Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pada tahap sebelumnya dari tutorial ini, kami menginstal PyTorch di komputer Anda. Sekarang, kita akan menggunakannya untuk menyiapkan kode kita dengan data yang akan kita gunakan untuk membuat model kita.
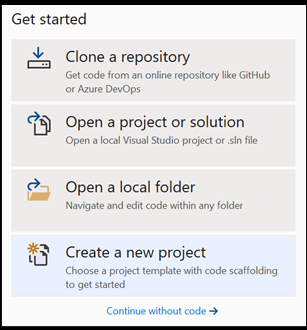
Buka proyek baru dalam Visual Studio.
- Buka Visual Studio dan pilih
create a new project.
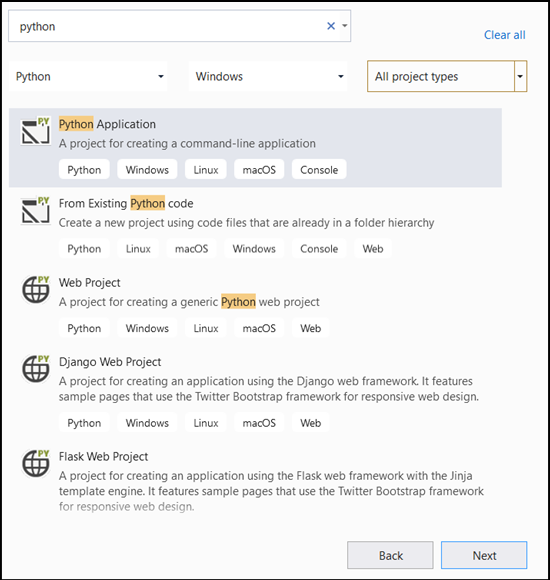
- Di bilah pencarian, ketik
Pythondan pilihPython Applicationsebagai templat proyek Anda.
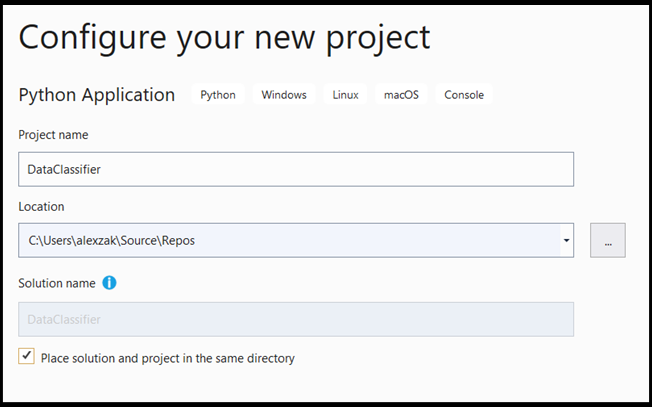
- Di jendela konfigurasi:
- Beri nama proyek Anda. Di sini, kami menyebutnya DataClassifier.
- Pilih lokasi proyek Anda.
- Jika Anda menggunakan VS2019, pastikan
Create directory for solutiondicentang. - Jika Anda menggunakan VS2017, pastikan
Place solution and project in the same directorytidak dicentang.
Tekan create untuk membuat proyek Anda.
Membuat penerjemah Python
Sekarang, Anda perlu menentukan penerjemah Python baru. Ini harus mencakup paket PyTorch yang baru saja Anda instal.
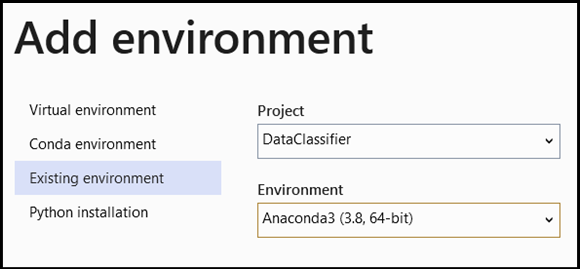
- Navigasikan ke pilihan penerjemah, dan pilih
Add Environment:

- Di jendela
Add Environment, pilihExisting environment, dan pilihAnaconda3 (3.6, 64-bit). Ini termasuk paket PyTorch.
Untuk menguji penerjemah Python baru dan paket PyTorch, masukkan kode berikut ke DataClassifier.py file:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
Output harus berupa tensor 5x3 acak yang mirip dengan di bawah ini.
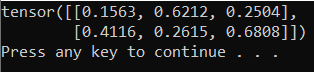
Nota
Tertarik untuk mempelajari lebih lanjut? Kunjungi situs web resmi PyTorch.
Memahami data
Kami akan melatih model pada himpunan data bunga Fisher's Iris. Himpunan data terkenal ini mencakup 50 catatan untuk masing-masing dari tiga spesies Iris: Iris setosa, Iris virginica, dan Iris versicolor.
Beberapa versi himpunan data telah diterbitkan. Anda dapat menemukan himpunan data Iris di Repositori Pembelajaran Mesin UCI, mengimpor himpunan data langsung dari pustaka Python Scikit-learn atau menggunakan versi lain yang sebelumnya diterbitkan. Untuk mempelajari tentang himpunan data bunga Iris, kunjungi halaman Wikipedia-nya.
Dalam tutorial ini, untuk menampilkan cara melatih model dengan jenis input tabular, Anda akan menggunakan himpunan data Iris yang diekspor ke file Excel.
Setiap baris tabel excel akan menampilkan empat fitur Irises: panjang sepal dalam cm, lebar sepal dalam cm, panjang kelopak dalam cm, dan lebar kelopak dalam cm. Fitur-fitur ini akan berfungsi sebagai input Anda. Kolom terakhir menyertakan jenis Iris yang terkait dengan parameter ini dan akan mewakili output regresi. Secara total, himpunan data mencakup 150 input dari empat fitur, masing-masing cocok dengan jenis Iris yang relevan.

Analisis regresi melihat hubungan antara variabel input dan hasilnya. Berdasarkan input, model akan belajar memprediksi jenis output yang benar - salah satu dari tiga jenis Iris: Iris-setosa, Iris-versicolor, Iris-virginica.
Penting
Jika Anda memutuskan untuk menggunakan himpunan data lain untuk membuat model Anda sendiri, Anda harus menentukan variabel input model dan output sesuai dengan skenario Anda.
Muat himpunan data.
Unduh himpunan data Iris dalam format Excel. Anda dapat menemukannya di sini.
DataClassifier.pyDalam file di folder File Penjelajah Solusi, tambahkan pernyataan impor berikut untuk mendapatkan akses ke semua paket yang akan kita butuhkan.
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
Seperti yang Anda lihat, Anda akan menggunakan paket panda (analisis data Python) untuk memuat dan memanipulasi data dan paket torch.nn yang berisi modul dan kelas yang dapat diperluas untuk membangun jaringan neural.
- Muat data ke dalam memori dan verifikasi jumlah kelas. Kami berharap untuk melihat 50 item dari setiap jenis Iris. Pastikan untuk menentukan lokasi himpunan data di PC Anda.
Tambahkan kode berikut ke file DataClassifier.py.
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
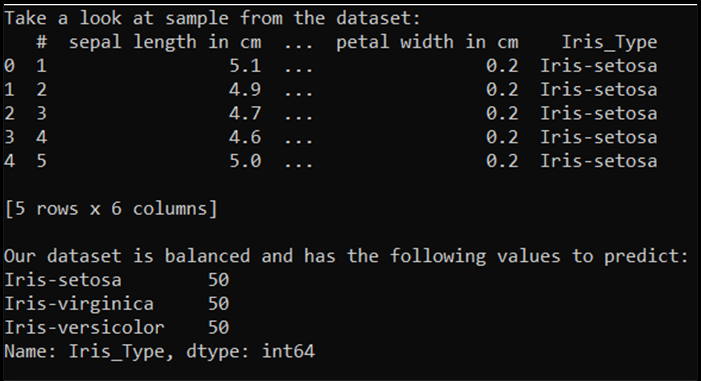
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
Ketika kita menjalankan kode ini, output yang diharapkan adalah sebagai berikut:
Agar dapat menggunakan himpunan data dan melatih model, kita perlu menentukan input dan output. Input mencakup 150 baris fitur, dan outputnya adalah kolom jenis Iris. Jaringan neural yang akan kita gunakan memerlukan variabel numerik, sehingga Anda akan mengonversi variabel output ke format numerik.
- Buat kolom baru dalam himpunan data yang akan mewakili output dalam format numerik dan menentukan input dan output regresi.
Tambahkan kode berikut ke file DataClassifier.py.
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
Ketika kita menjalankan kode ini, output yang diharapkan adalah sebagai berikut:
Input dan output
Untuk melatih model, kita perlu mengonversi input dan output model ke format Tensor:
- Konversi ke Tensor:
Tambahkan kode berikut ke file DataClassifier.py.
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
Jika kita menjalankan kode, output yang diharapkan akan menampilkan format input dan output, sebagai berikut:

Ada 150 nilai input. Sekitar 60% akan digunakan sebagai data pelatihan model. Anda akan menyimpan 20% untuk validasi dan 30% untuk pengujian.
Dalam tutorial ini, ukuran batch untuk himpunan data pelatihan didefinisikan sebagai 10. Ada 95 elemen dalam set pelatihan, yang berarti secara rata-rata, ada 9 batch lengkap untuk menjalankan set pelatihan satu kali (satu epoch). Anda akan menyimpan ukuran batch validasi dan set pengujian sebanyak 1.
- Pisahkan data untuk melatih, memvalidasi, dan menguji set:
Tambahkan kode berikut ke file DataClassifier.py.
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
Langkah Selanjutnya
Dengan data siap digunakan, saatnya untuk melatih model PyTorch kami