Panduan pemulihan bencana khusus pengalaman
Dokumen ini memberikan panduan khusus pengalaman untuk memulihkan data Fabric Anda jika terjadi bencana regional.
Contoh skenario
Sejumlah bagian panduan dalam dokumen ini menggunakan skenario sampel berikut untuk tujuan penjelasan dan ilustrasi. Lihat kembali skenario ini seperlunya.
Katakanlah Anda memiliki kapasitas C1 di wilayah A yang memiliki ruang kerja W1. Jika Anda telah mengaktifkan pemulihan bencana untuk kapasitas C1, data OneLake akan direplikasi ke cadangan di wilayah B. Jika wilayah A menghadapi gangguan, layanan Fabric di C1 gagal ke wilayah B.
Gambar berikut menggambarkan skenario ini. Kotak di sebelah kiri memperlihatkan wilayah yang terganggu. Kotak di tengah mewakili ketersediaan data yang berkelanjutan setelah failover, dan kotak di sebelah kanan menunjukkan situasi yang sepenuhnya tercakup setelah pelanggan bertindak untuk memulihkan layanan mereka ke fungsi penuh.
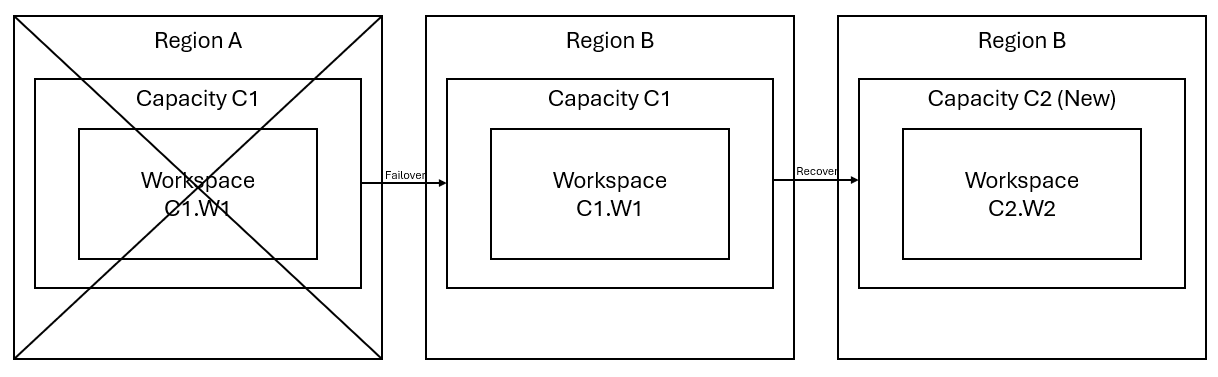
Berikut adalah rencana pemulihan umum:
Buat C2 kapasitas Fabric baru di wilayah baru.
Buat ruang kerja W2 baru di C2, termasuk item terkait dengan nama yang sama seperti di C1. W1.
Salin data dari C1 yang terganggu. W1 ke C2. W2.
Ikuti instruksi khusus untuk setiap komponen untuk memulihkan item ke fungsi penuhnya.
Rencana pemulihan khusus pengalaman
Bagian berikut menyediakan panduan langkah demi langkah untuk setiap pengalaman Fabric untuk membantu pelanggan melalui proses pemulihan.
Rekayasa Data
Panduan ini memandu Anda melalui prosedur pemulihan untuk pengalaman Rekayasa Data. Ini mencakup definisi pekerjaan lakehouse, notebook, dan Spark.
Lakehouse
Lakehouse dari wilayah asli tetap tidak tersedia untuk pelanggan. Untuk memulihkan lakehouse, pelanggan dapat membuatnya kembali di ruang kerja C2. W2. Kami merekomendasikan dua pendekatan untuk memulihkan lakehouse:
Pendekatan 1: Menggunakan skrip kustom untuk menyalin tabel dan file Lakehouse Delta
Pelanggan dapat membuat ulang lakehouse dengan menggunakan skrip Scala kustom.
Buat lakehouse (misalnya, LH1) di ruang kerja C2 yang baru dibuat. W2.
Buat buku catatan baru di ruang kerja C2. W2.
Untuk memulihkan tabel dan file dari lakehouse asli, lihat data dengan jalur OneLake seperti abfss (lihat Menyambungkan ke Microsoft OneLake). Anda dapat menggunakan contoh kode di bawah ini (lihat Pengenalan Utilitas Microsoft Spark) di buku catatan untuk mendapatkan jalur ABFS file dan tabel dari lakehouse asli. (Ganti C1. W1 dengan nama ruang kerja aktual)
