Memperkenalkan Kluster Big Data SQL Server
Berlaku untuk: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Penting
Add-on Kluster Big Data Microsoft SQL Server 2019 akan dihentikan. Dukungan untuk SQL Server 2019 Kluster Big Data akan berakhir pada 28 Februari 2025. Semua pengguna SQL Server 2019 yang ada dengan Jaminan Perangkat Lunak akan didukung sepenuhnya pada platform dan perangkat lunak akan terus dipertahankan melalui pembaruan kumulatif SQL Server hingga saat itu. Untuk informasi selengkapnya, lihat posting blog pengumuman dan Opsi big data di platform Microsoft SQL Server.
Di SQL Server 2019 (15.x), SQL Server Kluster Big Data memungkinkan Anda untuk menyebarkan kluster kontainer SQL Server, Spark, dan HDFS yang dapat diskalakan yang berjalan di Kubernetes. Komponen-komponen ini berjalan berdampingan untuk memungkinkan Anda membaca, menulis, dan memproses big data dari T-SQL atau Spark, memungkinkan Anda menggabungkan dan menganalisis data hubungan bernilai tinggi dengan big data bervolume tinggi dengan mudah.
Memulai
- Pertama, lihat Mulai menggunakan penyebaran Kluster Big Data SQL Server
- Untuk fitur baru untuk rilis terbaru, lihat catatan rilis
- Untuk tanya jawab umum, lihat tanya jawab umum Kluster Big Data
Arsitektur kluster big data
Diagram berikut menunjukkan komponen kluster big data SQL Server:

Pengontrol
Pengontrol menyediakan manajemen dan keamanan untuk kluster. Ini berisi layanan kontrol, penyimpanan konfigurasi, dan layanan tingkat kluster lainnya seperti Kibana, Grafana, dan Elastic Search.
Kumpulan komputasi
Kumpulan komputasi menyediakan sumber daya komputasi ke kluster. Ini berisi simpul yang menjalankan SQL Server pada pod Linux. Pod dalam kumpulan komputasi dibagi menjadi instans SQL Compute untuk tugas pemrosesan tertentu.
Kumpulan data
Kumpulan data digunakan untuk persistensi data. Kumpulan data terdiri dari satu atau beberapa pod yang menjalankan SQL Server di Linux. Ini digunakan untuk menyerap data dari kueri SQL atau pekerjaan Spark.
Kumpulan penyimpanan
Kumpulan penyimpanan terdiri dari pod kumpulan penyimpanan yang terdiri dari SQL Server di Linux, Spark, dan HDFS. Semua simpul penyimpanan dalam kluster big data SQL Server adalah anggota kluster HDFS.
Tip
Untuk melihat arsitektur dan penginstalan kluster big data secara mendalam, lihat Lokakarya: Arsitektur Kluster Big Data Microsoft SQL Server.
Kumpulan aplikasi
Penyebaran aplikasi memungkinkan penyebaran aplikasi di SQL Server Kluster Big Data dengan menyediakan antarmuka untuk membuat, mengelola, dan menjalankan aplikasi.
Skenario dan fitur
SQL Server Kluster Big Data memberikan fleksibilitas dalam cara Anda berinteraksi dengan big data Anda. Anda dapat mengkueri sumber data eksternal, menyimpan big data di HDFS yang dikelola oleh SQL Server, atau mengkueri data dari beberapa sumber data eksternal melalui kluster. Anda kemudian dapat menggunakan data untuk AI, pembelajaran mesin, dan tugas analisis lainnya.
Gunakan Kluster Big Data SQL Server untuk:
- Sebarkan kluster kontainer SQL Server, Spark, dan HDFS yang dapat diskalakan yang berjalan di Kubernetes.
- Membaca, menulis, dan memproses big data dari Transact-SQL atau Spark.
- Gabungkan dan analisis data relasional bernilai tinggi dengan big data volume tinggi dengan mudah.
- Mengkueri sumber data eksternal.
- Simpan big data di HDFS yang dikelola oleh SQL Server.
- Mengkueri data dari beberapa sumber data eksternal melalui kluster.
- Gunakan data untuk AI, pembelajaran mesin, dan tugas analisis lainnya.
- Menyebarkan dan menjalankan aplikasi di Kluster Big Data.
- Virtualisasikan data dengan PolyBase. Data kueri dari sumber data SQL Server eksternal, Oracle, Teradata, MongoDB, dan ODBC generik dengan tabel eksternal.
- Berikan ketersediaan tinggi untuk instans master SQL Server dan semua database dengan menggunakan teknologi grup ketersediaan AlwaysOn.
Bagian berikut ini menyediakan informasi selengkapnya tentang skenario ini.
Virtualisasi data
Dengan memanfaatkan PolyBase, SQL Server Kluster Big Data dapat mengkueri sumber data eksternal tanpa memindahkan atau menyalin data. SQL Server 2019 (15.x) memperkenalkan konektor baru ke sumber data, untuk informasi selengkapnya lihat Apa yang baru di PolyBase 2019?.
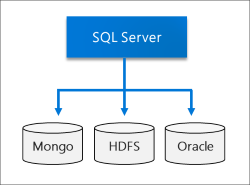
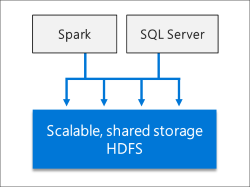
Data lake
Kluster big data SQL Server mencakup kumpulan penyimpanan HDFS yang dapat diskalakan. Ini dapat digunakan untuk menyimpan big data, yang berpotensi diserap dari beberapa sumber eksternal. Setelah big data disimpan dalam HDFS di kluster big data, Anda dapat menganalisis dan mengkueri data dan menggabungkannya dengan data relasional Anda.
AI terintegrasi dan pembelajaran mesin
SQL Server Kluster Big Data mengaktifkan tugas AI dan pembelajaran mesin pada data yang disimpan di kumpulan penyimpanan HDFS dan kumpulan data. Anda dapat menggunakan Spark serta alat AI bawaan di SQL Server menggunakan R, Python, Scala, atau Java.

Manajemen dan pemantauan
Manajemen dan pemantauan disediakan melalui kombinasi alat baris perintah, API, portal, dan tampilan manajemen dinamis.
Anda dapat menggunakan Azure Data Studio untuk melakukan berbagai tugas pada kluster big data:
- Cuplikan bawaan untuk tugas manajemen umum.
- Kemampuan untuk menelusuri HDFS, mengunggah file, mempratinjau file, dan membuat direktori.
- Kemampuan untuk membuat, membuka, dan menjalankan notebook yang kompatibel dengan Jupyter.
- Wizard virtualisasi data untuk menyederhanakan pembuatan sumber data eksternal (diaktifkan oleh Ekstensi Virtualisasi Data).
Konsep Kubernetes
Kluster big data SQL Server adalah kluster kontainer Linux yang diorkestrasi oleh Kubernetes.
Kubernetes adalah orkestrator kontainer sumber terbuka, yang dapat menskalakan penyebaran kontainer sesuai kebutuhan. Tabel berikut mendefinisikan beberapa terminologi Kubernetes penting:
| Persyaratan | Deskripsi |
|---|---|
| Kluster | Kluster Kubernetes adalah sekumpulan komputer, yang dikenal sebagai simpul. Satu simpul mengontrol kluster dan ditunjuk sebagai simpul master; node yang tersisa adalah simpul pekerja. Master Kubernetes bertanggung jawab untuk mendistribusikan pekerjaan antara pekerja, dan untuk memantau kesehatan kluster. |
| Node | Simpul menjalankan aplikasi kontainer. Ini bisa berupa komputer fisik atau komputer virtual. Kluster Kubernetes dapat berisi campuran komputer fisik dan simpul komputer virtual. |
| Pod | Pod adalah unit penyebaran atom Kubernetes. Pod adalah grup logis dari satu atau beberapa kontainer dan sumber daya terkait yang diperlukan untuk menjalankan aplikasi. Setiap pod berjalan pada node; sebuah node dapat menjalankan satu atau beberapa pod. Master Kubernetes secara otomatis menetapkan pod ke simpul dalam kluster. |
Di SQL Server Kluster Big Data, Kubernetes bertanggung jawab atas status kluster. Kubernetes membangun dan mengonfigurasi node kluster, menetapkan pod ke simpul, dan memantau kesehatan kluster.