Configurare il training di ML automatizzato senza codice per i dati tabulari con l'interfaccia utente di studio
Questo articolo illustra come configurare processi di training di Machine Learning automatizzato usando ML automatizzato di Azure Machine Learning in studio di Azure Machine Learning. Questo approccio consente di configurare il processo senza scrivere una singola riga di codice. Ml automatizzato è un processo in cui Azure Machine Learning seleziona l'algoritmo di Machine Learning migliore per i dati specifici. Il processo consente di generare rapidamente modelli di Machine Learning. Per altre informazioni, vedere Panoramica del processo di Machine Learning automatizzato.
Questa esercitazione offre una panoramica generale per l'uso di Machine Learning automatizzato in studio. Gli articoli seguenti forniscono istruzioni dettagliate per l'uso di modelli di Machine Learning specifici:
- Classificazione: Esercitazione: Eseguire il training di un modello di classificazione con ML automatizzato in studio
- Previsione di serie temporali: Esercitazione: Prevedere la domanda con ML automatizzato in studio
- Elaborazione del linguaggio naturale (NLP): Configurare ML automatizzato per eseguire il training di un modello NLP (SDK Python o interfaccia della riga di comando di Azure)
- Visione artificiale: Configurare AutoML per eseguire il training di modelli di visione artificiale (SDK Python o interfaccia della riga di comando di Azure)
- Regressione: Eseguire il training di un modello di regressione con ML automatizzato (SDK Python)
Prerequisiti
Una sottoscrizione di Azure. È possibile creare un account gratuito o a pagamento per Azure Machine Learning.
Un'area di lavoro di Azure Machine Learning e un'istanza dell’ambiente di calcolo. Per preparare queste risorse, vedere Guida introduttiva: Introduzione ad Azure Machine Learning.
Asset di dati da usare per il processo di training di Machine Learning automatizzato. Questa esercitazione descrive come selezionare un asset di dati esistente o creare un asset di dati da un'origine dati, ad esempio un file locale, un URL Web o un archivio dati. Per altre informazioni, vedere Creare e gestire asset di dati.
Importante
Esistono due requisiti per i dati di training:
- I dati devono essere in formato tabulare.
- Il valore che si desidera prevedere (la colonna di destinazione) deve essere presente nei dati.
Creare un esperimento
Creare ed eseguire un esperimento seguendo questa procedura:
Accedere ad Azure Machine Learning Studio e selezionare la sottoscrizione e l'area di lavoro.
Nel riquadro sinistro selezionare ML automatizzato nella sezione Creazione:
La prima volta che si lavora con gli esperimenti in studio, vengono visualizzati un elenco vuoto e i collegamenti alla documentazione. In caso contrario, viene visualizzato un elenco degli esperimenti di ML automatizzato recenti, inclusi gli elementi creati con l'SDK di Azure Machine Learning.
Selezionare Nuovo processo di ML automatizzato per avviare il processo Invia un processo di ML automatizzato.
Per impostazione predefinita, il processo seleziona l'opzione Esegui training automaticamente nella scheda Metodo di training e continua con le impostazioni di configurazione.
Nella scheda Impostazioni di base, immettere i valori per le impostazioni richieste, inclusi il nome del Processo e il nome dell'Esperimento. È anche possibile specificare i valori per le impostazioni facoltative, come desiderato.
Selezionare Avanti per continuare.

Identificare l'asset di dati
Nella scheda Tipo attività e dati, specificare l'asset di dati per l'esperimento e il modello di Machine Learning da usare per eseguire il training dei dati.
In questa esercitazione, è possibile usare un asset di dati esistente o creare un nuovo asset di dati da un file nel computer locale. Le pagine dell'interfaccia utente di studio cambiano in base alla selezione dell'origine dati e aNDl tipo di modello di training.
Se si sceglie di usare un asset di dati esistente, è possibile continuare con la sezione Configurare il modello di training.
Per creare un nuovo asset di dati, seguire questa procedura:
Per creare un nuovo asset di dati da un file nel computer locale, selezionare Crea.
Nella pagina Tipo di dati:
- Immettere un nome per l'Asset di dati.
- Per Tipo, selezionare Tabulare dall'elenco a discesa.
- Selezionare Avanti.
Nella pagina Origine dati, selezionare Da file locali.
Studio di Machine Learning aggiunge opzioni aggiuntive al menu a sinistra per configurare l'origine dati.
Selezionare Avanti per passare alla pagina Tipo di archiviazione di destinazione, in cui si specifica il percorso di Archiviazione di Azure per caricare l'asset di dati.
È possibile specificare il contenitore di archiviazione predefinito creato automaticamente con l'area di lavoro o scegliere un contenitore di archiviazione da usare per l'esperimento.
- Per Tipo di archivio dati, selezionare Archiviazione BLOB di Azure.
- Nell'elenco degli archivi dati, selezionare workspaceblobstore.
- Selezionare Avanti.
Nella pagina Selezione file e cartelle, usare il menu a discesa Carica file o cartelle e selezionare l'opzione Carica file o Carica cartella.
- Passare al percorso dei dati da caricare e selezionare Apri.
- Dopo il caricamento dei file, selezionare Avanti.
Studio di Machine Learning convalida e carica i dati.
Nota
Se i dati si trovano dietro una rete virtuale, è necessario abilitare la funzionalità Ignora la convalida per assicurarsi che l'area di lavoro possa accedere ai dati. Per altre informazioni, vedere Usare studio di Azure Machine Learning in una rete virtuale di Azure.
Controllare i dati caricati nella pagina Impostazioni per verificarne l'accuratezza. I campi nella pagina vengono precompilati in base al tipo di file dei dati:
Campo Descrizione Formato file Definisce il layout e il tipo di dati archiviati in un file. Delimitatore Identifica uno o più caratteri per specificare il limite tra aree distinte indipendenti in testo normale o altri flussi di dati. Encoding Identifica la tabella dello schema bit-carattere da usare per leggere il set di dati. Intestazioni di colonna Indica come verranno considerate le intestazioni del set di dati, se presenti. Ignora righe Indica quante righe vengono eventualmente ignorate nel set di dati. Selezionare Avanti per continuare con la pagina Schema. Anche questa pagina è precompilata in base alle selezioni delle Impostazioni. È possibile configurare il tipo di dati per ogni colonna, esaminare i nomi delle colonne e gestire le colonne:
- Per modificare il tipo di dati per una colonna, usare il menu a discesa Tipo per selezionare un'opzione.
- Per escludere una colonna dall'asset di dati, attivare o disattivare l'opzione Includi per la colonna.
Selezionare Avanti per continuare con la pagina Rivedi. Rivedere il riepilogo delle impostazioni di configurazione per il processo, quindi selezionare Crea.
Configurare il modello di training
Quando l'asset di dati è pronto, Studio di Machine Learning torna alla scheda Tipo di attività e dati per il processo Invia un processo di ML automatizzato. Il nuovo asset di dati è elencato nella pagina.
Per completare la configurazione del processo, seguire questa procedura:
Espandere il menu a discesa Seleziona tipo di attività e scegliere il modello di training da usare per l'esperimento. Le opzioni includono classificazione, regressione, previsione delle serie temporali, elaborazione del linguaggio naturale (NLP) o visione artificiale. Per altre informazioni su queste opzioni, vedere le descrizioni dei tipi di attività supportati.
Dopo aver specificato il modello di training, selezionare il set di dati nell'elenco.
Selezionare Avanti per continuare con la scheda Impostazioni attività.
Nell'elenco a discesa Colonna di destinazione, selezionare la colonna da usare per le stime del modello.
A seconda del modello di training, configurare le impostazioni necessarie seguenti:
Classificazione: scegliere se abilitare l'apprendimento avanzato.
Previsione di serie temporali: scegliere se abilitare l'apprendimento avanzato e confermare le preferenze per le impostazioni necessarie:
Usare la Colonna ora per specificare i dati relativi all'ora da usare nel modello.
Scegliere se abilitare una o più opzioni di rilevamento automatico. Quando si deseleziona un'opzione di Rilevamento automatico, ad esempio Orizzonte previsione di rilevamento automatico, è possibile indicare un valore specifico. Il valore dell'orizzonte di previsione indica il numero di unità di tempo (minuti/ore/giorni/settimane/mesi/anni) che il modello prevede per il futuro. Maggiore è il tempo per il quale il modello deve effettuare previsioni nel futuro, minore sarà il livello di precisione.
Per altre informazioni su come configurare queste impostazioni, vedere Usare Machine Learning automatizzato per eseguire il training di un modello di previsione delle serie temporali.
Elaborazione del linguaggio naturale: confermare le preferenze per le impostazioni necessarie:
Usare l'opzione Seleziona sottotipo per configurare il tipo di classificazione secondaria per il modello NLP. È possibile scegliere tra classificazione multiclasse, classificazione con più etichette e riconoscimento di entità denominate.
Nella sezione Impostazioni di organizzazione, specificare i valori per il fattore di Slack e l'algoritmo di campionamento.
Nella sezione spazio di ricerca, configurare il set di opzioni dell'Algoritmo del modello.
Per altre informazioni su come configurare queste impostazioni, vedere Configurare Machine Learning automatizzato per eseguire il training di un modello NLP (SDK Python o interfaccia della riga di comando di Azure).
Visione artificiale: scegliere se abilitare lo Sweep manuale e confermare le preferenze per le impostazioni necessarie:
- Usare l'opzione Seleziona sottotipo per configurare il tipo di classificazione secondaria per il modello di visione artificiale. È possibile scegliere tra Classificazione immagini (multiclasse) o (a più etichette), Rilevamento oggetti e Poligono (segmentazione dell'istanza).
Per altre informazioni su come configurare queste impostazioni, vedere Configurare AutoML per eseguire il training di modelli di visione artificiale (SDK Python o interfaccia della riga di comando di Azure).
Specificare le impostazioni facoltative
Machine Learning Studio offre impostazioni facoltative che è possibile configurare in base alla selezione del modello di Machine Learning. Le sezioni seguenti descrivono le impostazioni aggiuntive.
Configurare le impostazioni aggiuntive
È possibile selezionare l'opzione Visualizza impostazioni di configurazione aggiuntive per visualizzare le azioni da eseguire sui dati in preparazione del training.
La pagina Configurazione aggiuntiva mostra i valori predefiniti in base alla selezione e ai dati dell'esperimento. È possibile usare i valori predefiniti o configurare le impostazioni seguenti:
| Impostazione | Descrizione |
|---|---|
| Metrica primaria | Identificare la metrica principale per assegnare un punteggio al modello. Per altre informazioni, vedere le metriche dei modelli. |
| Abilitare la distribuzione con spaziatura dell'insieme | Consentire l'apprendimento dell'insieme e migliorare i risultati di Machine Learning e le prestazioni predittive combinando più modelli rispetto all'uso di modelli singoli. Per altre informazioni, vedere Modelli di insieme. |
| Usa tutti i modelli supportati | Usare questa opzione per indicare a Machine Learning automatizzato se usare tutti i modelli supportati nell'esperimento. Per altre informazioni, vedere gli algoritmi supportati per ogni tipo di attività. - Selezionare questa opzione per configurare l'impostazione Modelli bloccati. - Deselezionare questa opzione per configurare l'impostazione Modelli consentiti. |
| Modelli bloccati | (Disponibile quando l'opzione Usa tutti i modelli supportati è selezionata) Usare l'elenco a discesa e selezionare i modelli da escludere dal processo di training. |
| Modelli consentiti | (Disponibile quando l'opzione Usa tutti i modelli supportati non è selezionata) Usare l'elenco a discesa e selezionare i modelli da usare per il processo di training. Importante: disponibile solo per gli esperimenti SDK. |
| Modello esplicativo migliore | Scegliere questa opzione per visualizzare automaticamente la spiegazione sul modello migliore creato da Machine Learning automatizzato. |
| Etichetta di classe positiva | Immettere l'etichetta per Machine Learning automatizzato da usare per il calcolo delle metriche binarie. |
Configurare le impostazioni di definizione delle funzionalità
È possibile selezionare l'opzione Visualizza impostazioni di definizione delle funzionalità per visualizzare le azioni da eseguire sui dati in preparazione del training.
La pagina Definizione delle funzionalità mostra le tecniche di definizione delle caratteristiche predefinite per le colonne di dati. È possibile abilitare/disabilitare la definizione automatica delle funzionalità e personalizzare le impostazioni di definizione delle funzionalità automatiche per l'esperimento.

Selezionare l'opzione Abilita definizione delle funzionalità per consentire la configurazione.
Importante
Quando i dati contengono colonne non numeriche, la definizione delle funzionalità è sempre abilitata.
Configurare ogni colonna disponibile, come desiderato. La tabella seguente riepiloga le personalizzazioni attualmente disponibili tramite lo studio.
Istogramma Personalizzazione Tipo di funzionalità Modifica il tipo di valore per la colonna selezionata. Attribuisci con Selezionare il valore con cui imputare i valori mancanti nei dati. 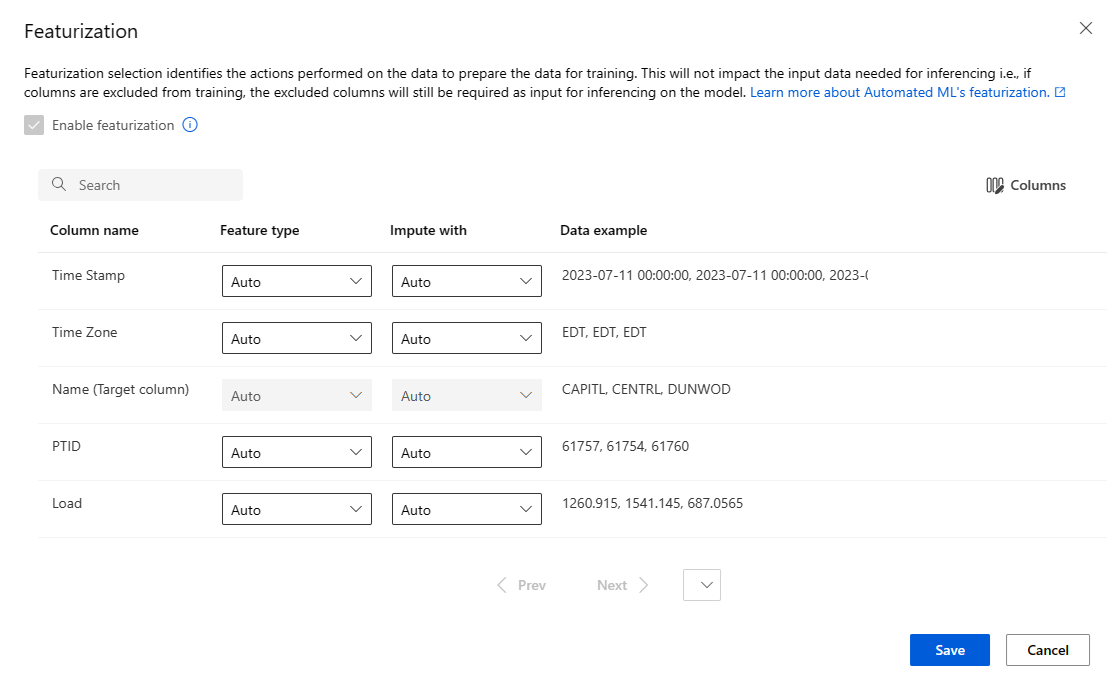

Le impostazioni di definizione delle funzionalità non influiscono sui dati di input necessari per l'inferenza. Se si escludono colonne dal training, le colonne escluse sono comunque necessarie come input per l'inferenza nel modello.
Configurare i limiti per il processo
La sezione Limiti fornisce le opzioni di configurazione per le impostazioni seguenti:
| Impostazione | Descrizione | valore |
|---|---|---|
| Max prova | Specificare il numero massimo di prove da effettuare durante il processo di Machine Learning automatizzato, in cui ogni versione di valutazione ha una combinazione diversa di algoritmi e iperparametri. | Numero intero compreso tra 1 e 1.000 |
| Numero massimo di versioni di valutazione simultanee | Specificare il numero massimo di processi di prova che possono essere eseguiti in parallelo. | Numero intero compreso tra 1 e 1.000 |
| Numero massimo di nodi | Specificare il numero massimo di nodi che questo processo può usare dalla destinazione di calcolo selezionata. | 1 o più, a seconda della configurazione di calcolo |
| Soglia di punteggio metrica | Immettere il valore soglia della metrica di iterazione. Quando l'iterazione raggiunge la soglia, il processo di training termina. Tenere presente che i modelli significativi hanno una correlazione maggiore di zero. In caso contrario, il risultato è uguale a un tentativo. | Soglia media delle metriche, tra limiti [0, 10] |
| Timeout dell'esperimento (minuti) | Specificare il tempo massimo di esecuzione dell'intero esperimento. Dopo che l'esperimento raggiunge il limite, il sistema annulla il processo di Machine Learning automatizzato, incluse tutte le versioni di valutazione (processi figlio). | Numero di minuti |
| Timeout della sessione (minuti) | Specificare il tempo massimo per l'esecuzione di ogni processo di valutazione. Dopo che il processo di prova raggiunge questo limite, il sistema annulla la prova. | Numero di minuti |
| Abilitare la terminazione anticipata | Usare questa opzione per terminare il processo quando il punteggio non migliora a breve termine. | Selezionare l'opzione per abilitare la fine anticipata del processo |
Convalidare e testare
La sezione Convalida e test offre le opzioni di configurazione seguenti:
Specificare il Tipo di convalida da usare per il processo di training. Se non viene specificato in modo esplicito un parametro
validation_dataon_cross_validations, ML automatizzato applica tecniche predefinite in base al numero di righe fornite nel singolo set di datitraining_data.Dimensioni dei dati di training Tecnica di convalida Più di 20.000 righe Viene applicata la suddivisione dei dati di training/convalida. Per impostazione predefinita, come set di convalida viene considerato il 10% del set di dati di training iniziale. A sua volta, il set di convalida viene usato per il calcolo delle metriche. Meno di 20.000 righe Viene applicato l'approccio di convalida incrociata. Il numero predefinito di riduzioni dipende dal numero di righe.
- Set di dati con meno di 1.000 righe: vengono usate 10 riduzioni
- Set di dati con 1.000-20.000 righe: vengono usate tre riduzioniFornire Dati di test (anteprima) per valutare il modello consigliato generato automaticamente da ML automatizzato alla fine dell'esperimento. Quando si forniscono set di dati di test, un processo di test viene attivato automaticamente alla fine dell'esperimento. Questo processo di test è il solo sul modello migliore consigliato dal ML automatizzato. Per altre informazioni, vedere Visualizzare i risultati dei processi di test remoti (anteprima).
Importante
Fornire un set di dati di test per valutare i modelli generati è una funzionalità di anteprima. Questa funzionalità è una funzionalità di anteprima sperimentale e può cambiare in qualsiasi momento.
I dati di test sono considerati separati dal training e dalla convalida, e non devono distorcere i risultati del processo di test del modello consigliato. Per altre informazioni, vedere Training, convalida e test dei dati.
È possibile fornire un set di dati di test personalizzato o scegliere di usare una percentuale del set di dati di training. I dati di test devono essere specificati nel formato Set di dati tabulari di Azure Machine Learning.
Lo schema del set di dati di test deve corrispondere al set di dati di training. La colonna di destinazione è facoltativa, ma se questa non viene indicata non viene calcolata alcuna metrica di test.
Il set di dati di test non deve corrispondere al set di dati di training o al set di dati di convalida.
I processi di previsione non supportano la divisione di training/test.

Configurare l'ambiente di calcolo
Seguire questa procedura e configurare l'ambiente di calcolo:
Selezionare Avanti per passare alla scheda Ambiente di calcolo.
Usare l'elenco a discesa Seleziona tipo di ambiente di calcolo per scegliere un'opzione per il processo di profiling e training dei dati. Le opzioni includono cluster di elaborazione, istanza di ambiente di calcolo o serverless.
Dopo aver selezionato il tipo di calcolo, l'altra interfaccia utente nella pagina cambia in base alla selezione:
Serverless: le impostazioni di configurazione vengono visualizzate nella pagina corrente. Continuare con il passaggio successivo per le descrizioni delle impostazioni da configurare.
Cluster di elaborazione o Istanza di ambiente di calcolo: scegliere tra le opzioni seguenti:
Usare l'elenco a discesa Seleziona ambiente di calcolo di ML automatizzato per selezionare un ambiente di calcolo esistente per l'area di lavoro, quindi selezionare Avanti. Passare alla sezione Esegui esperimento e visualizza i risultati.
Selezionare +Nuovo per creare una nuova istanza di ambiente di calcolo o cluster. Questa opzione apre la pagina Crea ambiente di calcolo. Continuare con il passaggio successivo per le descrizioni delle impostazioni da configurare.
Per un'elaborazione serverless o un nuovo ambiente di calcolo, configurare le impostazioni (*) necessarie:
Le impostazioni di configurazione variano a seconda del tipo di ambiente di calcolo. La tabella seguente riepiloga le varie impostazioni che potrebbe essere necessario configurare:
Campo Descrizione Nome dell'ambiente di calcolo Immettere un nome univoco che identifichi il contesto di calcolo. Location Specificare l'area per il computer. Priorità macchina virtuale Le macchine virtuali con priorità bassa sono più economiche, ma non garantiscono i nodi di calcolo. Tipo di macchina virtuale Selezionare CPU o GPU per il tipo di macchina virtuale. Livello macchina virtuale Selezionare la priorità per l'esperimento. Virtual machine size (Dimensioni della macchina virtuale) Selezionare le dimensioni della macchina virtuale per il contesto di calcolo. Nodi min/max Per profilare i dati, è necessario specificare almeno un nodo. Immettere il numero massimo di nodi per l’ambiente di calcolo. Il valore predefinito è sei nodi per un ambiente di calcolo di Azure Machine Learning. Secondi di inattività prima della riduzione Specificare il tempo di inattività prima che il cluster venga ridotto automaticamente al numero minimo di nodi. Impostazioni avanzate Queste impostazioni consentono di configurare un account utente e una rete virtuale esistente per l'esperimento. Dopo aver configurato le impostazioni necessarie, selezionare Avanti o Crea, in base alle esigenze.
La creazione di un nuovo ambiente di calcolo può richiedere alcuni minuti. Al termine della creazione, selezionare Avanti.
Eseguire l'esperimento e visualizzare i risultati
Selezionare Fine per eseguire l'esperimento. L'esperimento di preparazione del processo può richiedere fino a 10 minuti. Per completare l'esecuzione di ogni pipeline, i processi di training possono richiedere altri 2-3 minuti. Se è stato specificato di generare il dashboard RAI per il modello consigliato, potrebbero essere necessari fino a 40 minuti.
Nota
Gli algoritmi utilizzati da ML automatizzato hanno una casualità intrinseca che può causare lievi variazioni nel punteggio finale delle metriche del modello consigliato, ad esempio l'accuratezza. Machine Learning automatizzato esegue anche operazioni sui dati, ad esempio la divisione dei test di training, la divisione della convalida del training o la convalida incrociata, quando necessario. Se si esegue più volte un esperimento con le stesse impostazioni di configurazione e la stessa metrica primaria, è probabile che si vedano variazioni nel punteggio finale di ogni esperimento a causa di questi fattori.
Visualizzare i dettagli sull'esperimento
Viene visualizzata la schermata Dettagli processo nella scheda Dettagli. Questa schermata mostra un riepilogo del processo dell'esperimento, inclusa una barra di stato in alto accanto al numero di processo.
La scheda Modelli contiene un elenco dei modelli creati, ordinati in base al punteggio della metrica. Per impostazione predefinita, il modello che riceve il punteggio più alto in base alla metrica scelta si trova all'inizio dell'elenco. Man mano che il processo di training prova più modelli, i modelli sottoposti a esercitazione vengono aggiunti all'elenco. Usare questo approccio per ottenere un rapido confronto delle metriche per i modelli prodotti finora.
Visualizza i dettagli del processo di training
Eseguire il drill-down su uno dei modelli completati per visualizzare i dettagli del processo di training. È possibile visualizzare grafici delle metriche delle prestazioni per modelli specifici nella scheda Metriche. Per altre informazioni, vedere Valutare i risultati dell'esperimento di Machine Learning automatizzato. Su questa pagina, è anche possibile trovare informazioni dettagliate su tutte le proprietà del modello insieme a codice, processi figlio e immagini associati.
Visualizzare i risultati del processo di test remoto (anteprima)
Se è stato specificato un set di dati di test o si è scelto di eseguire una suddivisione di training/test durante l'installazione dell'esperimento nel modulo Convalida e test, il ML automatizzato testa automaticamente il modello consigliato per impostazione predefinita. Di conseguenza, ML automatizzato calcola le metriche di test per determinare la qualità del modello consigliato e le relative stime.
Importante
Il test dei modelli con un set di dati di test per valutare i modelli generati è una funzionalità di anteprima. Questa funzionalità è una funzionalità di anteprima sperimentale e può cambiare in qualsiasi momento.
Questa funzionalità non è disponibile per gli scenari di Machine Learning automatizzato seguenti:
Seguire questa procedura per visualizzare le metriche del processo di test del modello consigliato:
In studio, passare alla pagina Modelli e selezionare il modello migliore.
Selezionare la scheda Risultati del test (anteprima).
Selezionare il processo desiderato e visualizzare la scheda Metriche:

Visualizzare le stime di test usate per calcolare le metriche di test seguendo questa procedura:
Nella parte inferiore della pagina, selezionare il collegamento in Set di dati output per aprire il set di dati.
Nella pagina Set di dati selezionare la scheda Esplora per visualizzare le stime del processo di test.
È anche possibile visualizzare e scaricare il file di previsione dalla scheda Output + log. Espandere la cartella Previsioni per individuare il file prediction.csv.
Il processo di test del modello genera il file predictions.csv archiviato nell'archivio dati predefinito creato con l'area di lavoro. Questo archivio dati è visibile a tutti gli utenti con la stessa sottoscrizione. I processi di test non sono consigliati per gli scenari se una delle informazioni usate per o create dal processo di test deve rimanere privata.
Testare un modello di Machine Learning automatizzato esistente (anteprima)
Al termine dell'esperimento, è possibile testare i modelli generati da Machine Learning automatizzato.
Importante
Il test dei modelli con un set di dati di test per valutare i modelli generati è una funzionalità di anteprima. Questa funzionalità è una funzionalità sperimentale di anteprima e può cambiare in qualsiasi momento.
Questa funzionalità non è disponibile per gli scenari di Machine Learning automatizzato seguenti:
Se si vuole testare un modello generato da ML automatizzato diverso e non il modello consigliato, seguire questa procedura:
Selezionare un processo di esperimento di ML automatizzato esistente.
Andare alla scheda Modelli del processo e selezionare il modello completato da testare.
Nella pagina Dettagli del modello, selezionare l'opzione Modello di test (anteprima) per aprire il riquadro Modello di test.
Nel riquadro Modello di test selezionare il cluster di elaborazione e un set di dati di test da usare per il processo di test.
Selezionare l'opzione Test. Lo schema del set di dati di test deve corrispondere al set di dati di training, ma la Colonna di destinazione è facoltativa.
Al termine della creazione del processo di test del modello, nella pagina Dettagli viene visualizzato un messaggio di operazione riuscita. Selezionare la scheda Risultati di test per visualizzare lo stato di avanzamento del processo.
Per visualizzare i risultati del processo di test, aprire la pagina Dettagli e seguire la procedura della sezione Visualizzare i risultati del processo di test remoto (anteprima).

Dashboard di intelligenza artificiale responsabile (anteprima)
Per comprendere meglio il modello, è possibile visualizzare varie informazioni dettagliate sul modello usando il dashboard di intelligenza artificiale responsabile. Questa interfaccia utente consente di valutare ed eseguire il debug del miglior modello di ML automatizzato. Il dashboard di intelligenza artificiale responsabile valuta gli errori del modello e i problemi di equità, diagnostica il motivo per cui si verificano tali errori valutando i dati di training e/o test e osservando le spiegazioni del modello. Queste informazioni dettagliate consentono di creare un trust con il modello e di passare i processi di controllo. I dashboard di intelligenza artificiale responsabile non possono essere generati per un modello di ML automatizzato esistente. Il dashboard viene creato solo per il modello consigliato quando viene creato un nuovo processo di ML automatizzato. Gli utenti devono continuare a usare Spiegazioni del modello (anteprima) fino a quando non viene fornito il supporto per i modelli esistenti.
Generare un dashboard di intelligenza artificiale responsabile per un particolare modello seguendo questa procedura:
Durante l'invio di un processo di Machine Learning automatizzato, passare alla sezione Impostazioni attività sul menu a sinistra e selezionare l’opzioneVisualizza impostazioni di configurazione aggiuntive.
Nella pagina Configurazione aggiuntiva, selezionare l'opzione Spiega modello migliore:

Passare alla scheda Ambiente di calcolo e selezionare l'opzione Serverless per l'elaborazione:

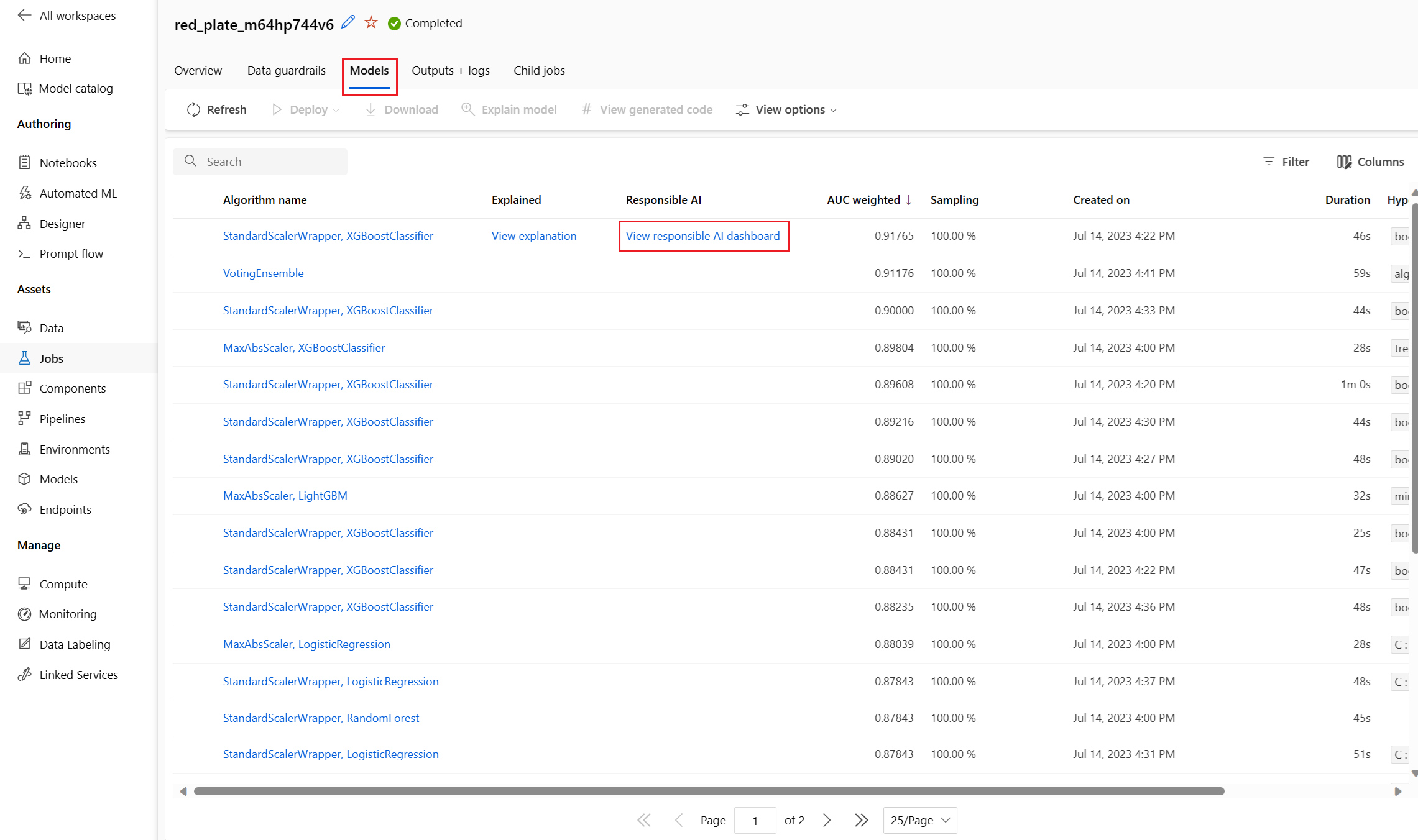
Al termine dell'operazione, passare alla pagina Modelli del processo di ML automatizzato, che contiene un elenco dei modelli sottoposti a training. Selezionare il collegamento Visualizza dashboard di intelligenza artificiale responsabile:
Il dashboard di intelligenza artificiale responsabile viene visualizzato per il modello selezionato:
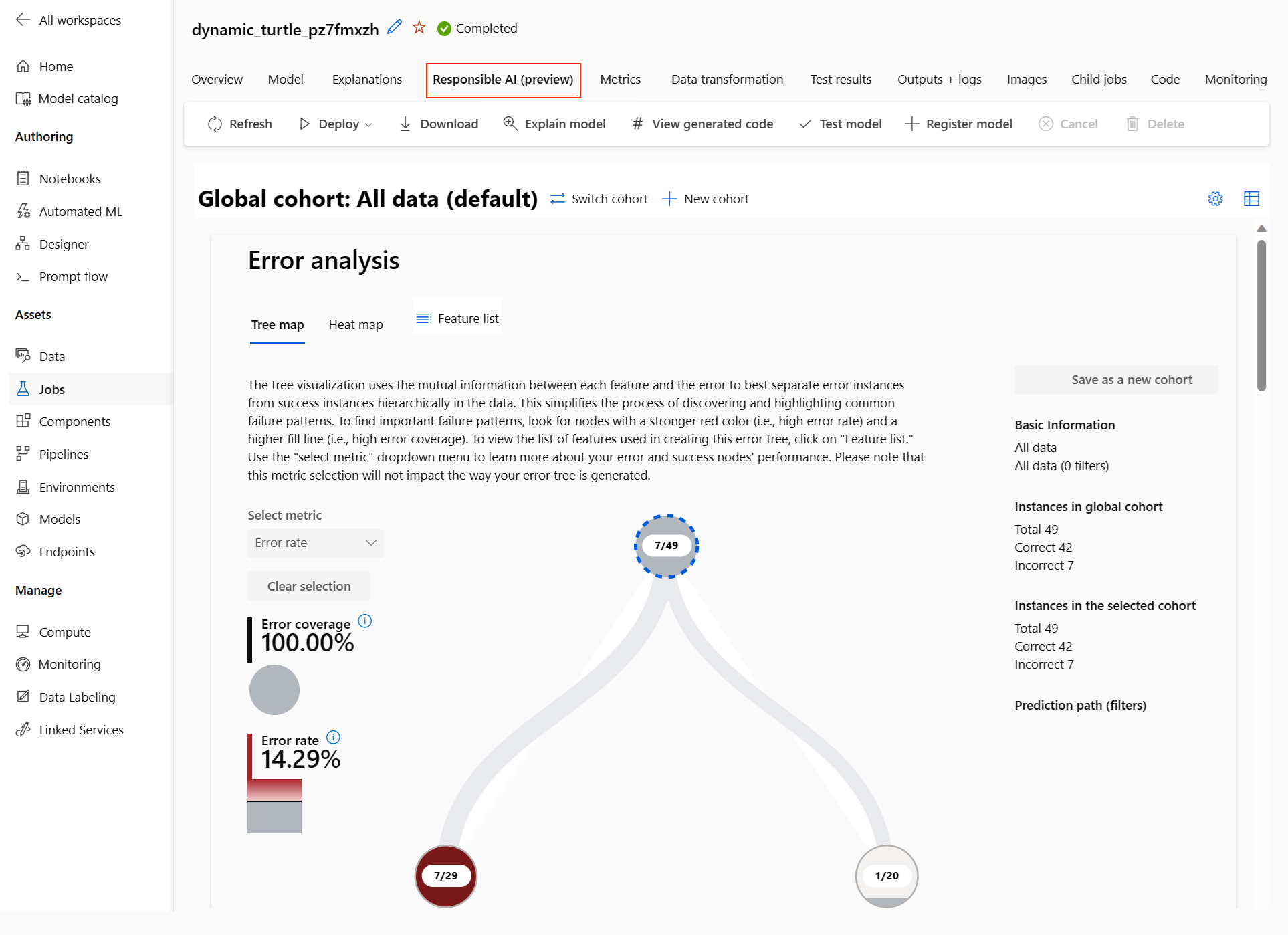
Nel dashboard sono visualizzati quattro componenti attivati per il modello migliore di Machine Learning automatizzato:
Componente Cosa mostra il componente? Come leggere questo grafico? Analisi degli errori Usare l'analisi degli errori quando è necessario:
- Acquisire una conoscenza approfondita circa il modo in cui gli errori del modello vengono distribuiti in un set di dati e in diverse dimensioni di input e funzionalità.
- Suddividere le metriche delle prestazioni aggregate per individuare automaticamente coorti errate per informare i passaggi di mitigazione mirati.Grafici di analisi degli errori Panoramica del modello ed equità Usare questo componente per:
- Acquisire una conoscenza approfondita delle prestazioni del modello tra coorti di dati diversi.
- Comprendere i problemi di equità del modello esaminando le metriche di disparità. Queste metriche possono valutare e confrontare il comportamento del modello tra sottogruppi identificati in termini di funzionalità sensibili (o senza distinzione).Panoramica del modello e grafici di equità Spiegazioni del modello Usare il componente di spiegazione del modello per generare descrizioni comprensibili delle stime di un modello di Machine Learning esaminando:
- Spiegazioni globali: ad esempio, quali funzionalità influiscono sul comportamento complessivo di un modello di allocazione prestiti?
- Spiegazioni locali: ad esempio, perché la richiesta di un prestito di un cliente è stata approvata o rifiutata?Grafici di spiegazione dei modelli Analisi dei dati Usare l'analisi dei dati quando è necessario:
- Esplorare le statistiche del set di dati selezionando filtri diversi per suddividere i dati in dimensioni diverse (note anche come coorti).
- Comprendere la distribuzione del set di dati tra coorti e gruppi di funzionalità diversi.
- Determinare se i risultati correlati all'equità, all'analisi degli errori e alla causalità (derivati da altri componenti del dashboard) sono il risultato della distribuzione del set di dati.
- Decidere in quali aree raccogliere più dati per mitigare gli errori provenienti da problemi di rappresentazione, disturbo delle etichette, disturbo delle funzionalità, distorsione delle etichette e fattori simili.Grafici di Esplora dati Inoltre, è possibile creare coorti (sottogruppi di punti dati che condividono le caratteristiche specificate) per concentrarsi sull'analisi di ogni componente su coorti diverse. Il nome della coorte attualmente applicato al dashboard viene sempre visualizzato in alto a sinistra del dashboard. La vista predefinita nel dashboard è l'intero set di dati, denominato Tutti i dati (per impostazione predefinita). Per altre informazioni, vedere Controlli globali per il dashboard.


Modifica e invia processi (anteprima)
Negli scenari in cui si vuole creare un nuovo esperimento in base alle impostazioni di un esperimento esistente, ML automatizzato offre l'opzione Modifica e invio nell'interfaccia utente di studio. Questa funzionalità è limitata agli esperimenti avviati dall'interfaccia utente di Studio e richiede lo schema dei dati per il nuovo esperimento in modo che corrisponda a quello dell'esperimento originale.
Importante
La possibilità di copiare, modificare e inviare un nuovo esperimento basato su un esperimento esistente è una funzionalità di anteprima. Questa funzionalità è una funzionalità di anteprima sperimentale e può cambiare in qualsiasi momento.
L'opzione Modifica e invio apre la procedura guidata Crea un nuovo processo di Machine Learning automatizzato con i dati, le impostazioni di calcolo e l’esperimento prepopolati. È possibile configurare le opzioni in ogni scheda della procedura guidata e modificare le selezioni in base alle esigenze per il nuovo esperimento.
Distribuire il modello
Una volta ottenuto il modello migliore, è possibile distribuire il modello come servizio Web per eseguire previsioni sui nuovi dati.
Nota
Per distribuire un modello generato tramite il pacchetto automl con Python SDK, è necessario registrare il modello) all'area di lavoro.
Dopo aver registrato il modello, è possibile individuare il modello in studio selezionando Modelli nel menu a sinistra. Nella pagina di panoramica del modello, è possibile selezionare l'opzione Distribuisci e procedere al passaggio 2 in questa sezione.
Machine Learning automatizzato facilita la distribuzione del modello senza scrivere codice.
Avviare la distribuzione usando uno dei metodi seguenti:
Distribuire il modello migliore con i criteri delle metriche definiti:
Al termine dell'esperimento, selezionare Processo 1 e passare alla pagina del processo padre.
Selezionare il modello elencato nella sezione Riepilogo modello migliore, quindi selezionare Distribuisci.
Per distribuire un'iterazione del modello specifica da questo esperimento:
- Selezionare il modello desiderato dalla scheda Modelli, quindi selezionare Distribuisci.
Inserire i dati nel riquadro Distribuisci modello:
Campo Valore Nome Specificare un nome univoco per la distribuzione. Descrizione Immettere una descrizione per identificare meglio le finalità della distribuzione. Tipo di ambiente di calcolo Selezionare il tipo di endpoint da distribuire: Servizio Azure Kubernetes o Istanza di Azure Container. Nome dell'ambiente di calcolo (Si applica solo al servizio Azure Kubernetes) Selezionare il nome del cluster del servizio Azure Kubernetes in cui si vuole eseguire la distribuzione. Abilita autenticazione Selezionare questa impostazione per consentire l'autenticazione basata su token o basata su chiave. Usa asset di distribuzione personalizzati Abilitare gli asset personalizzati se si desidera caricare lo script di punteggio e il file di ambiente. In caso contrario, ML automatizzato fornisce automaticamente questi asset per impostazione predefinita. Per altre informazioni, vedere Distribuire e assegnare punteggi a un modello di Machine Learning usando un endpoint online. Importante
I nomi dei file devono essere composti da un numero di caratteri compreso tra 1 e 32. Il nome deve iniziare e terminare con caratteri alfanumerici e può includere una combinazione di trattini, caratteri di sottolineatura, punti e caratteri alfanumerici. Non sono consentiti spazi.
Il menu Avanzata offre funzionalità di distribuzione predefinite, quali la raccolta dati e le impostazioni di utilizzo delle risorse. È possibile usare le opzioni in questo menu per sostituire queste impostazioni predefinite. Per altre informazioni, vedere Monitorare gli endpoint online.
Seleziona Distribuisci. Il completamento della distribuzione può richiedere circa 20 minuti.
Dopo l'avvio della distribuzione, viene visualizzata la scheda Riepilogo modello. È possibile monitorare lo stato di avanzamento della distribuzione nella sezione Stato distribuzione.
A questo punto, è disponibile un servizio Web operativo per generare previsioni. È possibile testare le stime eseguendo query sul servizio dagli Esempi di intelligenza artificiale end-to-end in Microsoft Fabric.