Mengirimkan pekerjaan Spark di SQL Server Kluster Big Data di Azure Data Studio
Berlaku untuk: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Penting
Add-on Kluster Big Data Microsoft SQL Server 2019 akan dihentikan. Dukungan untuk SQL Server 2019 Kluster Big Data akan berakhir pada 28 Februari 2025. Semua pengguna SQL Server 2019 yang ada dengan Jaminan Perangkat Lunak akan didukung sepenuhnya pada platform dan perangkat lunak akan terus dipertahankan melalui pembaruan kumulatif SQL Server hingga saat itu. Untuk informasi selengkapnya, lihat posting blog pengumuman dan Opsi big data di platform Microsoft SQL Server.
Salah satu skenario utama untuk kluster big data adalah kemampuan untuk mengirimkan pekerjaan Spark untuk SQL Server. Fitur pengiriman pekerjaan Spark memungkinkan Anda mengirimkan file Jar atau Py lokal dengan referensi ke kluster big data SQL Server 2019. Ini juga memungkinkan Anda untuk menjalankan file Jar atau Py, yang sudah terletak di sistem file HDFS.
Prasyarat
Alat big data SQL Server 2019:
- Azure Data Studio
- Ekstensi SQL Server 2019
- kubectl
Sambungkan Azure Data Studio ke gateway HDFS/Spark dari kluster big data Anda.
Membuka dialog pengiriman pekerjaan Spark
Ada beberapa cara untuk membuka dialog pengiriman pekerjaan Spark. Caranya termasuk Dasbor, Menu Konteks di Object Explorer, dan Palet Perintah.
Untuk membuka dialog pengiriman pekerjaan Spark, klik Pekerjaan Spark Baru di dasbor.
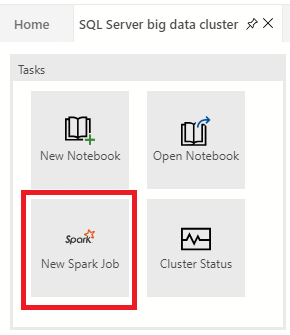
Atau klik kanan pada kluster di Object Explorer dan pilih Kirim Pekerjaan Spark dari menu konteks.
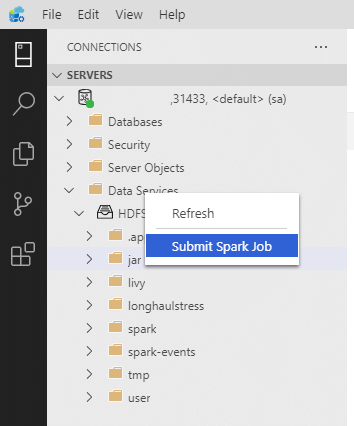
Untuk membuka dialog pengiriman pekerjaan Spark dengan bidang Jar/Py yang telah diisi sebelumnya, klik kanan pada file Jar/Py di Object Explorer dan pilih Kirim Pekerjaan Spark dari menu konteks.
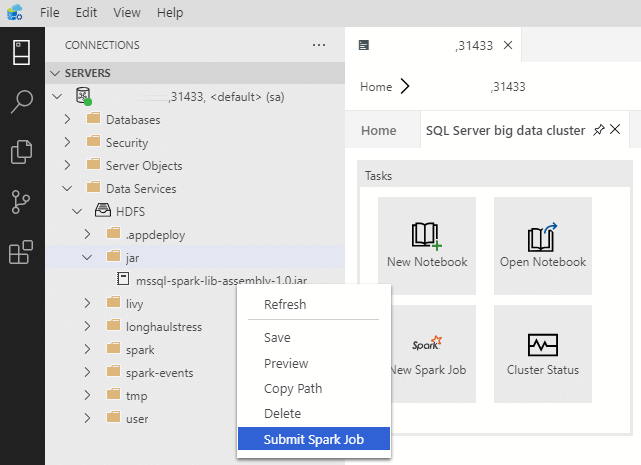
Gunakan Kirim Pekerjaan Spark dari palet perintah dengan mengetik Ctrl+Shift+P (di Windows) dan Cmd+Shift+P (di Mac).

Kirim pekerjaan Spark
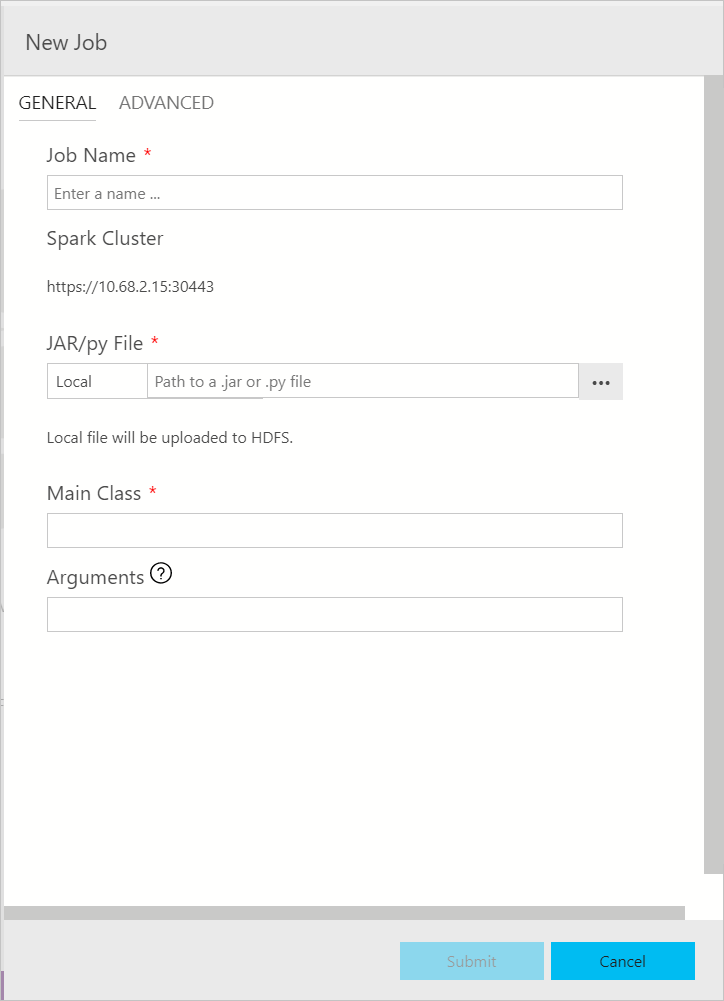
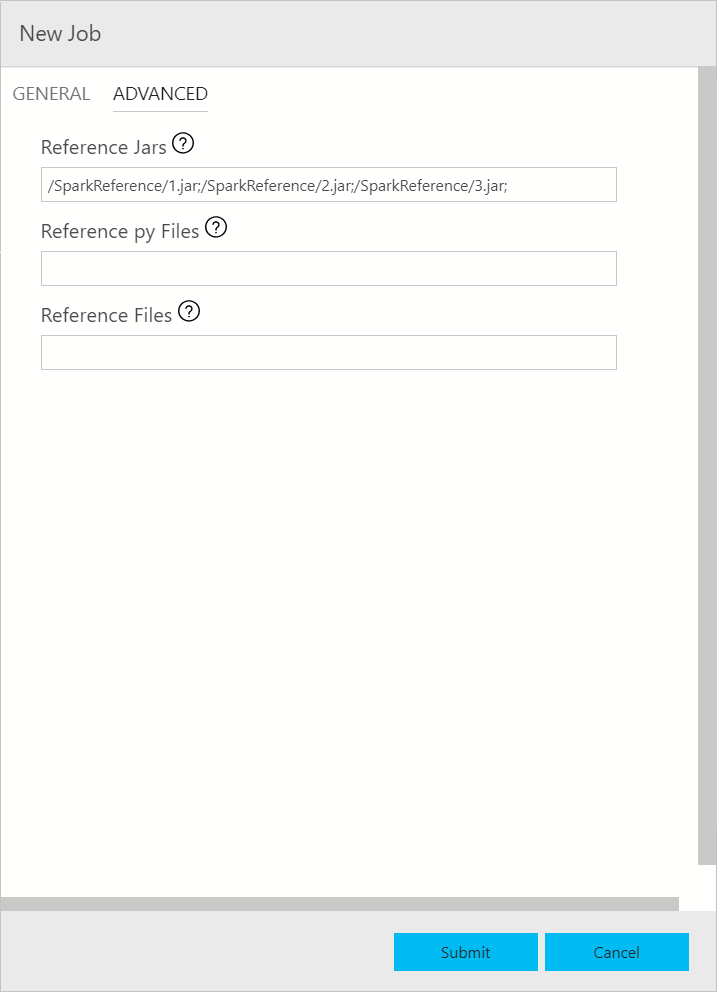
Dialog pengiriman pekerjaan Spark ditampilkan sebagai berikut. Masukkan Nama pekerjaan, jalur file JAR/Py, kelas utama, dan bidang lainnya. Sumber file Jar/Py bisa dari Lokal atau dari HDFS. Jika pekerjaan Spark memiliki Jar referensi, file Py, atau file tambahan, klik tab ADVANCED dan masukkan jalur file yang sesuai. Klik Kirim untuk mengirimkan pekerjaan Spark.
