Peritel dan merek konsumen berfokus untuk memastikan mereka memiliki produk dan layanan yang tepat yang ingin dibeli konsumen dalam marketplace. Ketika melihat memaksimalkan penjualan, produk (atau kombinasi produk) adalah bagian utama dari pengalaman belanja. Ketersediaan penawaran—inventori—menjadi perhatian konstan bagi merek konsumen.
Persediaan produk, juga dikenal sebagai berbagai SKU, adalah masalah kompleks yang mencakup rantai nilai pasokan dan logistik. Untuk artikel ini, kami berfokus khusus pada masalah mengoptimalkan berbagai SKU untuk memaksimalkan pendapatan dari sudut pandang barang konsumen
Teka-teki pengoptimalan berbagai SKU dapat diselesaikan dengan mengembangkan algoritma untuk menjawab pertanyaan-pertanyaan berikut:
- SKU mana yang berkinerja terbaik di pasar atau toko tertentu?
- SKU mana yang harus dialokasikan ke pasar atau toko tertentu berdasarkan performanya?
- SKU mana yang berkinerja rendah dan harus digantikan oleh SKU berkinerja lebih tinggi?
- Wawasan lain apa yang dapat kita peroleh tentang segmen konsumen dan pasar kita?
Mengotomatiskan pengambilan keputusan
Secara tradisional, merek konsumen mendekati masalah permintaan konsumen dengan meningkatkan jumlah SKU dalam portofolio SKU. Ketika jumlah SKU balon dan persaingan meningkat, diperkirakan bahwa 90 persen pendapatan hanya dikaitkan dengan 10 persen SKU produk dalam portofolio. Biasanya, 80 persen pendapatan bertambah dari 20 persen SKU. Dan rasio ini adalah kandidat untuk meningkatkan profitabilitas.
Metode tradisional pelaporan statis menggunakan data historis, yang membatasi wawasan. Yang terbaik, keputusan masih dibuat dan diimplementasikan secara manual. Ini berarti intervensi manusia dan waktu pemrosesan. Dengan kemajuan AI dan komputasi cloud, dimungkinkan untuk menggunakan analitik tingkat lanjut untuk memberikan berbagai pilihan dan prediksi. Otomatisasi semacam ini meningkatkan hasil dan kecepatan-ke-pelanggan.
Pengoptimalan bermata SKU
Solusi bermakna SKU harus menangani jutaan SKU dengan mengesegmentasi data penjualan menjadi perbandingan yang bermakna dan terperinci. Tujuan dari solusi ini adalah untuk menggunakan analitik tingkat lanjut untuk memaksimalkan penjualan di setiap outlet atau toko dengan menyetel berbagai produk. Tujuan kedua adalah untuk menghilangkan saham dan meningkatkan berbagai macam. Tujuan fiskal adalah peningkatan penjualan 5 hingga sepuluh persen. Untuk itu, wawasan memungkinkan satu untuk:
- Memahami performa portofolio SKU dan mengelola performa rendah.
- Optimalkan distribusi SKU untuk mengurangi kehabisan stok.
- Pahami bagaimana SKU baru mendukung strategi jangka pendek dan jangka panjang.
- Buat wawasan yang dapat diulang, dapat diskalakan, dan dapat ditindakkan dari data yang ada.
Analitik deskriptif
Model deskriptif menggabungkan titik data dan mengeksplorasi hubungan di antara faktor-faktor yang dapat memengaruhi penjualan produk. Informasi dapat ditambah dengan beberapa titik data eksternal, seperti lokasi, cuaca, dan data sensus. Visualisasi membantu orang memperoleh wawasan dengan menginterpretasikan data. Namun, dalam melakukannya, pemahaman terbatas pada apa yang terjadi selama siklus penjualan sebelumnya, atau mungkin apa yang terjadi di yang saat ini (tergantung pada seberapa sering data di-refresh).
Pendekatan pergudangan dan pelaporan data tradisional cukup dalam hal ini untuk dipahami, misalnya, SKU apa yang telah menjadi performer terbaik dan terburuk selama jangka waktu tertentu.
Gambar berikut menunjukkan laporan khas data penjualan historis. Ini fitur beberapa blok dengan kotak centang untuk memilih kriteria untuk memfilter hasilnya. Pusat memperlihatkan dua bagan batang yang memperlihatkan penjualan dari waktu ke waktu. Bagan pertama menunjukkan penjualan rata-rata menurut minggu. Yang kedua menunjukkan jumlah menurut minggu.

Analitik prediktif
Pelaporan historis membantu dalam memahami apa yang terjadi. Pada akhirnya, kita ingin ramalan tentang apa yang mungkin terjadi. Informasi sebelumnya dapat berguna untuk tujuan tersebut. Misalnya, kita dapat mengidentifikasi tren musiman. Tetapi tidak dapat membantu dengan skenario bagaimana-jika, misalnya, untuk memodelkan pengenalan produk baru. Untuk melakukan itu, kita harus mengalihkan fokus kita untuk memodelkan perilaku pelanggan, karena itulah faktor utama yang menentukan penjualan.
Melihat secara mendalam masalah: model pilihan
Mari kita mulai dengan menentukan apa yang kita cari dan data apa yang kita miliki:
Pengoptimalan bermacam-macam berarti menemukan subset produk untuk menjual yang memaksimalkan pendapatan yang diharapkan. Inilah yang kita cari.
Data transaksi secara rutin dikumpulkan untuk tujuan keuangan.
Data bermakna dapat mencakup apa pun yang berkaitan dengan SKU: Berikut adalah contoh apa yang kita inginkan:
- Jumlah SKU
- Deskripsi SKU
- Kuantitas yang dialokasikan
- SKU dan kuantitas yang dibeli
- Stempel waktu peristiwa (misalnya, pembelian)
- Harga SKU
- Harga SKU di POS
- Tingkat stok setiap SKU kapan saja
Sayangnya, data tersebut tidak dikumpulkan dengan andal seperti data transaksi.
Dalam artikel ini, untuk kesederhanaan, kami hanya akan mempertimbangkan data transaksi dan data SKU, bukan faktor eksternal.
Meskipun demikian, perhatikan bahwa, mengingat satu set produk n, ada 2n kemungkinan berbagai macam. Ini membuat masalah pengoptimalan menjadi proses intensif komputasi. Mengevaluasi semua kemungkinan kombinasi tidak praktis dengan sejumlah besar produk. Jadi, biasanya, berbagai macam disegmentasi berdasarkan kategori (misalnya, sereal), lokasi, dan kriteria lainnya untuk mengurangi jumlah variabel. Model pengoptimalan mencoba memangkas jumlah permutasi ke subset yang dapat digunakan.
Crux masalah bersandar dalam memodelkan perilaku konsumen secara efektif. Dalam dunia yang sempurna, produk yang disajikan kepada mereka akan cocok dengan yang ingin mereka beli.
Model matematika untuk memprediksi pilihan konsumen telah dikembangkan selama beberapa dekade. Pilihan model pada akhirnya akan menentukan teknologi implementasi yang paling cocok. Oleh karena itu, kami akan meringkasnya dan menawarkan beberapa pertimbangan.
Model parametrik
Model parametrik memperhitungkan perilaku pelanggan dengan menggunakan fungsi dengan sekumpulan parameter terbatas. Kami memperkirakan sekumpulan parameter agar paling sesuai dengan data yang kami inginkan. Salah satu yang paling tua dan paling dikenal adalah Regresi Logistik Multinomial (juga dikenal sebagai MNL, logit multi-kelas, atau regresi softmax). Ini digunakan untuk menghitung probabilitas beberapa kemungkinan hasil dalam masalah klasifikasi. Dalam hal ini, Anda dapat menggunakan MNL untuk menghitung:
Probabilitas bahwa konsumen (c) memilih item (i) pada waktu tertentu (t), mengingat serangkaian item kategori tersebut dalam berbagai (a) dengan utilitas yang diketahui kepada pelanggan (v).
Kami juga berasumsi bahwa utilitas item dapat menjadi fungsi dari fitur-fiturnya. Informasi eksternal juga dapat disertakan dalam ukuran utilitas (misalnya, payung lebih berguna saat hujan).
Kami sering menggunakan MNL sebagai tolok ukur untuk model lain karena traktabilitasnya saat memperkirakan parameter dan saat mengevaluasi hasil. Dengan kata lain, jika Anda melakukan yang lebih buruk dari MNL, algoritma Anda tidak berguna.
Beberapa model telah berasal dari MNL, tetapi berada di luar cakupan makalah ini untuk mendiskusikannya.
Ada pustaka untuk bahasa pemrograman R dan Python. Untuk R, Anda dapat menggunakan glm (dan turunan). Untuk Python, ada scikit-learn, biogeme, dan larch. Pustaka ini menawarkan alat untuk menentukan masalah MNL, dan pemecah paralel untuk menemukan solusi pada berbagai platform.
Baru-baru ini, implementasi model MNL pada GPU telah diusulkan untuk menghitung model kompleks dengan sejumlah parameter yang akan membuatnya tidak dapat dilacak jika tidak.
Jaringan neural dengan lapisan output softmax telah digunakan secara efektif pada masalah multi-kelas besar. Jaringan ini menghasilkan vektor output yang mewakili distribusi probabilitas atas sejumlah hasil yang berbeda. Mereka lambat dilatih dibandingkan dengan implementasi lain, tetapi dapat menangani sejumlah besar kelas dan parameter.
Model non-parametrik
Terlepas dari popularitasnya, MNL menempatkan beberapa asumsi signifikan pada perilaku manusia yang dapat membatasi kegunaannya. Secara khusus, ia mengasumsikan bahwa probabilitas relatif seseorang yang memilih antara dua opsi tidak bergantung pada alternatif tambahan yang diperkenalkan dalam set nanti. Itu tidak praktis dalam banyak kasus.
Misalnya, jika Anda menyukai produk A dan produk B secara merata, Anda akan memilih satu dari 50% waktu lainnya. Mari kita perkenalkan produk C ke campuran. Anda masih dapat memilih produk A 50% dari waktu, tetapi sekarang Anda membagi preferensi Anda 25% untuk produk B dan 25% ke produk C. Probabilitas relatif telah berubah.
Selain itu, MNL dan turunan tidak memiliki cara sederhana untuk memperhitungkan substitusi yang disebabkan oleh variasi stock-out atau bermacam-macam (yaitu, ketika Anda tidak memiliki ide yang jelas dan memilih item acak di antara mereka yang ada di rak).
Model non-parametrik dirancang untuk memperhitungkan penggantian dan memberlakukan lebih sedikit batasan pada perilaku pelanggan.
Mereka memperkenalkan konsep peringkat, di mana konsumen mengekspresikan preferensi ketat untuk produk dalam berbagai macam. Oleh karena itu, perilaku pembelian mereka dapat dimodelkan dengan mengurutkan produk dalam urutan preferensi turun.
Masalah pengoptimalan bermasalah dapat dinyatakan sebagai maksimalisasi pendapatan:
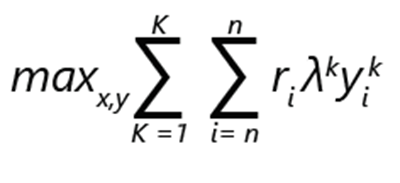
- ri menunjukkan pendapatan produk i.
- yik adalah 1 jika produk i dipilih dalam peringkat k. Jika tidak, itu adalah 0.
- λk adalah probabilitas bahwa pelanggan membuat pilihan sesuai dengan peringkat k.
- xi adalah 1, jika produk termasuk dalam bermata. Jika tidak, itu adalah 0.
- K adalah jumlah peringkat.
- n adalah jumlah produk.
Catatan
Tunduk pada batasan:
- Mungkin ada tepat 1 pilihan untuk setiap peringkat.
- Di bawah peringkat k, produk yang dapat saya pilih hanya jika itu adalah bagian dari berbagai.
- Jika produk i disertakan dalam berbagai macam, tidak ada opsi yang kurang disukai dalam peringkat k yang dapat dipilih.
- Tidak ada pembelian adalah opsi, dan karena itu tidak ada opsi yang kurang lebih disukai dalam peringkat yang dapat dipilih.
Dalam rumusan seperti itu, masalah dapat dianggap sebagai pengoptimalan bilangan bulat campuran.
Mari kita pertimbangkan bahwa jika ada n produk, jumlah maksimum peringkat yang mungkin, termasuk opsi tanpa pilihan, bersifat faktorial: (n+1)!
Batasan dalam rumusan memungkinkan pemangkasan opsi yang relatif efisien. Misalnya, hanya opsi yang paling disukai yang dipilih dan diatur ke 1. Sisanya diatur ke 0. Anda dapat membayangkan bahwa skalabilitas implementasi akan penting, mengingat jumlah alternatif yang mungkin.
Pentingnya data
Kami menyebutkan sebelum data penjualan tersebut tersedia. Kami ingin menggunakannya untuk menginformasikan model pengoptimalan bermasalah kami. Secara khusus, kita ingin menemukan probabilitas distribusi λ.
Data penjualan dari sistem titik penjualan terdiri dari transaksi yang memiliki stempel waktu dan serangkaian produk yang ditunjukkan kepada pelanggan pada waktu dan lokasi tersebut. Dari mereka, kita dapat membangun vektor penjualan aktual, yang elemen vi,m mewakili probabilitas menjual item i kepada pelanggan yang diberikan berbagai macam Sm
Kita juga dapat membuat matriks:
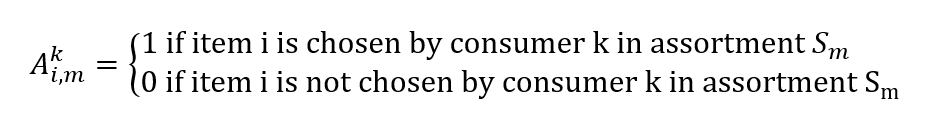
Menemukan distribusi probabilitas kami λ mengingat data penjualan kami menjadi masalah pengoptimalan lain. Kami ingin menemukan vektor λ untuk meminimalkan kesalahan perkiraan penjualan kami:
minλ |Λλ - v|
Perhatikan bahwa komputasi juga dapat dinyatakan sebagai regresi dan, dengan demikian, model seperti pohon keputusan multi-variat dapat digunakan.
Detail implementasi
Seperti yang dapat kita simpulkan dari formulasi sebelumnya, model pengoptimalan berbasis data dan komputasi intensif.
Mitra Microsoft, seperti Neal Analytics, telah mengembangkan arsitektur yang kuat untuk memenuhi kondisi tersebut. Lihat SKU Max. Kami akan menggunakan arsitektur tersebut sebagai contoh dan menawarkan beberapa pertimbangan.
- Pertama, mereka mengandalkan alur data yang kuat dan dapat diskalakan untuk memberi makan model dan pada infrastruktur eksekusi yang kuat dan dapat diskalakan untuk menjalankannya.
- Kedua, hasilnya mudah dikonsumsi oleh perencana melalui dasbor.
Gambar 2 menunjukkan contoh arsitektur. Ini termasuk empat blok utama: tangkapan, proses, model, dan operasionalisasi. Setiap blok berisi proses utama. Pengambilan mencakup pra-pemrosesan data; proses mencakup fungsi data penyimpanan; model mencakup fungsi melatih model pembelajaran mesin; dan operasionalisasi mencakup opsi penyimpanan data dan pelaporan (seperti dasbor).

Gambar 2: Arsitektur untuk pengoptimalan SKU, berdasarkan Neal Analytics
Alur data
Arsitektur ini menyoroti pentingnya membangun alur data untuk pelatihan dan operasi model. Kami mengatur aktivitas dalam alur dengan menggunakan Azure Data Factory, layanan ekstrak, transformasi, dan pemuatan terkelola (ETL) yang memungkinkan Anda merancang dan menjalankan alur kerja integrasi Anda.
Azure Data Factory adalah layanan terkelola dengan komponen yang disebut aktivitas yang menggunakan dan/atau menghasilkan himpunan data.
Aktivitas dapat dibagi menjadi:
- Pergerakan data (misalnya, menyalin dari sumber ke tujuan)
- Transformasi data (misalnya, menggabungkan dengan kueri SQL, atau menjalankan prosedur tersimpan)
Alur kerja yang menautkan kumpulan aktivitas dapat dijadwalkan, dipantau, dan dikelola oleh layanan pabrik data. Alur kerja lengkap disebut alur.
Dalam fase pengambilan, kita dapat menggunakan aktivitas penyalinan Data Factory untuk mentransfer data dari berbagai sumber (baik lokal maupun di cloud) ke Gudang Data Azure SQL. Contoh cara melakukannya disediakan dalam dokumentasi:
Gambar berikut menunjukkan definisi alur. Ini terdiri dari tiga blok berukuran sama berturut-turut. Dua yang pertama adalah himpunan data dan aktivitas yang disambungkan oleh panah untuk menunjukkan aliran data. Yang ketiga diberi label Alur dan menunjuk ke dua yang pertama untuk menunjukkan enkapulasi.

Gambar 3: Konsep dasar Azure Data Factory
Contoh format data yang digunakan oleh solusi Neal Analytics dapat ditemukan di halaman marketplace komersial Microsoft. Solusinya mencakup himpunan data berikut:
- Data riwayat penjualan untuk setiap kombinasi penyimpanan dan SKU
- Menyimpan dan catatan konsumen
- Kode dan deskripsi SKU
- Atribut SKU yang menangkap fitur produk (misalnya, ukuran dan bahan). Ini biasanya digunakan dalam model parametrik untuk membedakan antara varian produk.
Jika sumber data tidak diekspresikan dalam format tertentu, Data Factory menawarkan serangkaian aktivitas transformasi.
Dalam fase proses, Gudang Data SQL adalah mesin penyimpanan utama. Anda dapat mengekspresikan aktivitas transformasi seperti prosedur tersimpan SQL, yang dapat secara otomatis dipanggil sebagai bagian dari alur. Dokumentasi ini memberikan instruksi terperinci:
Perhatikan bahwa Data Factory tidak membatasi Anda ke SQL Data Warehouse dan prosedur tersimpan SQL. Bahkan, terintegrasi dengan berbagai platform. Anda dapat, misalnya, menggunakan Databricks dan menjalankan skrip Python sebagai gantinya untuk transformasi. Ini adalah keuntungan, karena Anda dapat menggunakan satu platform untuk penyimpanan, transformasi, dan pelatihan algoritma pembelajaran mesin dalam tahap model berikut.
Melatih algoritma ML
Ada beberapa alat yang dapat membantu Anda menerapkan model parametrik dan non-parametrik. Pilihan Anda tergantung pada skalabilitas dan persyaratan performa Anda.
Azure ML Studio adalah alat yang bagus untuk membuat prototipe. Ini menyediakan cara mudah bagi Anda untuk membangun dan menjalankan alur kerja pelatihan dengan modul kode Anda (di R atau Python), atau dengan komponen ML yang telah ditentukan sebelumnya (seperti pengklasifikasi multi-kelas dan regresi pohon keputusan yang ditingkatkan) di lingkungan grafis. Ini juga memudahkan Anda untuk menerbitkan model terlatih sebagai layanan web untuk konsumsi lebih lanjut, menghasilkan antarmuka REST untuk Anda.
Namun, ukuran data yang dapat ditanganinya saat ini dibatasi hingga 10 GB dan jumlah inti yang tersedia untuk setiap komponen dibatasi hingga dua.
Jika Anda perlu menskalakan lebih lanjut tetapi masih ingin menggunakan beberapa implementasi Microsoft yang cepat, paralel, dari algoritma pembelajaran mesin umum (seperti regresi logistik multinomial), Anda dapat mempertimbangkan Microsoft ML Server yang berjalan di Azure Ilmu Data Virtual Machine.
Untuk ukuran data (TB) yang sangat besar, masuk akal untuk memilih platform tempat penyimpanan dan elemen komputasi dapat:
- Skalakan secara independen, untuk membatasi biaya saat Anda tidak melatih model.
- Distribusikan komputasi di beberapa inti.
- Jalankan komputasi yang dekat dengan penyimpanan untuk membatasi pergerakan data.
Azure HDInsight dan Databricks memenuhi persyaratan tersebut. Selain itu, keduanya adalah platform eksekusi yang didukung dalam editor Azure Data Factory. Relatif mudah untuk mengintegrasikan salah satu ke dalam alur kerja.
ML Server dan pustakanya dapat disebarkan di atas HDInsight, tetapi untuk memanfaatkan sepenuhnya kemampuan platform, Anda dapat menerapkan algoritma ML pilihan Anda dengan menggunakan pustaka SparkML, Microsoft ML Spark di Python, atau pemecah pemrograman linier spesialis lainnya seperti TFoCS, Spark-LP, atau SolveDF.
Memulai proses pelatihan kemudian menjadi pertanyaan untuk memanggil skrip atau notebook pySpark yang sesuai dari alur kerja Data Factory. Ini sepenuhnya didukung di editor grafis. Untuk detail selengkapnya, lihat Menjalankan buku catatan Databricks dengan Aktivitas Notebook Databricks di Azure Data Factory.
Gambar berikut menunjukkan antarmuka pengguna Data Factory, seperti yang diakses melalui portal Azure. Ini termasuk blok untuk berbagai proses dalam alur kerja.

Gambar 4: Contoh alur Data Factory dengan aktivitas buku catatan Databricks
Perhatikan juga bahwa dalam solusi pengoptimalan inventarisasi kami, kami mengusulkan implementasi pemecah berbasis kontainer yang diskalakan melalui Azure Batch. Pustaka pengoptimalan spesialis seperti pyomo memungkinkan Anda untuk mengekspresikan masalah pengoptimalan dengan menggunakan bahasa pemrograman Python, lalu memanggil pemecah independen seperti bonmin (sumber terbuka) atau gurobi (komersial) untuk menemukan solusi.
Dokumentasi pengoptimalan inventarisasi berkaitan dengan masalah yang berbeda (jumlah pesanan) daripada pengoptimalan bermakna, namun implementasi pemecah di Azure juga berlaku.
Meskipun lebih kompleks daripada yang disarankan sejauh ini, teknik ini memungkinkan skalabilitas maksimum, sebagian besar dibatasi oleh jumlah inti yang dapat Anda mampu.
Menjalankan model (mengoprasikan)
Setelah model dilatih, menjalankannya biasanya memerlukan infrastruktur yang berbeda dari yang digunakan untuk penyebaran. Agar mudah dikonsumsi, Anda dapat menyebarkannya sebagai layanan web dengan antarmuka REST. Azure ML Studio dan ML Server mengotomatiskan proses pembuatan layanan tersebut. Dalam kasus ML Server, Microsoft menyediakan templat untuk penyebaran infrastruktur pendukung. Silakan lihat dokumentasi yang relevan.
Gambar berikut menunjukkan arsitektur penyebaran. Ini termasuk representasi server yang menjalankan bahasa R dan Python. Kedua server berkomunikasi ke sub-bagian simpul web yang melakukan komputasi. Penyimpanan data besar terhubung ke blok komputasi.

Gambar 5: Contoh penyebaran server ML
Model yang dibuat pada HDInsight atau Databricks bergantung pada lingkungan Spark (pustaka, kemampuan paralel, dan sebagainya). Anda dapat mempertimbangkan untuk menjalankannya pada kluster. Panduan disediakan di sini. Melakukan ini memiliki keuntungan bahwa model operasional itu sendiri dapat dipanggil melalui aktivitas alur Data Factory untuk penilaian.
Untuk menggunakan kontainer, Anda dapat mengemas model dan menyebarkannya di Azure Kubernetes Service. Prototipe memerlukan penggunaan Azure Ilmu Data VM. Anda juga harus menginstal alat baris perintah Azure ML di VM.
Output dan pelaporan data
Setelah disebarkan, model dapat memproses alur kerja transaksi keuangan dan pembacaan saham untuk menghasilkan prediksi bermasalah yang optimal. Data yang dihasilkan dapat disimpan kembali ke Gudang Data Azure SQL untuk analisis lebih lanjut. Secara khusus, dimungkinkan untuk mempelajari performa historis berbagai SKU, mengidentifikasi generator pendapatan terbaik dan pembuat kerugian. Anda kemudian dapat membandingkan mereka dengan berbagai macam yang disarankan oleh model, dan mengevaluasi performa dan kebutuhan untuk pelatihan ulang.
Power BI menyediakan cara untuk menganalisis dan menampilkan data yang dihasilkan dalam proses.
Gambar berikut ini memperlihatkan dasbor Power BI yang khas. Ini termasuk dua grafik yang menunjukkan informasi stok SKU.
Pertimbangan keamanan
Solusi yang berkaitan dengan data sensitif berisi catatan keuangan, tingkat saham, dan informasi harga. Data sensitif tersebut harus dilindungi. Anda dapat mengalihkan kekhawatiran tentang keamanan dan privasi data dengan cara berikut:
- Anda dapat menjalankan beberapa alur Azure Data Factory lokal dengan menggunakan Azure Integration Runtime. Runtime menjalankan aktivitas pergerakan data ke dan dari sumber lokal. Ini juga mengirimkan aktivitas untuk eksekusi lokal.
- Anda dapat mengembangkan aktivitas kustom untuk menganonimkan data untuk ditransfer ke Azure, dan menjalankannya secara lokal.
- Semua layanan yang disebutkan mendukung enkripsi saat transit dan tidak aktif. Jika Anda memilih untuk menyimpan data dengan menggunakan Azure Data Lake, enkripsi diaktifkan secara default. Jika Anda menggunakan Azure SQL Data Warehouse, Anda dapat mengaktifkan enkripsi data transparan (TDE).
- Semua layanan yang disebutkan, dengan pengecualian studio ML, mendukung integrasi dengan ID Microsoft Entra untuk autentikasi dan otorisasi. Jika Anda menulis kode Anda sendiri, Anda harus membangun integrasi tersebut ke dalam aplikasi Anda.
Untuk informasi selengkapnya tentang Peraturan Perlindungan Data Umum (GDPR), perlindungan data dan peraturan privasi di Uni Eropa, lihat halaman kepatuhan kami.
Komponen
Teknologi berikut ditampilkan dalam artikel ini:
- Azure Batch
- Microsoft Entra ID
- Azure Data Factory
- HDInsight
- Databricks
- Ilmu Data Virtual Machines
- Azure Kubernetes Service
- Microsoft Power BI
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Scott Seely | Arsitek Perangkat Lunak
Untuk melihat profil LinkedIn non-publik, masuk ke LinkedIn.
Langkah berikutnya
- Apa itu Azure Data Factory?
- Runtime integrasi di Azure Data Factory
- Apa itu kumpulan SQL khusus (sebelumnya SQL DW) di Azure Synapse Analytics?
- Microsoft Pembelajaran Mesin Studio (klasik)
- Apa itu Server Pembelajaran Mesin
- Bahasa pemodelan pengoptimalan Pyomo
- Pemecah Bonmin
- Pemecah TFoCS untuk Spark
Sumber daya terkait
Panduan ritel terkait:
- Solusi untuk industri ritel
- Memigrasikan solusi e-niaga Anda ke Azure
- Pencarian visual di ritel dengan Azure Cosmos DB
- Menyebarkan solusi deteksi footfall berbasis AI menggunakan Azure dan Azure Stack Hub
Arsitektur terkait: