Mengonfigurasi grup ketersediaan terdistribusi AlwaysOn
Berlaku untuk:![]() SQL Server
SQL Server
Untuk membuat grup ketersediaan terdistribusi, Anda harus membuat dua grup ketersediaan masing-masing dengan pendengarnya sendiri. Anda kemudian menggabungkan grup ketersediaan ini ke dalam grup ketersediaan terdistribusi. Langkah-langkah berikut memberikan contoh dasar dalam Transact-SQL. Contoh ini tidak mencakup semua detail pembuatan grup ketersediaan dan pendengar; sebaliknya, ia berfokus pada menyoroti persyaratan utama.
Untuk gambaran umum teknis grup ketersediaan terdistribusi, lihat Grup ketersediaan terdistribusi.
Prasyarat
Jika Anda mengonfigurasi pendengar untuk grup ketersediaan di SQL Server di Azure VM dengan menggunakan nama jaringan terdistribusi (DNN), maka mengonfigurasi grup ketersediaan terdistribusi di atas grup ketersediaan Anda tidak didukung. Untuk mempelajari selengkapnya, lihat SQL Server interoperabilitas fitur Azure VM dengan pendengar AG dan DNN.
Mengatur pendengar titik akhir untuk mendengarkan semua alamat IP
Pastikan titik akhir dapat berkomunikasi antara grup ketersediaan yang berbeda dalam grup ketersediaan terdistribusi. Jika satu grup ketersediaan diatur ke jaringan tertentu pada titik akhir, grup ketersediaan terdistribusi tidak berfungsi dengan baik. Di setiap server yang menghosting replika di grup ketersediaan terdistribusi, atur pendengar untuk mendengarkan semua alamat IP (LISTENER_IP = ALL).
Membuat titik akhir untuk mendengarkan semua alamat IP
Misalnya, skrip berikut membuat titik akhir pendengar pada port TCP 5022 yang mendengarkan di semua alamat IP.
CREATE ENDPOINT [aodns-hadr]
STATE=STARTED
AS TCP (LISTENER_PORT = 5022, LISTENER_IP = ALL)
FOR DATA_MIRRORING (
ROLE = ALL,
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES
)
GO
Mengubah titik akhir untuk mendengarkan semua alamat IP
Misalnya, skrip berikut mengubah titik akhir pendengar untuk mendengarkan semua alamat IP.
ALTER ENDPOINT [aodns-hadr]
AS TCP (LISTENER_IP = ALL)
GO
Membuat grup ketersediaan pertama
Membuat grup ketersediaan utama pada kluster pertama
Buat grup ketersediaan pada Kluster Failover Windows Server (WSFC) pertama. Dalam contoh ini, grup ketersediaan dinamai ag1 untuk database db1. Replika utama grup ketersediaan utama dikenal sebagai primer global dalam grup ketersediaan terdistribusi. Server1 adalah primer global dalam contoh ini.
CREATE AVAILABILITY GROUP [ag1]
FOR DATABASE db1
REPLICA ON N'server1' WITH (ENDPOINT_URL = N'TCP://server1.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server2' WITH (ENDPOINT_URL = N'TCP://server2.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Catatan
Contoh sebelumnya menggunakan seeding otomatis, di mana SEEDING_MODE diatur ke OTOMATIS untuk replika dan grup ketersediaan terdistribusi. Konfigurasi ini mengatur replika sekunder dan grup ketersediaan sekunder untuk diisi secara otomatis tanpa memerlukan pencadangan manual dan pemulihan database utama.
Menggabungkan replika sekunder ke grup ketersediaan utama
Setiap replika sekunder harus bergabung ke grup ketersediaan dengan UBAH GRUP KETERSEDIAAN dengan opsi JOIN . Karena seeding otomatis digunakan dalam contoh ini, Anda juga harus memanggil ALTER AVAILABILITY GROUP dengan opsi GRANT CREATE ANY DATABASE . Pengaturan ini memungkinkan grup ketersediaan untuk membuat database dan mulai menyemainya secara otomatis dari replika utama.
Dalam contoh ini, perintah berikut dijalankan pada replika sekunder, server2, untuk bergabung dengan ag1 grup ketersediaan. Grup ketersediaan kemudian diizinkan untuk membuat database di sekunder.
ALTER AVAILABILITY GROUP [ag1] JOIN
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE
GO
Catatan
Saat grup ketersediaan membuat database pada replika sekunder, grup tersebut menetapkan pemilik database sebagai akun yang menjalankan ALTER AVAILABILITY GROUP pernyataan untuk memberikan izin untuk membuat database apa pun. Untuk informasi selengkapnya, lihat Memberikan izin buat database pada replika sekunder ke grup ketersediaan.
Membuat pendengar untuk grup ketersediaan utama
Selanjutnya tambahkan pendengar untuk grup ketersediaan utama pada WSFC pertama. Dalam contoh ini, pendengar diberi nama ag1-listener. Untuk petunjuk terperinci tentang membuat pendengar, lihat Membuat atau Mengonfigurasi Listener Grup Ketersediaan (SQL Server).
ALTER AVAILABILITY GROUP [ag1]
ADD LISTENER 'ag1-listener' (
WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) ,
PORT = 60173);
GO
Membuat grup ketersediaan kedua
Kemudian pada WSFC kedua, buat grup ketersediaan kedua, ag2. Dalam hal ini, database tidak ditentukan, karena secara otomatis disemai dari grup ketersediaan utama. Replika utama grup ketersediaan sekunder dikenal sebagai penerus dalam grup ketersediaan terdistribusi. Dalam contoh ini, server3 adalah penerus.
CREATE AVAILABILITY GROUP [ag2]
FOR
REPLICA ON N'server3' WITH (ENDPOINT_URL = N'TCP://server3.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server4' WITH (ENDPOINT_URL = N'TCP://server4.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Catatan
Grup ketersediaan sekunder harus menggunakan titik akhir pencerminan database yang sama (dalam contoh port 5022 ini). Jika tidak, replikasi akan berhenti setelah failover lokal.
Menggabungkan replika sekunder ke grup ketersediaan sekunder
Dalam contoh ini, perintah berikut dijalankan pada replika sekunder, server4, untuk bergabung dengan ag2 grup ketersediaan. Grup ketersediaan kemudian diizinkan untuk membuat database di sekunder untuk mendukung seeding otomatis.
ALTER AVAILABILITY GROUP [ag2] JOIN
ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE
GO
Membuat pendengar untuk grup ketersediaan sekunder
Selanjutnya tambahkan pendengar untuk grup ketersediaan sekunder pada WSFC kedua. Dalam contoh ini, pendengar diberi nama ag2-listener. Untuk petunjuk terperinci tentang membuat pendengar, lihat Membuat atau Mengonfigurasi Listener Grup Ketersediaan (SQL Server).
ALTER AVAILABILITY GROUP [ag2]
ADD LISTENER 'ag2-listener' ( WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) , PORT = 60173);
GO
Membuat grup ketersediaan terdistribusi pada kluster pertama
Pada WSFC pertama, buat grup ketersediaan terdistribusi (dinamai distributedag dalam contoh ini). Gunakan perintah CREATE AVAILABILITY GROUP dengan opsi DISTRIBUTED . Parameter AVAILABILITY GROUP ON menentukan grup ag1 ketersediaan anggota dan ag2.
Untuk membuat grup ketersediaan terdistribusi Anda menggunakan seeding otomatis, gunakan kode Transact-SQL berikut:
CREATE AVAILABILITY GROUP [distributedag]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Catatan
LISTENER_URL menentukan pendengar untuk setiap grup ketersediaan bersama dengan titik akhir pencerminan database dari grup ketersediaan. Dalam contoh ini, yaitu port 5022 (bukan port 60173 yang digunakan untuk membuat listener). Jika Anda menggunakan load balancer, misalnya di Azure, tambahkan aturan penyeimbangan beban untuk port grup ketersediaan terdistribusi. Tambahkan aturan untuk port pendengar, selain port instans SQL Server.
Batalkan seeding otomatis ke penerus
Jika, karena alasan apa pun, perlu untuk membatalkan inisialisasi penerus sebelum dua grup ketersediaan disinkronkan, UBAH grup ketersediaan terdistribusi dengan mengatur parameter SEEDING_MODE penerus ke MANUAL dan segera membatalkan seeding. Jalankan perintah pada primer global:
-- Cancel automatic seeding. Connect to global primary but specify DAG AG2
ALTER AVAILABILITY GROUP [distributedag]
MODIFY
AVAILABILITY GROUP ON
'ag2' WITH
( SEEDING_MODE = MANUAL );
Bergabung dengan grup ketersediaan terdistribusi pada kluster kedua
Kemudian bergabunglah dengan grup ketersediaan terdistribusi pada WSFC kedua.
Untuk bergabung dengan grup ketersediaan terdistribusi Anda menggunakan seeding otomatis, gunakan kode Transact-SQL berikut:
ALTER AVAILABILITY GROUP [distributedag]
JOIN
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Bergabung dengan database di sekunder grup ketersediaan kedua
Jika grup ketersediaan kedua disiapkan untuk menggunakan seeding otomatis, lanjutkan ke langkah 2.
- Jika grup ketersediaan kedua menggunakan seeding manual, maka pulihkan cadangan yang Anda ambil di primer global ke sekunder grup ketersediaan kedua:
RESTORE DATABASE [db1]
FROM DISK = '<full backup location>' WITH NORECOVERY
RESTORE LOG [db1] FROM DISK = '<log backup location>' WITH NORECOVERY
- Setelah database pada replika sekunder grup ketersediaan kedua dalam status pemulihan, Anda harus menggabungkannya secara manual ke grup ketersediaan.
ALTER DATABASE [db1] SET HADR AVAILABILITY GROUP = [ag2];
Failover ke grup ketersediaan sekunder
Ada dua set instruksi yang berbeda untuk melakukan failover ke grup ketersediaan sekunder. Gunakan instruksi yang sesuai untuk versi dan konfigurasi Anda.
Instruksi di bawah ini berlaku untuk SQL Server 2022 (16.x) atau yang lebih baru, jika REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT diatur.
Untuk konfigurasi lain, lihat Failover ke sekunder (sebelum SQL Server 2022).
Instruksi di bawah ini berlaku jika REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT tidak diatur untuk grup ketersediaan terdistribusi. Ini termasuk versi sebelum SQL Server 2022 (16.x) karena pengaturan ini tidak didukung untuk grup ketersediaan terdistribusi.
Pada SQL Server 2022 (16.x) atau yang lebih baru Anda dapat mengatur REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT. Jika pengaturan ini dikonfigurasi, ikuti instruksi untuk Failover ke grup ketersediaan sekunder (SQL Server 2022 dan yang lebih baru).
Failover ke sekunder (sebelum SQL Server 2022)
Hanya failover manual yang didukung saat ini. Untuk melakukan failover grup ketersediaan terdistribusi secara manual:
- Untuk memastikan bahwa tidak ada data yang hilang, hentikan semua transaksi pada database utama global (yaitu, database grup ketersediaan utama), lalu atur grup ketersediaan terdistribusi ke penerapan sinkron.
- Tunggu hingga grup ketersediaan terdistribusi disinkronkan dan memiliki last_hardened_lsn per database yang sama.
- Pada replika utama global, atur peran grup ketersediaan terdistribusi ke
SECONDARY. - Uji kesiapan failover.
- Failover grup ketersediaan utama.
Contoh Transact-SQL berikut menunjukkan langkah-langkah terperinci untuk melakukan failover pada grup ketersediaan terdistribusi bernama distributedag:
Untuk memastikan bahwa tidak ada data yang hilang, hentikan semua transaksi pada database utama global (yaitu, database grup ketersediaan utama). Kemudian atur grup ketersediaan terdistribusi ke penerapan sinkron dengan menjalankan kode berikut pada primer global dan penerus.
-- sets the distributed availability group to synchronous commit ALTER AVAILABILITY GROUP [distributedag] MODIFY AVAILABILITY GROUP ON 'ag1' WITH ( AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ), 'ag2' WITH ( AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ); -- verifies the commit state of the distributed availability group select ag.name, ag.is_distributed, ar.replica_server_name, ar.availability_mode_desc, ars.connected_state_desc, ars.role_desc, ars.operational_state_desc, ars.synchronization_health_desc from sys.availability_groups ag join sys.availability_replicas ar on ag.group_id=ar.group_id left join sys.dm_hadr_availability_replica_states ars on ars.replica_id=ar.replica_id where ag.is_distributed=1 GOCatatan
Dalam grup ketersediaan terdistribusi, status sinkronisasi antara dua grup ketersediaan tergantung pada mode ketersediaan kedua replika. Untuk mode penerapan sinkron, grup ketersediaan utama saat ini, dan grup ketersediaan sekunder saat ini harus memiliki
SYNCHRONOUS_COMMITmode ketersediaan. Untuk alasan ini, Anda harus menjalankan skrip di atas pada replika utama global, dan penerus.Tunggu hingga status grup ketersediaan terdistribusi berubah menjadi
SYNCHRONIZEDdan semua replika memiliki last_hardened_lsn yang sama (per database). Jalankan kueri berikut pada primer global, yang merupakan replika utama grup ketersediaan utama, dan penerus untuk memeriksa synchronization_state_desc dan last_hardened_lsn:-- Run this query on the Global Primary and the forwarder -- Check the results to see if synchronization_state_desc is SYNCHRONIZED, and the last_hardened_lsn is the same per database on both the global primary and forwarder -- If not rerun the query on both side every 5 seconds until it is the case -- SELECT ag.name , drs.database_id , db_name(drs.database_id) as database_name , drs.group_id , drs.replica_id , drs.synchronization_state_desc , drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states drs INNER JOIN sys.availability_groups ag on drs.group_id = ag.group_id;Lanjutkan setelah grup ketersediaan synchronization_state_desc adalah
SYNCHRONIZED, dan last_hardened_lsn sama per database pada primer global dan penerus. Jika synchronization_state_desc tidakSYNCHRONIZEDatau last_hardened_lsn tidak sama, jalankan perintah setiap lima detik hingga berubah. Jangan lanjutkan sampai synchronization_state_desc =SYNCHRONIZEDdan last_hardened_lsn sama per database.Pada primer global, atur peran grup ketersediaan terdistribusi ke
SECONDARY.ALTER AVAILABILITY GROUP distributedag SET (ROLE = SECONDARY);Pada titik ini, grup ketersediaan terdistribusi tidak tersedia.
Uji kesiapan failover. Jalankan kueri berikut pada primer global dan penerus:
-- Run this query on the Global Primary and the forwarder -- Check the results to see if the last_hardened_lsn is the same per database on both the global primary and forwarder -- The availability group is ready to fail over when the last_hardened_lsn is the same for both availability groups per database -- SELECT ag.name, drs.database_id, db_name(drs.database_id) as database_name, drs.group_id, drs.replica_id, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states drs INNER JOIN sys.availability_groups ag ON drs.group_id = ag.group_id;Grup ketersediaan siap untuk failover ketika last_hardened_lsn sama untuk kedua grup ketersediaan per database. Jika last_hardened_lsn tidak sama setelah jangka waktu tertentu, untuk menghindari kehilangan data, failback ke primer global dengan menjalankan perintah ini pada primer global dan kemudian memulai kembali dari langkah kedua:
-- If the last_hardened_lsn is not the same after a period of time, to avoid data loss, -- we need to fail back to the global primary by running this command on the global primary -- and then start over from the second step: ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS;Failover dari grup ketersediaan utama ke grup ketersediaan sekunder. Jalankan perintah berikut pada penerus, SQL Server yang menghosting replika utama grup ketersediaan sekunder.
-- Once the last_hardened_lsn is the same per database on both sides -- We can Fail over from the primary availability group to the secondary availability group. -- Run the following command on the forwarder, the SQL Server instance that hosts the primary replica of the secondary availability group. ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS;Setelah langkah ini, grup ketersediaan terdistribusi tersedia.
Setelah menyelesaikan langkah-langkah di atas, grup ketersediaan terdistribusi gagal tanpa kehilangan data. Jika grup ketersediaan berada di seluruh jarak geografis yang menyebabkan latensi, ubah mode ketersediaan kembali ke ASYNCHRONOUS_COMMIT.
Failover ke grup ketersediaan sekunder (SQL Server 2022 dan yang lebih baru)
Langkah-langkah di bagian ini dirancang untuk menjamin tidak ada kehilangan data saat grup ketersediaan terdistribusi gagal. Langkah-langkahnya termasuk pengaturan REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT. Dukungan untuk pengaturan ini untuk grup ketersediaan terdistribusi dimulai dengan SQL Server 2022 (16.x).
Hanya failover manual yang didukung saat ini. Untuk melakukan failover grup ketersediaan terdistribusi secara manual:
- Untuk memastikan bahwa tidak ada data yang hilang, hentikan semua transaksi pada database utama global (yaitu, database grup ketersediaan utama), lalu atur grup ketersediaan terdistribusi ke penerapan sinkron.
- Tunggu hingga grup ketersediaan terdistribusi disinkronkan dan memiliki last_hardened_lsn per database yang sama.
- Pada replika utama global, atur peran grup ketersediaan terdistribusi ke
SECONDARY.
Penting
Pada titik ini, grup ketersediaan terdistribusi tidak tersedia.
- Atur grup ketersediaan terdistribusi REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT ke 1.
- Uji kesiapan failover.
- Failover grup ketersediaan utama.
- Atur grup ketersediaan terdistribusi REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT ke 0.
Contoh Transact-SQL berikut menunjukkan langkah-langkah terperinci untuk melakukan failover pada grup ketersediaan terdistribusi bernama distributedag:
Untuk memastikan bahwa tidak ada data yang hilang, hentikan semua transaksi pada database utama global (yaitu, database grup ketersediaan utama). Kemudian atur grup ketersediaan terdistribusi ke penerapan sinkron dengan menjalankan kode berikut pada primer global dan penerus.
-- sets the distributed availability group to synchronous commit ALTER AVAILABILITY GROUP [distributedag] MODIFY AVAILABILITY GROUP ON 'ag1' WITH ( AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ), 'ag2' WITH ( AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ); -- verifies the commit state of the distributed availability group select ag.name, ag.is_distributed, ar.replica_server_name, ar.availability_mode_desc, ars.connected_state_desc, ars.role_desc, ars.operational_state_desc, ars.synchronization_health_desc from sys.availability_groups ag join sys.availability_replicas ar on ag.group_id=ar.group_id left join sys.dm_hadr_availability_replica_states ars on ars.replica_id=ar.replica_id where ag.is_distributed=1 GOCatatan
Dalam grup ketersediaan terdistribusi, status sinkronisasi antara dua grup ketersediaan tergantung pada mode ketersediaan kedua replika. Untuk mode penerapan sinkron, grup ketersediaan utama saat ini, dan grup ketersediaan sekunder saat ini harus memiliki
SYNCHRONOUS_COMMITmode ketersediaan. Untuk alasan ini, Anda harus menjalankan skrip di atas pada replika utama global, dan penerus.Tunggu hingga status grup ketersediaan terdistribusi berubah menjadi
SYNCHRONIZEDdan semua replika memiliki last_hardened_lsn yang sama (per database). Jalankan kueri berikut pada primer global, yang merupakan replika utama grup ketersediaan utama, dan penerus untuk memeriksa synchronization_state_desc dan last_hardened_lsn:-- Run this query on the Global Primary and the forwarder -- Check the results to see if synchronization_state_desc is SYNCHRONIZED, and the last_hardened_lsn is the same per database on both the global primary and forwarder -- If not rerun the query on both side every 5 seconds until it is the case -- SELECT ag.name , drs.database_id , db_name(drs.database_id) as database_name , drs.group_id , drs.replica_id , drs.synchronization_state_desc , drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states drs INNER JOIN sys.availability_groups ag on drs.group_id = ag.group_id;Lanjutkan setelah grup ketersediaan synchronization_state_desc adalah
SYNCHRONIZED, dan last_hardened_lsn sama per database pada primer global dan penerus. Jika synchronization_state_desc tidakSYNCHRONIZEDatau last_hardened_lsn tidak sama, jalankan perintah setiap lima detik hingga berubah. Jangan lanjutkan sampai synchronization_state_desc =SYNCHRONIZEDdan last_hardened_lsn sama per database.Pada primer global, atur peran grup ketersediaan terdistribusi ke
SECONDARY.ALTER AVAILABILITY GROUP distributedag SET (ROLE = SECONDARY);Pada titik ini, grup ketersediaan terdistribusi tidak tersedia.
Untuk SQL Server 2022 (16.x) dan yang lebih baru, pada primer global, atur REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT.
ALTER AVAILABILITY GROUP distributedag SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Uji kesiapan failover. Jalankan kueri berikut pada primer global dan penerus:
-- Run this query on the Global Primary and the forwarder -- Check the results to see if the last_hardened_lsn is the same per database on both the global primary and forwarder -- The availability group is ready to fail over when the last_hardened_lsn is the same for both availability groups per database -- SELECT ag.name, drs.database_id, db_name(drs.database_id) as database_name, drs.group_id, drs.replica_id, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states drs INNER JOIN sys.availability_groups ag ON drs.group_id = ag.group_id;Grup ketersediaan siap untuk failover ketika last_hardened_lsn sama untuk kedua grup ketersediaan per database. Jika last_hardened_lsn tidak sama setelah jangka waktu tertentu, untuk menghindari kehilangan data, failback ke primer global dengan menjalankan perintah ini pada primer global dan kemudian memulai kembali dari langkah kedua:
-- If the last_hardened_lsn is not the same after a period of time, to avoid data loss, -- we need to fail back to the global primary by running this command on the global primary -- and then start over from the second step: ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS;Failover dari grup ketersediaan utama ke grup ketersediaan sekunder. Jalankan perintah berikut pada penerus, SQL Server yang menghosting replika utama grup ketersediaan sekunder.
-- Once the last_hardened_lsn is the same per database on both sides -- We can Fail over from the primary availability group to the secondary availability group. -- Run the following command on the forwarder, the SQL Server instance that hosts the primary replica of the secondary availability group. ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS;Setelah langkah ini, grup ketersediaan terdistribusi tersedia.
Untuk SQL Server 2022 (16.x) dan yang lebih baru, bersihkan REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT grup ketersediaan terdistribusi.
ALTER AVAILABILITY GROUP distributedag SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0);
Setelah menyelesaikan langkah-langkah di atas, grup ketersediaan terdistribusi gagal tanpa kehilangan data. Jika grup ketersediaan berada di seluruh jarak geografis yang menyebabkan latensi, ubah mode ketersediaan kembali ke ASYNCHRONOUS_COMMIT.
Menghapus grup ketersediaan terdistribusi
Pernyataan Transact-SQL berikut menghapus grup ketersediaan terdistribusi bernama distributedag:
DROP AVAILABILITY GROUP [distributedag]
Membuat grup ketersediaan terdistribusi pada instans kluster failover
Anda dapat membuat grup ketersediaan terdistribusi menggunakan grup ketersediaan pada instans kluster failover (FCI). Dalam hal ini, Anda tidak memerlukan listener grup ketersediaan. Gunakan nama jaringan virtual (VNN) untuk replika utama instans FCI. Contoh berikut menunjukkan grup ketersediaan terdistribusi yang disebut SQLFCIDAG. Salah satu grup ketersediaan adalah SQLFCIAG. SQLFCIAG memiliki dua replika FCI. VNN untuk replika FCI utama adalah SQLFCIAG-1, dan VNN untuk replika FCI sekunder adalah SQLFCIAG-2. Grup ketersediaan terdistribusi juga mencakup SQLAG-DR, untuk pemulihan bencana.
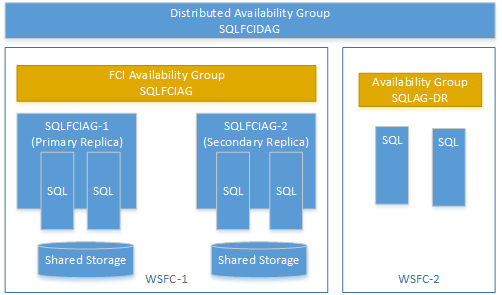
DDL berikut membuat grup ketersediaan terdistribusi ini.
CREATE AVAILABILITY GROUP [SQLFCIDAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-1.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'SQLAG-DR' WITH
(
LISTENER_URL = 'tcp://SQLAG-DR.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
URL pendengar adalah VNN dari instans FCI utama.
Failover FCI secara manual dalam grup ketersediaan terdistribusi
Untuk melakukan failover grup ketersediaan FCI secara manual, perbarui grup ketersediaan terdistribusi untuk mencerminkan perubahan URL pendengar. Misalnya, jalankan DDL berikut pada primer global AG terdistribusi dan penerus AG terdistribusi SQLFCIDAG:
ALTER AVAILABILITY GROUP [SQLFCIDAG]
MODIFY AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-2.contoso.com:5022'
)
Langkah berikutnya
BUAT GRUP KETERSEDIAAN (Transact-SQL)
UBAH GRUP KETERSEDIAAN (Transact-SQL)
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk