Virtualisasikan data CSV dari kumpulan penyimpanan (Kluster Big Data)
Penting
Add-on Kluster Big Data Microsoft SQL Server 2019 akan dihentikan. Dukungan untuk Kluster Big Data SQL Server 2019 akan berakhir pada 28 Februari 2025. Semua pengguna SQL Server 2019 yang ada dengan Jaminan Perangkat Lunak akan didukung penuh pada platform dan perangkat lunak akan terus dipertahankan melalui pembaruan kumulatif SQL Server hingga saat itu. Untuk informasi selengkapnya, lihat posting blog pengumuman dan opsi Big data di platform Microsoft SQL Server.
SQL Server Kluster Big Data dapat memvirtualisasi data dari file CSV dalam HDFS. Proses ini memungkinkan data untuk tetap berada di lokasi aslinya, tetapi dapat dikueri dari instans SQL Server seperti tabel lainnya. Fitur ini menggunakan konektor PolyBase, dan meminimalkan kebutuhan akan proses ETL. Untuk informasi selengkapnya tentang virtualisasi data, lihat Memperkenalkan virtualisasi data dengan PolyBase
Prasyarat
Memilih atau mengunggah file CSV untuk virtualisasi data
Di Azure Data Studio (ADS) sambungkan ke instans master SQL Server Kluster Big Data Anda. Setelah tersambung, perluas elemen HDFS di penjelajah objek untuk menemukan file CSV yang ingin Anda virtualisasikan datanya.
Untuk tujuan tutorial ini, buat direktori baru bernama Data.
- Klik kanan pada menu konteks direktori akar HDFS.
- Pilih Direktori baru.
- Beri nama Data direktori baru.
Unggah data sampel. Untuk panduan sederhana, Anda dapat menggunakan sampel file data csv. Artikel ini menggunakan data penyebab keterlambatan maskapai dari Departemen Transportasi AS. Unduh data mentah, dan ekstrak data ke komputer Anda. Beri nama file airline_delay_causes.csv.
Untuk mengunggah file sampel setelah Anda mengekstraknya:
- Di Azure Data Studio, klik kanan direktori baru yang Anda buat.
- Pilih Unggah file.
Azure Data Studio mengunggah file ke HDFS di Big Data Cluster.
Membuat sumber data eksternal kumpulan penyimpanan di database target Anda
Sumber data eksternal kumpulan penyimpanan tidak dibuat dalam database secara default di Kluster Big Data Anda. Sebelum Anda bisa membuat tabel eksternal, buat Sumber Data Eksternal SqlStoragePool default di database target Anda dengan kueri Transact-SQL berikut ini. Pastikan Anda terlebih dahulu mengubah konteks kueri ke database target Anda.
-- Create the default storage pool source for SQL Big Data Cluster
IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlStoragePool')
CREATE EXTERNAL DATA SOURCE SqlStoragePool
WITH (LOCATION = 'sqlhdfs://controller-svc/default');
Membuat tabel eksternal
Dari ADS, klik kanan file CSV dan pilih Buat Tabel Eksternal Dari File CSV dari menu konteks. Anda juga dapat membuat tabel eksternal dari file CSV dari direktori di HDFS jika file di bawah direktori mengikuti skema yang sama. Ini akan memungkinkan virtualisasi data pada tingkat direktori tanpa perlu memproses file individual dan mendapatkan hasil gabungan yang ditetapkan atas data gabungan. Azure Data Studio memandu Anda melalui langkah-langkah untuk membuat tabel eksternal.
Tentukan database, sumber data, nama tabel, skema, dan nama untuk format file eksternal tabel.
Pilih Selanjutnya.
Pratinjau Data
Azure Data Studio menyediakan pratinjau data yang diimpor.
