Memperkenalkan kumpulan data di SQL Server Kluster Big Data
Berlaku untuk: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Penting
Add-on Kluster Big Data Microsoft SQL Server 2019 akan dihentikan. Dukungan untuk SQL Server 2019 Kluster Big Data akan berakhir pada 28 Februari 2025. Semua pengguna SQL Server 2019 yang ada dengan Jaminan Perangkat Lunak akan didukung sepenuhnya pada platform dan perangkat lunak akan terus dipertahankan melalui pembaruan kumulatif SQL Server hingga saat itu. Untuk informasi selengkapnya, lihat posting blog pengumuman dan Opsi big data di platform Microsoft SQL Server.
Artikel ini menjelaskan peran kumpulan data SQL Server dalam kluster big data SQL Server. Bagian berikut menjelaskan arsitektur, fungsionalitas, dan skenario penggunaan kumpulan data.
Video 5 menit ini memperkenalkan kumpulan data dan menunjukkan kepada Anda cara mengkueri data dari kumpulan data:
Arsitektur kumpulan data
Kumpulan data terdiri dari satu atau beberapa instans kumpulan data SQL Server yang menyediakan penyimpanan SQL Server persisten untuk kluster. Ini memungkinkan kueri performa data yang di-cache terhadap sumber data eksternal dan offloading pekerjaan. Data diserap ke dalam kumpulan data menggunakan kueri T-SQL atau dari pekerjaan Spark. Untuk meningkatkan performa di seluruh himpunan data besar, data yang diserap didistribusikan ke dalam pecahan dan disimpan di semua instans SQL Server di kumpulan. Metode distribusi yang didukung adalah round robin dan direplikasi. Untuk pengoptimalan akses baca, indeks penyimpan kolom berkluster dibuat pada setiap tabel di setiap instans kumpulan data. Kumpulan data berfungsi sebagai data mart peluasan skala untuk Kluster Big Data SQL Server.
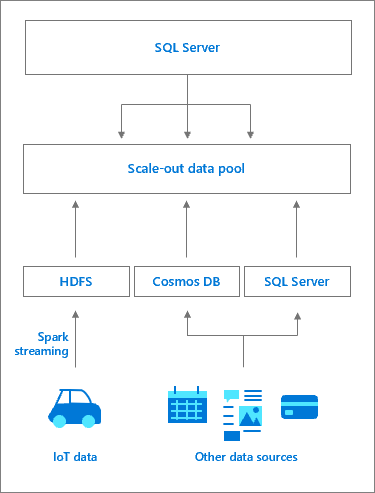
Akses ke instans server SQL di kumpulan data dikelola dari instans master SQL Server. Sumber data eksternal ke kumpulan data dibuat, bersama dengan tabel eksternal PolyBase untuk menyimpan cache data. Di latar belakang, pengontrol membuat database di kumpulan data dengan tabel yang cocok dengan tabel eksternal. Dari instans master SQL Server, alur kerja transparan; pengontrol mengalihkan permintaan tabel eksternal tertentu ke instans SQL Server di kumpulan data, yang mungkin melalui kumpulan komputasi, menjalankan kueri dan mengembalikan tataan hasil. Data dalam kumpulan data hanya dapat diserap atau dikueri dan tidak dapat dimodifikasi. Oleh karena itu, setiap refresh data akan memerlukan penurunan tabel, diikuti dengan rekreasi tabel dan repopulasi data berikutnya.
Skenario kumpulan data
Tujuan pelaporan adalah skenario kumpulan data umum. Misalnya, kueri kompleks yang bergabung dengan beberapa sumber data PolyBase, yang digunakan untuk laporan mingguan, dapat dilepaskan ke kumpulan data. Data yang di-cache menyediakan komputasi cepat lokal dan menghilangkan kebutuhan untuk kembali ke himpunan data asli. Demikian juga, data dasbor yang memerlukan penyegaran berkala dapat di-cache di kumpulan data untuk pelaporan yang dioptimalkan. Pembelajaran Mesin eksplorasi berulang juga dapat memperoleh manfaat dari penembolokan himpunan data di kumpulan data.
Langkah berikutnya
Untuk mempelajari selengkapnya tentang Kluster Big Data SQL Server, lihat sumber daya berikut ini: