Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk:![]() SQL Server 2017 (14.x) dan versi yang lebih baru
SQL Server 2017 (14.x) dan versi yang lebih baru
Artikel ini menjelaskan ekstensi Python untuk menjalankan skrip Python eksternal dengan SQL Server Layanan Pembelajaran Mesin. Ekstensi menambahkan:
- Lingkungan eksekusi Python
- Distribusi Anaconda dengan runtime dan interpreter Python 3.5
- Pustaka dan alat standar
- Paket Microsoft Python:
- revoscalepy untuk analitik dalam skala besar.
- microsoftml untuk algoritma pembelajaran mesin.
Penginstalan runtime dan interpreter Python 3.5 memastikan kompatibilitas hampir lengkap dengan solusi Python standar. Python berjalan dalam proses terpisah dari SQL Server, untuk menjamin bahwa operasi database tidak disusupi.
Komponen Python
SQL Server mencakup paket sumber terbuka dan kepemilikan. Runtime Python yang diinstal oleh Setup adalah Anaconda 4.2 dengan Python 3.5. Runtime Python diinstal secara independen dari alat SQL, dan dijalankan di luar proses mesin inti, dalam kerangka kerja ekstensibilitas. Sebagai bagian dari penginstalan Layanan Pembelajaran Mesin dengan Python, Anda harus menyetujui ketentuan Lisensi Publik GNU.
SQL Server tidak memodifikasi executable Python, tetapi Anda harus menggunakan versi Python yang diinstal oleh penginstalan karena pada versi itulah paket-paket kepemilikan dibangun dan diuji. Untuk daftar paket yang didukung oleh distribusi Anaconda, lihat daftar situs analitik Continuum: Paket Anaconda.
Distribusi Anaconda yang terkait dengan instans mesin database tertentu dapat ditemukan di folder yang terkait dengan instans. Misalnya, jika Anda menginstal mesin database SQL Server 2017 dengan Layanan Pembelajaran Mesin dan Python pada instans default, lihat di bawah C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES.
Paket Python yang ditambahkan oleh Microsoft untuk beban kerja paralel dan terdistribusi mencakup pustaka berikut.
| Pustaka | Deskripsi |
|---|---|
| revoscalepy | Mendukung objek sumber data dan eksplorasi data, manipulasi, transformasi, dan visualisasi. Ini mendukung pembuatan konteks komputasi jarak jauh, serta berbagai model pembelajaran mesin yang dapat diskalakan, seperti rxLinMod. Untuk informasi selengkapnya, lihat modul revoscalepy dengan SQL Server. |
| microsoftml | Berisi algoritma pembelajaran mesin yang telah dioptimalkan untuk kecepatan dan akurasi, serta transformasi in-line untuk bekerja dengan teks dan gambar. Untuk informasi selengkapnya, lihat modul microsoftml dengan SQL Server. |
Microsoftml dan revoscalepy digabungkan erat; sumber data yang digunakan dalam microsoftml didefinisikan sebagai objek revoscalepy. Menghitung batasan konteks dalam transfer revoscalepy ke microsoftml. Yaitu, semua fungsionalitas tersedia untuk operasi lokal, tetapi beralih ke konteks komputasi jarak jauh memerlukan RxInSqlServer.
Menggunakan Python di SQL Server
Anda mengimpor modul revoscalepy ke dalam kode Python Anda, lalu memanggil fungsi dari modul, seperti fungsi Python lainnya.
Sumber data yang didukung termasuk database ODBC, format file SQL Server, dan XDF untuk bertukar data dengan sumber lain, atau dengan solusi R. Data input untuk Python harus bertabel. Semua hasil Python harus dikembalikan dalam bentuk bingkai data panda .
Konteks komputasi yang didukung mencakup konteks komputasi SQL Server lokal, atau jarak jauh. Konteks komputasi jarak jauh mengacu pada eksekusi kode yang dimulai pada satu komputer seperti stasiun kerja, tetapi kemudian mengalihkan eksekusi skrip ke komputer jarak jauh. Mengalihkan konteks komputasi mengharuskan kedua sistem memiliki pustaka revoscalepy yang sama.
Konteks komputasi lokal, seperti yang Anda harapkan, termasuk eksekusi kode Python pada server yang sama dengan instans mesin database, dengan kode di dalam T-SQL atau disematkan dalam prosedur tersimpan. Anda juga dapat menjalankan kode dari IDE Python lokal dan menjalankan skrip pada komputer SQL Server, dengan menentukan konteks komputasi jarak jauh.
Arsitektur Pelaksanaan
Diagram berikut menggambarkan interaksi komponen SQL Server dengan runtime Python di setiap skenario yang didukung: menjalankan skrip dalam database, dan eksekusi jarak jauh dari terminal Python, menggunakan konteks komputasi SQL Server.
Skrip Python dijalankan dalam database
Ketika Anda menjalankan Python "inside" SQL Server, Anda harus merangkum skrip Python di dalam prosedur tersimpan khusus, sp_execute_external_script.
Setelah skrip disematkan dalam prosedur tersimpan, aplikasi apa pun yang dapat melakukan panggilan prosedur tersimpan dapat memulai eksekusi kode Python. Setelah itu SQL Server mengelola eksekusi kode seperti yang dirangkum dalam diagram berikut.
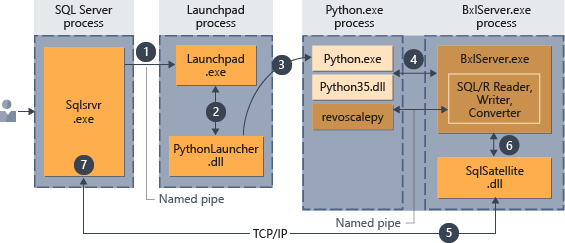
- Permintaan untuk runtime Python ditandai oleh parameter
@language='Python'yang diteruskan ke prosedur tersimpan. SQL Server mengirimkan permintaan ini ke layanan launchpad. Di Linux, SQL menggunakan layanan launchpadd untuk berkomunikasi dengan proses launchpad terpisah untuk setiap pengguna. Lihat diagram arsitektur Ekstensibilitas untuk detailnya. - Layanan launchpad memulai peluncur yang sesuai; dalam hal ini, PythonLauncher.
- PythonLauncher memulai proses Python35 eksternal.
- BxlServer berkoordinasi dengan runtime Python untuk mengelola pertukaran data, dan penyimpanan hasil kerja.
- Satelit SQL mengelola komunikasi tentang tugas dan proses terkait dengan SQL Server.
- BxlServer menggunakan Satelit SQL untuk mengomunikasikan status dan hasil ke SQL Server.
- SQL Server mendapatkan hasil dan menutup tugas dan proses terkait.
Skrip Python dijalankan dari klien jarak jauh
Anda dapat menjalankan skrip Python dari komputer jarak jauh, seperti laptop, dan menjalankannya dalam konteks komputer SQL Server, jika kondisi ini terpenuhi:
- Anda merancang skrip dengan tepat
- Komputer jarak jauh telah menginstal pustaka ekstensibilitas yang digunakan oleh Layanan Pembelajaran Mesin. Paket revoscalepy diperlukan untuk menggunakan konteks komputasi jarak jauh.
Diagram berikut ini meringkas alur kerja keseluruhan saat skrip dikirim dari komputer jarak jauh.
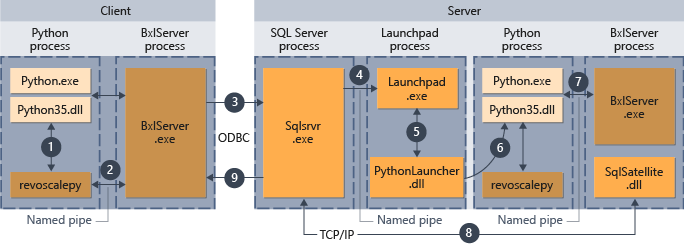
- Untuk fungsi yang didukung dalam revoscalepy, runtime Python memanggil fungsi penautan, yang pada gilirannya memanggil BxlServer.
- BxlServer termasuk dalam Machine Learning Services (In-Database) dan berjalan dalam proses terpisah dari runtime Python.
- BxlServer menentukan target koneksi dan memulai koneksi menggunakan ODBC, meneruskan kredensial yang disediakan sebagai bagian dari string koneksi dalam skrip Python.
- BxlServer membuka koneksi ke instans SQL Server.
- Ketika runtime skrip eksternal dipanggil, layanan launchpad dipanggil dan kemudian memulai peluncur yang sesuai: dalam hal ini, PythonLauncher.dll. Setelah itu, pemrosesan kode Python ditangani dalam alur kerja yang mirip dengan ketika kode Python dipanggil dari prosedur tersimpan di T-SQL.
- PythonLauncher melakukan panggilan ke instans Python yang diinstal pada komputer SQL Server.
- Hasil dikembalikan ke BxlServer.
- Satelit SQL mengelola komunikasi dengan SQL Server dan pembersihan objek pekerjaan terkait.
- SQL Server meneruskan hasil kembali ke klien.