menandai tabel sebagai privat dalam model semantik: Objek tersembunyi atau privat apa pun tidak akan dipertimbangkan oleh Copilot.
Menyembunyikan halaman laporan atau visual: Demikian pula, setiap halaman laporan tersembunyi atau visual yang tersembunyi di balik marka buku laporan juga tidak dipertimbangkan oleh Copilot.
Petunjuk / Saran
Pengoptimalan pengguna terutama efektif untuk meningkatkan kegunaan output Copilot, daripada mengoptimalkan biaya Copilot. Untuk informasi selengkapnya, lihat artikel khusus untuk berbagai beban kerja dan pengalaman Copilot.
Anda tidak memiliki visibilitas pada proses tokenisasi, dan Anda hanya dapat berdampak minimal pada token input dan output. Dengan demikian, cara paling efektif bagi Anda untuk mengelola konsumsi Copilot dan menghindari pembatasan adalah dengan mengelola penggunaan Copilot.
Copilot adalah operasi latar belakang yang dihaluskan
Penggunaan Copilot secara bersamaan dalam Fabric—ketika banyak individu menggunakannya pada saat yang sama—ditangani oleh proses yang disebut smoothing. Dalam Fabric, setiap operasi yang diklasifikasikan sebagai operasi latar belakang memiliki konsumsi CU-nya dibagi selama jendela 24 jam, mulai dari waktu operasi hingga tepat 24 jam kemudian. Ini berbeda dengan operasi interaktif, seperti kueri model semantik dari individu menggunakan laporan Power BI, yang tidak dihaluskan.
Nota
Untuk menyederhanakan pemahaman, latar belakang, dan operasi interaktif Anda mengklasifikasikan berbagai hal yang terjadi di Fabric untuk tujuan penagihan. Mereka tidak selalu terkait dengan apakah suatu item atau fitur interaktif bagi pengguna atau terjadi di latar belakang, seperti yang kesan dari namanya.
Misalnya, jika Anda menggunakan 48 CUs dengan operasi latar belakang sekarang, itu akan menghasilkan 2 CUs penggunaan sekarang, dan juga 2 CUs setiap jam dari sekarang hingga 24 jam ke depan. Jika Anda menggunakan 48 CU dengan operasi interaktif, hal itu menghasilkan penggunaan 48 CU yang teramati sekarang, dan tidak berpengaruh pada konsumsi di masa mendatang. Namun, smoothing juga berarti Anda dapat berpotensi mengakumulasi konsumsi CU di jendela tersebut apabila penggunaan Copilot atau beban kerja Fabric lainnya cukup besar.
Untuk lebih memahami proses smoothing dan dampaknya pada penggunaan Fabric CU Anda, lihatlah diagram berikut:

Diagram menggambarkan contoh skenario dengan penggunaan bersamaan yang tinggi dari operasi interaktif (yang tidak dihaluskan). Operasi interaktif melewati batas pembatasan (kapasitas Fabric yang tersedia) dan memasuki carryforward. Ini adalah skenario tanpa menghaluskan. Sebaliknya, operasi latar belakang seperti Copilot memiliki konsumsi yang tersebar selama 24 jam. Operasi berikutnya dalam jendela 24 jam tersebut akan terakumulasi dan berkontribusi pada total konsumsi kumulatif selama periode tersebut. Dalam skenario yang dihaluskan dari contoh ini, operasi latar belakang seperti Copilot akan berkontribusi pada konsumsi CU di masa mendatang, tetapi tidak memicu pembatasan atau melewati batas apa pun.
Memantau konsumsi Copilot di Fabric
Administrator Fabric dapat memantau seberapa banyak konsumsi Copilot yang terjadi dalam kapasitas Fabric Anda dengan menggunakan aplikasi Metrik Kapasitas Microsoft Fabric. Di aplikasi, administrator Fabric dapat melihat perincian berdasarkan aktivitas dan pengguna, membantu mereka mengidentifikasi individu dan area di mana mereka mungkin perlu fokus selama periode konsumsi tinggi.
Petunjuk / Saran
Daripada mempertimbangkan perhitungan abstrak seperti token ke CUs, kami sarankan Anda fokus pada persentase kapasitas Fabric yang telah Anda gunakan. Metrik ini adalah yang paling sederhana untuk dipahami dan ditindaklanjuti, karena setelah Anda mencapai pemanfaatan 100%, Anda dapat mengalami pembatasan.
Anda dapat menemukan informasi ini di halaman titik waktu aplikasi.
Nota
Ketika Anda menjeda kapasitas, penggunaan yang telah dihaluskan disatukan ke dalam titik waktu di mana kapasitas itu dijeda. Pemadatan konsumsi yang dihaluskan ini menghasilkan puncak konsumsi yang diamati, yang tidak mencerminkan penggunaan aktual Anda. Puncak penggunaan ini akan sering menghasilkan pemberitahuan dan peringatan bahwa Anda telah melebihi kapasitas Fabric yang tersedia, tetapi ini adalah kesalahan positif.
Mengurangi penggunaan dan penghambatan yang tinggi
Copilot mengonsumsi FABRIC CUs, dan bahkan dengan smoothing, Anda mungkin mengalami situasi pemanfaatan tinggi, yang menyebabkan konsumsi tinggi, dan pembatasan beban kerja Fabric Anda yang lain. Bagian berikut membahas beberapa strategi yang dapat Anda gunakan untuk meringankan dampak pada kapasitas Fabric Anda dalam skenario ini.
Pelatihan dan daftar izin pengguna
Cara penting untuk memastikan adopsi yang efektif dari alat apa pun adalah dengan membekali pengguna dengan pendampingan dan pelatihan yang memadai, dan untuk secara bertahap meluncurkan akses saat orang menyelesaikan pelatihan tersebut. Pelatihan yang efektif adalah tindakan pencegahan untuk menghindari penggunaan yang berlebihan dan pembatasan secara proaktif, dengan mendidik pengguna tentang cara menggunakan Copilot secara efektif dan hal-hal yang sebaiknya dihindari.
Anda dapat mengontrol siapa yang dapat menggunakan Copilot di Fabric dengan membuat daftar putih pengguna yang diizinkan mengakses fitur tersebut dari pengaturan penyewa Fabric. Ini berarti Bahwa Anda mengaktifkan Copilot di Fabric hanya untuk pengguna yang termasuk dalam kelompok keamanan tertentu. Jika perlu, Anda dapat membuat grup keamanan terpisah untuk setiap beban kerja Fabric di mana Anda dapat mengaktifkan Copilot untuk mendapatkan kontrol yang lebih terperinci atas siapa yang dapat menggunakan pengalaman Copilot tertentu. Untuk informasi selengkapnya tentang membuat grup keamanan, lihat Membuat, mengedit, atau menghapus grup keamanan.
Setelah menambahkan grup keamanan tertentu ke pengaturan penyewa Copilot, Anda dapat menyusun pelatihan onboarding untuk pengguna. Kursus pelatihan Copilot harus mencakup topik dasar, seperti berikut ini.
Petunjuk / Saran
Pertimbangkan untuk membuat pelatihan gambaran umum untuk konsep dasar tentang LLM dan AI generatif, tetapi kemudian buat pelatihan khusus beban kerja untuk pengguna. Tidak semua individu perlu belajar tentang setiap tugas Fabric jika tidak relevan bagi mereka.
LLM: Jelaskan dasar-dasar apa itu LLM dan cara kerjanya. Anda tidak boleh masuk ke detail teknis, tetapi Anda harus menjelaskan konsep seperti perintah, grounding, dan token. Anda juga dapat menjelaskan bagaimana LLM bisa mendapatkan arti dari input dan menghasilkan respons yang sesuai konteks karena data pelatihan mereka. Mengajarkan ini kepada pengguna membantu mereka memahami cara kerja teknologi dan apa yang dapat dan tidak dapat dilakukan.
Copilot dan alat AI generatif lainnya digunakan untuk: Anda harus menjelaskan bahwa Copilot bukan agen otonom dan tidak dimaksudkan untuk menggantikan manusia dalam tugas mereka, tetapi dimaksudkan untuk menambah individu untuk berpotensi melakukan tugas mereka saat ini dengan lebih baik dan lebih cepat. Anda juga harus menekankan kasus di mana Copilot tidak cocok, menggunakan contoh tertentu, dan menjelaskan alat dan informasi lain apa yang mungkin digunakan individu untuk mengatasi masalah mereka dalam skenario tersebut.
Cara untuk secara kritis menilai output Copilot: Penting bagi Anda untuk memandu pengguna tentang bagaimana mereka dapat memvalidasi output Copilot. Validasi ini tergantung pada pengalaman Copilot yang mereka gunakan, tetapi secara umum, Anda harus menekankan poin-poin berikut:
- Periksa setiap output sebelum Anda menggunakannya.
- Evaluasi dan tanyakan pada diri Anda apakah outputnya benar atau tidak.
- Tambahkan komentar ke kode yang dihasilkan untuk memahami cara kerjanya. Atau, mintalah Copilot untuk penjelasan tentang kode tersebut, jika perlu, dan referensi silang penjelasan dengan sumber tepercaya.
- Jika output menghasilkan hasil yang tidak terduga, pecahkan masalah dengan perintah yang berbeda atau dengan melakukan validasi manual.
Risiko dan batasan LLM dan AI generatif: Anda harus menjelaskan risiko dan batasan utama Copilot, LLM, dan AI generatif, seperti yang disebutkan dalam artikel ini:
- Mereka non-deterministik.
- Mereka tidak memberikan indikasi atau jaminan akurasi, keandalan, atau kebenaran.
- Mereka dapat berhalusinasi dan menghasilkan output yang tidak akurat atau berkualitas rendah.
- Mereka tidak dapat menghasilkan informasi yang melampaui cakupan data pelatihan mereka.
Tempat menemukan Copilot di Fabric: Berikan gambaran tingkat tinggi secara umum tentang berbagai beban kerja, item, dan pengalaman Copilot yang dapat digunakan.
Menskalakan kapasitas Anda
Ketika Anda mengalami pembatasan sumber daya di Fabric karena konsumsi Copilot atau operasi lain, Anda dapat sementara menaikkan skala kapasitas Anda ke SKU yang lebih tinggi. Ini adalah langkah reaktif yang sementara meningkatkan biaya Anda untuk mengurangi masalah jangka pendek karena pembatasan atau pelampauan. Ini sangat membantu ketika Anda mengalami pembatasan terutama karena operasi latar belakang, karena konsumsi (dan dengan demikian dampaknya) mungkin tersebar di jendela 24 jam.
Strategi pembagian kapasitas
Dalam skenario di mana Anda mengharapkan tingkat penggunaan Copilot yang tinggi di Fabric (contohnya di organisasi besar), Anda mungkin dapat mempertimbangkan untuk memisahkan konsumsi Copilot dari beban kerja Fabric lainnya. Dalam skenario kapasitas terpisah ini, Anda mencegah konsumsi Copilot berdampak negatif pada beban kerja Fabric lainnya dengan mengaktifkan Copilot hanya pada F64 terpisah atau SKU yang lebih tinggi, yang hanya Anda gunakan untuk pengalaman Copilot khusus. Strategi kapasitas terpisah ini menghasilkan biaya yang lebih tinggi, tetapi mungkin membuatnya lebih mudah untuk mengelola dan mengatur penggunaan Copilot.
Petunjuk / Saran
Anda dapat menggunakan beberapa pengalaman Copilot dengan item dalam kapasitas lain yang tidak mendukung atau mengaktifkan Copilot. Misalnya, di Power BI Desktop, Anda dapat menghubungkan ke ruang kerja dengan kapasitas SKU Fabric F64, lalu menyambungkan ke model semantik di ruang kerja F2 atau PPU. Kemudian, Anda dapat menggunakan pengalaman Copilot di Power BI Desktop, dan konsumsi Copilot hanya akan memengaruhi SKU F64.
Diagram berikut menggambarkan contoh strategi pembagian kapasitas untuk mengisolasi penggunaan Copilot dengan fitur-fitur serupa seperti yang ada di Copilot dalam Power BI Desktop.

Anda juga dapat menggunakan solusi kapasitas terpisah dengan menetapkan konsumsi Copilot ke kapasitas terpisah. Menetapkan konsumsi Copilot ke kapasitas terpisah memastikan bahwa pemanfaatan Copilot yang tinggi tidak memengaruhi beban kerja Fabric Anda yang lain dan proses penting bisnis yang bergantung padanya. Tentu saja, menggunakan strategi pembagian kapasitas mengharuskan Anda sudah memiliki dua atau lebih SKU F64 atau lebih tinggi. Dengan demikian, strategi ini mungkin tidak dapat dikelola bagi organisasi atau organisasi yang lebih kecil dengan anggaran terbatas untuk dibelanjakan pada platform data mereka.
Terlepas dari bagaimana Anda memilih untuk mengelola Copilot, yang paling penting adalah Anda memantau konsumsi Copilot dalam kapasitas Fabric yang Anda miliki.