Usare notebook di Jupyter in Azure Data Studio
Importante
Azure Data Studio sarà ritirato il 28 febbraio 2026. È consigliabile usare Visual Studio Code. Per altre informazioni sulla migrazione a Visual Studio Code, vedere Che cosa accade in Azure Data Studio?
Si applica a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Jupyter Notebook è un'applicazione Web open source che consente di creare e condividere documenti contenenti codice attivo, equazioni, visualizzazioni e testo narrativo. L'uso include la pulizia e la trasformazione dei dati, simulazioni numeriche, modellazioni statistiche, visualizzazioni di dati e apprendimento automatico.
Questo articolo descrive come creare un nuovo notebook nella versione più recente di Azure Data Studio e come iniziare a creare notebook personalizzati usando kernel diversi.
Guardare questo breve video di 5 minuti per un'introduzione ai notebook in Azure Data Studio:
Creare un notebook
Ci sono diversi modi per creare un nuovo notebook. In ogni caso, verrà aperto un nuovo file denominato Notebook-1.ipynb.
Passare al menu File in Azure Data Studio e selezionare Nuovo notebook.
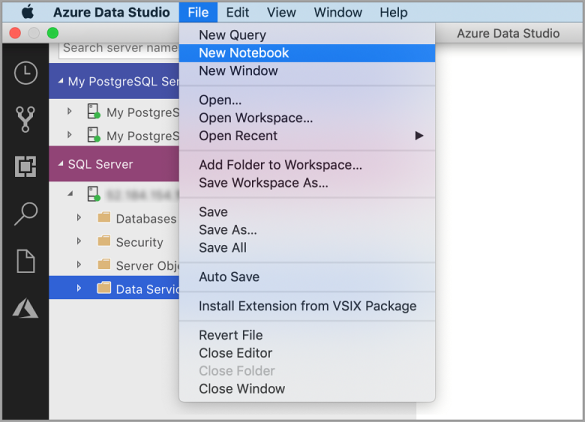
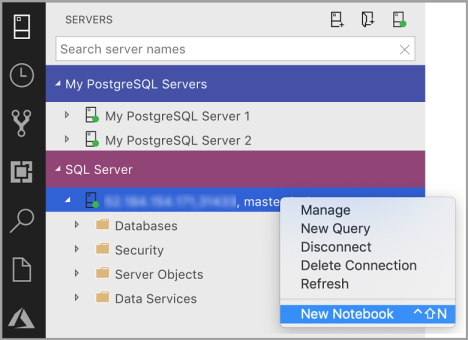
Fare clic con il pulsante destro del mouse su una connessione a SQL Server e scegliere Nuovo notebook.
Aprire il riquadro comandi (CTRL+MAIUSC+P), digitare "nuovo notebook" e selezionare il comando Nuovo notebook.

Connettersi a un kernel
I notebook di Azure Data Studio supportano numerosi kernel diversi, tra cui SQL Server, Python, PySpark e altri. Ogni kernel supporta un linguaggio diverso nelle celle del codice del notebook. Ad esempio, quando si è connessi al kernel SQL Server, è possibile immettere ed eseguire istruzioni T-SQL in una cella di codice del notebook.
Collega a fornisce il contesto per il kernel. Se ad esempio si usa il kernel SQL, è possibile collegarsi a qualsiasi istanza di SQL Server. Se si usa il kernel Python3, ci si collega a localhost ed è possibile usare questo kernel per lo sviluppo Python locale.
Il kernel SQL può essere usato anche per la connessione alle istanze del server PostgreSQL. Se si è uno sviluppatore PostgreSQL e si vogliono connettere i notebook al server PostgreSQL, scaricare l'estensione PostgreSQL nel marketplace delle estensioni di Azure Data Studio e connettersi al server PostgreSQL.
Se si è connessi al cluster Big Data di SQL Server 2019, il valore predefinito di Collega a è l'endpoint del cluster. È possibile inviare il codice Python, Scala e R usando il calcolo Spark del cluster.
| Kernel | Descrizione |
|---|---|
| Kernel SQL | Scrivere codice SQL destinato al database relazionale. |
| Kernel PySpark3 e PySpark | Scrivere codice Python usando il contesto di calcolo Spark del cluster. |
| Kernel Spark | Scrivere codice Scala e R usando il contesto di calcolo Spark del cluster. |
| Kernel Python | Scrivere codice Python per lo sviluppo locale. |
Per altre informazioni su kernel specifici, vedere:
- Creare ed eseguire un notebook di SQL Server
- Creare ed eseguire un notebook Python
- Estensione Kqlmagic in Azure Data Studio: estende le funzionalità del kernel Python
Aggiungere una cella di codice
Le celle di codice consentono di eseguire il codice in modo interattivo all'interno del notebook.
Aggiungere una nuova cella di codice facendo clic sul comando +Cella sulla barra degli strumenti e selezionando Code cell (Cella di codice). Viene aggiunta una nuova cella di codice dopo la cella attualmente selezionata.
Immettere il codice nella cella per il kernel selezionato. Se ad esempio si usa il kernel SQL, è possibile immettere comandi T-SQL nella cella di codice.
L'immissione di codice con il kernel SQL è simile a quella in un editor di query SQL. La cella di codice supporta un'esperienza di codifica SQL moderna con funzionalità predefinite quali un editor SQL avanzato, IntelliSense e frammenti di codice predefiniti. I frammenti di codice consentono di generare la sintassi SQL appropriata per creare database, tabelle, viste, stored procedure e così via, nonché aggiornare gli oggetti di database esistenti. Usare i frammenti di codice per creare rapidamente copie del database a scopo di sviluppo o test e per generare ed eseguire script.
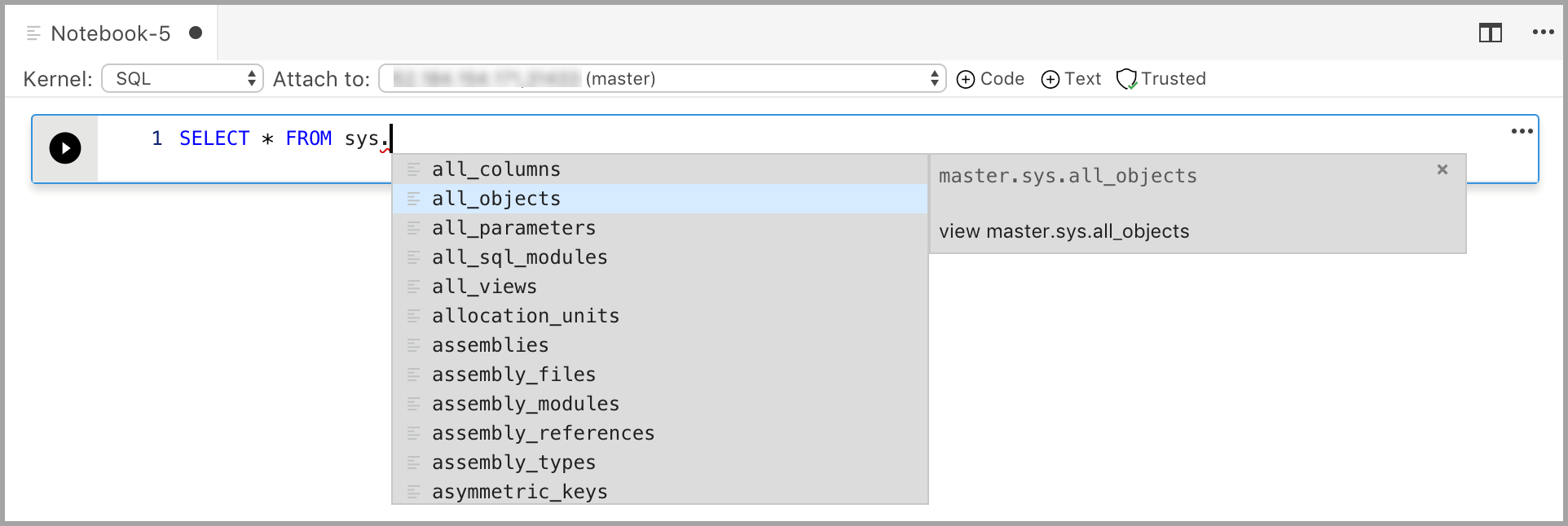
Aggiungere una cella di testo
Le celle di testo consentono di documentare il codice aggiungendo blocchi di testo Markdown tra le celle di codice.
Aggiungere una nuova cella di testo facendo clic sul comando +Cella sulla barra degli strumenti e selezionando Cella di testo.
La cella viene avviata in modalità di modifica in cui è possibile digitare il testo Markdown. Durante la digitazione, viene visualizzata un'anteprima al di sotto.
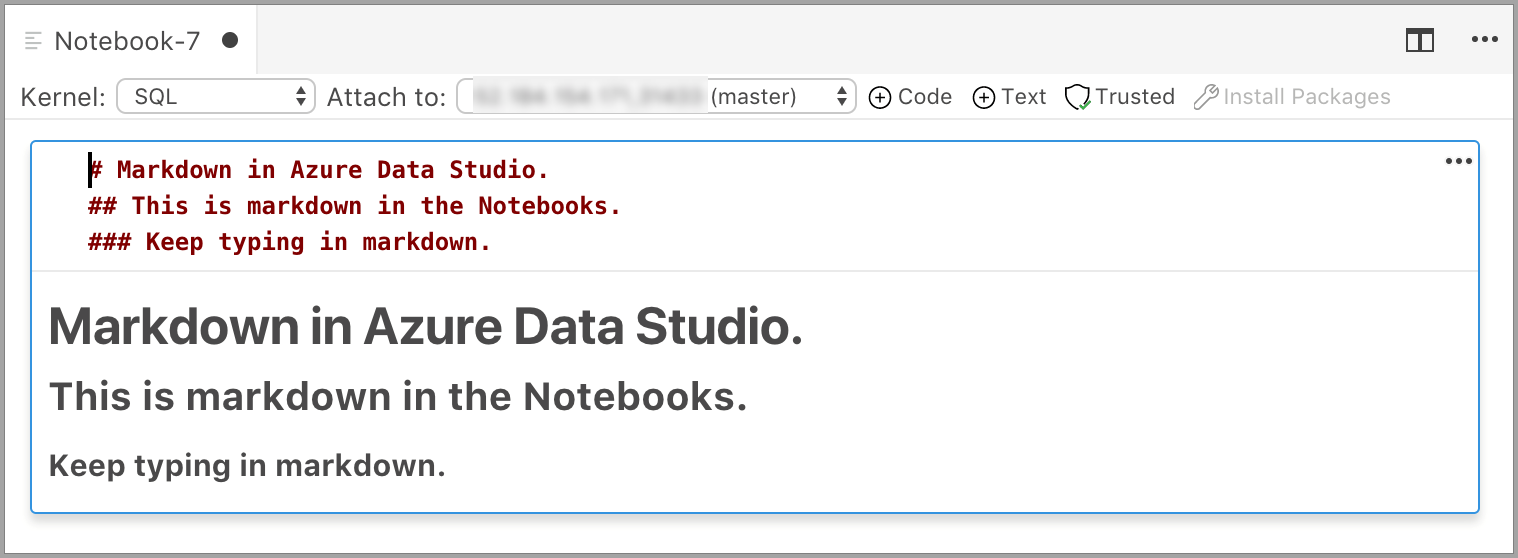
Se si fa clic all'esterno della cella di testo, viene visualizzato il testo Markdown.
Se si fa nuovamente clic nella cella di testo, si passa alla modalità di modifica.
Eseguire una cella
Per eseguire una singola cella, fare clic su Esegui cella (la freccia rotonda nera) a sinistra della cella oppure selezionare la cella e premere F5. È possibile eseguire tutte le celle nel notebook facendo clic su Esegui tutti sulla barra degli strumenti. Le celle vengono eseguite una alla volta e l'esecuzione viene arrestata se viene rilevato un errore in una cella.
I risultati della cella vengono visualizzati sotto la cella. È possibile cancellare i risultati di tutte le celle eseguite nel notebook selezionando il pulsante Cancella risultati sulla barra degli strumenti.
Salvare un notebook
Per salvare un notebook, eseguire una delle operazioni seguenti.
- Digitare CTRL+S
- Scegliere Salva dal menu File
- Scegliere Salva con nome dal menu File
- Scegliere Salva tutto dal menu File per salvare tutti i notebook aperti
- Nel riquadro comandi immettere File: Salva
I notebook vengono salvati come file con estensione .ipynb.
Notebook attendibili e non attendibili
I notebook aperti in Azure Data Studio sono attendibili per impostazione predefinita.
Se si apre un notebook da un'altra origine, viene aperto in modalità non attendibile e sarà quindi possibile impostarlo come attendibile.
Esempi
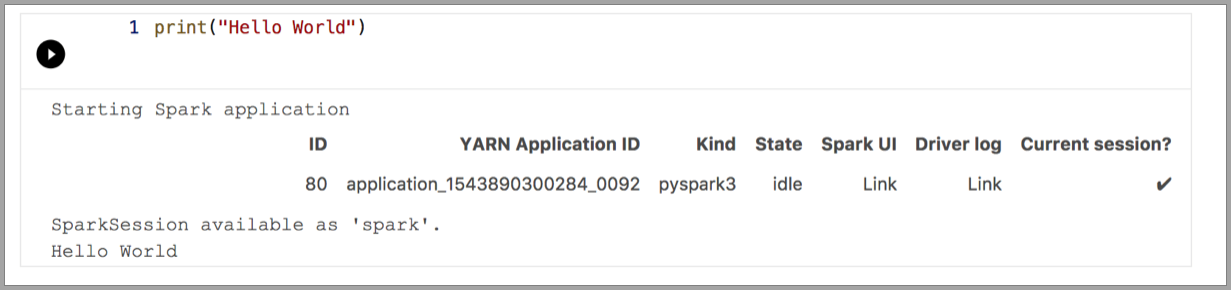
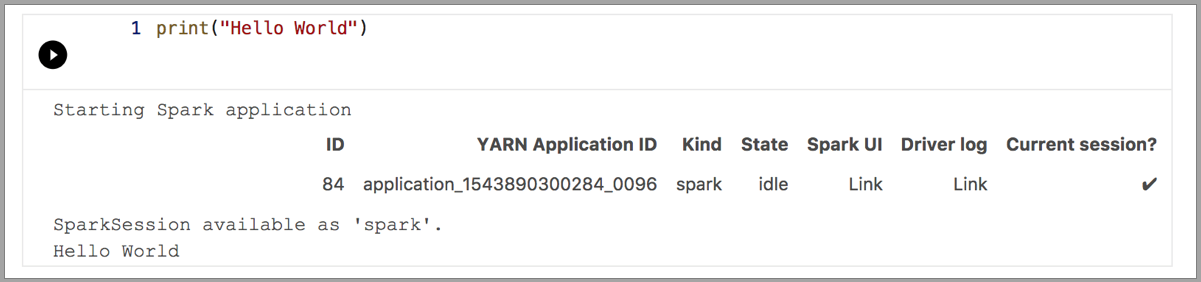
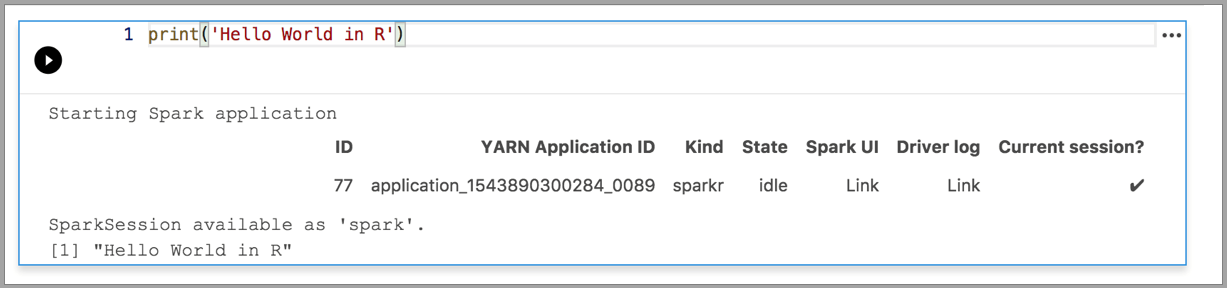
Gli esempi seguenti illustrano l'uso di kernel diversi per eseguire un semplice comando "Hello World". Selezionare il kernel, immettere il codice di esempio in una cella e fare clic su Esegui cella.
Pyspark
Spark | Linguaggio Scala
Spark | Linguaggio R
Python 3

Passaggi successivi
- Creare ed eseguire un notebook di SQL Server.
- Creare ed eseguire un notebook Python
- Eseguire script Python e R in notebook di Azure Data Studio con SQL Server Machine Learning Services.
- Distribuire un cluster Big Data di SQL Server con un notebook di Azure Data Studio.
- Gestire cluster Big Data di SQL Server con notebook di Azure Data Studio.
- Eseguire un notebook di esempio con Spark.