Eseguire modelli di Azure Machine Learning dal Fabric usando endpoint batch (anteprima)
SI APPLICA A: Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Questo articolo spiega come usare le distribuzioni batch di Azure Machine Learning da Microsoft Fabric. Il flusso di lavoro, anche se usa modelli distribuiti negli endpoint batch, supporta anche l'uso di distribuzioni di pipeline batch da Fabric.
Importante
Questa funzionalità è attualmente in anteprima pubblica. Questa versione di anteprima viene fornita senza contratto di servizio, pertanto se ne sconsiglia l’uso per i carichi di lavoro in ambienti di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate.
Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Prerequisiti
- Ottenere una sottoscrizione di Microsoft Fabric. In alternativa, iscriversi per ottenere una versione di valutazione gratuita di Microsoft Fabric.
- Accedere a Microsoft Fabric.
- Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare. Provare la versione gratuita o a pagamento di Azure Machine Learning.
- Un'area di lavoro di Azure Machine Learning. Se non si disponesse di una, seguire la procedura descritta in Come gestire le aree di lavoro per crearne una.
- Assicurarsi di avere le autorizzazioni seguenti nell'area di lavoro:
- Creare o gestire endpoint e distribuzioni batch: usare i ruoli Proprietario, Collaboratore o un ruolo personalizzato che consenta di
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*. - Creare distribuzioni ARM nel gruppo di risorse dell'area di lavoro: usare i ruoli Proprietario, Collaboratore o un ruolo personalizzato che consentono di
Microsoft.Resources/deployments/writenel gruppo di risorse in cui viene distribuita l'area di lavoro.
- Creare o gestire endpoint e distribuzioni batch: usare i ruoli Proprietario, Collaboratore o un ruolo personalizzato che consenta di
- Assicurarsi di avere le autorizzazioni seguenti nell'area di lavoro:
- Modello distribuito in un endpoint batch. Se non è disponibile, attenersi alla procedura descritta in Distribuire i modelli per l'assegnazione dei punteggi negli endpoint batch per crearne uno.
- Scaricare il set di dati campione heart-unlabeled.csv da usare per l'assegnazione dei punteggi.
Architettura
Azure Machine Learning non può accedere direttamente ai dati archiviati in OneLake di Fabric. È tuttavia possibile usare la funzionalità di OneLake per creare collegamenti all'interno di una Lakehouse per leggere e scrivere dati archiviati in Azure Data Lake Gen2. Poiché Azure Machine Learning supporta l'archiviazione di Azure Data Lake Gen2, questa configurazione consente di usare insieme Fabric e Azure Machine Learning. L'architettura dei dati è la seguente:

Configurare l'accesso ai dati
Per consentire a Fabric e ad Azure Machine Learning di leggere e scrivere gli stessi dati senza doverli copiare, è possibile sfruttare i collegamenti a OneLake e gli archivi dati di Azure Machine Learning. Facendo reindirizzare un collegamento OneLake e un archivio dati allo stesso account di archiviazione, è possibile assicurarsi che sia Fabric sia Azure Machine Learning leggano e scrivano negli stessi dati sottostanti.
In questa sezione viene creato o identificato un account di archiviazione da usare per archiviare le informazioni che verranno usate dall'endpoint batch e che gli utenti di Fabric vedranno in OneLake. L'infrastruttura supporta solo gli account di archiviazione con nomi gerarchici abilitati, ad esempio Azure Data Lake Gen2.
Creare un collegamento OneLake all'account di archiviazione
Aprire l'esperienza Ingegneria dei dati di Synapse in Fabric.
Nel pannello a sinistra selezionare l'area di lavoro Fabric per aprirla.
Aprire il lakehouse che verrà usato per configurare la connessione. Se non si ha già un lakehouse, passare all'esperienza Ingegneria dei dati per creare un lakehouse. In questo esempio si usa un lakehouse denominato trusted.
Nella barra di spostamento a sinistra aprire altre opzioni per Filee quindi selezionare Nuovo collegamento per visualizzare la procedura guidata.
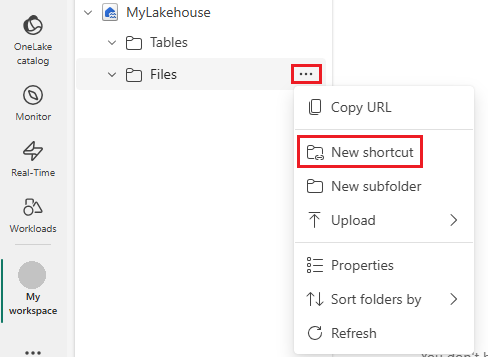
Selezionare l'opzione Azure Data Lake Storage Gen2.

Nella sezione Impostazioni di connessione incollare l'URL associato all'account di archiviazione di Azure Data Lake Gen2.
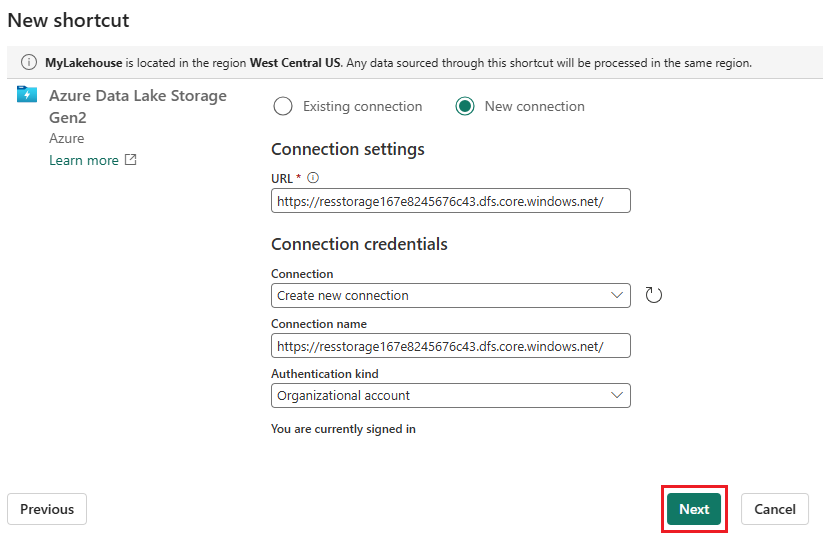
Nella sezione Credenziali di connessione:
- In Connessioneselezionare Crea nuova connessione.
- Per Nome connessionemantenere il valore popolato predefinito.
- Per Tipo di autenticazione selezionare Account dell'organizzazione per usare le credenziali dell'utente connesso tramite OAuth 2.0.
- Selezionare Accedi per accedere.
Selezionare Avanti.
Configurare il percorso del collegamento, in relazione all'account di archiviazione, se necessario. Usare questa impostazione per configurare la cartella a cui punterà il collegamento.
Configurare il Nome del collegamento. Questo nome sarà un percorso all'interno del lakehouse. In questo esempio assegnare un nome ai set di dati del collegamento.
Salvare le modifiche.



Creare un archivio dati che reindirizzi all'account di archiviazione
Aprire lo studio di Azure Machine Learning.
Esplorare l'area di lavoro di Azure Machine Learning.
Passare alla sezione Dati.
Selezionare la scheda Archivi dati.
Seleziona Crea.
Configurare l'archivio dati come indicato di seguito:
Per Nome archivio dati immettere trusted_blob.
Per Tipo di archivio dati selezionare Archiviazione BLOB di Azure.
Suggerimento
Perché configurare Archiviazione BLOB di Azure anziché Azure Data Lake Gen2? Gli endpoint batch possono scrivere stime solo in account di archiviazione BLOB. Tuttavia, ogni account di archiviazione di Azure Data Lake Gen2 è anche un account di archiviazione BLOB; pertanto, possono essere usati in modo intercambiabile.
Selezionare l'account di archiviazione dalla procedura guidata usando l'ID sottoscrizione, l'account di archiviazione e il contenitore BLOB (file system).

Seleziona Crea.
Verificare che il calcolo in cui è in esecuzione l'endpoint batch disponga dell'autorizzazione per montare i dati in questo account di archiviazione. Anche se l'accesso viene ancora concesso dall'identità che richiama l'endpoint, il calcolo in cui viene eseguito l'endpoint batch deve disporre dell'autorizzazione per montare l'account di archiviazione fornito. Per altre informazioni, vedere Accesso ai servizi di archiviazione.
Caricare dati campione
Caricare alcuni dati campione per l'endpoint da usare come input:
Passare all'area di lavoro Fabric.
Selezionare il lakehouse in cui è stato creato il collegamento.
Passare al collegamento ai set di dati.
Creare una cartella per archiviare il set di dati campione a cui si intende assegnare un punteggio. Denominare la cartella uci-heart-unlabeled.
Usare l'opzione Recupera dati e selezionare Carica file per caricare il set di dati campioneheart-unlabeled.csv.
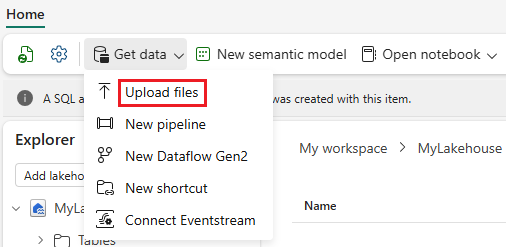
Caricare il set di dati campione.

Il file campione è pronto per l'utilizzo. Prendere nota del percorso in cui è stato salvato.


Creare un'infrastruttura per l'inferenza batch della pipeline
In questa sezione viene creata una pipeline di inferenza dall'infrastruttura a batch nell'area di lavoro di Fabric esistente e si richiamano gli endpoint batch.
Tornare all'esperienza di Ingegneria dei dati se si è già passati da questa usando l'icona del selettore esperienza nell'angolo inferiore sinistro della home page.
Aprire l'area di lavoro di Fabric.
Nella sezione Nuovo della home page selezionare Pipeline di dati.
Assegnare alla pipeline il nome e selezionare Crea.
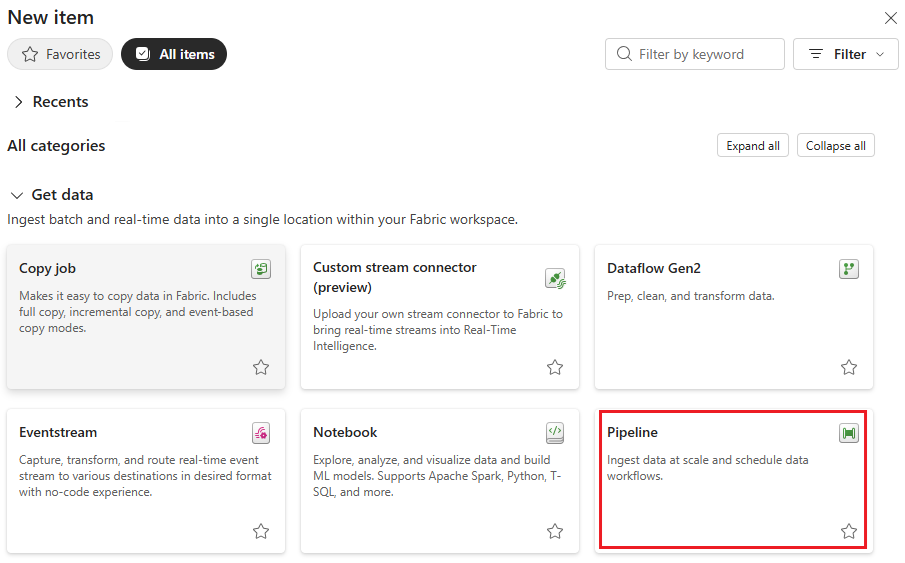
Selezionare la scheda Attività dalla barra degli strumenti nel pannello Canvas della finestra di progettazione.
Selezionare altre opzioni alla fine della scheda e selezionare Azure Machine Learning.
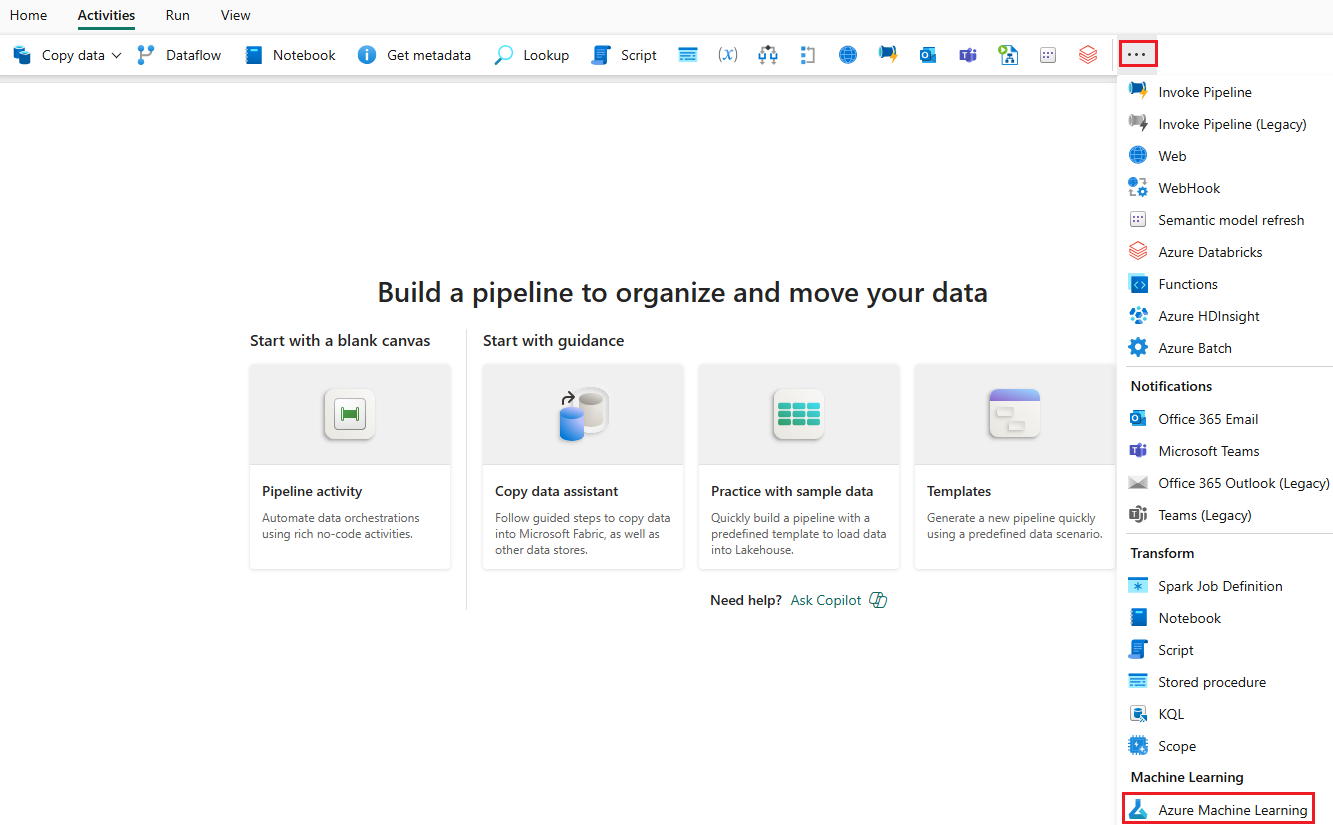
Passare alla scheda Impostazioni e configurare l'attività nel modo seguente:
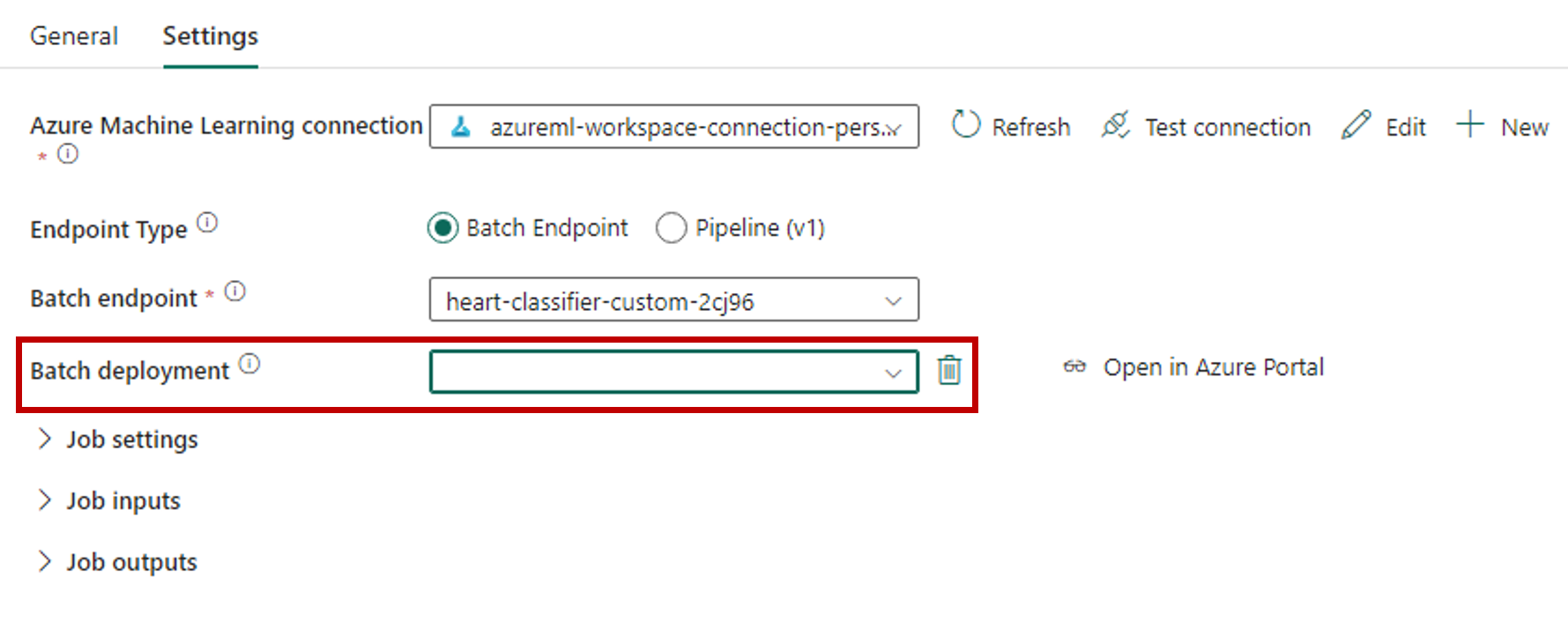
Selezionare Nuovo accanto a Connessione di Azure Machine Learning per creare una nuova connessione all'area di lavoro di Azure Machine Learning che contiene la distribuzione.
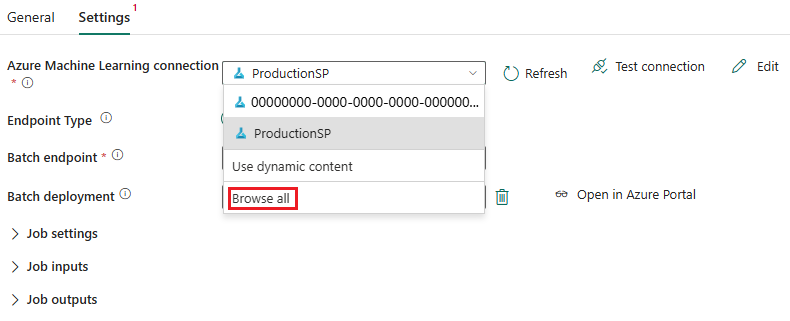
Nella sezione Impostazioni di connessione della creazione della procedura guidata specificare i valori dell'ID sottoscrizione, del nome del Gruppo di risorse e del nome dell'Area di lavoro in cui viene distribuito l'endpoint.
Nella sezione Credenziali di connessione selezionare Account dell'organizzazione come valore del Tipo di autenticazione della propria connessione. L'account dell'organizzazione usa le credenziali dell'utente connesso. In alternativa, è possibile usare l'Entità servizio. Nelle impostazioni di produzione è consigliabile usare un'Entità servizio. Indipendentemente dal tipo di autenticazione, assicurarsi che l'identità associata alla connessione disponga dei diritti per chiamare l'endpoint batch che è stato distribuito.
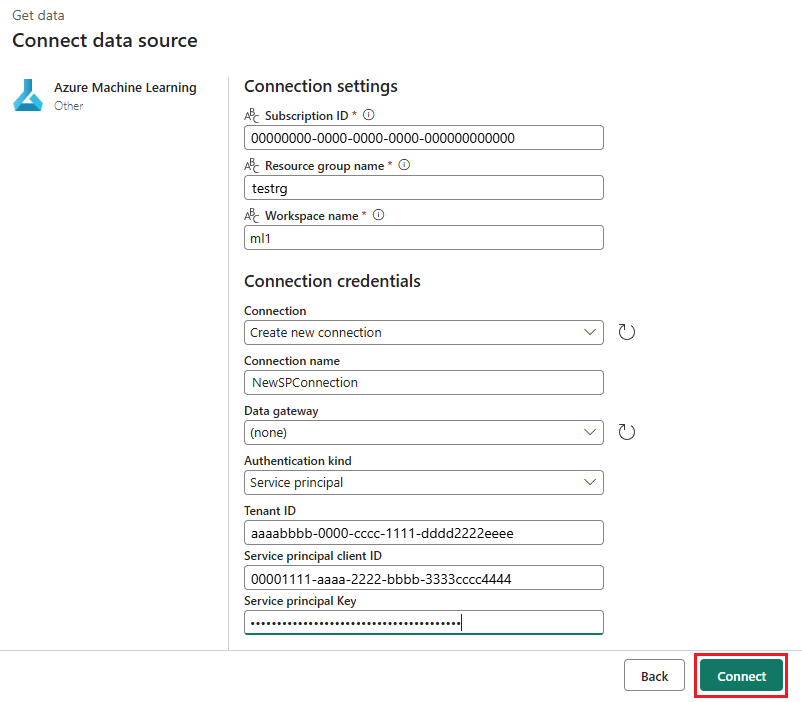
Salvare la connessione. Dopo aver selezionato la connessione, Fabric popola automaticamente gli endpoint batch disponibili nell'area di lavoro selezionata.
Per Endpoint batch selezionare l'endpoint batch che si vuole chiamare. In questo esempio selezionare heart-classifier-....
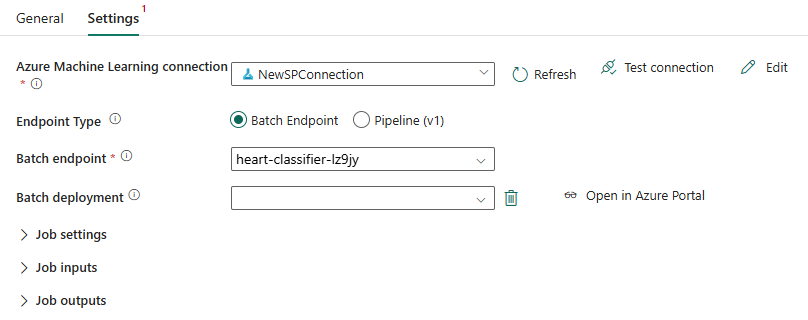
La sezione Distribuzione batch popola automaticamente con le distribuzioni disponibili nell'endpoint.
Per Distribuzione batch, selezionare una distribuzione specifica dall'elenco, se necessario. Se non si seleziona una distribuzione, Fabric richiama la distribuzionePredefinita nell'endpoint, consentendo all'autore dell'endpoint batch di decidere quale distribuzione viene chiamata. Nella maggior parte degli scenari è consigliabile mantenere questo comportamento predefinito.







Configurare input e output per l'endpoint batch
In questa sezione vengono configurati input e output dall'endpoint batch. Gli input degli endpoint batch forniscono dati e parametri necessari per eseguire il processo. La pipeline batch di Azure Machine Learning in Fabric supporta sia distribuzioni modelli sia distribuzioni di pipeline. Il numero e il tipo di input forniti dipendono dal tipo di distribuzione. In questo esempio si usa una distribuzione modello che richiede esattamente un input e produce un output.
Per altre informazioni sugli input e sugli output degli endpoint batch, vedere Informazioni sugli input e gli output in Endpoint batch.
Configurare la sezione input
Configurare la sezione Input processo come indicato di seguito:
Espandere la sezione Input processo.
Selezionare Nuovo per aggiungere un nuovo input all'endpoint.
Assegnare all'input il nome
input_data. Poiché si usa una distribuzione modello, è possibile usare qualsiasi nome. Per le distribuzioni di pipeline, tuttavia, è necessario indicare il nome esatto dell'input previsto dal modello.Selezionare il menu a discesa accanto all'input appena aggiunto per aprire la proprietà dell'input (campo nome e valore).
Immettere
JobInputTypenel campoNome per indicare il tipo di input che si sta creando.Immettere
UriFoldernel campoValore per indicare che l'input è un percorso di cartella. Altri valori supportati per questo campo sono UriFile (un percorso di file) o Literal (qualsiasi valore letterale come stringa o Integer). È necessario usare il tipo corretto previsto dalla propria distribuzione.Selezionare il segno più accanto alla proprietà per aggiungere un'altra proprietà per questo input.
Immettere
Urinel campo Nome per indicare il percorso dei dati.Immettere
azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled, il percorso per individuare i dati nel campo Valore. In questo caso si usa un percorso che porta all'account di archiviazione collegato a OneLake in Fabric e ad Azure Machine Learning. azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled è il percorso dei file CSV con i dati di input previsti per il modello distribuito nell'endpoint batch. È anche possibile usare un percorso diretto per l'account di archiviazione, ad esempiohttps://<storage-account>.dfs.azure.com.
Suggerimento
Se l'input è di tipo Literal, sostituire la proprietà
Uricon 'Value'.
Se l'endpoint richiede più input, ripetere i passaggi precedenti per ognuno di essi. In questo esempio le distribuzioni modelli richiedono esattamente un input.
Configurare la sezione output
Configurare la sezione Output del processo come indicato di seguito:
Espandere la sezione Output del processo.
Selezionare Nuovo per aggiungere un nuovo output all'endpoint.
Assegnare il nome
output_dataall'output. Poiché si usa una distribuzione modello, è possibile usare qualsiasi nome. Per le distribuzioni di pipeline, tuttavia, è necessario indicare il nome esatto dell'output generato dal modello.Selezionare il menu a discesa accanto all'output appena aggiunto per aprire la proprietà dell'output (campo nome e valore).
Immettere
JobOutputTypenel campo Nome per indicare il tipo di output che si sta creando.Immettere
UriFilenel campo Valore per indicare che l'output è un percorso di file. L'altro valore supportato per questo campo è UriFolder (un percorso cartella). A differenza della sezione di input del processo, il Valore letterale (qualsiasi valore letterale come stringa o Integer) non è supportato come output.Selezionare il segno più accanto alla proprietà per aggiungere un'altra proprietà per questo output.
Immettere
Urinel campo Nome per indicare il percorso dei dati.Immettere
@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv'), il percorso in cui inserire l'output nel campo Valore. Gli endpoint batch di Azure Machine Learning supportano solo l'uso dei percorsi dell'archivio dati come output. Poiché gli output devono essere univoci per evitare conflitti, è stata usata un'espressione dinamica,@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv'), per costruire il percorso.
Se l'endpoint restituisce più output, ripetere i passaggi precedenti per ognuno di essi. In questo esempio le distribuzioni modelli producono esattamente un output.
(Facoltativo) Configurare le impostazioni del processo
È anche possibile configurare le Impostazioni del processo aggiungendo le proprietà seguenti:
Per distribuzioni modelli:
| Impostazione | Descrizione |
|---|---|
MiniBatchSize |
Le dimensioni del batch. |
ComputeInstanceCount |
Numero di istanze di ambiente calcolo da richiedere dalla distribuzione. |
Per le distribuzioni della pipeline:
| Impostazione | Descrizione |
|---|---|
ContinueOnStepFailure |
Indica se la pipeline deve interrompere l'elaborazione dei nodi dopo un errore. |
DefaultDatastore |
Indica l'archivio dati predefinito da usare per gli output. |
ForceRun |
Indica se la pipeline deve forzare l'esecuzione di tutti i componenti anche se l'output può essere inferito da un'esecuzione precedente. |
Dopo la configurazione è possibile testare la pipeline.