mssparkutils.fs.ls('abfs[s]://<C1.W1>@onelake.dfs.fabric.microsoft.com/<item>.<itemtype>/<Tables>/<fileName>')Gunakan contoh kode berikut untuk menyalin tabel dan file ke lakehouse yang baru dibuat.
Untuk tabel Delta, Anda perlu menyalin tabel satu per satu untuk pulih di lakehouse baru. Dalam kasus file Lakehouse, Anda dapat menyalin struktur file lengkap dengan semua folder yang mendasar dengan satu eksekusi.
Hubungi tim dukungan untuk tanda waktu failover yang diperlukan dalam skrip.
%%spark val source="abfs path to original Lakehouse file or table directory" val destination="abfs path to new Lakehouse file or table directory" val timestamp= //timestamp provided by Support mssparkutils.fs.cp(source, destination, true) val filesToDelete = mssparkutils.fs.ls(s"$source/_delta_log") .filter{sf => sf.isFile && sf.modifyTime > timestamp} for(fileToDelte <- filesToDelete) { val destFileToDelete = s"$destination/_delta_log/${fileToDelte.name}" println(s"Deleting file $destFileToDelete") mssparkutils.fs.rm(destFileToDelete, false) } mssparkutils.fs.write(s"$destination/_delta_log/_last_checkpoint", "", true)Setelah Anda menjalankan skrip, tabel akan muncul di lakehouse baru.
Pendekatan 2: Gunakan Azure Storage Explorer untuk menyalin file dan tabel
Untuk memulihkan hanya file atau tabel Lakehouse tertentu dari lakehouse asli, gunakan Azure Storage Explorer. Lihat Mengintegrasikan OneLake dengan Azure Storage Explorer untuk langkah-langkah terperinci. Untuk ukuran data besar, gunakan Pendekatan 1.
Catatan
Dua pendekatan yang dijelaskan di atas memulihkan metadata dan data untuk tabel berformat Delta, karena metadata terletak bersama dan disimpan dengan data di OneLake. Untuk tabel berformat non-Delta (e.g. CSV, Parquet, dll.) yang dibuat menggunakan skrip/perintah Spark Data Definition Language (DDL), pengguna bertanggung jawab untuk memelihara dan menjalankan kembali skrip/perintah Spark DDL untuk memulihkannya.
Notebook
Notebook dari wilayah utama tetap tidak tersedia untuk pelanggan dan kode di notebook tidak akan direplikasi ke wilayah sekunder. Untuk memulihkan kode Notebook di wilayah baru, ada dua pendekatan untuk memulihkan konten kode Notebook.
Pendekatan 1: Redundansi yang dikelola pengguna dengan integrasi Git (dalam pratinjau publik)
Cara terbaik untuk membuatnya mudah dan cepat adalah dengan menggunakan integrasi Fabric Git, lalu menyinkronkan notebook Anda dengan repositori ADO Anda. Setelah layanan gagal ke wilayah lain, Anda bisa menggunakan repositori untuk membangun kembali buku catatan di ruang kerja baru yang Anda buat.
Konfigurasikan Integrasi Git untuk ruang kerja Anda dan pilih Sambungkan dan sinkronkan dengan repositori ADO.

Gambar berikut ini memperlihatkan buku catatan yang disinkronkan.

Pulihkan buku catatan dari repositori ADO.
Di ruang kerja yang baru dibuat, sambungkan ke repositori Azure ADO Anda lagi.

Pilih tombol Kontrol sumber. Kemudian pilih cabang repositori yang relevan. Lalu pilih Perbarui semua. Buku catatan asli akan muncul.


Jika buku catatan asli memiliki lakehouse default, pengguna dapat merujuk ke bagian Lakehouse untuk memulihkan lakehouse dan kemudian menghubungkan lakehouse yang baru dipulihkan ke notebook yang baru dipulihkan.

Integrasi Git tidak mendukung sinkronisasi file, folder, atau rekam jepret notebook di penjelajah sumber daya notebook.
Jika buku catatan asli memiliki file di penjelajah sumber daya notebook:
Pastikan untuk menyimpan file atau folder ke disk lokal atau ke tempat lain.
Unggah ulang file dari disk lokal atau drive cloud Anda ke notebook yang dipulihkan.
Jika buku catatan asli memiliki rekam jepret notebook, simpan juga rekam jepret buku catatan ke sistem kontrol versi atau disk lokal Anda sendiri.


Untuk informasi selengkapnya tentang integrasi Git, lihat Pengantar integrasi Git.
Pendekatan 2: Pendekatan manual untuk mencadangkan konten kode
Jika Anda tidak mengambil pendekatan integrasi Git, Anda dapat menyimpan versi terbaru kode, file di penjelajah sumber daya, dan rekam jepret notebook dalam sistem kontrol versi seperti Git, dan memulihkan konten buku catatan secara manual setelah bencana:
Gunakan fitur "Impor buku catatan" untuk mengimpor kode buku catatan yang ingin Anda pulihkan.

Setelah mengimpor, buka ruang kerja yang Anda inginkan (misalnya, "C2. W2") untuk mengaksesnya.
Jika buku catatan asli memiliki lakehouse default, lihat bagian Lakehouse. Kemudian sambungkan lakehouse yang baru dipulihkan (yang memiliki konten yang sama dengan lakehouse default asli) ke notebook yang baru dipulihkan.
Jika buku catatan asli memiliki file atau folder di penjelajah sumber daya, unggah ulang file atau folder yang disimpan dalam sistem kontrol versi pengguna.
Definisi Pekerjaan Spark
Definisi kerja Spark (SJD) dari wilayah utama tetap tidak tersedia untuk pelanggan, dan file definisi utama dan file referensi dalam buku catatan akan direplikasi ke wilayah sekunder melalui OneLake. Jika Anda ingin memulihkan SJD di wilayah baru, Anda dapat mengikuti langkah-langkah manual yang dijelaskan di bawah ini untuk memulihkan SJD. Perhatikan bahwa eksekusi historis SJD tidak akan dipulihkan.
Anda dapat memulihkan item SJD dengan menyalin kode dari wilayah asli dengan menggunakan Azure Storage Explorer dan menyambungkan kembali referensi Lakehouse secara manual setelah bencana.
Buat item SJD baru (misalnya, SJD1) di ruang kerja baru C2. W2, dengan pengaturan dan konfigurasi yang sama dengan item SJD asli (misalnya, bahasa, lingkungan, dll.).
Gunakan Azure Storage Explorer untuk menyalin Libs, Mains, dan Snapshot dari item SJD asli ke item SJD baru.

Konten kode akan muncul di SJD yang baru dibuat. Anda harus menambahkan referensi Lakehouse yang baru dipulihkan secara manual ke pekerjaan (Lihat langkah-langkah pemulihan Lakehouse). Pengguna harus memasukkan kembali argumen baris perintah asli secara manual.

