Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Artikel ini menjelaskan peran kumpulan penyimpanan SQL Server dalam kluster big data SQL Server. Bagian berikut menjelaskan arsitektur dan fungsionalitas kumpulan penyimpanan.
Important
Kluster Big Data Microsoft SQL Server 2019 dihentikan. Dukungan untuk Kluster Big Data SQL Server 2019 berakhir per 28 Februari 2025. Untuk informasi selengkapnya, lihat posting blog pengumuman dan Opsi big data di platform Microsoft SQL Server.
Arsitektur kumpulan penyimpanan
Kumpulan penyimpanan adalah kluster HDFS (Hadoop) lokal dalam kluster big data SQL Server. Ini menyediakan penyimpanan persisten untuk data yang tidak terstruktur dan semi terstruktur. File data, seperti Parquet atau teks yang dibatasi, dapat disimpan di kumpulan penyimpanan. Agar penyimpanan bertahan lama, setiap pod dalam pool memiliki volume persisten yang melekat padanya. File kumpulan penyimpanan dapat diakses melalui PolyBase melalui SQL Server atau langsung menggunakan Apache Knox Gateway.
Pengaturan HDFS klasik terdiri dari satu set komputer perangkat keras umum dengan penyimpanan terpasang. Data tersebar di blok di seluruh simpul untuk toleransi kesalahan dan memanfaatkan pemrosesan paralel. Salah satu simpul dalam kluster berfungsi sebagai node nama dan berisi informasi metadata tentang file yang terletak di simpul data.
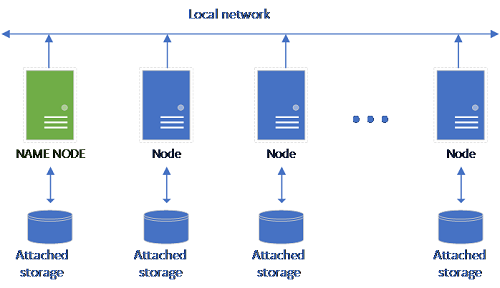
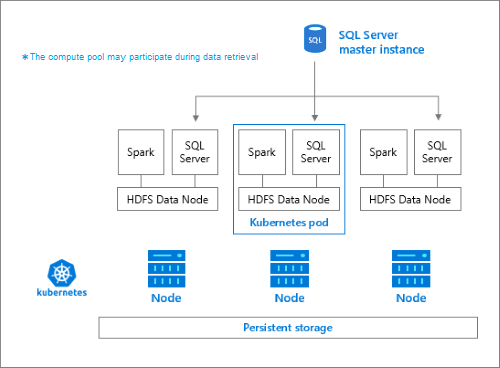
Kumpulan penyimpanan terdiri dari simpul penyimpanan yang merupakan anggota kluster HDFS. Ini menjalankan satu atau beberapa pod Kubernetes dengan setiap pod yang menghosting kontainer berikut:
- Kontainer Hadoop yang ditautkan ke volume persisten (penyimpanan). Semua kontainer jenis ini bersama-sama membentuk kluster Hadoop. Di dalam kontainer Hadoop, ada proses manajer node YARN yang dapat membuat proses pekerja Apache Spark secara instan ketika diperlukan. Simpul kepala Spark menghosting metastore Hive, riwayat Spark, dan kontainer riwayat pekerjaan YARN.
- Instans SQL Server untuk membaca data dari HDFS menggunakan teknologi OpenRowSet.
-
collectduntuk mengumpulkan data metrik. -
fluentbituntuk mengumpulkan data log.
Responsibilities
Simpul penyimpanan bertanggung jawab atas:
- Penyerapan data melalui Apache Spark.
- Penyimpanan data dalam HDFS (Parquet dan format teks yang dibatasi). HDFS juga menyediakan persistensi data, karena data HDFS tersebar di semua simpul penyimpanan di SQL BDC.
- Akses data melalui titik akhir HDFS dan SQL Server.
Accessing data
Metode utama untuk mengakses data di kumpulan penyimpanan adalah:
- Spark jobs.
- Pemanfaatan tabel eksternal SQL Server untuk memungkinkan kueri data menggunakan simpul komputasi PolyBase dan instans SQL Server yang berjalan di simpul HDFS.
Anda juga dapat berinteraksi dengan HDFS menggunakan:
- Azure Data Studio.
- Azure Data CLI (
azdata). - kubectl untuk mengeluarkan perintah ke kontainer Hadoop.
- Gerbang HTTP HDFS.
Next steps
Untuk mempelajari selengkapnya tentang Kluster Big Data SQL Server, lihat sumber daya berikut ini:
- Memperkenalkan Kluster Big Data SQL Server 2019
- Lokakarya: Arsitektur Data Besar Microsoft SQL Server