Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
BERLAKU UNTUK: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Aliran data tersedia di Alur Azure Data Factory dan Azure Synapse. Artikel ini berlaku untuk memetakan aliran data. Jika Anda baru mengenal transformasi, silakan lihat artikel pengantar Transformasi data menggunakan aliran data pemetaan.
Transformasi Agregat menentukan agregasi kolom di aliran data Anda. Menggunakan Penyusun Ekspresi, Anda dapat menentukan berbagai jenis agregasi seperti SUM, MIN, MAX, dan COUNT yang dikelompokkan menurut kolom yang sudah ada atau dihitung.
Kelompokkan berdasarkan
Pilih kolom yang sudah ada atau buat kolom komputasi baru untuk digunakan sebagai grup menurut klausul untuk agregasi Anda. Untuk menggunakan kolom yang sudah ada, pilih kolom tersebut dari dropdown. Untuk membuat kolom komputasi baru, arahkan kursor ke klausul dan klik Kolom komputasi. Ini membuka penyusun ekspresi aliran data. Setelah membuat kolom komputasi, masukkan nama kolom output di bawah bidangNama sebagai. Jika Anda ingin menambahkan grup tambahan menurut klausul, arahkan kursor ke klausul yang ada dan klik ikon plus.
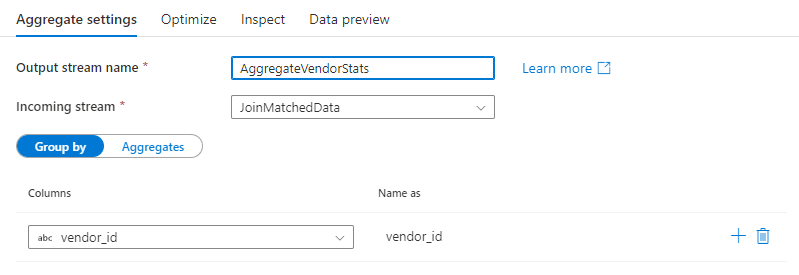
Grup menurut klausul bersifat opsional dalam transformasi Agregat.
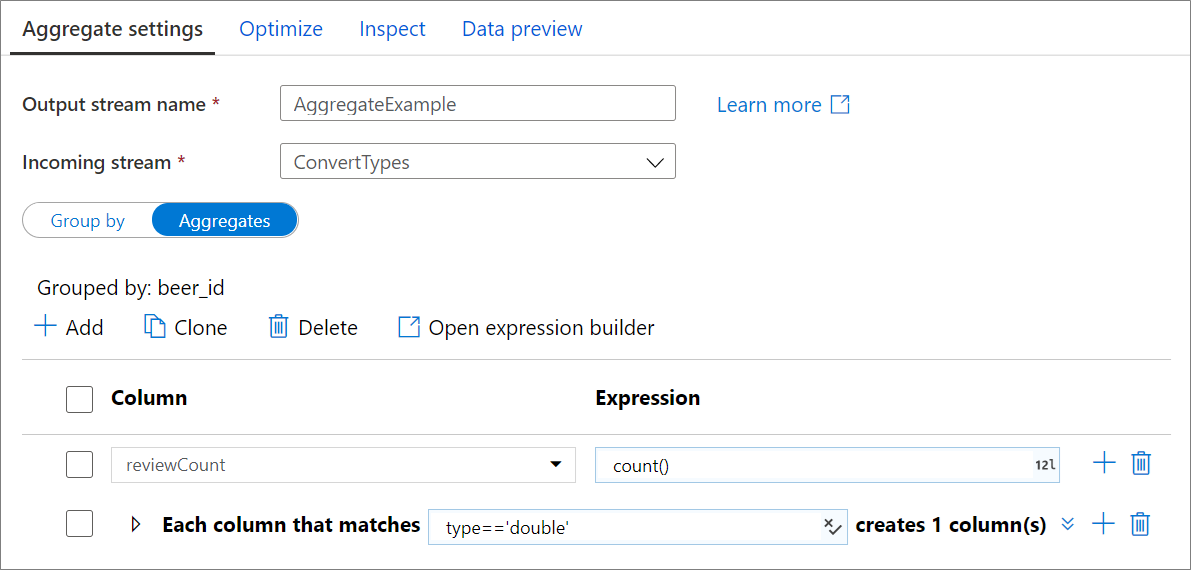
Kolom agregat
Buka tab Agregat untuk menyusun ekspresi agregasi. Anda dapat menimpa kolom yang sudah ada dengan agregasi, atau membuat bidang baru dengan nama baru. Ekspresi agregasi dimasukkan di kotak kanan di samping pemilih nama kolom. Untuk mengedit ekspresi, klik kotak teks dan buka penyusun ekspresi. Untuk menambahkan kolom agregat lainnya, klik Tambahkan di atas daftar kolom atau ikon plus di samping kolom agregat yang sudah ada. Pilih Tambahkan kolom atau Tambahkan pola kolom. Setiap ekspresi agregasi harus berisi setidaknya satu fungsi agregat.
Catatan
Dalam mode Debug, penyusun ekspresi tidak dapat menghasilkan pratinjau data dengan fungsi agregat. Untuk melihat pratinjau data untuk transformasi agregat, tutup pembangun ekspresi dan tampilkan data melalui tab 'Pratinjau Data'.
Pola kolom
Gunakan pola kolom untuk menerapkan agregasi yang sama ke set kolom. Hal ini berguna jika Anda ingin bertahan dengan banyak kolom dari skema input saat dihilangkan secara default. Gunakan heuristik seperti first() untuk mempertahankan kolom input melalui agregasi.
Menyambungkan kembali baris dan kolom
Transformasi agregat mirip dengan kueri pemilihan agregat SQL. Kolom yang tidak disertakan dalam grup Anda berdasarkan klausul atau fungsi agregat tidak akan mengalir ke output transformasi agregat Anda. Jika ingin menyertakan kolom lain dalam output agregat Anda, lakukan salah satu metode berikut:
- Gunakan fungsi agregat seperti
last()ataufirst()untuk menyertakan kolom tambahan tersebut. - Bergabung kembali dengan kolom ke aliran output Anda menggunakan pola gabungan mandiri.
Menghapus baris duplikat
Penggunaan umum transformasi agregat yaitu menghapus atau mengidentifikasi entri duplikat dalam data sumber. Proses ini dikenal sebagai deduplikasi. Berdasarkan satu set grup menurut kunci, gunakan heuristik pilihan Anda untuk menentukan baris duplikat mana yang akan disimpan. Heuristik umum adalah first(), last(), max(), dan min(). Gunakan pola kolom untuk menerapkan aturan ke setiap kolom kecuali untuk grup menurut kolom.
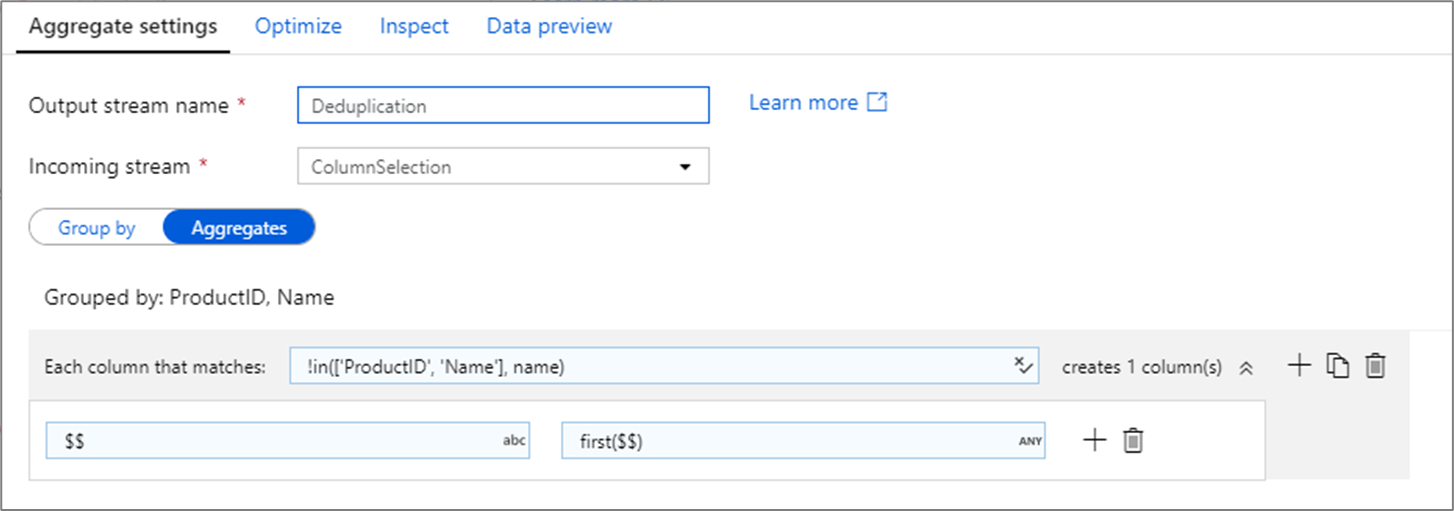
Dalam contoh di atas, kolomProductID dan Name sedang digunakan untuk pengelompokan. Jika dua baris memiliki nilai yang sama untuk dua kolom tersebut, baris tersebut dianggap sebagai duplikat. Dalam transformasi agregat ini, nilai baris pertama yang cocok akan disimpan dan semua lainnya akan dihilangkan. Menggunakan sintaks pola kolom, semua kolom yang namanya tidak ProductID dan Name dipetakan ke nama kolom yang sudah ada dan diberi nilai baris pertama yang cocok. Skema output sama dengan skema input.
Untuk skenario validasi data, fungsi count() ini dapat digunakan untuk menghitung berapa banyak duplikat yang ada.
Skrip aliran data
Sintaks
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
Contoh
Contoh di bawah ini mengambil aliran masuk MoviesYear dan grup baris menurut kolom year. Transformasi membuat kolom agregat avgrating yang dievaluasi ke rata-rata kolom Rating. Transformasi agregat ini dinamai AvgComedyRatingsByYear.
Di UI, transformasi ini terlihat seperti gambar di bawah ini:
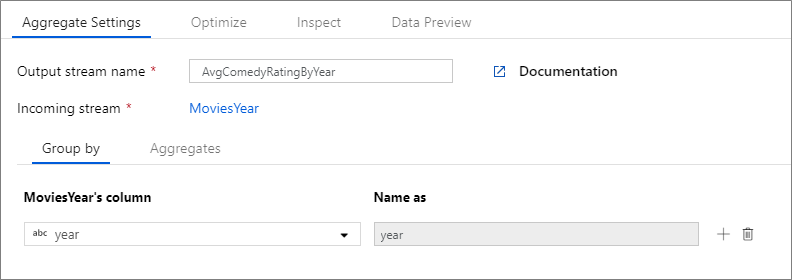
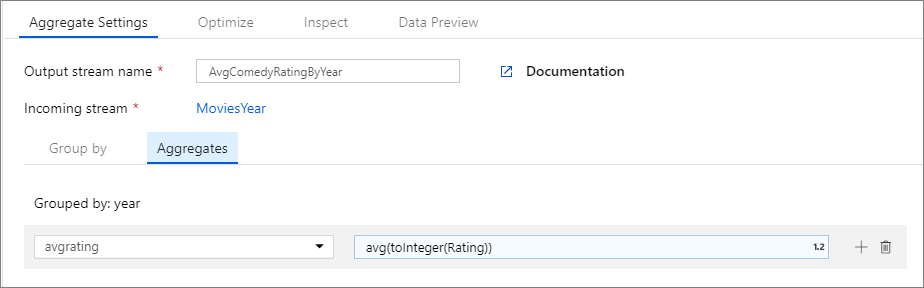
Skrip aliran data untuk transformasi ini ada di cuplikan di bawah ini.
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
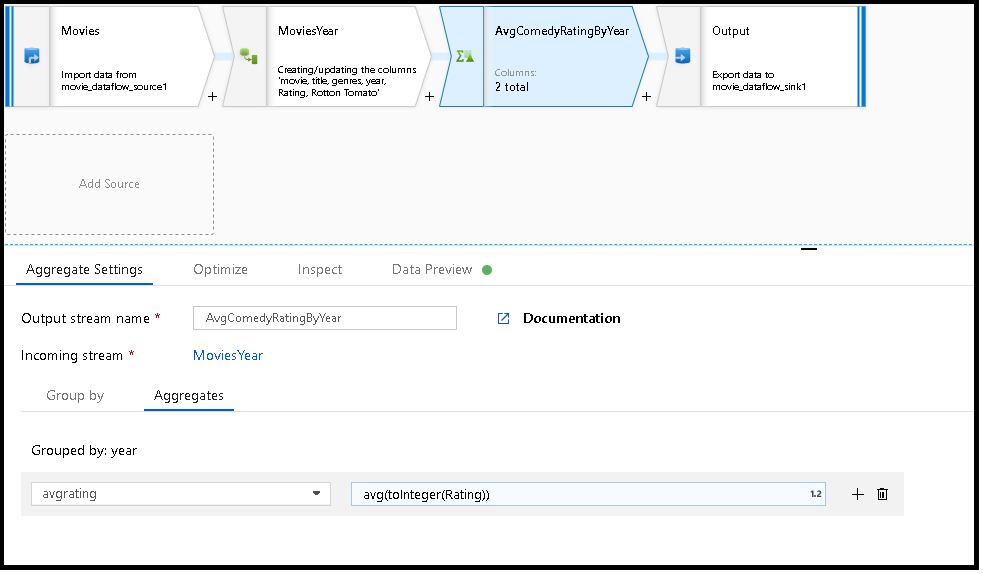
MoviesYear: Kolom Turunan mendefinisikan kolom tahun dan judul AvgComedyRatingByYear: Transformasi agregat untuk peringkat rata-rata komedi yang dikelompokkan menurut tahun avgrating: Nama kolom baru yang dibuat untuk menahan nilai agregat
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
Konten terkait
- Tentukan agregasi berbasis jendela menggunakanTransformasi jendela