Sekarang Anda dapat menjalankan atau menjadwalkan SJD yang baru dipulihkan.
Untuk detail tentang Azure Storage Explorer, lihat Mengintegrasikan OneLake dengan Azure Storage Explorer.
Ilmu data
Panduan ini memandu Anda melalui prosedur pemulihan untuk pengalaman Ilmu Data. Ini mencakup model dan eksperimen ML.
Model dan Eksperimen ML
Ilmu Data item dari wilayah utama tetap tidak tersedia untuk pelanggan, dan konten dan metadata dalam model dan eksperimen ML tidak akan direplikasi ke wilayah sekunder. Untuk memulihkannya sepenuhnya di wilayah baru, simpan konten kode dalam sistem kontrol versi (seperti Git), dan jalankan ulang konten kode secara manual setelah bencana.
Pulihkan buku catatan. Lihat langkah-langkah pemulihan Notebook.
Konfigurasi, metrik yang dijalankan secara historis, dan metadata tidak akan direplikasi ke wilayah yang dipasangkan. Anda harus menjalankan ulang setiap versi kode ilmu data Anda untuk sepenuhnya memulihkan model dan eksperimen ML setelah bencana.
Gudang Data
Panduan ini memandu Anda melalui prosedur pemulihan untuk pengalaman Gudang Data. Ini mencakup gudang.
Gudang
Gudang dari wilayah asli tetap tidak tersedia untuk pelanggan. Untuk memulihkan gudang, gunakan dua langkah berikut.
Buat lakehouse sementara baru di ruang kerja C2. W2 untuk data yang akan Anda salin dari gudang asli.
Isi tabel Delta gudang dengan memanfaatkan penjelajah gudang dan kemampuan T-SQL (lihat Tabel di pergudangan data di Microsoft Fabric).
Catatan
Disarankan agar Anda menyimpan kode Gudang Anda (skema, tabel, tampilan, prosedur tersimpan, definisi fungsi, dan kode keamanan) versi dan disimpan di lokasi yang aman (seperti Git) sesuai dengan praktik pengembangan Anda.
Penyerapan data melalui kode Lakehouse dan T-SQL
Di ruang kerja C2 yang baru dibuat. W2:
Buat "LH2" lakehouse sementara di C2. W2.
Pulihkan tabel Delta di lakehouse sementara dari gudang asli dengan mengikuti langkah-langkah pemulihan Lakehouse.
Buat gudang baru "WH2" di C2. W2.
Hubungkan lakehouse sementara di penjelajah gudang Anda.
Bergantung pada bagaimana Anda akan menyebarkan definisi tabel sebelum impor data, T-SQL aktual yang digunakan untuk impor dapat bervariasi. Anda dapat menggunakan pendekatan INSERT INTO, SELECT INTO, atau CREATE TABLE AS SELECT untuk memulihkan tabel Gudang dari lakehouse. Selanjutnya dalam contoh, kita akan menggunakan rasa INSERT INTO. (Jika Anda menggunakan kode di bawah ini, ganti sampel dengan nama tabel dan kolom yang sebenarnya)
USE WH1 INSERT INTO [dbo].[aggregate_sale_by_date_city]([Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit]) SELECT [Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit] FROM [LH11].[dbo].[aggregate_sale_by_date_city] GOTerakhir, ubah string koneksi dalam aplikasi menggunakan gudang Fabric Anda.
Catatan
Untuk pelanggan yang membutuhkan pemulihan bencana lintas regional dan kelangsungan bisnis yang sepenuhnya otomatis, kami sarankan untuk menyimpan dua pengaturan Fabric Warehouse di wilayah Fabric terpisah dan mempertahankan paritas kode dan data dengan melakukan penyebaran reguler dan penyerapan data ke kedua situs.
Database cermin
Database cermin dari wilayah utama tetap tidak tersedia untuk pelanggan dan pengaturan tidak direplikasi ke wilayah sekunder. Untuk memulihkannya jika terjadi kegagalan regional, Anda perlu membuat ulang database cermin Anda di ruang kerja lain dari wilayah lain.
Data Factory
Item Data Factory dari wilayah utama tetap tidak tersedia untuk pelanggan dan pengaturan dan konfigurasi dalam alur data atau item aliran data gen2 tidak akan direplikasi ke wilayah sekunder. Untuk memulihkan item ini jika terjadi kegagalan regional, Anda harus membuat ulang item Integrasi Data di ruang kerja lain dari wilayah lain. Bagian berikut menguraikan detailnya.
Aliran Data Gen2
Jika Anda ingin memulihkan item Dataflow Gen2 di wilayah baru, Anda perlu mengekspor file PQT ke sistem kontrol versi seperti Git lalu memulihkan konten Dataflow Gen2 secara manual setelah bencana.
Dari item Dataflow Gen2 Anda, di tab Beranda editor Power Query, pilih Ekspor templat.

Dalam dialog Ekspor templat, masukkan nama (wajib) dan deskripsi (opsional) untuk templat ini. Setelah selesai, pilih OK.

Setelah bencana, buat item Dataflow Gen2 baru di ruang kerja baru "C2. W2".
Dari panel tampilan saat ini dari editor Power Query, pilih Impor dari templat Power Query.

Dalam dialog Buka, telusuri folder unduhan default Anda dan pilih file .pqt yang Anda simpan di langkah-langkah sebelumnya. Lalu pilih Buka.
Templat kemudian diimpor ke item Dataflow Gen2 baru Anda.
Alur Data
Pelanggan tidak dapat mengakses alur data jika terjadi bencana regional, dan konfigurasi tidak direplikasi ke wilayah yang dipasangkan. Sebaiknya bangun alur data penting Anda di beberapa ruang kerja di berbagai wilayah.
Menyalin Tugas
Pengguna CopyJob harus melakukan tindakan proaktif untuk melindungi dari bencana regional. Pendekatan berikut memastikan bahwa, setelah bencana regional, CopyJobs milik pengguna tetap tersedia.
Redundansi yang dikelola pengguna dengan integrasi Git (dalam pratinjau publik)
Cara terbaik untuk membuat proses ini mudah dan cepat adalah dengan menggunakan integrasi Fabric Git, lalu menyinkronkan CopyJob Anda dengan repositori ADO Anda. Setelah layanan beralih ke wilayah lain, Anda dapat menggunakan repositori untuk merekonstruksi CopyJob di ruang kerja baru yang Anda buat.
Konfigurasikan Integrasi Git ruang kerja Anda dan pilih menyambungkan dan menyinkronkan dengan repositori ADO.

Gambar berikut menunjukkan CopyJob yang disinkronkan.

Pulihkan CopyJob dari repositori ADO.
Di ruang kerja yang baru dibuat, sambungkan dan sinkronkan ke repositori Azure ADO Anda lagi. Semua item Fabric di repositori ini secara otomatis diunduh ke Ruang Kerja baru Anda.
Jika CopyJob asli menggunakan Lakehouse, pengguna dapat mengacu pada bagian Lakehouse untuk memulihkan Lakehouse, lalu menghubungkan CopyJob yang baru dipulihkan ke Lakehouse yang baru dipulihkan.
Untuk informasi selengkapnya tentang integrasi Git, lihat Pengantar integrasi Git.
Kecerdasan Real Time
Panduan ini memandu Anda melalui prosedur pemulihan untuk pengalaman Kecerdasan Real-Time. Ini mencakup database/set kueri KQL dan eventstream.
KQL Database/Queryset
Pengguna database/set kueri KQL harus melakukan langkah-langkah proaktif untuk melindungi dari bencana regional. Pendekatan berikut memastikan bahwa, jika terjadi bencana regional, data dalam kumpulan kueri database KQL Anda tetap aman dan dapat diakses.
Gunakan langkah-langkah berikut untuk menjamin solusi pemulihan bencana yang efektif untuk database dan set kueri KQL.
Membuat database KQL independen: Mengonfigurasi dua atau beberapa database/set kueri KQL independen pada kapasitas Fabric khusus. Ini harus disiapkan di dua wilayah Azure yang berbeda (sebaiknya wilayah yang dipasangkan Azure) untuk memaksimalkan ketahanan.
Mereplikasi aktivitas manajemen: Tindakan manajemen apa pun yang diambil dalam satu database KQL harus dicerminkan di database lainnya. Ini memastikan bahwa kedua database tetap sinkron. Aktivitas utama untuk direplikasi meliputi:
Tabel: Pastikan struktur tabel dan definisi skema konsisten di seluruh database.
Pemetaan: Duplikat pemetaan yang diperlukan. Pastikan sumber data dan tujuan selaras dengan benar.
Kebijakan: Pastikan kedua database memiliki retensi data, akses, dan kebijakan relevan lainnya yang serupa.
Mengelola autentikasi dan otorisasi: Untuk setiap replika, siapkan izin yang diperlukan. Pastikan bahwa tingkat otorisasi yang tepat ditetapkan, memberikan akses ke personel yang diperlukan sambil mempertahankan standar keamanan.
Penyerapan data paralel: Untuk menjaga data tetap konsisten dan siap di beberapa wilayah, muat himpunan data yang sama ke setiap database KQL secara bersamaan saat Anda menyerapnya.
Eventstream
Eventstream adalah tempat terpusat di platform Fabric untuk menangkap, mengubah, dan merutekan peristiwa real-time ke berbagai tujuan (misalnya, lakehouse, database KQL/set kueri) dengan pengalaman tanpa kode. Selama tujuan didukung oleh pemulihan bencana, eventstream tidak akan kehilangan data. Oleh karena itu, pelanggan harus menggunakan kemampuan pemulihan bencana dari sistem tujuan tersebut untuk menjamin ketersediaan data.
Pelanggan juga dapat mencapai geo-redundansi dengan menyebarkan beban kerja Eventstream yang identik di beberapa wilayah Azure sebagai bagian dari strategi aktif/aktif multi-situs. Dengan pendekatan aktif/aktif multi-situs, pelanggan dapat mengakses beban kerja mereka di salah satu wilayah yang disebarkan. Pendekatan ini adalah pendekatan paling kompleks dan mahal untuk pemulihan bencana, tetapi dapat mengurangi waktu pemulihan mendekati nol dalam sebagian besar situasi. Untuk sepenuhnya geo-redundan, pelanggan dapat
Buat replika sumber data mereka di berbagai wilayah.
Buat item Eventstream di wilayah terkait.
Sambungkan item baru ini ke sumber data yang identik.
Tambahkan tujuan yang identik untuk setiap eventstream di wilayah yang berbeda.