Memantau pengiriman pekerjaan Spark
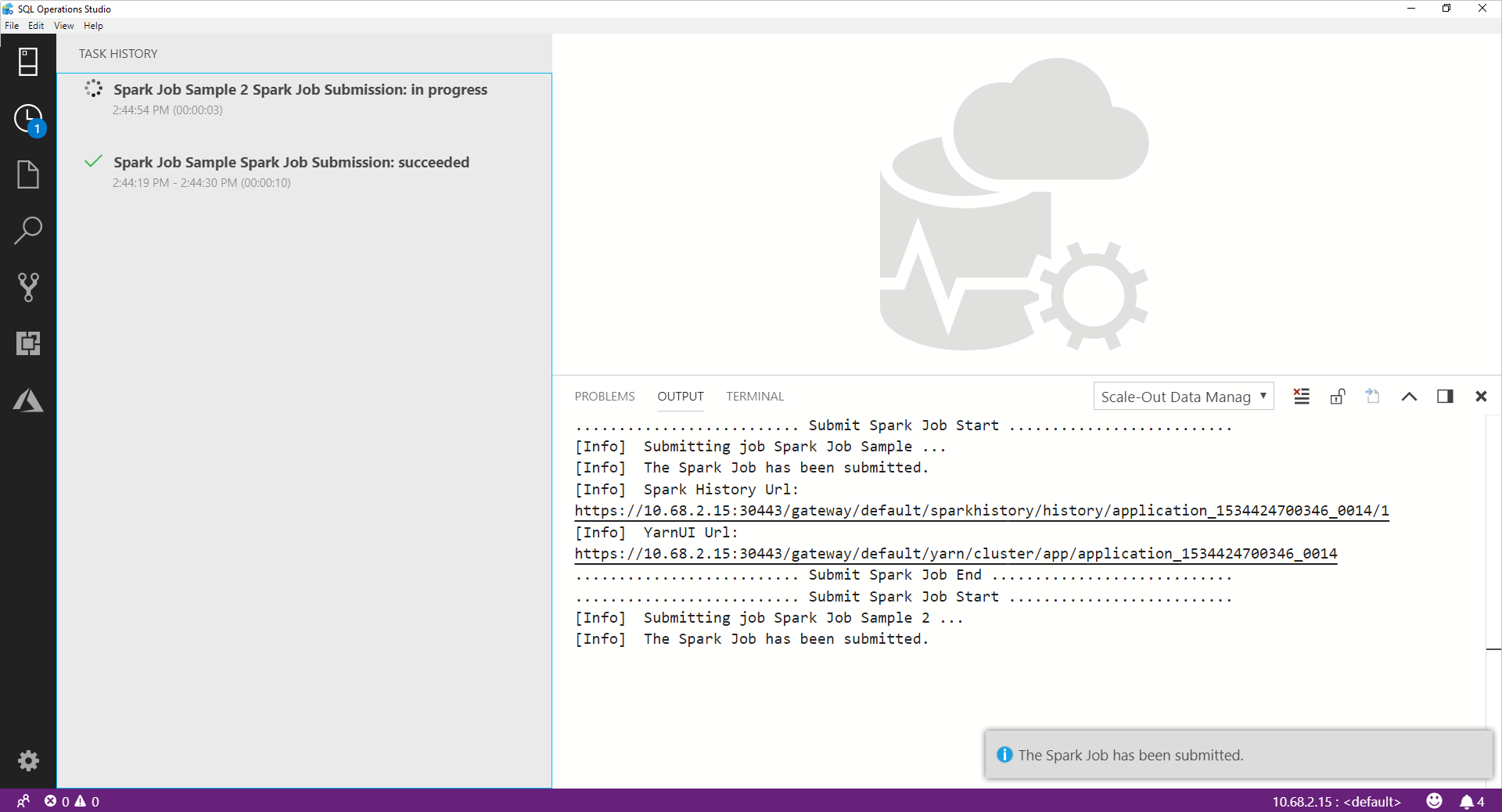
Setelah pekerjaan Spark dikirimkan, informasi status pengiriman dan eksekusi pekerjaan Spark ditampilkan di Riwayat Tugas di sebelah kiri. Detail tentang kemajuan dan log juga ditampilkan di jendela OUTPUT di bagian bawah.
Saat pekerjaan Spark sedang berlangsung, panel Riwayat Tugas dan jendela OUTPUT di-refresh dengan kemajuan.
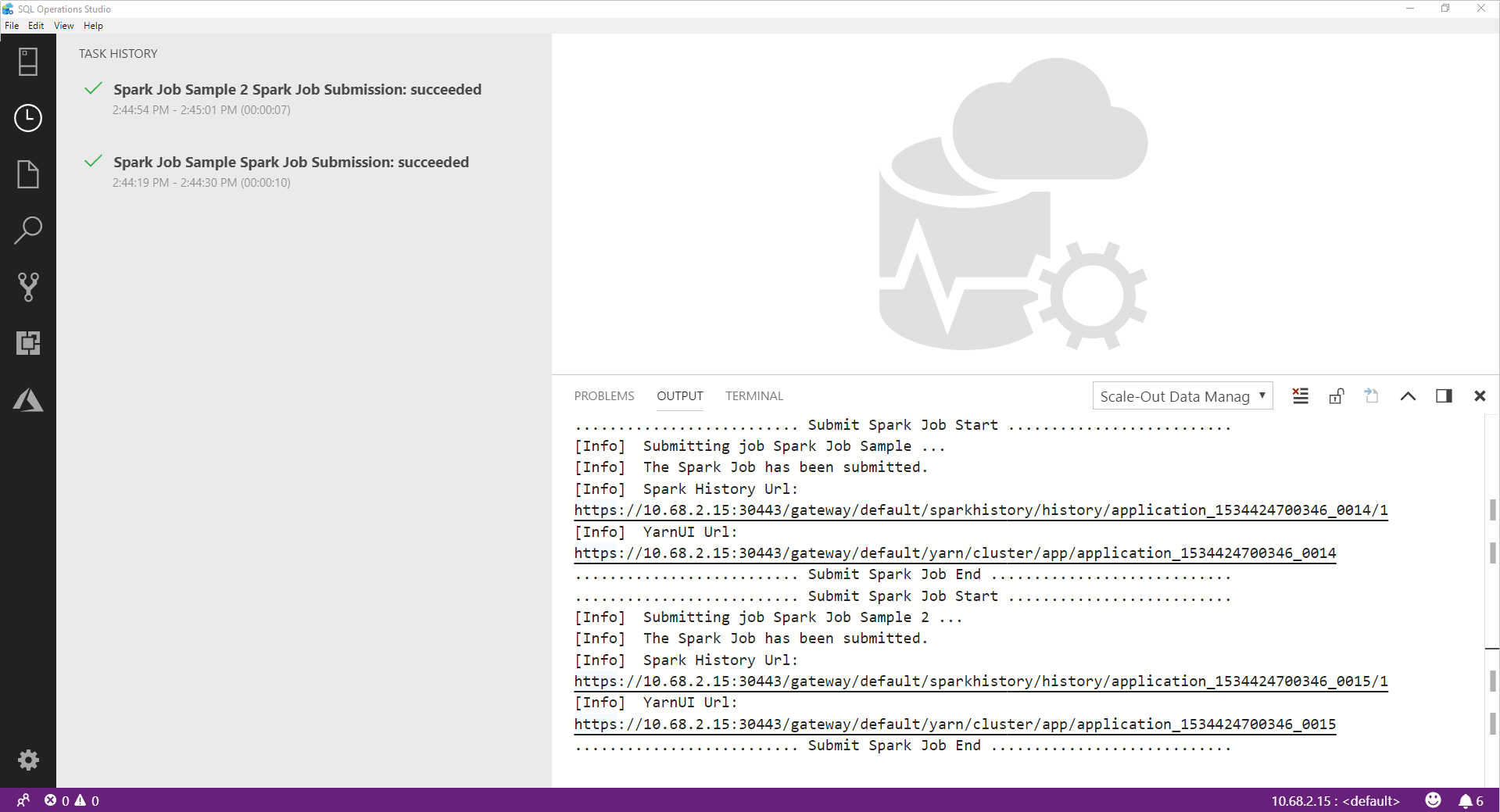
Ketika pekerjaan Spark berhasil diselesaikan, tautan UI Spark dan Yarn UI muncul di jendela OUTPUT . Klik tautan untuk informasi selengkapnya.
Langkah berikutnya
Untuk informasi selengkapnya tentang kluster big data SQL Server dan skenario terkait, lihat Memperkenalkan SQL Server Kluster Big Data.