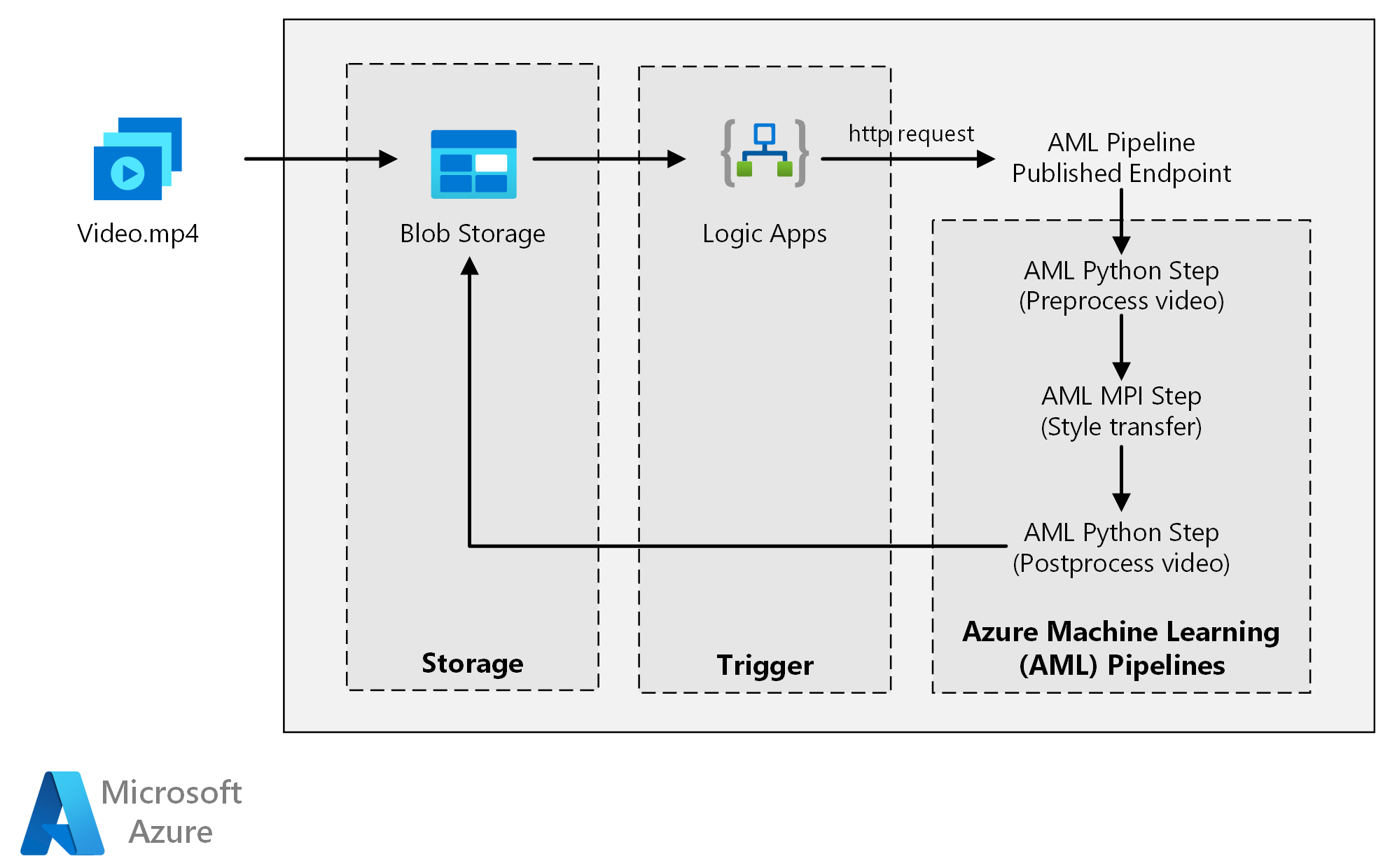
Questa architettura di riferimento illustra come applicare il trasferimento in stile neurale a un video usando Azure Machine Learning. Lo style transfer è una tecnica di apprendimento avanzato che ridefinisce un'immagine esistente usando lo stile di un'altra immagine. È possibile generalizzare questa architettura per qualsiasi scenario che usa l'assegnazione dei punteggi batch con Deep Learning.
Architettura
Scaricare un file di Visio di questa architettura.
Workflow
L'architettura è costituita dai componenti seguenti.
Calcolo
Azure Machine Learning usa le pipeline per creare sequenze di calcolo riproducibili e facili da gestire. Offre anche una destinazione di calcolo gestita (in cui è possibile eseguire il calcolo della pipeline), l'ambiente di calcolo di Machine Learning di Azure per il training, la distribuzione e l'assegnazione di punteggi ai modelli di Machine Learning.
Storage
Archiviazione BLOB di Azure archivia tutte le immagini (immagini di input, immagini di stile e immagini di output). Azure Machine Learning si integra con Archiviazione BLOB in modo che gli utenti non devono spostare manualmente i dati tra piattaforme di calcolo e archivi BLOB. L'archiviazione BLOB è anche conveniente per le prestazioni richieste da questo carico di lavoro.
Trigger
App per la logica di Azure attiva il flusso di lavoro. Quando l'app per la logica rileva che un BLOB è stato aggiunto al contenitore, attiva la pipeline di Azure Machine Learning. App per la logica è ideale per questa architettura di riferimento perché è un modo semplice per rilevare le modifiche all'archiviazione BLOB, con un semplice processo per modificare il trigger.
Pre-elaborazione e post-elaborazione dei dati
Questa architettura di riferimento usa un filmato di repertorio di un orangutan in una struttura ad albero.
- Usare FFmpeg per estrarre il file audio dal filmato video, in modo da riunirlo al video di output in un secondo momento.
- Usare FFmpeg per suddividere il video in singoli frame. I fotogrammi vengono elaborati in modo indipendente, in parallelo.
- A questo punto, è possibile applicare il trasferimento dello stile neurale a ogni singolo frame in parallelo.
- Dopo l'elaborazione di ogni fotogramma, usare FFmpeg per restituire i fotogrammi insieme.
- Infine, ricollega il file audio al filmato restitched.
Componenti
Dettagli della soluzione
Questa architettura di riferimento è progettata per i carichi di lavoro attivati dalla presenza di nuovi supporti in Archiviazione di Azure.
L'elaborazione prevede i passaggi seguenti:
- Caricare un file video in Archiviazione BLOB di Azure.
- Il file video attiva App per la logica di Azure per inviare una richiesta all'endpoint pubblicato della pipeline di Azure Machine Learning.
- La pipeline elabora il video, applica lo style transfer con MPI e poi lo post-elabora.
- L'output viene salvato nuovamente nell'archiviazione BLOB al termine della pipeline.
Potenziali casi d'uso
Un'organizzazione di supporti dispone di un video di cui desidera modificare l'aspetto, rendendolo simile a un dipinto specifico. L'organizzazione vuole applicare questo stile a tutti i fotogrammi del video in modo tempestivo e automatizzato. Per altre informazioni sugli algoritmi di neural style transfer, vedere il PDF Image Style Transfer Using Convolutional Neural Networks (Style transfer di immagini tramite reti neurali convoluzionali).
Considerazioni
Queste considerazioni implementano i pilastri di Azure Well-Architected Framework, che è un set di set di principi guida che possono essere usati per migliorare la qualità di un carico di lavoro. Per altre informazioni, vedere Framework ben progettato di Microsoft Azure.
Efficienza prestazionale
L'efficienza delle prestazioni è la capacità di dimensionare il carico di lavoro per soddisfare in modo efficiente le richieste poste dagli utenti. Per altre informazioni, vedere Panoramica dell'efficienza delle prestazioni.
GPU e CPU
Per i carichi di lavoro di Deep Learning, le GPU in genere eseguono CPU per una notevole quantità, nella misura in cui un cluster di CPU ridimensionabile è in genere necessario per ottenere prestazioni confrontabili. Sebbene sia possibile usare solo CPU in questa architettura, le GPU offrono un profilo di costo/prestazioni molto migliore. È consigliabile usare la serie NCv3 più recente di macchine virtuali ottimizzate per gpu.
Le GPU non sono abilitate per impostazione predefinita in tutte le aree. Assicurarsi di selezionare un'area con GPU abilitate. Le sottoscrizioni prevedono anche una quota predefinita di un numero di core pari a zero per macchine virtuali ottimizzate per la GPU. È possibile aumentare questa quota inoltrando una richiesta di supporto. Assicurarsi che la sottoscrizione disponga di una quota sufficiente per eseguire il carico di lavoro.
Parallelizzare tra macchine virtuali e core
Quando si esegue un processo di trasferimento di stile come processo batch, i processi eseguiti principalmente sulle GPU devono essere parallelizzati tra le macchine virtuali. Sono possibili due approcci: è possibile creare un cluster di dimensioni maggiori tramite macchine virtuali con una GPU singola o creare un cluster più piccolo tramite macchine virtuali con più GPU.
Per questo carico di lavoro, queste due opzioni hanno prestazioni confrontabili. L'utilizzo di un minor numero di macchine virtuali con più GPU per ognuna può contribuire a ridurre lo spostamento dati. Tuttavia, il volume di dati per ogni processo per questo carico di lavoro non è di grandi dimensioni, quindi non si osserverà una limitazione elevata da parte dell'archiviazione BLOB.
Passaggio MPI
Quando si crea la pipeline di Azure Machine Learning, uno dei passaggi usati per eseguire il calcolo parallelo è il passaggio MPI (interfaccia di elaborazione dei messaggi). Il passaggio MPI consente di suddividere i dati in modo uniforme tra i nodi disponibili. Il passaggio MPI non viene eseguito finché tutti i nodi richiesti non sono pronti. Se un nodo ha esito negativo o viene superato (se si tratta di una macchina virtuale con priorità bassa), il passaggio MPI dovrà essere rieseguito.
Sicurezza
La sicurezza offre garanzie contro attacchi intenzionali e l'abuso di dati e sistemi preziosi. Per altre informazioni, vedere Panoramica del pilastro della sicurezza. Questa sezione contiene considerazioni per la creazione di soluzioni sicure.
Limitare l'accesso ad Archiviazione BLOB di Azure
In questa architettura di riferimento Archiviazione BLOB di Azure è il componente di archiviazione principale che deve essere protetto. La distribuzione della baseline illustrata nel repository GitHub usa chiavi dell'account di archiviazione per accedere all'archiviazione BLOB. Per un ulteriore controllo e protezione, è consigliabile usare invece una firma di accesso condiviso. che consente l'accesso limitato agli oggetti presenti nell'archiviazione, senza la necessità di codificare le chiavi dell'account o salvarle in testo non crittografato. Questo approccio è particolarmente utile perché le chiavi dell'account sono visibili in testo non crittografato all'interno dell'interfaccia di progettazione dell'app per la logica. L'uso di una firma di accesso condiviso consente anche di garantire che l'account di archiviazione disponga di una governance appropriata e che l'accesso sia concesso soltanto agli utenti desiderati.
Per gli scenari con più dati sensibili, assicurarsi che tutte le chiavi di archiviazione siano protette, poiché concedono un accesso completo a tutti i dati di input e output dal carico di lavoro.
Crittografia e spostamento dei dati
Questa architettura di riferimento usa lo style transfer come esempio di processo di punteggio batch. Per altri scenari basati su dati sensibili, i dati contenuti nella risorsa di archiviazione dovranno essere crittografati a riposo. Ogni volta che i dati vengono spostati da una posizione alla successiva, usare Transport Layer Security (TSL) per proteggere il trasferimento dei dati. Per altre informazioni, vedere la Guida alla sicurezza di Archiviazione di Azure.
Proteggere il calcolo in una rete virtuale
Quando si distribuisce un cluster dell'ambiente di calcolo di Machine Learning, è possibile configurarlo in modo che ne venga eseguito il provisioning all'interno di una subnet di una rete virtuale. Questa subnet consente ai nodi di calcolo del cluster di comunicare in modo sicuro con altre macchine virtuali.
Proteggere da attività dannose
Negli scenari in cui sono presenti più utenti, assicurarsi che i dati sensibili siano protetti da attività dannose. Se altri utenti hanno accesso a questa distribuzione per personalizzare i dati di input, tenere presenti le precauzioni e le considerazioni seguenti:
- Usare il controllo degli accessi in base al ruolo di Azure per limitare l'accesso degli utenti solo alle risorse necessarie.
- Fornire due account di archiviazione separati. Archiviare i dati di input e output nel primo account. Gli utenti esterni potranno avere accesso a questo account. Archiviare script eseguibili e file di log di output nell'altro account. Gli utenti esterni non dovranno avere accesso a questo account. Questa separazione garantisce che gli utenti esterni non possano modificare file eseguibili (per inserire codice dannoso) e non abbiano accesso ai file di log, che potrebbero contenere informazioni riservate.
- Gli utenti malintenzionati possono eseguire un attacco DDoS alla coda dei processi o inserire messaggi non elaborabili in formato non valido nella coda del processo, causando il blocco o la causa di errori di annullamento della coda.
Ottimizzazione dei costi
L'ottimizzazione dei costi riguarda l'analisi dei modi per ridurre le spese non necessarie e migliorare l'efficienza operativa. Per altre informazioni, vedere Panoramica del pilastro di ottimizzazione dei costi.
Rispetto ai componenti di pianificazione e archiviazione, le risorse di calcolo usate in questa architettura di riferimento sono nettamente superiori in termini di costi. Una delle sfide principali consiste nel riuscire ad abbinare efficacemente in parallelo il lavoro all'interno di un cluster di computer abilitati per GPU.
Le dimensioni del cluster di calcolo di Azure Machine Learning possono aumentare e ridurre automaticamente le prestazioni a seconda dei processi nella coda. È possibile abilitare la scalabilità automatica a livello di codice impostando i nodi minimo e massimo.
Per il lavoro che non richiede l'elaborazione immediata, configurare la scalabilità automatica in modo che lo stato predefinito (minimo) sia un cluster di zero nodi. Con questa configurazione, il cluster inizia con un numero di nodi pari a zero, per poi aumentare quando rileva processi nella coda. Se il processo di assegnazione dei punteggi batch avviene solo poche volte al giorno o meno, questa impostazione comporta un notevole risparmio sui costi.
La scalabilità automatica potrebbe non essere appropriata per i processi batch troppo vicini tra loro. Anche il tempo necessario per avviare e interrompere un cluster comporta dei costi. Pertanto, se un carico di lavoro batch inizia solo pochi minuti dopo il termine del processo precedente, potrebbe essere più conveniente lasciare il cluster attivo tra i processi.
L'ambiente di calcolo di Azure Machine Learning supporta anche macchine virtuali con priorità bassa, che consente di eseguire il calcolo in macchine virtuali scontate, con l'avvertenza che potrebbero essere annullate in qualsiasi momento. Le macchine virtuali a bassa priorità sono ideali per carichi di lavoro di assegnazione di punteggi non critici.
Monitorare i processi batch
Durante l'esecuzione del processo, è importante monitorare lo stato di avanzamento e assicurarsi che il processo funzioni come previsto. Tuttavia, il monitoraggio in un cluster di nodi attivi può rivelarsi un problema.
Per controllare lo stato complessivo del cluster, passare al servizio Machine Learning nel portale di Azure per controllare lo stato dei nodi nel cluster. Se un nodo è inattivo o un processo non è riuscito, i log degli errori vengono salvati nell'archivio BLOB e sono accessibili anche nella portale di Azure.
È possibile arricchire ulteriormente il monitoraggio connettendo i log ad Application Insights o eseguendo processi separati per il polling dello stato del cluster e dei relativi processi.
Log con Azure Machine Learning
Azure Machine Learning registra automaticamente tutto stdout/stderr nell'account di archiviazione BLOB associato. Se non diversamente specificato, l'area di lavoro di Azure Machine Learning eseguirà automaticamente il provisioning di un account di archiviazione e ne eseguirà il dump. È anche possibile usare uno strumento di spostamento di archiviazione, ad esempio Archiviazione di Azure Explorer, che è un modo più semplice per esplorare i file di log.
Distribuire lo scenario
Per distribuire questa architettura di riferimento, seguire la procedura descritta nel repository GitHub.
È anche possibile distribuire un'architettura di assegnazione dei punteggi batch per i modelli di Deep Learning usando il servizio Azure Kubernetes (servizio Azure Kubernetes). Seguire i passaggi descritti in questo repository GitHub.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- Jian Tang | Program Manager II
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.
Passaggi successivi
- Assegnazione dei punteggi batch dei modelli Spark in Azure Databricks
- Assegnazione dei punteggi batch dei modelli Python in Azure