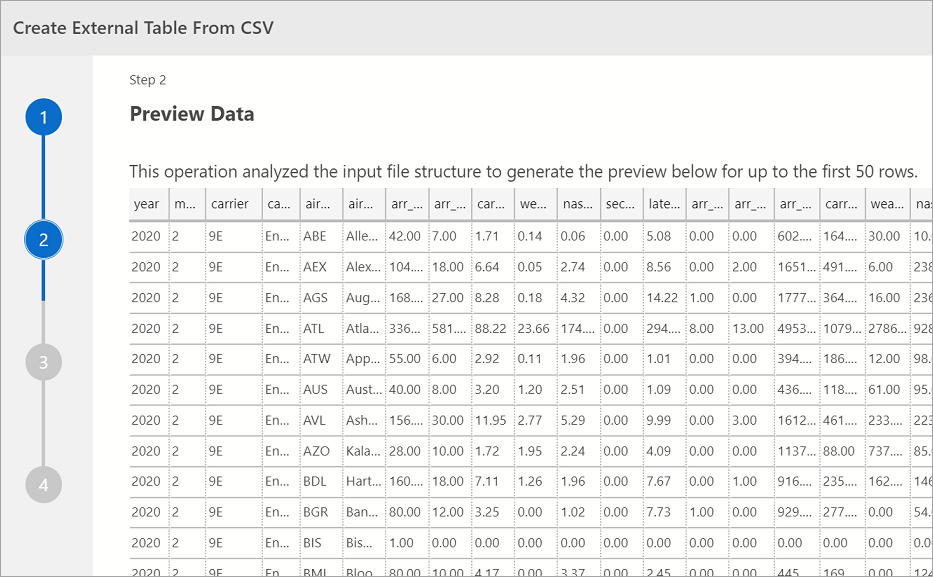
Setelah selesai melihat pratinjau, pilih Berikutnya untuk melanjutkan
Ubah Kolom
Di jendela berikutnya, Anda dapat mengubah kolom tabel eksternal yang ingin Anda buat. Anda dapat mengubah nama kolom, mengubah jenis data dan memungkinkan baris nullable.
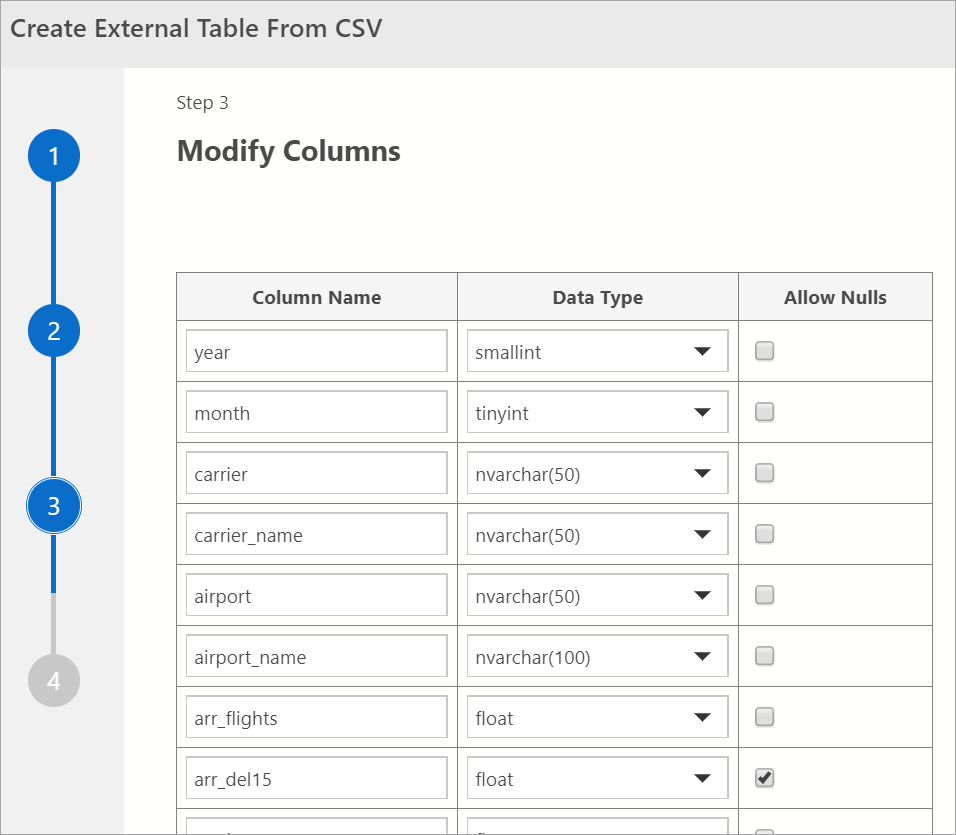
Setelah Anda memverifikasi kolom tujuan, pilih Berikutnya.
Ringkasan
Langkah ini menyediakan ringkasan pilihan Anda. Ini menyediakan nama SQL Server, nama database, nama tabel, skema tabel, dan informasi tabel eksternal. Dalam langkah ini, Anda memiliki opsi untuk membuat skrip atau membuat tabel. Hasilkan Skrip membuat skrip di T-SQL untuk membuat sumber data eksternal. Buat Tabel membuat sumber data eksternal.
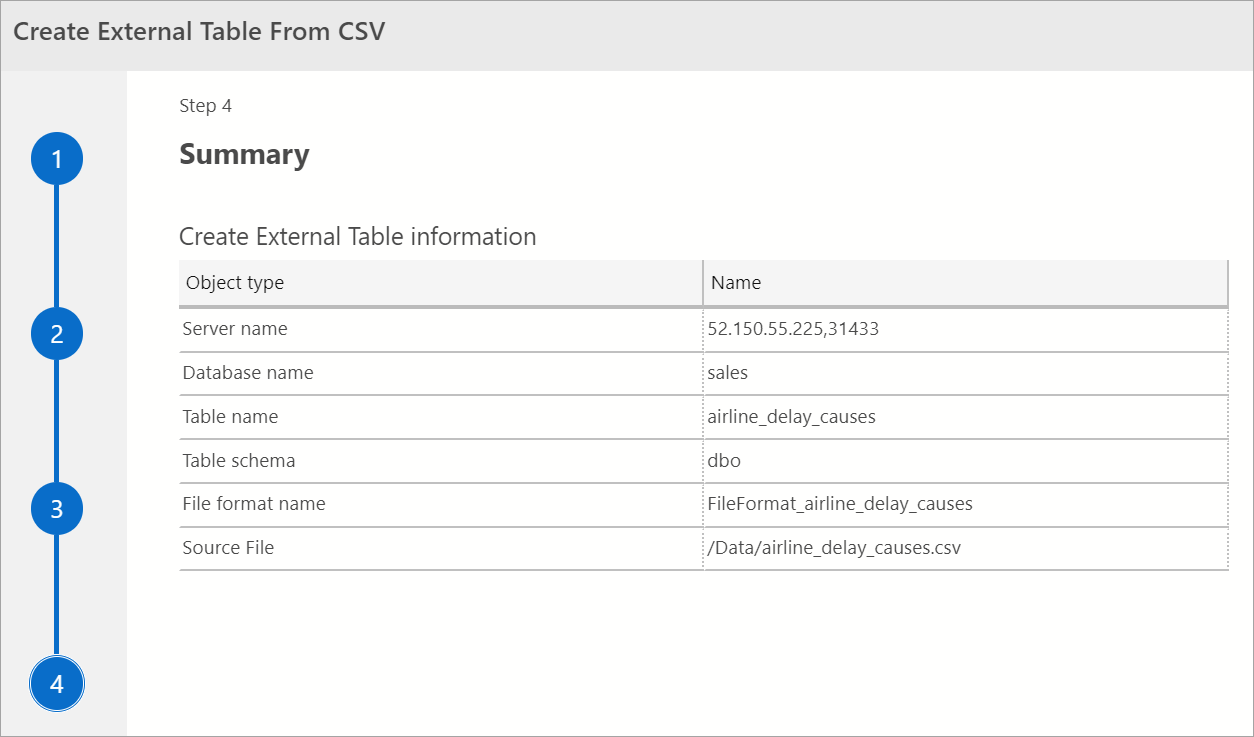
Jika Anda memilih Buat Tabel, SQL Server membuat tabel eksternal di database tujuan.
Jika Anda memilih, Buat Skrip, Azure Data Studio Anda membuat kueri T-SQL untuk membuat tabel eksternal.
Setelah dibuat, tabel sekarang dapat dikueri langsung menggunakan T-SQL dari instans SQL Server.
Langkah berikutnya
Untuk informasi selengkapnya tentang SQL Server Kluster Big Data dan skenario terkait, lihat Memperkenalkan SQL Server Kluster Big Data.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk