"Latihan - Menulis aliran data pemetaan Azure Data Factory"
Mentransformasi data dengan Pemetaan Aliran Data
Anda dapat melakukan transformasi data secara asli dengan kode Azure Data Factory gratis menggunakan tugas Aliran Data Pemetaan. Pemetaan Aliran Data memberikan pengalaman visual sepenuhnya tanpa memerlukan pengodean. Aliran data Anda akan berjalan di kluster eksekusi Anda sendiri untuk pemrosesan data yang diluaskan skalanya. Aktivitas aliran data dapat dioperasionalkan melalui kemampuan penjadwalan, kontrol, aliran, dan pemantauan Data Factory yang ada.
Saat membangun aliran data, Anda dapat mengaktifkan mode debug, yang mengaktifkan kluster Spark interaktif kecil. Aktifkan mode debug dengan mengaktifkan penggeser di bagian atas modul penulisan. Kluster debug membutuhkan waktu beberapa menit untuk disiapkan, tetapi dapat digunakan untuk melihat pratinjau output logika transformasi Anda secara interaktif.

Dengan penambahan Aliran Data Pemetaan, dan kluster Spark berjalan, ini akan memungkinkan Anda untuk melakukan transformasi, serta menjalankan dan melihat pratinjau data. Tidak diperlukan pengodean karena Azure Data Factory menangani semua terjemahan kode, pengoptimalan jalur, dan pelaksanaan pekerjaan aliran data Anda.
Menambahkan data sumber ke Pemetaan Aliran Data
Buka kanvas Aliran Data Pemetaan. Klik tombol Tambahkan Sumber di kanvas Aliran Data. Pada dropdown himpunan data sumber, pilih data sumber Anda, dalam hal ini himpunan data ADLS Gen2 digunakan dalam contoh ini
Ada beberapa poin yang perlu diperhatikan:
- Jika himpunan data Anda mengarah ke folder dengan file lain dan Anda hanya ingin menggunakan satu file, Anda mungkin perlu membuat himpunan data lain atau menggunakan parameterisasi untuk memastikan hanya file tertentu yang dibaca
- Jika Anda belum mengimpor skema di ADLS, tetapi telah menyerap data Anda, buka tab 'Skema' himpunan data dan klik 'Impor skema' sehingga aliran data Anda mengetahui proyeksi skema.
Pemetaan Aliran Data mengikuti pendekatan ekstrak, muat, transformasi (ELT) dan bekerja dengan pentahapan himpunan data yang semuanya ada di Azure. Saat ini himpunan data berikut dapat digunakan dalam transformasi sumber:
- Azure Blob Storage (JSON, Avro, Text, Parquet)
- Azure Data Lake Storage Gen1 (JSON, Avro, Text, Parquet)
- Azure Data Lake Storage Gen2 (JSON, Avro, Text, Parquet)
- Azure Synapse Analytics
- Azure SQL Database
- Azure Cosmos DB
Azure Data Factory memiliki akses ke lebih dari 80 konektor asli. Untuk menyertakan data dari sumber lain di aliran data Anda, gunakan Aktivitas Salin untuk memuat data tersebut ke salah satu area sementara yang didukung.
Setelah kluster debug Anda disiapkan, verifikasi data Anda dimuat dengan benar melalui tab Pratinjau Data. Setelah Anda mengklik tombol refresh, Pemetaan Aliran Data akan menampilkan salinan bayangan dari tampilan data Anda saat berada di setiap transformasi.
Menggunakan transformasi dalam Pemetaan Aliran Data
Kini setelah Anda memindahkan data ke Azure Data Lake Store Gen2, Anda siap untuk membangun Pemetaan Aliran Data yang akan mengubah data Anda dalam skala besar melalui kluster spark lalu memuatnya ke dalam Gudang Data.
Tugas utama untuk ini adalah sebagai berikut:
Mempersiapkan lingkungan
Menambahkan Sumber Data
Menggunakan transformasi Pemetaan Aliran Data
Menulis ke Sink Data
Tugas 1: Mempersiapkan lingkungan
Aktifkan Debug Aliran Data Aktifkan penggeser Debug Aliran Data yang terletak di bagian atas modul penulisan.
Catatan
Kluster Aliran Data membutuhkan waktu 5-7 menit untuk disiapkan.
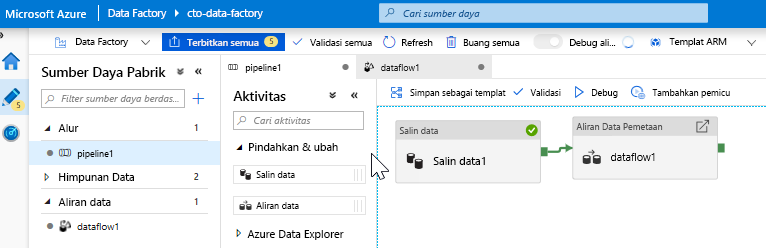
Tambahkan aktivitas Aliran Data. Di panel Aktivitas, buka akordeon Pindahkan dan Ubah dan seret aktivitas Aliran Data ke kanvas alur. Pada panel yang muncul, klik Buat Aliran Data baru dan pilih Pemetaan Aliran Data lalu klik OK. Klik tab pipeline1 dan seret kotak hijau dari aktivitas Salin ke Aktivitas Aliran Data untuk membuat kondisi yang berhasil. Anda akan melihat yang berikut ini di kanvas:
Tugas 2: Menambahkan Sumber Data
Tambahkan sumber ADLS. Klik dua kali pada objek Pemetaan Aliran Data di kanvas. Klik tombol Tambahkan Sumber di kanvas Aliran Data. Di dropdown Himpunan data sumber, pilih himpunan data ADLSG2 yang digunakan dalam aktivitas Salin Anda
- Jika himpunan data Anda mengarah ke folder dengan file lain, Anda mungkin perlu membuat himpunan data lain atau menggunakan parameterisasi untuk memastikan hanya file movieDB.csv yang dibaca
- Jika Anda belum mengimpor skema di ADLS, tetapi telah menyerap data Anda, buka tab 'Skema' himpunan data dan klik 'Impor skema' sehingga aliran data Anda mengetahui proyeksi skema.
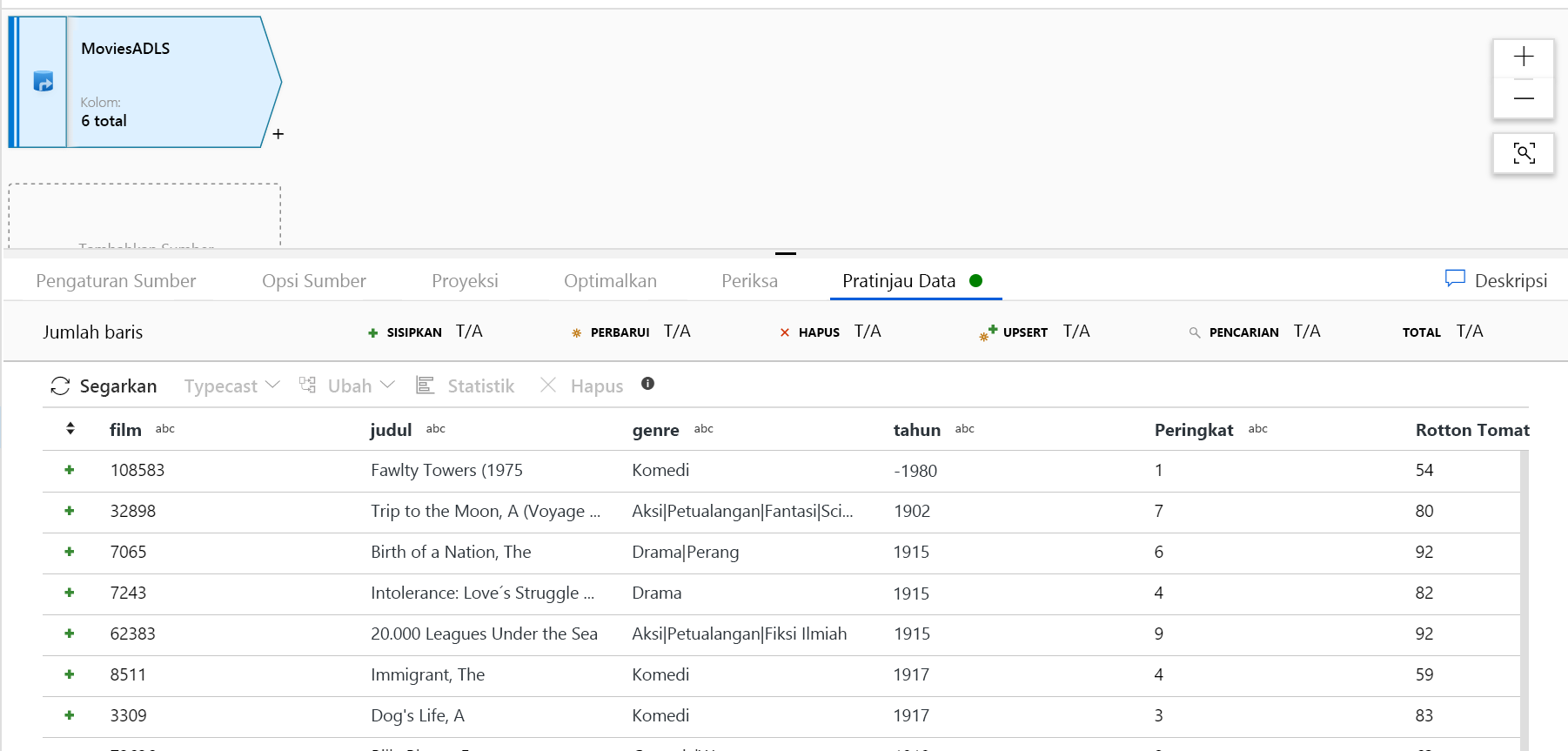
Setelah kluster debug Anda disiapkan, verifikasi data Anda dimuat dengan benar melalui tab Pratinjau Data. Setelah Anda mengklik tombol refresh, Pemetaan Aliran Data akan menampilkan salinan bayangan dari tampilan data Anda saat berada di setiap transformasi.
Tugas 3: Menggunakan transformasi Pemetaan Aliran Data
Tambahkan Transformasi pilih untuk mengganti nama dan menghilangkan kolom. Dalam pratinjau data, Anda mungkin memperhatikan bahwa kolom "Rotton Tomatoes" salah eja. Untuk menamainya dengan benar dan menghilangkan kolom Peringkat yang tidak digunakan, Anda dapat menambahkan Transformasi pilih dengan mengeklik ikon + di sebelah simpul sumber ADLS Anda dan memilih Pilih di bawah pengubah Skema.
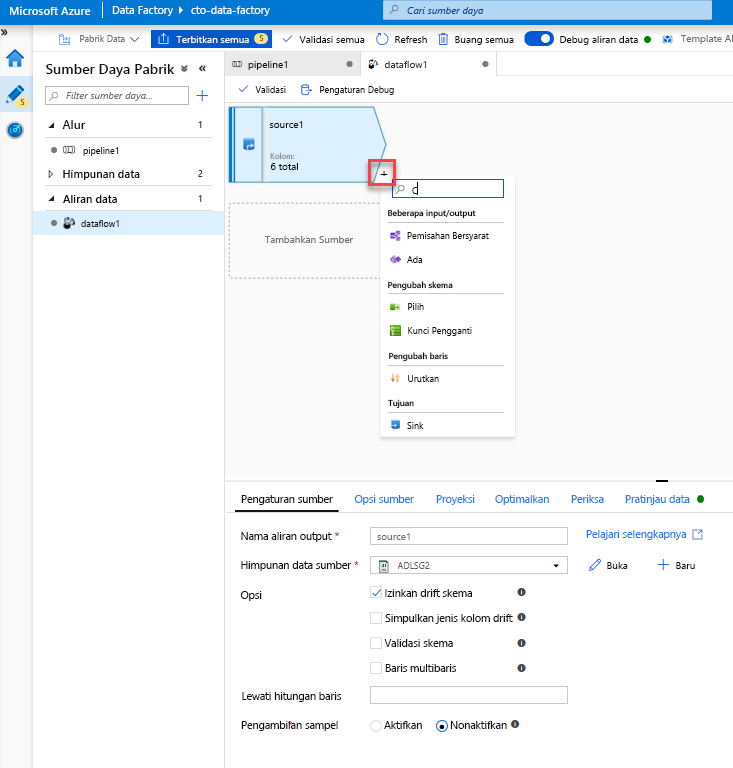
Di Nama sebagai bidang, ubah 'Rotton' menjadi 'Rotten'. Untuk menghilangkan kolom Peringkat, arahkan kursor ke atasnya dan klik ikon tempat sampah.
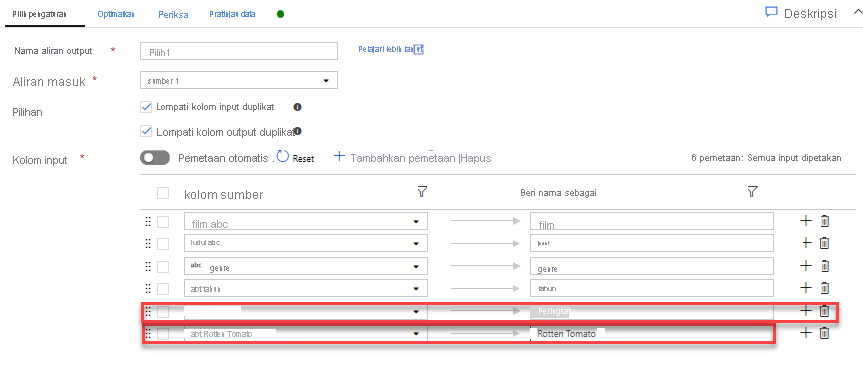
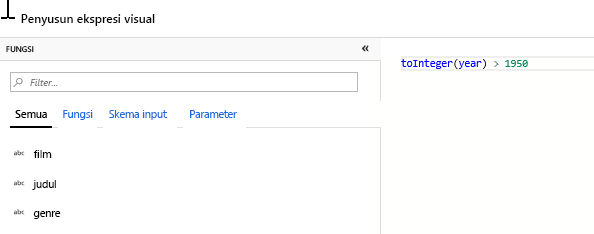
Tambahkan Transformasi Filter untuk menyaring tahun-tahun yang tidak diinginkan. Katakanlah Anda hanya tertarik pada film yang dibuat setelah tahun 1951. Anda dapat menambahkan Transformasi filter untuk menentukan kondisi filter dengan mengklik ikon + di samping Transformasi pilih dan memilih Filter di bawah Pengubah Baris. Klik kotak ekspresi untuk membuka Penyusun ekspresi dan masukkan kondisi filter Anda. Menggunakan sintaks bahasa ekspresi Aliran Data Pemetaan, toInteger(year) > 1950 akan mengonversi nilai tahun string menjadi bilangan bulat dan memfilter baris jika nilai tersebut di atas 1950.
Anda dapat menggunakan panel pratinjau Data yang disematkan pembuat ekspresi untuk memverifikasi kondisi Anda berfungsi dengan benar
Tambahkan Transformasi Turunan untuk menghitung genre utama. Seperti yang mungkin Anda perhatikan, kolom genre adalah string yang dibatasi oleh karakter '|'. Jika Anda hanya peduli dengan genre pertama di setiap kolom, Anda dapat memperoleh kolom baru bernama PrimaryGenre melalui transformasi Kolom Turunan dengan mengklik ikon + di sebelah Transformasi filter Anda dan memilih Turunan di bawah Pengubah Skema. Mirip dengan transformasi filter, kolom turunan menggunakan pembuat ekspresi Aliran Data Pemetaan untuk menentukan nilai kolom baru.

Dalam skenario ini, Anda mencoba mengekstrak genre pertama dari kolom genre, yang diformat sebagai 'genre1|genre2|...|genreN'. Gunakan fungsi locate untuk mendapatkan indeks berbasis 1 pertama dari '|' dalam string genre. Dengan menggunakan fungsi iif, jika indeks ini lebih besar dari 1, genre utama dapat dihitung melalui fungsi left, yang mengembalikan semua karakter dalam string di sebelah kiri indeks. Jika tidak, nilai PrimaryGenre sama dengan bidang genre. Anda dapat memverifikasi output melalui panel pratinjau Data penyusun ekspresi.
Beri peringkat film melalui Transformasi Jendela. Katakanlah Anda tertarik pada peringkat film dalam tahun tersebut untuk genre tertentu. Anda dapat menambahkan Transformasi jendela untuk menentukan agregasi berbasis jendela dengan mengklik ikon + di samping transformasi Kolom Turunan dan mengklik Jendela di bawah Pengubah skema. Untuk mencapai ini, tentukan apa yang Anda jendelakan, dasar pengurutan, rentangnya, dan bagaimana menghitung kolom jendela baru Anda. Dalam contoh ini, kita akan menjendelakan PrimaryGenre dan tahun dengan rentang tak terbatas, yang diurutkan berdasarkan Rotten Tomato secara menurun, dan menghitung kolom baru bernama RatingsRank yang sama dengan peringkat yang dimiliki setiap film dalam genre-tahun yang ditentukan.
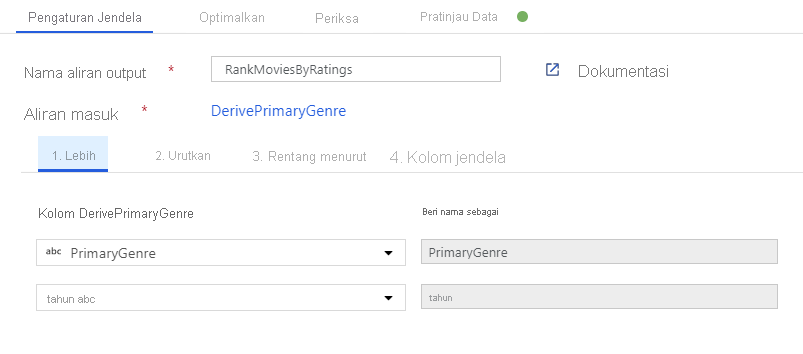
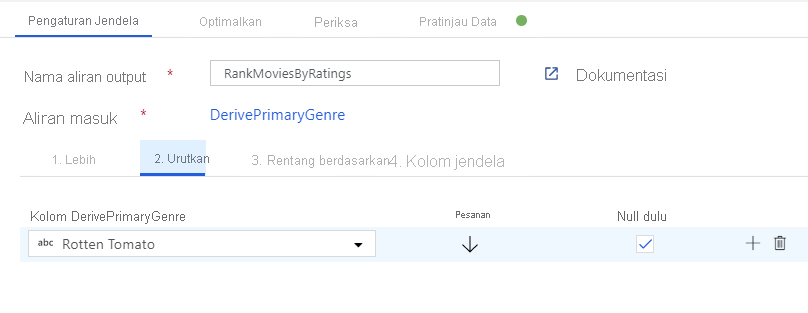
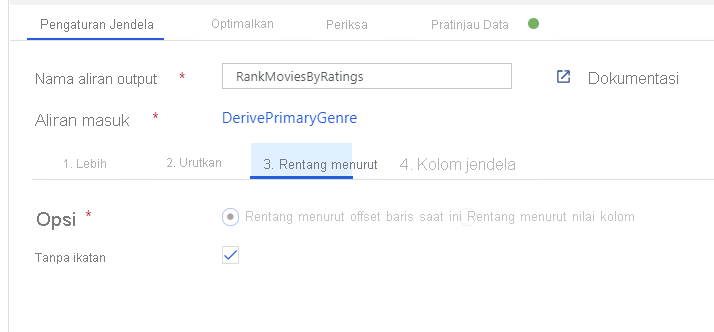
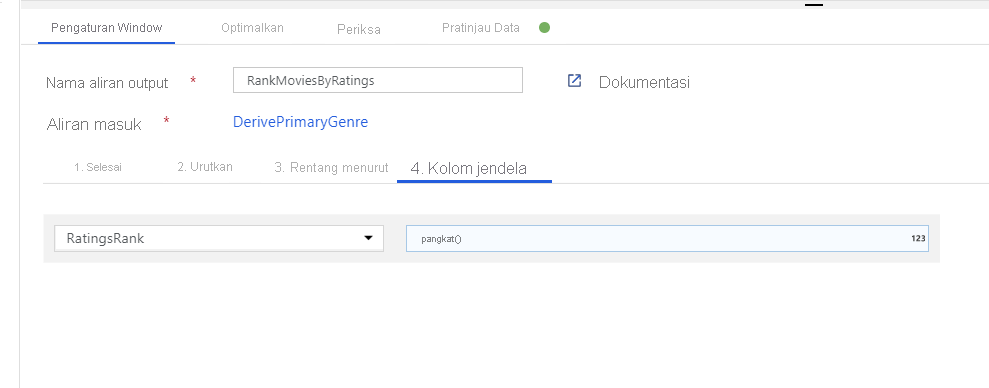
Peringkat agregat dengan Transformasi Agregat. Sekarang setelah Anda mengumpulkan dan memperoleh semua data yang diperlukan, kita dapat menambahkan Transformasi agregat untuk menghitung metrik berdasarkan grup yang diinginkan dengan mengklik ikon + di samping Transformasi jendela dan mengeklik Agregat di bawah Pengubah skema. Seperti yang Anda lakukan dalam transformasi jendela, mari mengelompokkan film berdasarkan PrimaryGenre dan tahun
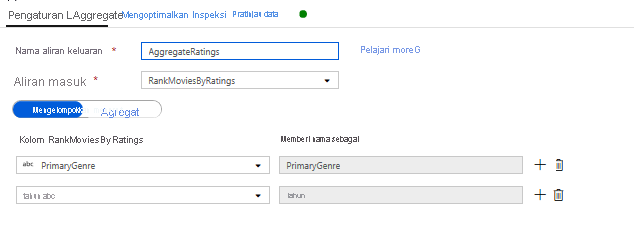
Di tab Agregat, Anda bisa membuat agregat yang dihitung atas grup yang ditentukan menurut kolom. Untuk setiap genre dan tahun, mari dapatkan rata-rata peringkat Rotten Tomatoes, film dengan rating tertinggi dan terendah (memanfaatkan fungsi menjendelakan) dan jumlah film yang ada di setiap grup. Agregasi secara signifikan mengurangi jumlah baris dalam aliran transformasi Anda dan hanya menyebarkan grup dan mengagregasi kolom yang ditentukan dalam transformasi.
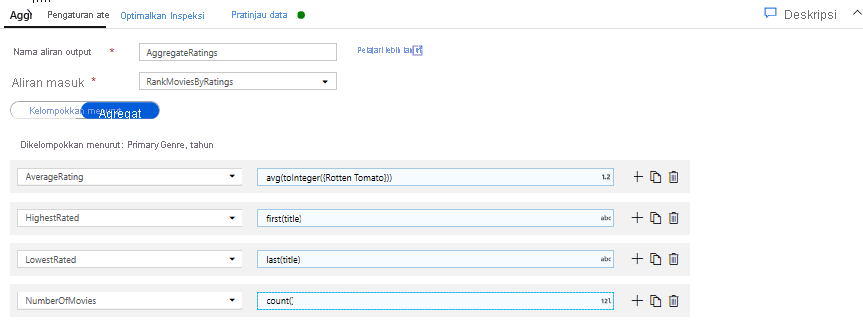
- Untuk melihat bagaimana transformasi agregat mengubah data Anda, gunakan tab Pratinjau Data
Tentukan kondisi Upsert melalui Transformasi Ubah Baris. Jika menulis ke sink tabular, Anda dapat menentukan kebijakan penyisipan, penghapusan, pembaruan, dan upsert pada baris menggunakan Ubah Transformasi baris dengan mengklik ikon + di samping Transformasi agregat Anda dan mengklik Ubah Baris di bawah Pengubah baris. Karena selalu menyisipkan dan memperbarui, Anda dapat menentukan bahwa semua baris akan selalu di-upsert.

Tugas 4: Menulis ke Sink Data
- Menulis ke Sink Azure Synapse Analytics. Sekarang setelah menyelesaikan semua logika transformasi, Anda siap untuk menulis ke Sink.
Tambahkan Sink dengan mengklik ikon + di samping Transformasi upsert Anda dan mengklik Sink di bawah Tujuan.
Di tab Sink, buat himpunan data gudang data baru melalui + Tombol baru.
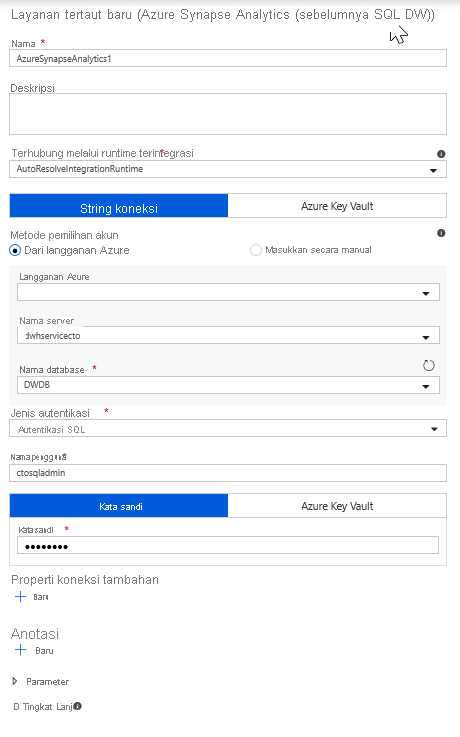
Pilih Azure Synapse Analytics dari daftar petak peta.
Pilih layanan tertaut baru dan konfigurasikan koneksi Azure Synapse Analytics Anda untuk tersambung ke database DWDB. Klik Buat saat selesai.
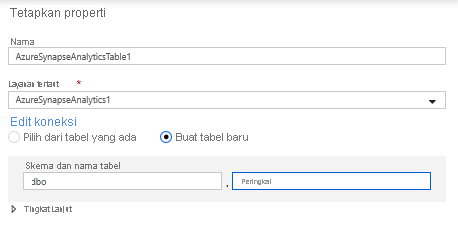
Dalam konfigurasi himpunan data, pilih Buat tabel baru dan masukkan skema Dbo dan nama tabel Peringkat. Klik OK setelah selesai.
Karena kondisi upsert ditentukan, Anda harus masuk ke tab Pengaturan dan pilih 'Izinkan upsert' berdasarkan kolom kunci PrimaryGenre dan tahun.
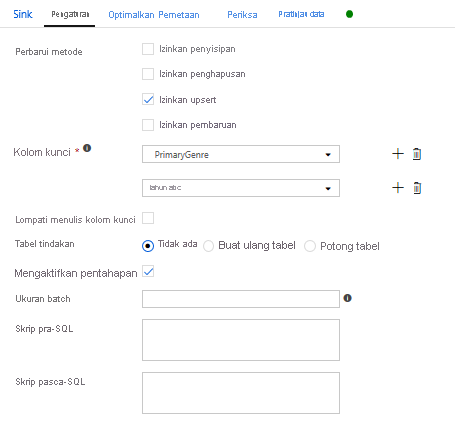
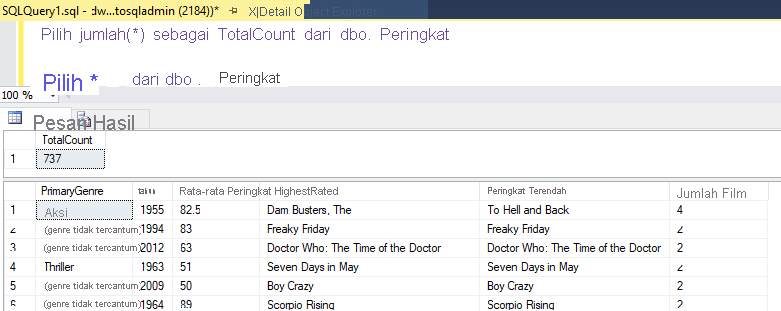
Pada proses ini, Anda telah selesai membangun 8 transformasi Aliran Data Pemetaan. Saatnya menjalankan alur dan melihat hasilnya!

Tugas 5: Menjalankan Alur
Buka tab pipeline1 di kanvas. Karena Azure Synapse Analytics di Aliran Data menggunakan PolyBase, Anda harus menentukan blob atau folder pentahapan ADLS. Di tab pengaturan aktivitas Jalankan Aliran Data, buka akordeon PolyBase dan pilih layanan tertaut ADLS Anda dan tentukan jalur folder pentahapan.
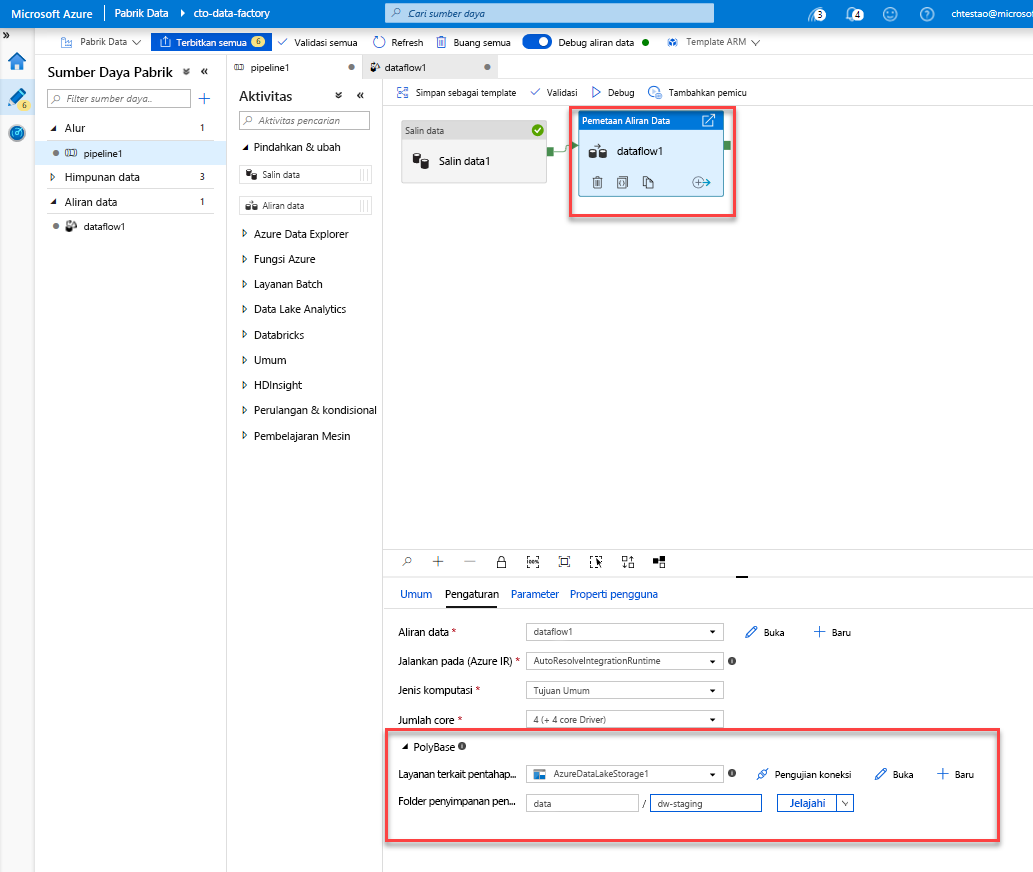
Sebelum Anda menerbitkan alur, jalankan proses debug lain untuk mengonfirmasi bahwa alur berfungsi seperti yang diharapkan. Melihat tab Output, Anda dapat memantau status kedua aktivitas saat sedang berjalan.
Setelah kedua aktivitas berhasil, Anda dapat mengklik ikon kacamata di sebelah aktivitas Aliran Data untuk melihat lebih dalam pada eksekusi Aliran Data.
Jika Anda menggunakan logika yang sama seperti yang dijelaskan di lab ini, Aliran Data Anda akan menulis 737 baris ke SQL DW Anda. Anda bisa masuk ke SQL Server Management Studio untuk memverifikasi bahwa alur berfungsi dengan benar dan melihat apa yang tertulis.