Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Dukungan untuk Studio Azure Machine Learning (klasik) akan berakhir pada 31 Agustus 2024. Sebaiknya Anda transisi ke Azure Machine Learning sebelum tanggal tersebut.
Mulai 1 Desember 2021, Anda tidak akan dapat membuat sumber daya Studio Azure Machine Learning (klasik) baru. Hingga 31 Agustus 2024, Anda dapat terus menggunakan sumber daya Pembelajaran Mesin Studio (klasik) yang ada.
- Lihat informasi tentang memindahkan proyek pembelajaran mesin dari ML Studio (klasik) ke Azure Machine Learning.
- Pelajari selengkapnya tentang Azure Machine Learning.
ML Dokumentasi Studio (klasik) sedang berhenti dan mungkin tidak diperbarui di masa mendatang.
Mengonversi data teks menjadi fitur yang dikodekan bilangan bulat menggunakan pustaka Vowpal Wabbit
Kategori: Analitik Teks
Catatan
Berlaku untuk: hanya Pembelajaran Mesin Studio (klasik)
Modul seret dan letakkan serupa tersedia di perancang Azure Machine Learning.
Ringkasan Modul
Artikel ini menjelaskan cara menggunakan modul Hashing Fitur di Pembelajaran Mesin Studio (klasik), untuk mengubah aliran teks bahasa Inggris menjadi serangkaian fitur yang direpresentasikan sebagai bilangan bulat. Anda kemudian dapat meneruskan fitur hash ini diatur ke algoritma pembelajaran mesin untuk melatih model analisis teks.
Fungsi hash fitur yang disediakan dalam modul ini didasarkan pada kerangka kerja Vowpal Wabbit. Untuk informasi selengkapnya, lihat Melatih Model Vowpal Wabbit 7-4 atau Melatih Model Vowpal Wabbit 7-10.
Selengkapnya tentang hashing fitur
Hashing fitur bekerja dengan mengubah token unik menjadi bilangan bulat. Fitur ini beroperasi pada string yang tepat yang Anda berikan sebagai input dan tidak melakukan analisis linguistik atau pra-proses.
Misalnya, ambil satu set kalimat sederhana seperti ini, diikuti dengan skor sentimen. Misalnya Anda ingin menggunakan teks ini untuk menyusun model.
| USERTEXT | SENTIMEN |
|---|---|
| Saya suka buku ini | 3 |
| Saya benci buku ini | 1 |
| Buku ini sangat bagus | 3 |
| Aku suka buku | 2 |
Secara internal, modul Hashing Fitur membuat kamus n-gram. Misalnya, daftar bigram untuk himpunan data ini akan menjadi sesuatu seperti ini:
| TERM (bigram) | FREKUENSI |
|---|---|
| Buku ini | 3 |
| Aku suka | 1 |
| Aku benci | 1 |
| Aku suka | 1 |
Anda dapat mengontrol ukuran n-gram dengan menggunakan properti N-gram. Jika Anda memilih bigram, unigram juga dihitung. Dengan demikian, kamus juga akan menyertakan istilah tunggal seperti ini:
| Istilah (unigram) | FREKUENSI |
|---|---|
| buku | 3 |
| saya | 3 |
| buku | 1 |
| sebelumnya | 1 |
Setelah kamus dibuat, modul Hashing Fitur mengonversi istilah kamus menjadi nilai hash, dan menghitung apakah fitur digunakan dalam setiap kasus. Untuk setiap baris data teks, modul menghasilkan sekumpulan kolom, satu kolom untuk setiap fitur hash.
Misalnya, setelah hashing, kolom fitur mungkin terlihat seperti ini:
| Peringkat | Fitur hashing 1 | Fitur hashing 2 | Fitur hashing 3 |
|---|---|---|---|
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 0 |
- Jika nilai dalam kolom adalah 0, baris tidak berisi fitur yang di-hash.
- Jika nilainya 1, baris tersebut memang berisi fitur tersebut.
Keuntungan menggunakan hashing fitur adalah Anda dapat mewakili dokumen teks dengan panjang variabel sebagai vektor fitur numerik dengan panjang yang sama, dan mencapai pengurangan dimensi. Sebaliknya, jika Anda mencoba menggunakan kolom teks untuk pelatihan apa adanya, kolom tersebut akan diperlakukan sebagai kolom fitur kategoris, dengan banyak, banyak nilai berbeda.
Memiliki output sebagai numerik juga memungkinkan untuk menggunakan banyak metode pembelajaran mesin yang berbeda dengan data, termasuk klasifikasi, pengklusteran, atau pengambilan informasi. Karena operasi pencarian dapat menggunakan hashes bilangan bulat daripada perbandingan string, mendapatkan bobot fitur juga jauh lebih cepat.
Cara mengonfigurasi Hashing Fitur
Tambahkan modul Hashing Fitur ke eksperimen Anda di Studio (klasik).
Sambungkan himpunan data yang berisi teks yang ingin Anda analisis.
Tip
Karena hashing fitur tidak melakukan operasi leksikal seperti stemming atau pemotongan, Anda kadang-kadang bisa mendapatkan hasil yang lebih baik dengan melakukan pra-pemrosesan teks sebelum menerapkan hashing fitur. Untuk saran, lihat bagian Praktik terbaik dan Catatan teknis .
Untuk Kolom target, pilih kolom teks yang ingin Anda konversi ke fitur yang di-hash.
Kolom harus berupa jenis data string, dan harus ditandai sebagai kolom Fitur .
Jika Anda memilih beberapa kolom teks untuk digunakan sebagai input, itu dapat memiliki efek besar pada dimensi fitur. Misalnya, jika hash 10-bit digunakan untuk satu kolom teks, output berisi 1024 kolom. Jika hash 10-bit digunakan untuk dua kolom teks, output berisi kolom 2048.
Catatan
Secara default, Studio (klasik) menandai sebagian besar kolom teks sebagai fitur, jadi jika Anda memilih semua kolom teks, Anda mungkin mendapatkan terlalu banyak kolom, termasuk banyak yang sebenarnya bukan teks gratis. Gunakan opsi Hapus fitur di Edit Metadata untuk mencegah kolom teks lain di-hash.
Gunakan bitsize Hashing untuk menentukan jumlah bit yang akan digunakan saat membuat tabel hash.
Ukuran bit default adalah 10. Untuk banyak masalah, nilai ini lebih dari memadai, tetapi apakah cukup untuk data Anda tergantung pada ukuran kosakata n-gram dalam teks pelatihan. Dengan kosakata yang besar, lebih banyak ruang mungkin diperlukan untuk menghindari tabrakan.
Kami menyarankan agar Anda mencoba menggunakan jumlah bit yang berbeda untuk parameter ini, dan mengevaluasi performa solusi pembelajaran mesin.
Untuk N-gram, ketik angka yang menentukan panjang maksimum n-gram untuk ditambahkan ke kamus pelatihan. N-gram adalah urutan kata n, diperlakukan sebagai unit yang unik.
N-gram = 1: Unigram, atau kata tunggal.
N-gram = 2: Bigram, atau urutan dua kata, ditambah unigram.
N-gram = 3: Trigram, atau urutan tiga kata, ditambah bigram dan unigram.
Jalankan eksperimen.
Hasil
Setelah pemrosesan selesai, modul menghasilkan himpunan data yang diubah di mana kolom teks asli telah dikonversi menjadi beberapa kolom, masing-masing mewakili fitur dalam teks. Tergantung pada seberapa besar kamus, himpunan data yang dihasilkan bisa sangat besar:
| Nama kolom 1 | Jenis kolom 2 |
|---|---|
| USERTEXT | Kolom data asli |
| SENTIMEN | Kolom data asli |
| USERTEXT - Fitur hashing 1 | Kolom fitur Hashed |
| USERTEXT - Fitur hashing 2 | Kolom fitur Hashed |
| USERTEXT - Fitur hashing n | Kolom fitur Hashed |
| USERTEXT - Fitur hashing 1024 | Kolom fitur Hashed |
Setelah membuat himpunan data yang diubah, Anda dapat menggunakannya sebagai input ke modul Latih Model , bersama dengan model klasifikasi yang baik, seperti Mesin Vektor Dukungan Dua Kelas.
Praktik terbaik
Beberapa praktik terbaik yang dapat Anda gunakan saat memodelkan data teks ditunjukkan dalam diagram berikut yang mewakili eksperimen
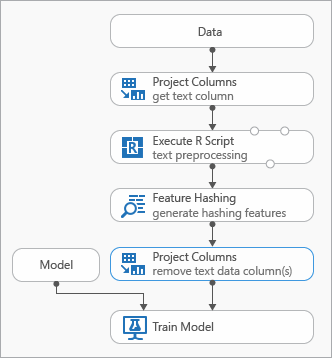
Anda mungkin perlu menambahkan modul Jalankan Skrip R sebelum menggunakan Hashing Fitur, untuk melakukan praproses teks input. Dengan skrip R, Anda juga memiliki fleksibilitas untuk menggunakan kosakata kustom atau transformasi kustom.
Anda harus menambahkan modul Pilih Kolom dalam Himpunan Data setelah modul Hashing Fitur untuk menghapus kolom teks dari himpunan data output. Anda tidak memerlukan kolom teks setelah fitur hashing dibuat.
Atau, Anda dapat menggunakan modul Edit Metadata untuk menghapus atribut fitur dari kolom teks.
Pertimbangkan juga untuk menggunakan opsi praproses teks ini, untuk menyederhanakan hasil dan meningkatkan akurasi:
- pemecahan kata
- hentikan penghapusan kata
- normalisasi kasus
- penghapusan tanda baca dan karakter khusus
- Berasal.
Serangkaian metode praproscessing optimal untuk diterapkan dalam solusi individual apa pun tergantung pada domain, kosakata, dan kebutuhan bisnis. Kami menyarankan agar Anda bereksperimen dengan data Anda untuk melihat metode pemrosesan teks kustom mana yang paling efektif.
