Memperkenalkan penyebaran aplikasi di SQL Server Kluster Big Data
Berlaku untuk: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Penting
Add-on Kluster Big Data Microsoft SQL Server 2019 akan dihentikan. Dukungan untuk SQL Server 2019 Kluster Big Data akan berakhir pada 28 Februari 2025. Semua pengguna SQL Server 2019 yang ada dengan Jaminan Perangkat Lunak akan didukung sepenuhnya pada platform dan perangkat lunak akan terus dipertahankan melalui pembaruan kumulatif SQL Server hingga saat itu. Untuk informasi selengkapnya, lihat posting blog pengumuman dan Opsi big data di platform Microsoft SQL Server.
Penyebaran aplikasi memungkinkan penyebaran aplikasi di SQL Server Kluster Big Data dengan menyediakan antarmuka untuk membuat, mengelola, dan menjalankan aplikasi. Aplikasi yang disebarkan pada Kluster Big Data mendapat manfaat dari kekuatan komputasi kluster dan dapat mengakses data yang tersedia di kluster. Ini meningkatkan skalabilitas dan performa aplikasi, sambil mengelola aplikasi tempat data berada. Runtime aplikasi yang didukung di SQL Server Kluster Big Data adalah: R, Python, dtexec, dan MLeap.
Bagian berikut menjelaskan arsitektur dan fungsionalitas penyebaran aplikasi.
Arsitektur penyebaran aplikasi
Penyebaran aplikasi terdiri dari pengontrol dan handler runtime aplikasi. Saat membuat aplikasi, file spesifikasi (spec.yaml) disediakan. File ini spec.yaml berisi semua yang perlu diketahui pengontrol untuk berhasil menyebarkan aplikasi. Berikut ini adalah sampel konten untuk spec.yaml:
#spec.yaml
name: add-app #name of your python script
version: v1 #version of the app
runtime: Python #the language this app uses (R or Python)
src: ./add.py #full path to the location of the app
entrypoint: add #the function that will be called upon execution
replicas: 1 #number of replicas needed
poolsize: 1 #the pool size that you need your app to scale
inputs: #input parameters that the app expects and the type
x: int
y: int
output: #output parameter the app expects and the type
result: int
Pengontrol memeriksa runtime yang ditentukan dalam spec.yaml file dan memanggil penangan runtime yang sesuai. Handler runtime membuat aplikasi. Pertama, ReplicaSet Kubernetes dibuat yang berisi satu atau beberapa pod, yang masing-masing berisi aplikasi yang akan disebarkan. Jumlah pod didefinisikan oleh parameter yang replicas diatur dalam spec.yaml file untuk aplikasi. Setiap pod dapat memiliki salah satu dari lebih banyak kumpulan. Jumlah kumpulan ditentukan oleh parameter yang poolsize ditetapkan dalam spec.yaml file.
Pengaturan ini menentukan jumlah permintaan yang dapat ditangani penyebaran secara paralel. Jumlah maksimum permintaan pada satu waktu tertentu sama dengan replicas waktu poolsize. Jika Anda memiliki 5 replika dan 2 kumpulan per replika, penyebaran dapat menangani 10 permintaan secara paralel. Lihat gambar di bawah ini untuk representasi grafis dan replicas poolsize:
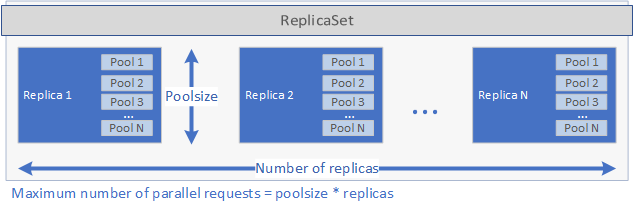
Setelah ReplicaSet dibuat dan pod telah dimulai, pekerjaan cron dibuat jika diatur schedule dalam spec.yaml file. Terakhir, Kubernetes Service dibuat yang dapat digunakan untuk mengelola dan menjalankan aplikasi (lihat di bawah).
Ketika aplikasi dijalankan, layanan Kubernetes untuk aplikasi menproksi permintaan ke replika dan mengembalikan hasilnya.
Pertimbangan keamanan untuk penyebaran aplikasi di OpenShift
SQL Server 2019 CU5 memungkinkan dukungan untuk penyebaran BDC pada Red Hat OpenShift dan model keamanan yang diperbarui untuk BDC sehingga kontainer istimewa tidak lagi diperlukan. Selain non-istimewa, kontainer berjalan sebagai pengguna non-root secara default untuk semua penyebaran baru menggunakan SQL Server 2019 CU5.
Pada saat rilis CU5, langkah penyiapan aplikasi yang disebarkan dengan antarmuka penyebaran aplikasi masih akan berjalan sebagai pengguna root . Ini diperlukan karena selama penyiapan paket tambahan yang akan digunakan aplikasi diinstal. Kode pengguna lain yang disebarkan sebagai bagian dari aplikasi akan berjalan sebagai pengguna dengan hak istimewa rendah.
Selain itu, CAP_AUDIT_WRITE kemampuan adalah kemampuan opsional yang diperlukan untuk memungkinkan penjadwalan aplikasi SQL Server Integration Services (SSIS) menggunakan pekerjaan cron. Ketika file spesifikasi yaml aplikasi menentukan jadwal, aplikasi akan dipicu melalui pekerjaan cron, yang memerlukan kemampuan tambahan. Atau, aplikasi dapat dipicu sesuai permintaan dengan azdata app run melalui panggilan layanan web, yang tidak memerlukan CAP_AUDIT_WRITE kemampuan. Perhatikan bahwa CAP_AUDIT_WRITE kemampuan tidak lagi diperlukan untuk cronjob memulai dari rilis CU8 SQL Server 2019.
Catatan
SCC kustom dalam artikel penyebaran OpenShift tidak menyertakan kemampuan ini karena tidak diperlukan oleh penyebaran default BDC. Untuk mengaktifkan kemampuan ini, Anda harus terlebih dahulu memperbarui file yaml SCC kustom untuk menyertakan CAP_AUDIT_WRITE.
...
allowedCapabilities:
- SETUID
- SETGID
- CHOWN
- SYS_PTRACE
- AUDIT_WRITE
...
Cara bekerja dengan penyebaran aplikasi di dalam Kluster Big Data
Dua antarmuka utama untuk penyebaran aplikasi adalah:
Aplikasi juga dapat dijalankan menggunakan layanan web RESTful. Untuk informasi selengkapnya, lihat Menggunakan aplikasi di Kluster Big Data.
Skenario penyebaran aplikasi
Penyebaran aplikasi memungkinkan penyebaran aplikasi pada SQL Server BDC dengan menyediakan antarmuka untuk membuat, mengelola, dan menjalankan aplikasi.
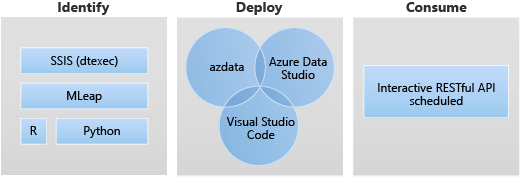
Berikut ini adalah skenario target untuk penyebaran aplikasi:
- Sebarkan layanan web Python atau R di dalam kluster big data untuk mengatasi berbagai kasus penggunaan seperti inferensi pembelajaran mesin, penyajian API, dll.
- Buat titik akhir inferensi pembelajaran mesin menggunakan mesin MLeap.
- Jadwalkan dan jalankan paket dari file DTSX menggunakan utilitas dtexec untuk transformasi dan pergerakan data.
Menggunakan runtime Python penyebaran aplikasi
Dalam penyebaran aplikasi, runtime python BDC memungkinkan aplikasi Python di dalam kluster big data untuk mengatasi berbagai kasus penggunaan seperti inferensi pembelajaran mesin, penyajian API, dan banyak lagi.
Aplikasi ini menyebarkan runtime Python menggunakan Python 3.8 di SQL Server Kluster Big Data CU10+.
Dalam penyebaran aplikasi, spec.yaml adalah tempat Anda memberikan informasi yang perlu diketahui pengontrol untuk menyebarkan aplikasi Anda. Berikut ini adalah bidang yang dapat ditentukan:
name: nama aplikasiversion: versi aplikasi, misalnya, sepertiv1runtime: runtime penyebaran aplikasi, Anda perlu menentukannya sebagai:Pythonsrc: jalur ke aplikasi Pythonentry point: fungsi titik masuk dalam skrip src yang akan dijalankan untuk aplikasi Python ini.
Selain di atas, Anda perlu menentukan input dan output aplikasi Python Anda. Yang menghasilkan file yang spec.yaml mirip dengan yang berikut ini:
#spec.yaml
name: add-app
version: v1
runtime: Python
src: ./add.py
entrypoint: add
replicas: 1
poolsize: 1
inputs:
x: int
y: int
output:
result: int
Anda dapat membuat folder dasar dan struktur file yang diperlukan untuk menyebarkan aplikasi Python yang berjalan di Kluster Big Data:
azdata app init --template python --name hello-py --version v1
Untuk langkah berikutnya, lihat Cara menyebarkan aplikasi di SQL Server Kluster Big Data.
Batasan penyebaran aplikasi runtime Python
Runtime Python penyebaran aplikasi tidak mendukung skenario penjadwalan. Setelah aplikasi Python disebarkan, dan berjalan di BDC, titik akhir RESTful dikonfigurasi untuk mendengarkan permintaan masuk.
Menggunakan runtime R penyebaran aplikasi
Dalam penyebaran aplikasi, runtime BDC Python memungkinkan aplikasi R di dalam kluster big data untuk mengatasi berbagai kasus penggunaan seperti inferensi pembelajaran mesin, penyajian API, dan banyak lagi.
Runtime R penyebaran aplikasi menggunakan Microsoft R Open (MRO) versi 3.5.2 di SQL Server Kluster Big Data CU10+.
Bagaimana cara menggunakannya?
Dalam penyebaran aplikasi, spec.yaml adalah tempat Anda memberikan informasi yang perlu diketahui pengontrol untuk menyebarkan aplikasi Anda. Berikut ini adalah bidang yang dapat ditentukan:
name: nama aplikasiversion: versi aplikasi, misalnya, sepertiv1runtime: runtime penyebaran aplikasi, Anda perlu menentukannya sebagai:Rsrc: jalur ke aplikasi Rentry point: titik masuk untuk menjalankan aplikasi R ini
Selain di atas, Anda perlu menentukan input dan output aplikasi R Anda. Yang menghasilkan file yang spec.yaml mirip dengan yang berikut ini:
#spec.yaml
name: roll-dice
version: v1
runtime: R
src: ./roll-dice.R
entrypoint: rollEm
replicas: 1
poolsize: 1
inputs:
x: integer
output:
result: data.fram
Anda dapat membuat folder dasar dan struktur file yang diperlukan untuk menyebarkan aplikasi R baru menggunakan perintah berikut:
azdata app init --template r --name hello-r --version v1
Untuk langkah berikutnya, lihat Cara menyebarkan aplikasi di SQL Server Kluster Big Data.
Batasan runtime R
Batasan ini selaras dengan Microsoft R Application Network, yang dihentikan pada 1 Juli 2023. Untuk informasi dan solusi selengkapnya, lihat Penghentian Microsoft R Application Network.
Menggunakan runtime dtexec penyebaran aplikasi
Dalam penyebaran aplikasi, utilitas dtexec terintegrasi runtime Big Data Cluster berasal dari SSIS di Linux (mssql-server-is). Penyebaran aplikasi menggunakan utilitas dtexec untuk memuat paket dari file *.dtsx. Ini mendukung menjalankan paket SSIS pada jadwal gaya cron atau sesuai permintaan melalui permintaan layanan web.
Fitur ini menggunakan /opt/ssis/bin/dtexec /FILE dari SQL Server 2019 Integration Service di Linux. Ini mendukung format dtsx untuk SQL Server 2019 Integration Service di Linux (mssql-server-is 15.0.2). Untuk mempelajari selengkapnya tentang utilitas dtexec, lihat Utilitas dtexec.
Dalam penyebaran aplikasi, spec.yaml adalah tempat Anda memberikan informasi yang perlu diketahui pengontrol untuk menyebarkan aplikasi Anda. Berikut ini adalah bidang yang dapat ditentukan:
name: aplikasinameversion: versi aplikasi, misalnya, sepertiv1runtime: runtime penyebaran aplikasi, untuk menjalankan utilitas dtexec, Anda perlu menentukannya sebagai:SSISentrypoint: tentukan titik masuk, ini biasanya file .dtsx Anda dalam kasus kami.options: tentukan opsi tambahan untuk/opt/ssis/bin/dtexec /FILE, misalnya untuk menyambungkan ke database dengan string koneksi, itu akan mengikuti pola berikut:/REP V /CONN "sqldatabasename"\;"\"Data Source=xx;User ID=xx;Password=xx\""Untuk detail tentang sintaksis, lihat Utilitas dtexec.
schedule: tentukan seberapa sering pekerjaan perlu dijalankan, misalnya, saat menggunakan ekspresi cron untuk menentukan nilai ini sebagai "*/1 * * *" yang berarti pekerjaan sedang dijalankan berdasarkan menit.
Anda dapat membuat folder dasar dan struktur file yang diperlukan untuk menyebarkan aplikasi SSIS baru menggunakan perintah berikut:
azdata app init --name hello-is –version v1 --template ssis
Yang menghasilkan spec.yaml file ke yang berikut:
#spec.yaml
entrypoint: ./hello.dtsx
name: hello-is
options: /REP V
poolsize: 2
replicas: 2
runtime: SSIS
schedule: '*/2 * * * *'
version: v1
Contohnya juga membuat paket sampel hello.dtsx .
Semua file aplikasi Anda berada dalam direktori yang sama dengan .spec.yaml spec.yaml harus berada di tingkat akar direktori kode sumber aplikasi Anda termasuk file dtsx.
Untuk langkah berikutnya, lihat Cara menyebarkan aplikasi di SQL Server Kluster Big Data.
Batasan runtime utilitas dtexec
Semua batasan dan masalah yang diketahui untuk SQL Server Integration Services (SSIS) di Linux berlaku di SQL Server Kluster Big Data. Anda dapat mengetahui lebih lanjut dari Batasan dan masalah yang diketahui untuk SSIS di Linux.
Menggunakan aplikasi menyebarkan runtime MLeap
Aplikasi menyebarkan runtime MLeap mendukung MLeap Serving v0.13.0.
Dalam penyebaran aplikasi, spec.yaml adalah tempat Anda memberikan informasi yang perlu diketahui pengontrol untuk menyebarkan aplikasi Anda. Berikut ini adalah bidang yang dapat ditentukan:
name: nama aplikasiversion: versi aplikasi, misalnya, sepertiv1runtime: runtime penyebaran aplikasi, Anda perlu menentukannya sebagai:Mleap
Selain di atas, Anda perlu menentukan bundleFileName aplikasi MLeap Anda. Yang menghasilkan file yang spec.yaml mirip dengan yang berikut ini:
#spec.yaml
name: mleap-census
version: v1
runtime: Mleap
bundleFileName: census-bundle.zip
replicas: 1
Anda dapat membuat folder dasar dan struktur file yang diperlukan untuk menyebarkan aplikasi MLeap baru menggunakan perintah berikut:
azdata app init --template mleap --name hello-mleap --version v1
Untuk langkah berikutnya, lihat Cara menyebarkan aplikasi di SQL Server Kluster Big Data.
Batasan runtime MLeap
Batasan selaras dengan visi dari proyek sumber terbuka MLeap Combust di GitHub.
Langkah berikutnya
Untuk mempelajari selengkapnya tentang cara membuat dan menjalankan aplikasi di SQL Server Kluster Big Data, lihat yang berikut ini:
- Menyebarkan aplikasi menggunakan azdata
- Menyebarkan aplikasi menggunakan ekstensi penyebaran aplikasi
- Mengonsumsi aplikasi pada Kluster Big Data
Untuk mempelajari selengkapnya tentang Kluster Big Data SQL Server, lihat gambaran umum berikut: