Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk:![]() SQL Server
SQL Server
Grup ketersediaan terdistribusi (AG) adalah jenis grup ketersediaan khusus yang mencakup dua grup ketersediaan terpisah. Grup ketersediaan terdistribusi tersedia dimulai dengan SQL Server 2016.
Artikel ini menjelaskan fitur grup ketersediaan terdistribusi. Untuk mengonfigurasi grup ketersediaan terdistribusi, lihat Mengonfigurasi grup ketersediaan terdistribusi.
Gambaran Umum
Grup ketersediaan terdistribusi adalah jenis khusus grup ketersediaan yang mencakup dua grup ketersediaan terpisah. Grup ketersediaan yang berpartisipasi dalam grup ketersediaan terdistribusi tidak perlu berada di lokasi yang sama. Mereka dapat berupa fisik, virtual, lokal, di cloud publik, atau di mana saja yang mendukung penyebaran grup ketersediaan. Ini termasuk lintas domain dan bahkan lintas platform - seperti antara grup ketersediaan yang dihosting di Linux dan satu yang dihosting di Windows. Selama dua grup ketersediaan dapat berkomunikasi, Anda dapat mengonfigurasi sebuah grup ketersediaan terdistribusi dengan mereka.
Grup ketersediaan tradisional memiliki sumber daya yang dikonfigurasikan dalam Windows Server Failover Cluster (WSFC) atau jika di Linux, Pacemaker. Grup ketersediaan terdistribusi tidak mengonfigurasi apa pun di kluster yang mendasarinya (WSFC atau Pacemaker). Segala sesuatu tentang hal itu dipertahankan dalam SQL Server. Untuk mempelajari cara menampilkan informasi untuk grup ketersediaan terdistribusi, lihat Menampilkan informasi grup ketersediaan terdistribusi.
Grup ketersediaan terdistribusi mengharuskan grup ketersediaan dasar memiliki listener. Daripada memberikan nama server yang mendasar untuk instans mandiri (atau dalam kasus instans kluster failover SQL Server [FCI], nilai yang terkait dengan sumber daya nama jaringan) seperti yang Anda lakukan dengan grup ketersediaan tradisional, Anda menentukan pendengar yang dikonfigurasi untuk grup ketersediaan terdistribusi dengan parameter ENDPOINT_URL saat Anda membuatnya. Meskipun setiap grup ketersediaan yang mendasar dari grup ketersediaan terdistribusi memiliki pendengar, grup ketersediaan terdistribusi tidak memiliki pendengar.
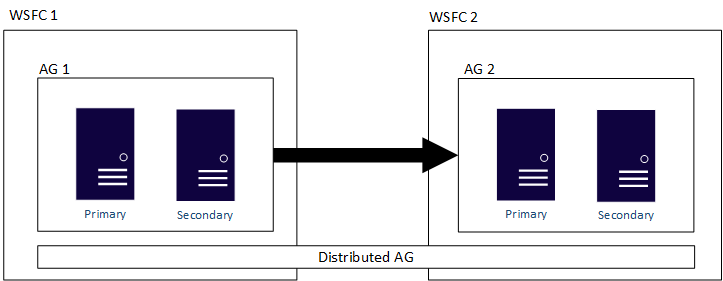
Gambar berikut menunjukkan tampilan tingkat tinggi dari grup ketersediaan terdistribusi yang mencakup dua grup ketersediaan (AG 1 dan AG 2), masing-masing dikonfigurasi pada WSFC sendiri. Grup ketersediaan terdistribusi memiliki total empat replika, dengan dua di setiap grup ketersediaan. Setiap grup ketersediaan dapat mendukung hingga jumlah maksimum replika, sehingga grup ketersediaan terdistribusi dapat memiliki hingga 18 replika total.
Anda dapat mengonfigurasi pergerakan data dalam grup ketersediaan terdistribusi sebagai sinkron atau asinkron. Namun, pergerakan data sedikit berbeda dalam grup ketersediaan terdistribusi dibandingkan dengan grup ketersediaan tradisional. Meskipun setiap grup ketersediaan memiliki replika utama, hanya ada satu salinan database yang berpartisipasi dalam grup ketersediaan terdistribusi yang dapat menerima penyisipan, pembaruan, dan penghapusan. Seperti yang ditunjukkan pada gambar berikut, AG 1 adalah grup ketersediaan utama. Replika utamanya mengirimkan transaksi ke replika sekunder AG 1 dan replika utama AG 2. Replika utama AG 2 juga dikenal sebagai penerus. Pengirim adalah replika utama dalam grup ketersediaan sekunder dalam grup ketersediaan terdistribusi. Penerus menerima transaksi dari replika utama dalam grup ketersediaan utama dan meneruskannya ke replika sekunder dalam grup ketersediaannya sendiri. Pengirim kemudian terus memperbarui replika sekunder AG 2.
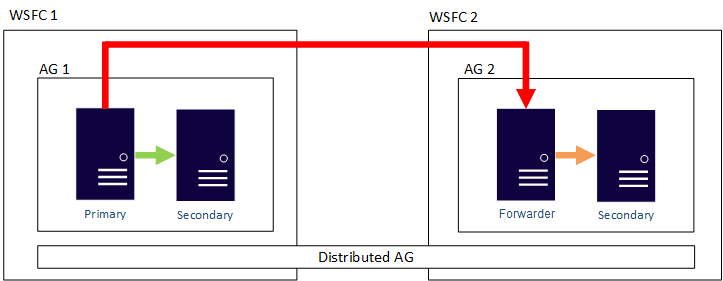
Satu-satunya cara untuk membuat replika utama AG 2 menerima sisipan, pembaruan, dan penghapusan, adalah dengan melakukan failover secara manual atas grup ketersediaan terdistribusi dari AG 1. Pada gambar sebelumnya, karena AG 1 berisi salinan basis data yang dapat ditulis, dengan melakukan failover menjadikan AG 2 kelompok ketersediaan yang dapat menangani penyisipan, pembaruan, dan penghapusan. Untuk informasi tentang cara mengalihkan satu grup ketersediaan terdistribusi ke grup ketersediaan terdistribusi lainnya, lihat Failover ke grup ketersediaan sekunder.
Catatan
- Grup ketersediaan terdistribusi di SQL Server 2016 mendukung failover hanya dari satu grup ketersediaan ke grup ketersediaan lainnya dengan menggunakan opsi
FORCE_FAILOVER_ALLOW_DATA_LOSS. - Saat menggunakan replikasi transaksional dengan grup ketersediaan terdistribusi, replika penerus tidak dapat dikonfigurasi sebagai penerbit.
Perubahan SQL Server 2025
SQL Server 2025 (17.x) memperkenalkan perubahan berikut:
Peningkatan sinkronisasi AG terdistribusi
SQL Server 2025 (17.x) memperkenalkan perubahan pada mekanisme sinkronisasi internal untuk grup ketersediaan terdistribusi untuk meningkatkan performa sinkronisasi dengan mengurangi saturasi jaringan ketika replika penerus dalam mode penerapan asinkron. Perubahan ini diaktifkan secara default dan tidak memerlukan konfigurasi apa pun.
Catatan
Mengonfigurasi grup ketersediaan terdistribusi Anda dengan ketidakcocokan antara mode ketersediaan dari dua grup ketersediaan yang mendasar tidak disarankan, dan dapat memperkenalkan latensi sinkronisasi. Kedua grup ketersediaan harus dikonfigurasi dengan mode ketersediaan yang sama (baik sinkron atau asinkron) untuk memastikan performa dan sinkronisasi yang optimal.
Dukungan untuk grup ketersediaan dengan batasan
SQL Server 2025 (17.x) memperkenalkan dukungan untuk grup ketersediaan terdistribusi yang terkandung. Jika Anda bermaksud menggunakan AG terkandung sebagai penerus dalam grup ketersediaan terdistribusi, Anda harus membuat AG terkandung dengan menggunakan klausa AUTOSEEDING_SYSTEM_DATABASES untuk opsi WITH | CONTAINED dari perintah CREATE AVAILABILITY GROUP.
Persyaratan versi dan edisi
Grup ketersediaan terdistribusi di SQL Server 2017 atau yang lebih baru dapat mencampur versi utama SQL Server dalam grup ketersediaan terdistribusi yang sama. AG yang berisi primer baca/tulis dapat menjadi versi yang sama atau lebih rendah dari AG lain yang berpartisipasi dalam AG terdistribusi. AG lainnya dapat memiliki versi yang sama atau lebih tinggi. Skenario ini ditargetkan untuk skenario peningkatan dan migrasi. Misalnya, jika AG yang berisi replika utama baca/tulis adalah SQL Server 2016, tetapi Anda ingin meningkatkan/memigrasikan ke SQL Server 2017 atau yang lebih baru, AG lain yang berpartisipasi dalam AG terdistribusi dapat dikonfigurasi dengan SQL Server 2017.
Karena fitur grup ketersediaan terdistribusi tidak ada di SQL Server 2012 atau 2014, grup ketersediaan yang dibuat dengan versi ini tidak dapat berpartisipasi dalam grup ketersediaan terdistribusi.
Catatan
Bergantung pada versi SQL Server, saat menyambungkan ke layanan Azure (seperti tautan Instans Terkelola), dimungkinkan untuk mengonfigurasi grup ketersediaan terdistribusi menggunakan edisi Standar atau campuran edisi Standar dan Enterprise. Tinjau KB5016729 untuk mempelajari lebih lanjut.
Karena ada dua grup ketersediaan terpisah, proses penginstalan paket layanan atau pembaruan kumulatif pada replika yang berpartisipasi dalam grup ketersediaan terdistribusi sedikit berbeda dari grup ketersediaan tradisional:
Mulailah dengan memperbarui replika grup ketersediaan kedua dalam grup ketersediaan terdistribusi.
Perbarui replika grup ketersediaan utama di dalam grup ketersediaan yang terdistribusi.
Seperti halnya grup ketersediaan standar, lakukan failover pada grup ketersediaan utama ke salah satu replikanya sendiri (bukan ke primer grup ketersediaan kedua) dan lakukan penambalan. Jika tidak ada replika selain replika primer, failover manual ke grup ketersediaan sekunder diperlukan.
Versi Windows Server dan grup ketersediaan terdistribusi
Grup ketersediaan terdistribusi mencakup beberapa grup ketersediaan, masing-masing pada WSFC-nya sendiri, dan grup ketersediaan terdistribusi adalah konstruksi khusus SQL Server. Ini berarti WSFC yang menampung grup ketersediaan individual dapat memiliki versi utama Windows Server yang berbeda. Versi utama SQL Server harus sama, seperti yang dibahas di bagian sebelumnya. Sama seperti gambar awal, gambar berikut menunjukkan AG 1 dan AG 2 berpartisipasi dalam grup ketersediaan terdistribusi, tetapi masing-masing WSFC adalah versi Windows Server yang berbeda.
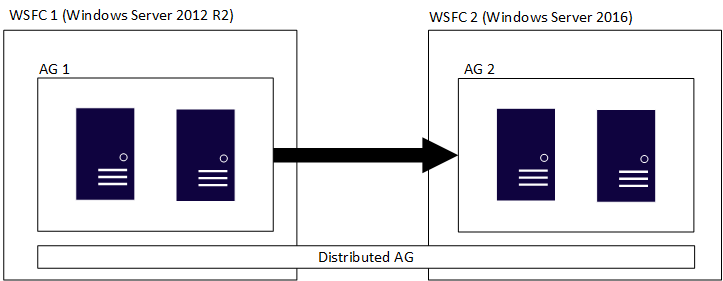
WSFC individual dan grup ketersediaan yang sesuai mengikuti aturan tradisional. Artinya, mereka dapat bergabung ke domain atau tidak bergabung ke domain (Server Windows 2016 atau yang lebih baru). Ketika dua grup ketersediaan yang berbeda digabungkan dalam satu grup ketersediaan terdistribusi, ada empat skenario:
- Kedua WSFC digabungkan ke domain yang sama.
- Setiap WSFC bergabung ke domain yang berbeda.
- Satu WSFC bergabung ke domain, dan satu WSFC tidak bergabung ke domain.
- Tidak ada satupun WSFC yang bergabung ke domain.
Ketika kedua WSFC digabungkan ke domain yang sama (bukan domain tepercaya), Anda tidak perlu melakukan sesuatu yang istimewa saat membuat grup ketersediaan terdistribusi. Untuk grup ketersediaan dan WSFC yang tidak bergabung ke domain yang sama, gunakan sertifikat untuk membuat grup ketersediaan terdistribusi berfungsi, dengan cara anda dapat membuat grup ketersediaan untuk grup ketersediaan independen domain. Untuk melihat cara mengonfigurasi sertifikat untuk grup ketersediaan terdistribusi, ikuti langkah 3-13 di bawah Buat grup ketersediaan independen domain.
Dengan grup ketersediaan terdistribusi, replika utama di setiap grup ketersediaan yang mendasar harus memiliki sertifikat satu sama lain. Jika Anda sudah memiliki titik akhir yang tidak menggunakan sertifikat, konfigurasi ulang titik akhir tersebut dengan menggunakan ALTER ENDPOINT untuk mencerminkan penggunaan sertifikat.
Skenario penggunaan
Berikut adalah tiga skenario penggunaan utama untuk grup ketersediaan terdistribusi:
- Pemulihan bencana dan konfigurasi multi-situs yang lebih mudah
- Migrasi ke perangkat keras atau konfigurasi baru, yang mungkin termasuk menggunakan perangkat keras baru atau mengubah sistem operasi yang mendasar
- Meningkatkan jumlah replika yang dapat dibaca melebihi delapan dalam satu grup ketersediaan dengan memperluas ke beberapa grup ketersediaan
Pemulihan bencana dan skenario multi-situs
Grup ketersediaan tradisional mengharuskan semua server harus menjadi bagian dari WSFC yang sama, yang dapat membuat penyebaran ke banyak pusat data menjadi menantang. Gambar berikut menunjukkan seperti apa arsitektur grup ketersediaan multi-situs tradisional, termasuk aliran data. Ada satu replika utama yang mengirim transaksi ke semua replika sekunder. Konfigurasi ini kurang dalam beberapa cara daripada grup ketersediaan terdistribusi. Misalnya, Anda harus menerapkan hal-hal seperti Direktori Aktif (jika berlaku) dan saksi untuk kuorum di WSFC. Anda mungkin juga perlu memperhitungkan aspek lain dari WSFC, seperti mengubah suara simpul.

Grup ketersediaan terdistribusi menawarkan skenario penyebaran yang lebih fleksibel untuk grup ketersediaan yang mencakup beberapa pusat data. Anda bahkan dapat menggunakan grup ketersediaan terdistribusi di mana fitur seperti pengiriman log digunakan di masa lalu untuk skenario seperti pemulihan bencana. Namun, tidak seperti pengiriman log, grup ketersediaan terdistribusi tidak dapat menunda penerapan transaksi. Ini berarti bahwa grup ketersediaan atau grup ketersediaan terdistribusi tidak dapat membantu jika terjadi kesalahan manusia di mana data salah diperbarui atau dihapus.
Grup ketersediaan terdistribusi digabungkan secara longgar, yang dalam hal ini berarti mereka tidak memerlukan satu WSFC dan dikelola oleh SQL Server. Karena WSFC dikelola secara individu dan sinkronisasi terutama asinkron antara kedua grup ketersediaan, lebih mudah untuk mengonfigurasi pemulihan setelah bencana di situs lain. Replika utama di setiap grup ketersediaan menyinkronkan replika sekunder mereka sendiri.
- Hanya failover manual yang didukung untuk grup ketersediaan terdistribusi. Dalam situasi pemulihan bencana di mana Anda beralih pusat data, Anda tidak boleh mengonfigurasi failover otomatis (dengan pengecualian langka).
- Anda kemungkinan besar tidak perlu mengatur beberapa item atau parameter tradisional untuk WSFC multi-situs atau subnet, seperti CrossSubnetThreshold, tetapi Anda masih perlu melihat tentang latensi jaringan pada lapisan yang berbeda dalam konteks pengiriman data. Perbedaannya adalah bahwa setiap WSFC mempertahankan ketersediaannya sendiri; kluster bukan satu entitas besar dari empat simpul. Anda memiliki dua WSFC dengan dua simpul setiap satu yang terpisah seperti yang ditunjukkan pada gambar sebelumnya.
- Kami merekomendasikan pergerakan data asinkron, karena pendekatan ini adalah untuk tujuan pemulihan bencana.
- Jika Anda mengonfigurasi pergerakan data sinkron antara replika utama dan setidaknya satu replika sekunder dari grup ketersediaan kedua, dan Anda mengonfigurasi gerakan sinkron pada grup ketersediaan terdistribusi, grup ketersediaan terdistribusi akan menunggu sampai semua salinan sinkron mengakui bahwa mereka memiliki data. Jika beberapa grup ketersediaan terdistribusi dirangkaikan secara seri (AG1 -> AG2 -> AG3) dan grup-grup tersebut diatur ke mode sinkron, sebuah grup ketersediaan terdistribusi akan menunggu hingga replika terakhir dari grup ketersediaan terakhir telah diperbarui.
Bermigrasi
Karena grup ketersediaan terdistribusi mendukung dua konfigurasi grup ketersediaan yang sama sekali berbeda, mereka tidak hanya memungkinkan skenario pemulihan bencana dan multi-situs yang lebih mudah, tetapi juga skenario migrasi. Baik Anda bermigrasi ke perangkat keras atau komputer virtual baru (lokal atau IaaS di cloud publik), mengonfigurasi grup ketersediaan terdistribusi memungkinkan migrasi terjadi di mana, di masa lalu, Anda mungkin telah menggunakan pencadangan, penyalinan, dan pemulihan, atau pengiriman log.
Kemampuan untuk bermigrasi sangat berguna dalam skenario di mana Anda mengubah atau meningkatkan OS yang mendasarinya saat Anda menyimpan versi SQL Server yang sama. Meskipun Server Windows 2016 memang memungkinkan peningkatan bergulir dari Windows Server 2012 R2 pada perangkat keras yang sama, sebagian besar pengguna memilih untuk menyebarkan perangkat keras atau komputer virtual baru.
Untuk menyelesaikan migrasi ke konfigurasi baru, di akhir proses, hentikan semua lalu lintas data ke grup ketersediaan asli, dan ubah grup ketersediaan terdistribusi menjadi pergerakan data sinkron. Tindakan ini memastikan bahwa replika utama grup ketersediaan kedua sepenuhnya disinkronkan, sehingga tidak akan ada kehilangan data. Setelah Anda memverifikasi sinkronisasi, lakukan failover grup ketersediaan terdistribusi ke grup ketersediaan sekunder. Untuk informasi selengkapnya, lihat failover ke grup ketersediaan yang sekunder.
Pascamigrasi, di mana grup ketersediaan kedua sekarang menjadi grup ketersediaan utama baru, Anda mungkin perlu melakukan salah satu langkah berikut:
- Ganti nama pendengar pada grup ketersediaan sekunder (dan mungkin menghapus atau mengganti nama yang lama pada grup ketersediaan utama asli), atau membuatnya kembali dengan pendengar dari grup ketersediaan utama asli, sehingga aplikasi dan pengguna dapat mengakses konfigurasi baru.
- Jika penggantian nama atau pembuatan ulang tidak dimungkinkan, arahkan aplikasi dan pengguna ke pendengar pada grup ketersediaan kedua.
Bermigrasi ke versi SQL Server yang lebih tinggi
Selama skenario migrasi, meskipun dimungkinkan untuk mengonfigurasi AG terdistribusi untuk memigrasikan database Anda ke target SQL Server yang merupakan versi yang lebih tinggi dari sumbernya, ada beberapa batasan.
Saat Anda mengonfigurasi AG terdistribusi dengan target migrasi SQL Server yang merupakan versi yang lebih tinggi dari sumbernya, autoseeding tidak didukung sehingga mode seeding harus diatur ke MANUAL. Jika Anda tidak menonaktifkan SEEDING OTOMATIS, migrasi Anda akan gagal dan Anda akan melihat kesalahan 946 "Tidak dapat membuka database 'DistributionAG' versi xxx. Tingkatkan database ke versi terbaru" di log kesalahan. Anda harus mengatur mode penyemaian (seeding mode) ke MANUAL dan secara manual melakukan pencadangan penuh dan pencadangan log transaksi database sumber dari Grup Ketersediaan (AG) utama. Kemudian pulihkan secara manual, bersama dengan log transaksi, ke AG sekunder. Untuk mempelajari lebih lanjut, tinjau langkah-langkah penyemaian manual untuk mengonfigurasi AG terdistribusi Anda, serta skrip untuk mencadangkan dan memulihkan database Anda dari AG utama ke AG sekunder.
Dengan asumsi AG sekunder (AG2) adalah target migrasi dan merupakan versi yang lebih tinggi daripada AG utama (AG1), pertimbangkan batasan berikut:
- Anda tidak akan memiliki akses baca ke salah satu database replika pada AG sekunder selama AG utama berada pada versi yang lebih rendah.
- Selama waktu ini, pembaruan akan terus mengalir dari AG Utama (AG1) ke AG Sekunder (AG2), tetapi status AG sekunder akan ditampilkan sebagai Sebagian Sehat, dan database pada replika sekunder AG Sekunder (AG2) akan ditampilkan sebagai Sinkronisasi/Dalam Pemulihan (bahkan jika AG berada dalam penerapan sinkronisasi).
- Setelah AG terdistribusi dialihkan ke versi yang lebih tinggi (AG2), AG2 harus berfungsi normal.
- Selama waktu ini, fail-back ke AG1 tidak akan dimungkinkan, karena berada pada versi yang lebih rendah.
- Karena AG1 berada pada versi yang lebih rendah, pembaruan dari AG2 setelah failover ke AG2 tidak akan direplikasi ke AG1.
- Dari sini, pilih apakah Anda ingin menonaktifkan AG asli (utama), atau jika Anda ingin meningkatkan AG1 dan mempertahankan AG terdistribusi.
- Jika Anda memilih untuk menonaktifkan AG1, hapus AG utama asli dari AG terdistribusi, dan prosesnya selesai.
- Jika Anda memilih untuk mempertahankan AG terdistribusi, tingkatkan versi SQL Server untuk AG1 agar sesuai dengan AG2. Setelah AG1 ditingkatkan, AG1 menjadi sehat, AG terdistribusi menjadi sehat, replika mengejar ketinggalan untuk disinkronkan, dan fail-back menjadi mungkin.
Meluaskan skala replika yang dapat dibaca
Satu grup ketersediaan terdistribusi dapat memiliki hingga 16 replika sekunder, sesuai kebutuhan. Sehingga dapat memiliki hingga 18 salinan yang tersedia untuk dibaca, termasuk dua duplikat utama dari berbagai grup ketersediaan. Pendekatan ini berarti bahwa lebih dari satu situs dapat memiliki akses hampir real-time untuk pelaporan ke berbagai aplikasi.
Grup ketersediaan terdistribusi dapat membantu Anda memperluas skala farm baca-saja lebih dari yang Anda bisa hanya dengan satu grup ketersediaan. Grup ketersediaan terdistribusi dapat menskalakan replika yang dapat dibaca dengan dua cara:
- Anda dapat menggunakan replika utama grup ketersediaan kedua dalam grup ketersediaan terdistribusi untuk membuat grup ketersediaan terdistribusi lain, meskipun database tidak berada di RECOVERY.
- Anda juga dapat menggunakan replika utama grup ketersediaan pertama untuk membuat grup ketersediaan terdistribusi lainnya.
Dengan kata lain, replika utama dapat berpartisipasi dalam grup ketersediaan terdistribusi yang berbeda. Gambar berikut menunjukkan AG 1 dan AG 2 keduanya berpartisipasi dalam Distributed AG 1, sementara AG 2 dan AG 3 berpartisipasi dalam Distributed AG 2. Replika utama (atau penerus) AG 2 adalah replika sekunder untuk AG Terdistribusi 1 dan replika utama AG Terdistribusi 2.
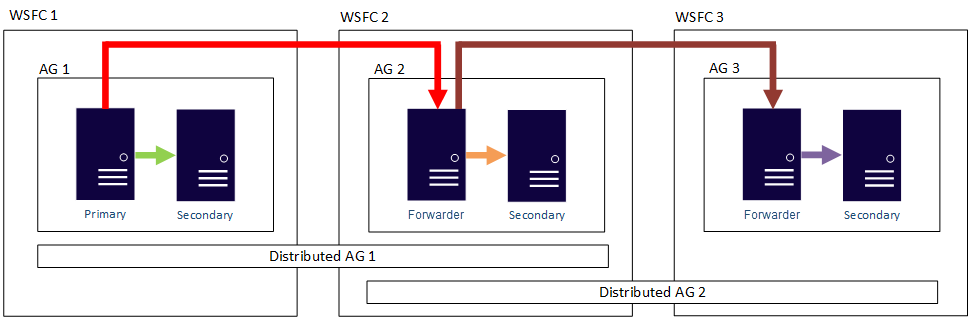
Gambar berikut menunjukkan AG 1 sebagai replika utama untuk dua grup ketersediaan terdistribusi yang berbeda: AG Terdistribusi 1 (terdiri dari AG 1 dan AG2) dan AG 2 Terdistribusi (terdiri dari AG 1 dan AG 3).
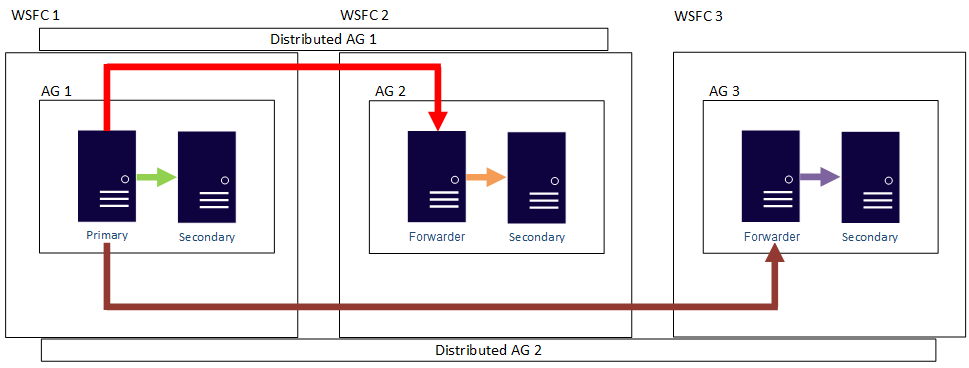
Dalam kedua contoh sebelumnya, dapat ada hingga 27 total replika di tiga grup ketersediaan, yang semuanya dapat digunakan untuk kueri baca-saja.
Routing hanya baca tidak berfungsi sepenuhnya dengan Grup Ketersediaan Terdistribusi. Lebih khusus lagi,
- Perutean Baca-Saja dapat dikonfigurasi dan akan berfungsi untuk grup ketersediaan utama dari grup ketersediaan terdistribusi.
- Perutean Baca-Saja dapat dikonfigurasi, tetapi tidak akan berfungsi untuk grup ketersediaan sekunder dari grup ketersediaan terdistribusi. Semua kueri, jika menggunakan listener untuk terhubung ke grup ketersediaan sekunder, akan menuju ke replika utama dari grup ketersediaan sekunder tersebut. Jika tidak, Anda perlu mengonfigurasi setiap replika untuk mengizinkan semua koneksi sebagai replika sekunder dan mengaksesnya secara langsung. Namun, routing read-only akan berfungsi jika grup ketersediaan sekunder berubah menjadi primary setelah failover. Perilaku ini mungkin diubah dalam pembaruan ke SQL Server 2016 atau di versi SQL Server yang akan datang.
Menginisialisasi grup ketersediaan sekunder
Grup ketersediaan terdistribusi dirancang dengan penanaman otomatis sebagai metode utama yang digunakan untuk menginisialisasi replika utama pada grup ketersediaan kedua. Pemulihan database lengkap pada replika utama grup ketersediaan kedua dimungkinkan jika Anda melakukan hal berikut:
- Pulihkan cadangan database DENGAN NORECOVERY.
- Jika perlu, pulihkan cadangan log transaksi yang tepat DENGAN NORECOVERY.
- Buat grup ketersediaan kedua tanpa menentukan nama database dan dengan SEEDING_MODE diatur ke OTOMATIS.
- Buat grup ketersediaan terdistribusi dengan menggunakan seeding otomatis.
Saat Anda menambahkan replika utama dari grup ketersediaan kedua ke grup ketersediaan terdistribusi, replika tersebut dicocokkan dengan database utama dari grup ketersediaan pertama, dan penyemaian otomatis menyelaraskan database ke sumbernya. Ada beberapa peringatan:
Output yang ditunjukkan pada
sys.dm_hadr_automatic_seedingreplika utama grup ketersediaan kedua akan menampilkancurrent_statedari FAILED dengan alasan "Seeding Check Message Timeout."Log kesalahan SQL Server saat ini pada replika utama grup ketersediaan kedua akan menunjukkan bahwa penyemaian otomatis berfungsi dan bahwa LSN disinkronkan.
Output yang ditunjukkan pada
sys.dm_hadr_automatic_seedingreplika utama dari grup ketersediaan pertama akan menunjukkan current_state sebagai SELESAI.Penyemaian otomatis juga memiliki perilaku yang berbeda dengan grup ketersediaan terdistribusi. Agar penyemaian otomatis dimulai pada replika kedua, Anda harus mengeluarkan
ALTER AVAILABILITY GROUP [AGName] GRANT CREATE ANY DATABASEperintah pada replika. Meskipun kondisi ini masih berlaku untuk setiap replika sekunder yang berpartisipasi dalam grup ketersediaan yang mendasarinya, replika utama grup ketersediaan kedua sudah memiliki izin yang tepat untuk memungkinkan penyemaian otomatis dimulai setelah ditambahkan ke grup ketersediaan terdistribusi.
Catatan
- Grup ketersediaan sekunder harus menggunakan titik akhir pencerminan database yang sama. Jika tidak, replikasi berhenti setelah failover lokal.
- Grup ketersediaan yang mendasar harus dalam mode ketersediaan yang sama - kedua grup ketersediaan harus dalam mode penerapan sinkron atau keduanya harus dalam mode penerapan asinkron. Jika Anda tidak yakin mana yang akan digunakan, atur keduanya ke mode penerapan asinkron hingga Anda siap untuk melakukan failover.
Memantau kesehatan
Grup ketersediaan terdistribusi adalah struktur yang khusus untuk SQL Server, dan tidak terlihat di WSFC dasar. Sampel kode berikut menunjukkan dua WSFC yang berbeda (CLUSTER_A dan CLUSTER_B), masing-masing dengan grup ketersediaannya sendiri. Hanya AG1 di CLUSTER_A dan AG2 di CLUSTER_B yang dibahas di sini.
PS C:\> Get-ClusterGroup -Cluster CLUSTER_A
Name OwnerNode State
---- --------- -----
AG1 DENNIS Online
Available Storage GLEN Offline
Cluster Group JY Online
New_RoR DENNIS Online
Old_RoR DENNIS Online
SeedingAG DENNIS Online
PS C:\> Get-ClusterGroup -Cluster CLUSTER_B
Name OwnerNode State
---- --------- -----
AG2 TOMMY Online
Available Storage JC Offline
Cluster Group JC Online
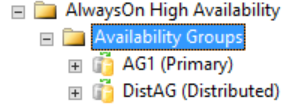
Semua informasi terperinci tentang grup ketersediaan terdistribusi ada di SQL Server, khususnya dalam tampilan manajemen dinamis grup ketersediaan. Saat ini, satu-satunya informasi yang ditampilkan di SQL Server Management Studio untuk grup ketersediaan terdistribusi ada di replika utama untuk grup ketersediaan. Seperti yang ditunjukkan pada gambar berikut, di bawah folder Grup Ketersediaan, SQL Server Management Studio menunjukkan bahwa ada grup ketersediaan terdistribusi. Gambar menunjukkan AG1 sebagai replika utama untuk grup ketersediaan individual yang lokal untuk instans tersebut, bukan untuk grup ketersediaan terdistribusi.
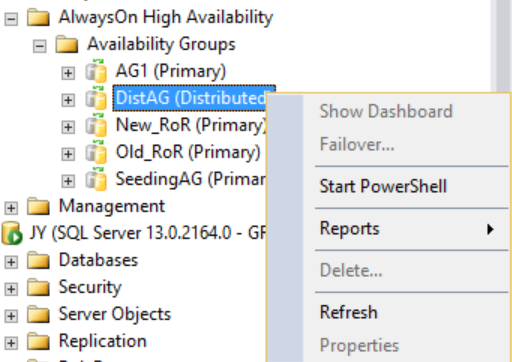
Namun, jika Anda mengklik kanan grup ketersediaan terdistribusi, tidak ada opsi yang tersedia (lihat gambar berikut), dan folder Database Ketersediaan, Pendengar Grup Ketersediaan, dan Replika Ketersediaan yang diperluas semuanya kosong. SQL Server Management Studio 16 menampilkan hasil ini, tetapi mungkin berubah dalam versi SQL Server Management Studio di masa mendatang.
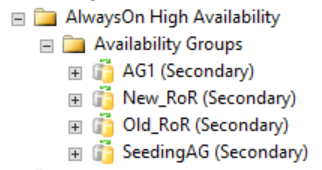
Seperti yang ditunjukkan pada gambar berikut, replika sekunder tidak menunjukkan apa pun di SQL Server Management Studio yang terkait dengan grup ketersediaan terdistribusi. Nama grup ketersediaan ini dipetakan ke peran yang ditunjukkan pada gambar WSFC CLUSTER_A sebelumnya.
DMV mencantumkan semua nama replika ketersediaan
Konsep yang sama berlaku saat Anda menggunakan tampilan manajemen dinamis. Dengan menggunakan kueri berikut, Anda dapat melihat semua grup ketersediaan (reguler dan terdistribusi) dan simpul yang berpartisipasi di dalamnya. Hasil ini ditampilkan hanya jika Anda mengkueri replika utama di salah satu WSFC yang berpartisipasi dalam grup ketersediaan terdistribusi. Ada kolom baru dalam tampilan sys.availability_groups manajemen dinamis bernama is_distributed, yaitu 1 ketika grup ketersediaan adalah grup ketersediaan terdistribusi. Untuk melihat kolom ini:
-- shows replicas associated with availability groups
SELECT
ag.[name] AS [AG Name],
ag.Is_Distributed,
ar.replica_server_name AS [Replica Name]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id;
GO
Contoh output dari WSFC kedua yang berpartisipasi dalam grup ketersediaan terdistribusi ditunjukkan pada gambar berikut. SPAG1 terdiri dari dua replika: DENNIS dan JY. Namun, grup ketersediaan terdistribusi bernama SPDistAG memiliki nama dua grup ketersediaan yang berpartisipasi (SPAG1 dan SPAG2) daripada nama instans, seperti halnya grup ketersediaan tradisional.
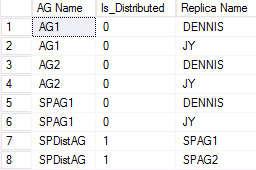
DMV akan mencantumkan kesehatan sistem AG yang terdistribusi
Di SQL Server Management Studio, status apa pun yang ditampilkan di Dasbor dan area lain, hanya untuk sinkronisasi lokal dalam grup ketersediaan tersebut. Untuk menampilkan kesehatan grup ketersediaan terdistribusi, kueri tampilan manajemen dinamis. Contoh kueri berikut memperluas dan menyempurnakan kueri sebelumnya:
-- shows sync status of distributed AG
SELECT
ag.[name] AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [Underlying AG],
ars.role_desc AS [Role],
ars.synchronization_health_desc AS [Sync Status]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

DMV untuk melihat kinerja yang mendasar
Untuk memperluas kueri sebelumnya lebih lanjut, Anda juga dapat melihat kinerja yang mendasarinya melalui tampilan manajemen dinamis dengan menambahkan di sys.dm_hadr_database_replicas_states. Tampilan manajemen dinamis saat ini hanya menyimpan informasi tentang grup ketersediaan kedua. Contoh kueri berikut, berjalan pada grup ketersediaan utama, menghasilkan output sampel yang ditunjukkan di bawah ini:
-- shows underlying performance of distributed AG
SELECT
ag.[name] AS [Distributed AG Name],
ar.replica_server_name AS [Underlying AG],
dbs.[name] AS [Database],
ars.role_desc AS [Role],
drs.synchronization_health_desc AS [Sync Status],
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate
FROM sys.databases AS dbs
INNER JOIN sys.dm_hadr_database_replica_states AS drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups AS ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

DMV untuk melihat penghitung kinerja untuk AG terdistribusi
Kueri di bawah ini menampilkan penghitung kinerja yang terkait dengan grup ketersediaan terdistribusi tertentu.
-- displays OS performance counters related to the distributed ag named 'distributedag'
SELECT * FROM sys.dm_os_performance_counters WHERE instance_name LIKE '%distributed%'
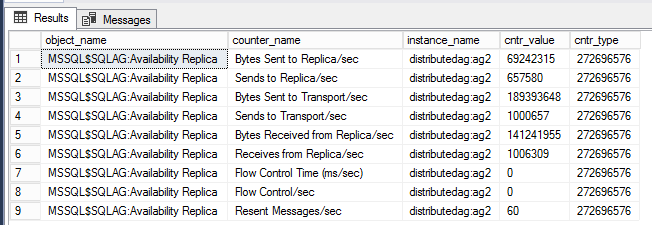
Catatan
LIKE Filter harus memiliki nama grup ketersediaan terdistribusi. Dalam contoh ini, nama grup ketersediaan terdistribusi adalah 'distributedag'. Ubah pengubah LIKE untuk mencerminkan nama grup ketersediaan terdistribusi Anda.
DMV untuk menampilkan status kesehatan dari kedua AG dan AG Terdistribusi
Kueri di bawah ini menampilkan banyak informasi tentang kesehatan grup ketersediaan, dan grup ketersediaan terdistribusi. (Diproduksi ulang dengan izin dari Tracy Boggiano.)
-- displays sync status, send rate, and redo rate of availability groups,
-- including distributed AG
SELECT ag.name AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [AG],
dbs.name AS [Database],
ars.role_desc,
drs.synchronization_health_desc,
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate,
drs.suspend_reason_desc,
drs.last_sent_time,
drs.last_received_time,
drs.last_hardened_time,
drs.last_redone_time,
drs.last_commit_time,
drs.secondary_lag_seconds
FROM sys.databases dbs
INNER JOIN sys.dm_hadr_database_replica_states drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas ar
ON ar.replica_id = ars.replica_id
--WHERE ag.is_distributed = 1
GO

DMV untuk melihat metadata AG terdistribusi
Kueri di bawah ini akan menampilkan informasi tentang URL titik akhir yang digunakan oleh grup ketersediaan, termasuk grup ketersediaan terdistribusi. (Diproduksi ulang dengan izin dari David Barbarin.)
-- shows endpoint url and sync state for ag, and dag
SELECT
ag.name AS group_name,
ag.is_distributed,
ar.replica_server_name AS replica_name,
ar.endpoint_url,
ar.availability_mode_desc,
ar.failover_mode_desc,
ar.primary_role_allow_connections_desc AS allow_connections_primary,
ar.secondary_role_allow_connections_desc AS allow_connections_secondary,
ar.seeding_mode_desc AS seeding_mode
FROM sys.availability_replicas AS ar
JOIN sys.availability_groups AS ag
ON ar.group_id = ag.group_id;
GO

DMV akan menunjukkan status seeding terbaru
Kueri di bawah ini menampilkan informasi tentang status penyemaian saat ini. Ini berguna untuk memecahkan masalah kesalahan sinkronisasi antar replika. (Diproduksi ulang dengan izin dari David Barbarin.)
-- shows current_state of seeding
SELECT ag.name AS aag_name,
ar.replica_server_name,
d.name AS database_name,
has.current_state,
has.failure_state_desc AS failure_state,
has.error_code,
has.performed_seeding,
has.start_time,
has.completion_time,
has.number_of_attempts
FROM sys.dm_hadr_automatic_seeding AS has
INNER JOIN sys.availability_groups AS ag
ON ag.group_id = has.ag_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = has.ag_remote_replica_id
INNER JOIN sys.databases AS d
ON d.group_database_id = has.ag_db_id;
GO
