Caricare dati in modo incrementale da un database SQL di Azure all'archiviazione BLOB di Azure tramite il rilevamento delle modifiche con PowerShell
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
In questa esercitazione si creerà una data factory di Azure con una pipeline che carica dati differenziali basati su informazioni di rilevamento delle modifiche nel database di origine del database SQL di Azure in una risorsa di Archiviazione BLOB di Azure.
In questa esercitazione vengono completati i passaggi seguenti:
- Preparare l'archivio dati di origine.
- Creare una data factory.
- Creare servizi collegati.
- Creare set di dati di origine, sink e di rilevamento delle modifiche.
- Creare, eseguire e monitorare la pipeline di copia completa
- Aggiungere o aggiornare dati nella tabella di origine
- Creare, eseguire e monitorare la pipeline di copia incrementale
Nota
È consigliabile usare il modulo Azure Az PowerShell per interagire con Azure. Per iniziare, vedere Installare Azure PowerShell. Per informazioni su come eseguire la migrazione al modulo AZ PowerShell, vedere Eseguire la migrazione di Azure PowerShell da AzureRM ad Az.
Panoramica
In una soluzione di integrazione dei dati il caricamento incrementale di dati dopo i caricamenti di dati iniziali è uno scenario ampiamente diffuso. In alcuni casi, i dati modificati entro un periodo di tempo nell'archivio dati di origine possono essere suddivisi facilmente, ad esempio con LastModifyTime e CreationTime. In alcuni casi, non esiste un modo esplicito per identificare i dati differenziali dall'ultima elaborazione dei dati. È possibile usare la tecnologia Rilevamento modifiche supportata da archivi dati come il database SQL di Azure e SQL Server per identificare i dati differenziali. Questa esercitazione descrive come usare Azure Data Factory con la tecnologia Rilevamento modifiche SQL per caricare in modo incrementare dati differenziali dal database SQL di Azure in Archiviazione BLOB di Azure. Per altre informazioni pratiche sulla tecnologia Rilevamento modifiche SQL, vedere Rilevamento modifiche in SQL Server.
Flusso di lavoro end-to-end
Ecco alcuni passaggi del tipico flusso di lavoro end-to-end per caricare dati in modo incrementale usando la tecnologia Rilevamento modifiche.
Nota
Sia il database SQL di Azure sia SQL Server supportano la tecnologia Rilevamento modifiche. Questa esercitazione usa il database SQL di Azure come archivio dati di origine. È anche possibile usare un'istanza di SQL Server.
- Caricamento iniziale dei dati cronologici (esecuzione una sola volta):
- Abilitare la tecnologia Rilevamento modifiche nel database di origine del database SQL di Azure.
- Ottenere il valore iniziale di SYS_CHANGE_VERSION nel database come base per acquisire i dati modificati.
- Caricare i dati completi dal database di origine a una risorsa di Archiviazione BLOB di Azure.
- Caricamento incrementale dei dati differenziali in base a una pianificazione (eseguito periodicamente dopo il caricamento iniziale dei dati):
- Ottenere i valori precedente e nuovo di SYS_CHANGE_VERSION.
- Caricare i dati differenziali unendo le chiavi primarie delle righe modificate (tra due valori di SYS_CHANGE_VERSION) da sys.change_tracking_tables ai dati nella tabella di origine e quindi spostare i dati differenziali nella destinazione.
- Aggiornare SYS_CHANGE_VERSION per il successivo caricamento differenziale.
Soluzione di alto livello
In questa esercitazione vengono create due pipeline che eseguono le due operazioni seguenti:
Caricamento iniziale: viene creata una pipeline con un'attività di copia che copia tutti i dati dall'archivio dati di origine (database SQL di Azure) all'archivio dati di destinazione (archiviazione BLOB di Azure).

Caricamento incrementale: viene creata una pipeline con le attività seguenti, eseguita periodicamente.
- Creare due attività di ricerca per ottenere i valori precedente e nuovo di SYS_CHANGE_VERSION dal database SQL di Azure e passarli all'attività di copia.
- Creare un'attività di copia per copiare i dati inseriti/aggiornati/eliminati tra i due valori di SYS_CHANGE_VERSION dal database SQL di Azure all'archiviazione BLOB di Azure.
- Creare un'attività stored procedure per aggiornare il valore di SYS_CHANGE_VERSION per la successiva esecuzione di pipeline.

Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
- Azure PowerShell. Installare i moduli di Azure PowerShell più recenti seguendo le istruzioni descritte in Come installare e configurare Azure PowerShell.
- Database SQL di Azure. Usare il database come archivio dati di origine. Se non si ha un database nel database SQL di Azure, vedere la procedura per crearne uno nell'articolo Creare un database nel database SQL di Azure.
- Account di archiviazione di Azure. Usare l'archivio BLOB come archivio dati sink. Se non si ha un account di archiviazione di Azure, vedere l'articolo Creare un account di archiviazione per informazioni su come crearne uno. Creare un contenitore denominato adftutorial.
Creare una tabella di origine dati nel database
Avviare SQL Server Management Studio e connettersi al database SQL.
In Esplora server fare clic con il pulsante destro del mouse sul database e scegliere Nuova query.
Eseguire questo comando SQL sul database per creare una tabella denominata
data_source_tablecome archivio dell'origine dati.create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Abilitare il meccanismo Rilevamento modifiche nel database e nella tabella di origine (data_source_table) eseguendo la query SQL seguente:
Nota
- Sostituire <your database name> con il nome del database che include data_source_table.
- Nell'esempio corrente i dati modificati vengono mantenuti per due giorni. Se i dati modificati vengono caricati ogni tre giorni o più, alcuni non verranno inclusi. In questo caso, è necessario modificare il valore di CHANGE_RETENTION impostando un numero maggiore. In alternativa, assicurarsi che il periodo per il caricamento dei dati modificati sia non più di due giorni. Per altre informazioni, vedere Abilitare il rilevamento delle modifiche per un database
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)Creare una nuova tabella e archiviare ChangeTracking_version con un valore predefinito eseguendo la query seguente:
create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Nota
Se i dati non vengono modificati dopo aver abilitato il rilevamento delle modifiche per il database SQL, il valore della versione di rilevamento delle modifiche è 0.
Eseguire la query seguente per creare una stored procedure nel database. La pipeline richiama questa stored procedure per aggiornare la versione di rilevamento delle modifiche nella tabella creata nel passaggio precedente.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Azure PowerShell
Installare i moduli di Azure PowerShell più recenti seguendo le istruzioni descritte in Come installare e configurare Azure PowerShell.
Creare una data factory
Definire una variabile per il nome del gruppo di risorse usato in seguito nei comandi di PowerShell. Copiare il testo del comando seguente in PowerShell, specificare un nome per il gruppo di risorse di Azure tra virgolette doppie e quindi eseguire il comando. Ad esempio:
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Se il gruppo di risorse esiste già, potrebbe essere preferibile non sovrascriverlo. Assegnare un valore diverso alla variabile
$resourceGroupNameed eseguire di nuovo il comando.Definire una variabile per la località della data factory:
$location = "East US"Per creare il gruppo di risorse di Azure, eseguire questo comando:
New-AzResourceGroup $resourceGroupName $locationSe il gruppo di risorse esiste già, potrebbe essere preferibile non sovrascriverlo. Assegnare un valore diverso alla variabile
$resourceGroupNameed eseguire di nuovo il comando.Definire una variabile per il nome della data factory.
Importante
Aggiornare il nome della data factory in modo che sia univoco a livello globale.
$dataFactoryName = "IncCopyChgTrackingDF";Per creare la data factory, eseguire questo cmdlet Set-AzDataFactoryV2:
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Notare i punti seguenti:
È necessario specificare un nome univoco globale per l'istanza di Azure Data Factory. Se viene visualizzato l'errore seguente, modificare il nome e riprovare.
The specified Data Factory name 'ADFIncCopyChangeTrackingTestFactory' is already in use. Data Factory names must be globally unique.Per creare istanze di Data Factory, l'account utente usato per accedere ad Azure deve essere un membro dei ruoli collaboratore o proprietario oppure un amministratore della sottoscrizione di Azure.
Per un elenco di aree di Azure in cui Data Factory è attualmente disponibile, selezionare le aree di interesse nella pagina seguente, quindi espandere Analytics per individuare Data Factory: Prodotti disponibili in base all'area. Gli archivi dati (Archiviazione di Azure, database SQL di Azure e così via) e le risorse di calcolo (HDInsight e così via) usati dalla data factory possono trovarsi in altre aree.
Creare servizi collegati
Si creano servizi collegati in una data factory per collegare gli archivi dati e i servizi di calcolo alla data factory. In questa sezione si creano servizi collegati all'account di archiviazione di Azure e al database nel database SQL di Azure.
Creare il servizio collegato Archiviazione di Azure.
In questo passaggio l'account di archiviazione di Azure viene collegato alla data factory.
Creare un file JSON denominato AzureStorageLinkedService.json nella cartella C:\ADFTutorials\IncCopyChangeTrackingTutorial con il contenuto seguente. Creare la cartella se non esiste già. Sostituire
<accountName>,<accountKey>con il nome e la chiave dell'account di archiviazione di Azure prima di salvare il file.{ "name": "AzureStorageLinkedService", "properties": { "type": "AzureStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>" } } }In Azure PowerShell passare alla cartella C:\ADFTutorials\IncCopyChangeTrackingTutorial.
Eseguire il cmdlet Set-AzDataFactoryV2LinkedService per creare il servizio collegato: Azure Archiviazione LinkedService. Nell'esempio seguente si passano i valori per i parametri ResourceGroupName e DataFactoryName.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Di seguito è riportato l'output di esempio:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureStorageLinkedService
Creare un servizio collegato Database SQL di Azure.
In questo passaggio si collega il database alla data factory.
Creare un file JSON denominato AzureSQLDatabaseLinkedService.json nella cartella C:\ADFTutorials\IncCopyChangeTrackingTutorial con il contenuto seguente: Sostituire il< nome> del database del server<>, <l'ID> utente e <la password> con il nome del server, il nome del database, l'ID utente e la password prima di salvare il file.
{ "name": "AzureSQLDatabaseLinkedService", "properties": { "type": "AzureSqlDatabase", "typeProperties": { "connectionString": "Server = tcp:<server>.database.windows.net,1433;Initial Catalog=<database name>; Persist Security Info=False; User ID=<user name>; Password=<password>; MultipleActiveResultSets = False; Encrypt = True; TrustServerCertificate = False; Connection Timeout = 30;" } } }In Azure PowerShell eseguire il cmdlet Set-AzDataFactoryV2LinkedService per creare il servizio collegato AzureSQLDatabaseLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Di seguito è riportato l'output di esempio:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Creare i set di dati
In questo passaggio vengono creati i set di dati per rappresentare l'origine dati, la destinazione dati e la posizione in cui archiviare SYS_CHANGE_VERSION.
Creare set di dati di origine
In questo passaggio viene creato un set di dati per rappresentare i dati di origine.
Creare un file JSON denominato SourceDataset.json nella stessa cartella con il contenuto seguente:
{ "name": "SourceDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "data_source_table" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Eseguire il cmdlet Set-AzDataFactoryV2Dataset per creare il set di dati: SourceDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Ecco l'output di esempio del cmdlet:
DatasetName : SourceDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Creare un set di dati sink
In questo passaggio viene creato un set di dati per rappresentare i dati copiati dall'archivio dati di origine.
Creare un file JSON denominato SinkDataset.json nella stessa cartella con il contenuto seguente:
{ "name": "SinkDataset", "properties": { "type": "AzureBlob", "typeProperties": { "folderPath": "adftutorial/incchgtracking", "fileName": "@CONCAT('Incremental-', pipeline().RunId, '.txt')", "format": { "type": "TextFormat" } }, "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" } } }Come parte dei prerequisiti, è necessario creare il contenitore adftutorial nell'archiviazione BLOB di Azure. Creare il contenitore se non esiste oppure impostare il nome di un contenitore esistente. In questa esercitazione il nome del file di output viene generato dinamicamente usando l'espressione : @CONCAT('Incremental-', pipeline(). RunId, '.txt').
Eseguire il cmdlet Set-AzDataFactoryV2Dataset per creare il set di dati: SinkDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Ecco l'output di esempio del cmdlet:
DatasetName : SinkDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobDataset
Creare un set di dati di rilevamento delle modifiche
In questo passaggio viene creato un set di dati per l'archiviazione della versione di rilevamento delle modifiche.
Creare un file JSON denominato ChangeTrackingDataset.json nella stessa cartella con il contenuto seguente:
{ "name": " ChangeTrackingDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "table_store_ChangeTracking_version" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Come parte dei prerequisiti, è necessario creare la tabella table_store_ChangeTracking_version.
Eseguire il cmdlet Set-AzDataFactoryV2Dataset per creare il set di dati: ChangeTrackingDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "ChangeTrackingDataset" -File ".\ChangeTrackingDataset.json"Ecco l'output di esempio del cmdlet:
DatasetName : ChangeTrackingDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Creare una pipeline per la copia completa
In questo passaggio viene creata una pipeline con un'attività di copia che copia tutti i dati dall'archivio dati di origine (database SQL di Azure) all'archivio dati di destinazione (Archiviazione BLOB di Azure).
Creare un file JSON denominato FullCopyPipeline.json nella stessa cartella con il contenuto seguente:
{ "name": "FullCopyPipeline", "properties": { "activities": [{ "name": "FullCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource" }, "sink": { "type": "BlobSink" } }, "inputs": [{ "referenceName": "SourceDataset", "type": "DatasetReference" }], "outputs": [{ "referenceName": "SinkDataset", "type": "DatasetReference" }] }] } }Eseguire il cmdlet Set-AzDataFactoryV2Pipeline per creare la pipeline FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "FullCopyPipeline" -File ".\FullCopyPipeline.json"Di seguito è riportato l'output di esempio:
PipelineName : FullCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {FullCopyActivity} Parameters :
Eseguire la pipeline di copia completa
Eseguire la pipeline FullCopyPipeline usando il cmdlet Invoke-AzDataFactoryV2Pipeline.
Invoke-AzDataFactoryV2Pipeline -PipelineName "FullCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Monitorare la pipeline di copia completa
Accedere al portale di Azure.
Fare clic su Tutti i servizi, eseguire una ricerca con la parola chiave
data factoriese selezionare Data factory.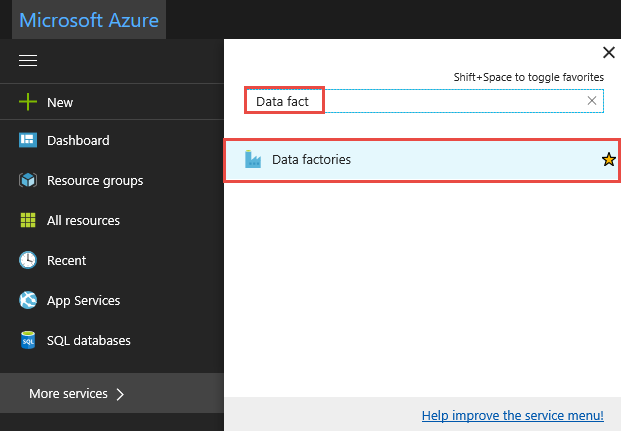
Cercare la propria data factory nell'elenco delle data factory e selezionarla per avviare la pagina Data factory.
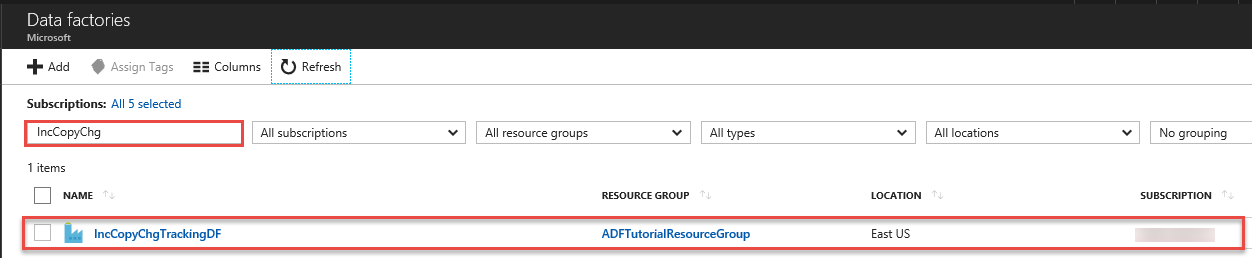
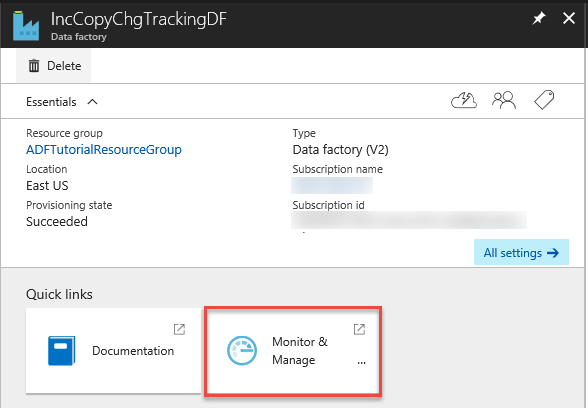
Nella pagina Data factory fare clic sul riquadro Monitoraggio e gestione.
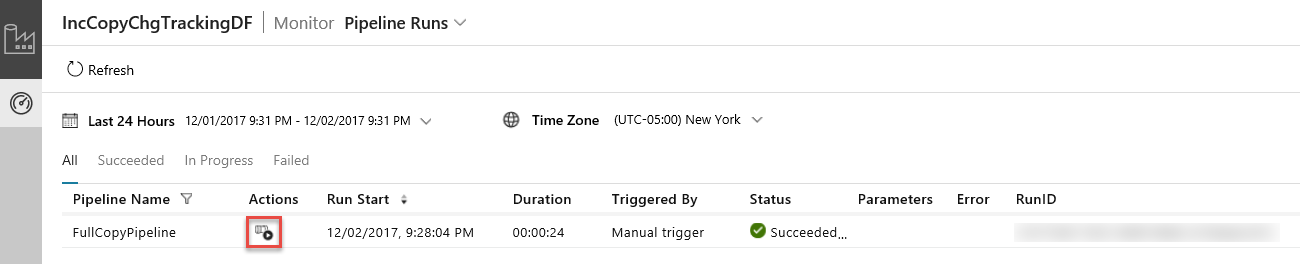
L'applicazione Integrazione dei dati viene avviata in una scheda separata. È possibile visualizzare tutte le esecuzioni della pipeline e i relativi stati. Notare che nell'esempio seguente lo stato dell'esecuzione della pipeline è Riuscito. È possibile controllare i parametri passati alla pipeline facendo clic sul collegamento nella colonna Parametri. Se si è verificato un errore, verrà visualizzato un collegamento nella colonna Errore. Fare clic sul collegamento nella colonna Azioni.
Quando si fa clic sul collegamento nella colonna Azioni, viene visualizzata la pagina seguente, che mostra tutte le esecuzioni di attività per la pipeline.
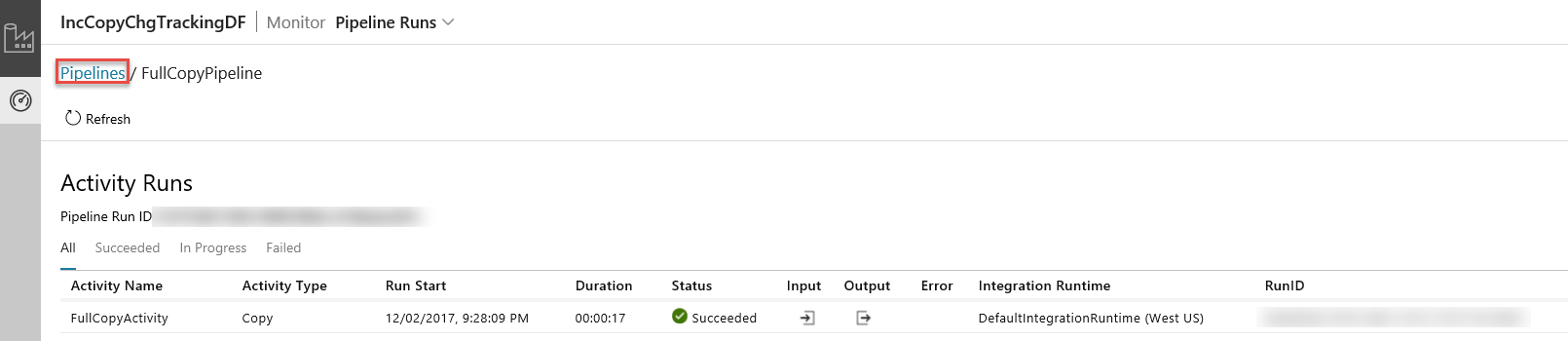
Per tornare alla visualizzazione Esecuzioni di pipeline, fare clic su Pipeline, come mostrato nell'immagine.
Esaminare i risultati
Viene visualizzato un file denominato incremental-<GUID>.txt nella cartella incchgtracking del contenitore adftutorial.
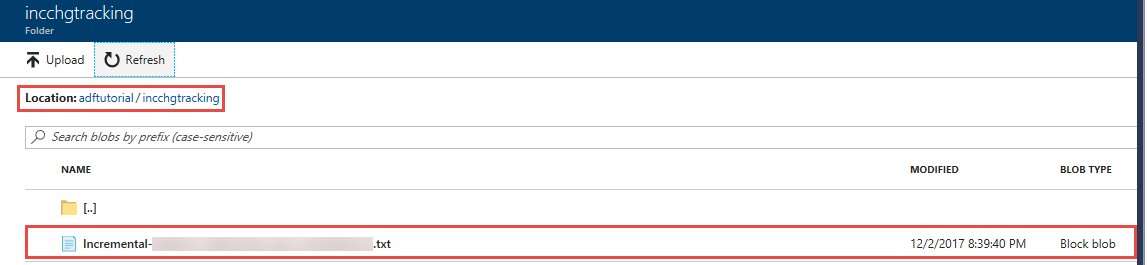
Il file conterrà i dati del database:
1,aaaa,21
2,bbbb,24
3,cccc,20
4,dddd,26
5,eeee,22
Aggiungere altri dati alla tabella di origine
Eseguire la query seguente sul database per aggiungere una riga e aggiornare una riga.
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Creare una pipeline per la copia differenziale
In questo passaggio viene creata una pipeline con le attività seguenti, eseguita periodicamente. Le attività di ricerca ottengono i valori precedente e nuovo di SYS_CHANGE_VERSION dal database SQL di Azure e li passano all'attività di copia. L'attività di copia copia i dati inseriti/aggiornati/eliminati tra i due valori di SYS_CHANGE_VERSION dal database SQL di Azure all'archiviazione BLOB di Azure. L'attività stored procedure aggiorna il valore di SYS_CHANGE_VERSION per la successiva esecuzione di pipeline.
Creare un file JSON denominato IncrementalCopyPipeline.json nella stessa cartella con il contenuto seguente:
{ "name": "IncrementalCopyPipeline", "properties": { "activities": [ { "name": "LookupLastChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select * from table_store_ChangeTracking_version" }, "dataset": { "referenceName": "ChangeTrackingDataset", "type": "DatasetReference" } } }, { "name": "LookupCurrentChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion" }, "dataset": { "referenceName": "SourceDataset", "type": "DatasetReference" } } }, { "name": "IncrementalCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) as CT on data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}" }, "sink": { "type": "BlobSink" } }, "dependsOn": [ { "activity": "LookupLastChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] }, { "activity": "LookupCurrentChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] } ], "inputs": [ { "referenceName": "SourceDataset", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "SinkDataset", "type": "DatasetReference" } ] }, { "name": "StoredProceduretoUpdateChangeTrackingActivity", "type": "SqlServerStoredProcedure", "typeProperties": { "storedProcedureName": "Update_ChangeTracking_Version", "storedProcedureParameters": { "CurrentTrackingVersion": { "value": "@{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}", "type": "INT64" }, "TableName": { "value": "@{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}", "type": "String" } } }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" }, "dependsOn": [ { "activity": "IncrementalCopyActivity", "dependencyConditions": [ "Succeeded" ] } ] } ] } }Eseguire il cmdlet Set-AzDataFactoryV2Pipeline per creare la pipeline FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Di seguito è riportato l'output di esempio:
PipelineName : IncrementalCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {LookupLastChangeTrackingVersionActivity, LookupCurrentChangeTrackingVersionActivity, IncrementalCopyActivity, StoredProceduretoUpdateChangeTrackingActivity} Parameters :
Eseguire la pipeline di copia incrementale
Eseguire la pipeline IncrementalCopyPipeline usando il cmdlet Invoke-AzDataFactoryV2Pipeline.
Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Monitorare la pipeline di copia incrementale
Nell'applicazione Integrazione dati aggiornare la visualizzazione Esecuzioni di pipeline. Verificare che la pipeline IncrementalCopyPipeline sia visualizzata nell'elenco. Fare clic sul collegamento nella colonna Azioni.
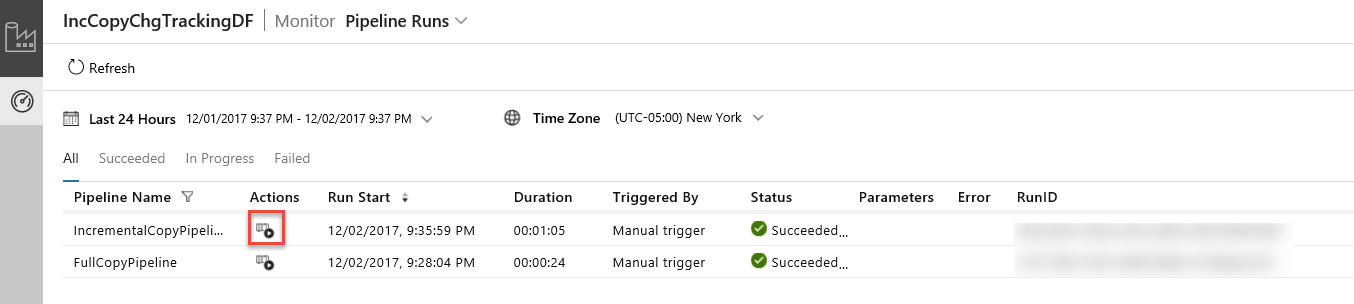
Quando si fa clic sul collegamento nella colonna Azioni, viene visualizzata la pagina seguente, che mostra tutte le esecuzioni di attività per la pipeline.
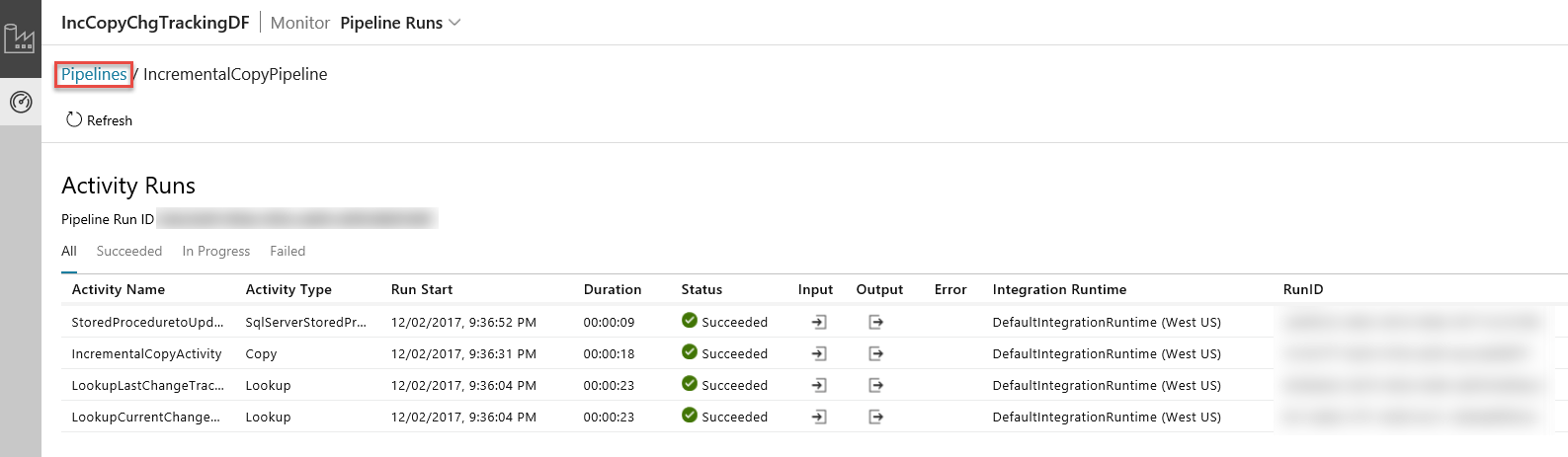
Per tornare alla visualizzazione Esecuzioni di pipeline, fare clic su Pipeline, come mostrato nell'immagine.
Esaminare i risultati
Il secondo file viene visualizzato nella cartella incchgtracking del contenitore adftutorial.
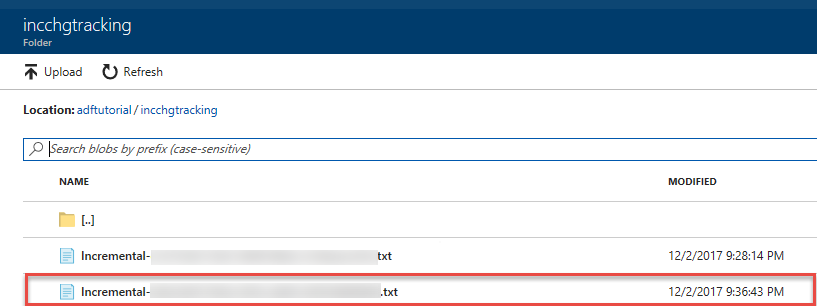
Il file conterrà solo i dati differenziali del database. Il record con U è la riga aggiornata nel database e I è la riga aggiunta.
1,update,10,2,U
6,new,50,1,I
Le prime tre colonne sono i dati modificati da data_source_table. Le ultime due colonne sono i metadati dalla tabella di sistema del rilevamento delle modifiche. La quarta colonna è SYS_CHANGE_VERSION per ogni riga modificata. La quinta colonna è l'operazione: U = aggiornamento, I = inserimento. Per tutti i dettagli sulle informazioni di rilevamento delle modifiche, vedere CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Contenuto correlato
Passare all'esercitazione successiva per informazioni sulla copia di file nuovi e modificati solo in base a LastModifiedDate:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per