Contoh
Untuk contoh bagaimana hashing fitur digunakan untuk analitik teks, lihat Galeri Azure AI:
Kategorisasi Berita: Menggunakan hashing fitur untuk mengklasifikasikan artikel ke dalam daftar kategori yang telah ditentukan sebelumnya.
Perusahaan Serupa: Menggunakan teks artikel Wikipedia untuk mengategorikan perusahaan.
Klasifikasi Teks: Sampel lima bagian ini menggunakan teks dari pesan Twitter untuk melakukan analisis sentimen.
Catatan teknis
Bagian ini berisi detail implementasi, tips, dan jawaban terkait pertanyaan yang sering diajukan.
Tip
Selain menggunakan hashing fitur, Anda mungkin ingin menggunakan metode lain untuk mengekstrak fitur dari teks. Contohnya:
- Gunakan modul Teks Praproses untuk menghapus artefak seperti kesalahan ejaan, atau untuk menyederhanakan persiapan teks ke hashing.
- Gunakan Ekstrak Frasa Kunci untuk menggunakan pemrosesan bahasa alami untuk mengekstrak frasa.
- Gunakan Pengenalan Entitas Karakter untuk mengidentifikasi entitas penting.
Pembelajaran Mesin Studio (klasik) menyediakan templat Klasifikasi Teks yang memandu Anda menggunakan modul Hashing Fitur untuk ekstraksi fitur.
Detail implementasi
Modul Hashing Fitur menggunakan kerangka kerja pembelajaran mesin cepat yang disebut Vowpal Wabbit yang hash kata-kata fitur ke dalam indeks dalam memori, menggunakan fungsi hash sumber terbuka populer yang disebut murmurhash3. Fungsi hash ini adalah algoritma hash non-kriptografi yang memetakan input teks ke bilangan bulat, dan populer karena berkinerja baik dalam distribusi kunci acak. Tidak seperti fungsi hash kriptografi, ini dapat dengan mudah dibalik oleh setan, sehingga tidak cocok untuk tujuan kriptografi.
Tujuan hashing adalah untuk mengonversi dokumen teks panjang variabel menjadi vektor fitur numerik dengan panjang yang sama, untuk mendukung pengurangan dimensi dan membuat pencarian bobot fitur lebih cepat.
Setiap fitur hash mewakili satu atau beberapa fitur teks n-gram (unigram atau kata individual, bi-gram, tri-gram, dll.), tergantung pada jumlah bit (direpresentasikan sebagai k) dan pada jumlah n-gram yang ditentukan sebagai parameter. Ini memproyeksikan nama fitur ke arsitektur mesin kata yang tidak ditandatangani menggunakan algoritma murmurhash v3 (hanya 32-bit) yang kemudian diedit AND dengan (2^k)-1. Artinya, nilai hash diproyeksikan ke bit urutan bawah k pertama, dan bit yang tersisa di-nol keluar. Jika jumlah bit yang ditentukan adalah 14, tabel hash dapat menampung 2entri 14-1 (atau 16.383).
Untuk banyak masalah, tabel hash default (bitsize = 10) lebih dari memadai; namun, tergantung pada ukuran kosakata n-gram dalam teks pelatihan, lebih banyak ruang mungkin diperlukan untuk menghindari tabrakan. Kami menyarankan agar Anda mencoba menggunakan jumlah bit yang berbeda untuk parameter Bitsize Hashing , dan mengevaluasi performa solusi pembelajaran mesin.
Input yang diharapkan
| Nama | Jenis | Deskripsi |
|---|---|---|
| Himpunan Data | Tabel Data | Himpunan data input |
Parameter modul
| Nama | Rentang | Jenis | Default | Deskripsi |
|---|---|---|---|---|
| Kolom target | Apa pun | ColumnSelection | StringFeature | Pilih kolom tempat hashing akan diterapkan. |
| Bitsize hashing | [1;31] | Bilangan bulat | 10 | Ketik jumlah bit yang akan digunakan saat hashing kolom yang dipilih |
| N-gram | [0;10] | Bilangan bulat | 2 | Tentukan jumlah N-gram yang dihasilkan selama hashing. Secara default, unigram dan bigram diekstraksi |
Output
| Nama | Jenis | Deskripsi |
|---|---|---|
| Himpunan data yang diubah | Tabel Data | Himpunan data output dengan kolom yang di-hash |
Pengecualian
| Pengecualian | Deskripsi |
|---|---|
| Kesalahan 0001 | Pengecualian terjadi jika satu atau beberapa kolom himpunan data tertentu tidak dapat ditemukan. |
| Kesalahan 0003 | Pengecualian terjadi jika satu atau beberapa input null atau kosong. |
| Kesalahan 0004 | Pengecualian terjadi jika parameter kurang dari atau sama dengan nilai tertentu. |
| Kesalahan 0017 | Pengecualian terjadi jika satu atau beberapa kolom yang ditentukan memiliki jenis yang tidak didukung oleh modul saat ini. |
Untuk daftar kesalahan khusus untuk modul Studio (klasik), lihat Pembelajaran Mesin Kode kesalahan.
Untuk daftar pengecualian API, lihat Pembelajaran Mesin Kode Kesalahan REST API.