Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L'elaborazione del linguaggio naturale comprende tecniche che analizzano, comprendono e generano il linguaggio umano dai dati di testo. Azure fornisce servizi gestiti basati su API e framework open source distribuiti che riguardano carichi di lavoro di elaborazione del linguaggio naturale che vanno dall'analisi del sentiment e dal riconoscimento delle entità alla classificazione dei documenti e al riepilogo del testo. Questa guida consente di valutare e scegliere tra le opzioni principali di elaborazione del linguaggio naturale in Azure in modo da poter corrispondere la tecnologia corretta ai requisiti del carico di lavoro.
Nota
Questa guida è incentrata sulle funzionalità di elaborazione del linguaggio naturale disponibili tramite Azure Language e Apache Spark con NLP Spark in Azure Databricks o Microsoft Fabric. Non fornisce indicazioni su come selezionare modelli linguistici o progettare Azure soluzioni OpenAI. Alcune descrizioni della piattaforma potrebbero fare riferimento alle integrazioni supportate del modello di base o del modello di riconoscimento vocale come dettagli di implementazione, ma questa guida è incentrata sulla selezione del servizio di elaborazione del linguaggio naturale. Per altre informazioni, vedere Scegliere una tecnologia di servizi di intelligenza artificiale.
Informazioni sull'elaborazione del linguaggio naturale e sui modelli linguistici
Prima di valutare i servizi di Azure, comprendere qual è l'elaborazione del linguaggio naturale, come differisce dai modelli linguistici e quali attività vengono affrontate.
Distinguere l'elaborazione del linguaggio naturale dai modelli linguistici
In questa sezione vengono chiariti i limiti tra l'elaborazione del linguaggio naturale e i modelli linguistici e vengono illustrate le funzionalità principali abilitate dalle tecniche di elaborazione del linguaggio naturale.
| Dimensione | Elaborazione del linguaggio naturale | Modelli linguistici |
|---|---|---|
| Ambito | Un ampio campo che illustra diverse tecniche di elaborazione del testo, tra cui tokenizzazione, stemming, riconoscimento di entità, analisi del sentiment e classificazione dei documenti. | Un sottotipo del deep learning nell'elaborazione del linguaggio naturale concentrato su attività di comprensione e generazione del linguaggio di alto livello. |
| Examples | Parser basati su regole, classificatori basati su frequenza dei termini-inversa frequenza documenti (TF-IDF), riconoscitori di entità denominate, analizzatori del sentiment. | GPT, BERT e modelli simili basati su trasformatori che generano testo umano e con riconoscimento contestuale. |
| Risultato | Segnali strutturati come etichette, punteggi, intervalli estratti e sintassi analizzata. | Linguaggio naturale fluente, come testo generato, riepiloghi, risposte e completamenti. |
| Relazione | Dominio principale. L'elaborazione del linguaggio naturale comprende la gamma completa di metodi di elaborazione del testo. | Strumento all'interno dell'elaborazione del linguaggio naturale. I modelli linguistici migliorano l'elaborazione del linguaggio naturale senza sostituirla. Gestiscono attività cognitive più ampie, ma non sono sinonimi di elaborazione del linguaggio naturale. |
Funzionalità di elaborazione del linguaggio naturale
Classificare i documenti etichettandoli come sensibili o spam. L'elaborazione del linguaggio naturale classifica automaticamente i documenti in base al contenuto per supportare la conformità e il filtro dei flussi di lavoro.
Riepilogare il testo identificando le entità nel documento. L'elaborazione del linguaggio naturale estrae le entità chiave per produrre riepiloghi concisi che acquisiscono le informazioni più importanti.
Contrassegna i documenti con parole chiave usando entità identificate. Dopo aver identificato le entità, è possibile generare tag di parole chiave che semplificano l'organizzazione dei documenti. Usare questi tag per la ricerca e il recupero basati sul contenuto.
Individuare gli argomenti per la navigazione e la scoperta di documenti correlati. L'elaborazione del linguaggio naturale identifica gli argomenti chiave usando entità estratte, che supporta la categorizzazione dei documenti e la navigazione basata su argomenti.
Valutare il sentiment del testo. L'analisi del sentiment valuta il tono emotivo del testo e classifica il contenuto come positivo, negativo o neutro.
Inserire output di elaborazione del linguaggio naturale in flussi di lavoro downstream. I risultati, ad esempio le entità estratte, i punteggi del sentiment e le etichette degli argomenti, fungono da input per l'elaborazione, l'indicizzazione della ricerca e l'analisi.
Identificare i potenziali casi d'uso
Gli scenari aziendali in molti settori traggono vantaggio dalle soluzioni di elaborazione del linguaggio naturale. I casi d'uso seguenti illustrano come le tecniche di elaborazione del linguaggio naturale affrontino le sfide reali, dall'elaborazione di documenti non strutturati all'abilitazione delle applicazioni emergenti nella cybersecurity e nell'accessibilità.
Elaborare documenti e testo non strutturato
Estrarre intelligenza dai documenti creati dal computer. L'elaborazione del linguaggio naturale consente l'elaborazione di documenti in settori finanziari, sanitari, retail, governativi e di altro tipo. È possibile analizzare i documenti creati digitalmente per estrarre informazioni strutturate da input non strutturati. Per i documenti scritti a mano, usare Azure Document Intelligence per convertire il contenuto scritto a mano in testo prima di applicare tecniche di elaborazione del linguaggio naturale.
Applicare attività di elaborazione del linguaggio naturale indipendenti dal settore per l'elaborazione del testo. Il riconoscimento delle entità denominate (NER), la classificazione, il riepilogo e l'estrazione delle relazioni consentono di elaborare e analizzare automaticamente il contenuto dei documenti non strutturati. Queste attività funzionano tra domini e non richiedono personalizzazioni specifiche del settore.
Creare modelli specifici del dominio per l'analisi specializzata. Esempi di queste attività includono modelli di stratificazione dei rischi per il settore sanitario, classificazione dell'ontologia per la gestione delle conoscenze e riepiloghi delle vendite al dettaglio per i dati dei prodotti e dei clienti. Il training di modelli personalizzati in Azure Language e Spark NLP consente di migliorare l'accuratezza per questi formati di documento specifici del dominio.
Generare report automatizzati da input di dati strutturati. È possibile sintetizzare e generare report testuali completi da dati strutturati. Questa funzionalità aiuta settori come finanza e conformità che richiedono documentazione approfondita.
Abilitare la ricerca, la traduzione e l'analisi
Creare grafici delle informazioni e abilitare la ricerca semantica tramite il recupero delle informazioni. L'elaborazione del linguaggio naturale supporta la creazione di knowledge graph e la ricerca semantica, che consente ai sistemi di interpretare il significato delle query anziché basarsi solo sulla corrispondenza di parole chiave.
Supportare la scoperta di farmaci e le prove cliniche con grafici di conoscenze mediche. I sistemi di elaborazione del linguaggio naturale analizzano il testo clinico. Grafici delle conoscenze mediche creati da tale testo supportano le pipeline di individuazione dei farmaci e la corrispondenza di studi clinici. Questi grafici connettono entità come farmaci, condizioni e risultati per accelerare i flussi di lavoro di ricerca. Analisi del testo per la salute in Azure Language estrae entità mediche, relazioni e affermazioni che si possono usare per costruire questi grafici.
Tradurre il testo per l'intelligenza artificiale conversazionale nelle applicazioni rivolte ai clienti. La traduzione testuale consente l'intelligenza artificiale conversazionale in più settori. È possibile creare applicazioni multilingue rivolte ai clienti che elaborano e rispondono nella lingua preferita dell'utente. Spark NLP offre funzionalità di traduzione direttamente. In Azure usare Azure Translator, che è un servizio separato da Azure Language.
Analizzare il sentiment e l'intelligenza emotiva per la percezione del marchio. L'analisi del sentiment consente di monitorare la percezione del marchio e analizzare il feedback dei clienti visualizzando segnali emotivi positivi, negativi e sfumati dal testo.
Estendere l'elaborazione del linguaggio naturale ai domini emergenti
Creare interfacce con attivazione vocale per Internet delle cose (IoT) e dispositivi intelligenti. L'elaborazione del linguaggio naturale gestisce l'output di testo dei sistemi di riconoscimento vocale per comprendere la finalità dell'utente ed estrarre significato negli scenari IoT e smart device. Gli scenari con attivazione vocale richiedono Azure Voce per la conversione della sintesi vocale prima dell'elaborazione del linguaggio naturale.
Regolare l'output del linguaggio in modo dinamico usando modelli linguistici adattivi. I modelli linguistici adattivi regolano dinamicamente l'output del linguaggio in base ai diversi livelli di comprensione del pubblico, che supportano la distribuzione e l'accessibilità dei contenuti didattici.
Rilevare phishing e disinformazioni tramite l'analisi del testo della cybersecurity. L'elaborazione del linguaggio naturale analizza i modelli di comunicazione e l'utilizzo del linguaggio in tempo reale per identificare potenziali minacce alla sicurezza nella comunicazione digitale. Questa analisi consente di rilevare tentativi di phishing e campagne di informazione errata.
Valutare Azure lingua
Azure Language è un servizio basato sul cloud che fornisce funzionalità di elaborazione del linguaggio naturale per la comprensione e l'analisi del testo. È possibile accedervi tramite il portale Foundry, le API REST e le librerie client per Python, C#, Java e JavaScript senza infrastruttura da gestire. Per lo sviluppo di agenti di intelligenza artificiale, è anche possibile accedere a queste funzionalità tramite il server MCP (Language Model Context Protocol) di Azure. È possibile accedervi come server remoto nel catalogo degli strumenti Microsoft Foundry o come server locale self-hosted.
Funzionalità predefinite
Le funzionalità predefinite non richiedono alcun training del modello e sono pronte per l'uso:
NER: Identifica e classifica le entità nel testo in tipi predefiniti, ad esempio persone, organizzazioni, posizioni e date.
Rilevamento delle informazioni personali: Identifica e redagirà informazioni personali (PII), inclusi i dati personali e sanitari sensibili, nelle conversazioni testuali e trascritte.
Rilevamento lingua: Rileva la lingua di un documento in un'ampia gamma di lingue e dialetti.
Analisi del sentiment e opinion mining: Identifica il sentiment positivo, negativo o neutro nel testo e collega opinioni a elementi specifici, ad esempio attributi di prodotto o aspetti del servizio.
Estrazione frasi chiave: Valuta il testo non strutturato e restituisce un elenco di concetti principali e frasi chiave.
Riassunto: Condensa documenti e conversazioni utilizzando approcci estrattivi o astrattivi, che supportano il riassunto di testo, chat e call center.
Analisi del testo per la salute: Estraggono ed etichettano le informazioni rilevanti di salute da testo clinico non strutturato, incluse entità mediche, relazioni e asserzioni.
Addestrare modelli personalizzati
È possibile usare funzionalità personalizzabili per eseguire il training dei modelli sui dati per gestire attività di elaborazione del linguaggio naturale specifiche del dominio:
- Riconoscimento personalizzato di entità denominate (CNER): Creare modelli personalizzati per estrarre categorie di entità specifiche del dominio da testo non strutturato. Usare CNER quando le categorie NER predefinite non coprono il vocabolario del dominio.
server e agenti MCP del linguaggio Azure
Nota
Il server MCP del linguaggio Azure e sia l'instradamento delle intenzioni che gli agenti per la risposta esatta alle domande sono in anteprima. Le funzionalità di anteprima non includono un contratto di servizio e non è consigliabile per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero avere funzionalità limitate. Per altre informazioni, vedere Condizioni per l'utilizzo Microsoft Azure anteprime.
Azure Language offre agenti predefiniti e opzioni di distribuzione flessibili per i carichi di lavoro di elaborazione del linguaggio naturale di produzione:
Agente di instradamento delle intenzioni: Gestisce i flussi di conversazione. Comprende le intenzioni degli utenti e indirizza alle risposte accurate tramite logica deterministica e verificabile. Usare questo agente quando è necessario un routing conversazionale deterministico trasparente.
Agente di risposta esatta alle domande: Fornisce risposte affidabili e parola per parola alle domande critiche aziendali mantenendo il controllo di qualità e la supervisione umana. Usare questo agente quando l'accuratezza e la coerenza della risposta sono essenziali.
È possibile accedere a entrambi gli agenti tramite il catalogo degli strumenti Foundry. Per altre informazioni, vedere Azure Language MCP server and agents (preview).
Il server MCP del linguaggio Azure supporta più opzioni di distribuzione:
Server MCP ospitato nel cloud remoto: Il catalogo degli strumenti Foundry elenca questo server. Il server fornisce l'accesso gestito dal cloud alle funzionalità del linguaggio di Azure e non richiede alcuna infrastruttura locale.
Server MCP locale self-hosted: Supporta distribuzioni on-premise o autogestite per requisiti di conformità normativa, sicurezza o residenza dei dati.
Distribuzione containerizzata: Le seguenti funzionalità supportano la distribuzione containerizzata per scenari che richiedono ambienti di elaborazione locale o isolati dall'aria. Per l'elenco completo dei contenitori disponibili e del relativo stato di disponibilità, vedere Azure supporto dei contenitori di intelligenza artificiale.
- Analisi del sentimento
- Rilevamento della lingua
- Estrazione di frasi chiave
- NER
- Rilevamento di informazioni personali
- CNER
- Analisi del testo per il settore medico
- Riepilogo (anteprima)
Valutare Apache Spark con Spark NLP
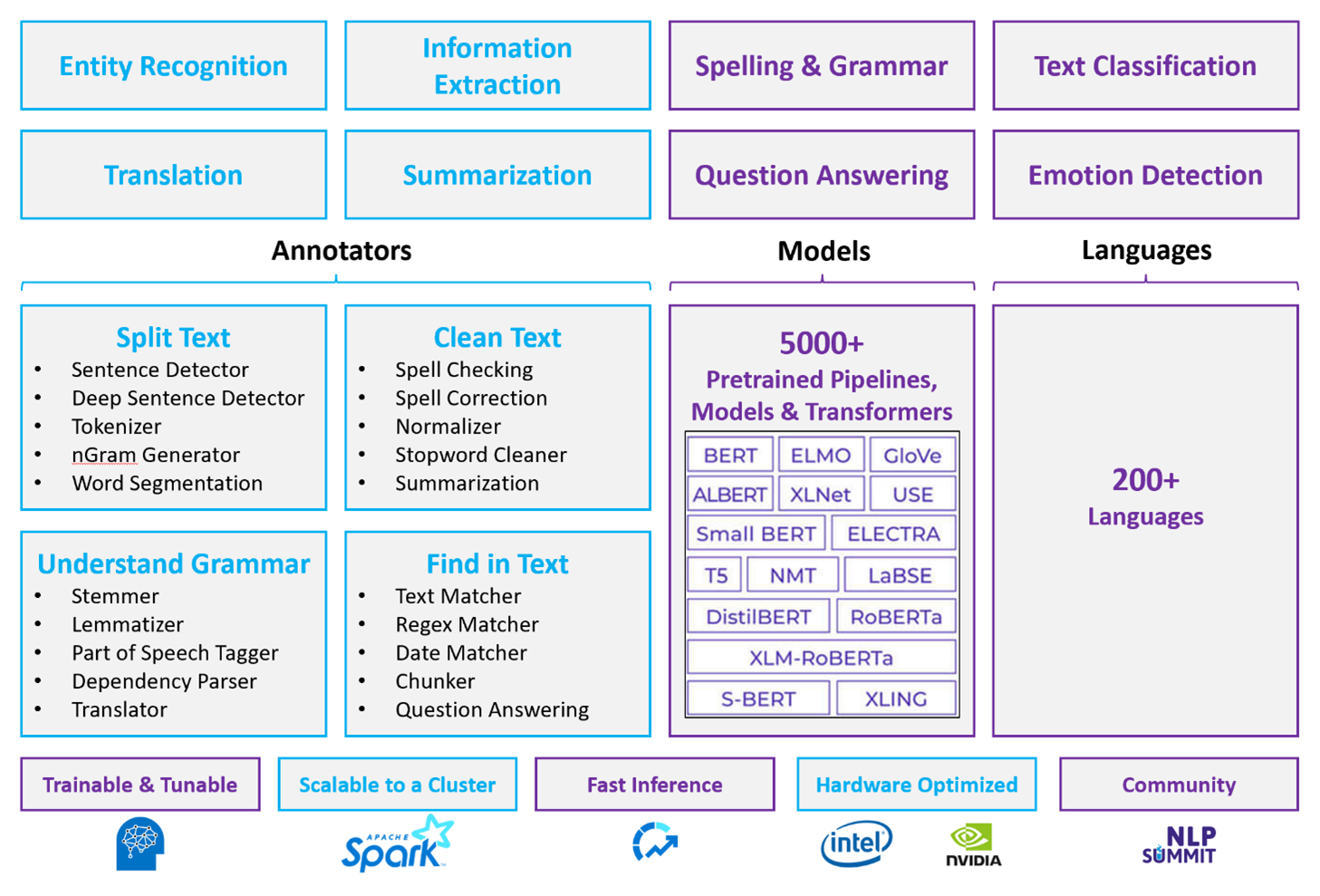
Apache Spark con Spark NLP è un approccio open source distribuito all'elaborazione del linguaggio naturale che opera su scala di cluster. L'architettura, le prestazioni e l'ecosistema di modelli predefiniti della piattaforma Spark NLP lo rendono un'opzione avanzata per carichi di lavoro di elaborazione del linguaggio naturale su larga scala e personalizzabili in Azure Databricks o Fabric.
Comprendere la piattaforma e l'architettura
È consigliabile usare Fabric o Azure Databricks per carichi di lavoro di elaborazione del linguaggio naturale basati su Apache Spark.
Apache Spark offre un'elaborazione parallela in memoria per l'analisi dei Big Data. Fabric e Azure Databricks consentono di accedere alle funzionalità di elaborazione di Apache Spark per carichi di lavoro di elaborazione del linguaggio naturale su larga scala.
Spark NLP opera come estensione nativa di Spark ML nei frame di dati. Questa integrazione consente l'elaborazione unificata del linguaggio naturale e le pipeline di Machine Learning con prestazioni migliorate nei cluster distribuiti.
Spark NLP è una libreria open source con supporto Python, Java e Scala. La libreria offre funzionalità paragonabili a spaCy e Natural Language Toolkit (NLTK), inclusi il controllo ortografico, l'analisi del sentiment e la classificazione dei documenti.

Apache®, Apache Spark e il logo di fiamma sono marchi o marchi registrati di Apache Software Foundation nei United States e/o in altri paesi. L'uso di questi marchi non implica alcuna approvazione da parte di Apache Software Foundation.
Valutare le prestazioni e la scalabilità
I benchmark pubblici mostrano miglioramenti significativi della velocità rispetto ad altre librerie di elaborazione del linguaggio naturale. Rispetto ai framework come spaCy e NLTK, Spark NLP dimostra un training e un'inferenza più veloci nei cluster distribuiti. I modelli personalizzati di cui Spark NLP esegue il training raggiungono livelli di accuratezza che corrispondono a quelli di altri framework di elaborazione del linguaggio naturale, che lo rendono adatto per i carichi di lavoro di produzione che richiedono velocità e precisione.
Le build ottimizzate per CPU, GPU e chip Intel Xeon usano completamente i cluster Apache Spark. Queste versioni consentono al training e all'inferenza di scalare in modo efficiente attraverso i nodi del cluster.
Gli incorporamenti MPNet e ONNX supportano l'elaborazione precisa e compatibile con il contesto. MPNet produce rappresentazioni vettoriali dense che acquisiscono significato semantico e il supporto ONNX consente di importare ed eseguire modelli ottimizzati per l'inferenza.
Usare modelli e pipeline predefiniti
I modelli di Deep Learning predefiniti gestiscono NER, classificazione dei documenti e rilevamento del sentiment. La libreria include modelli di Deep Learning predefiniti.
I modelli linguistici con training preliminare supportano incorporamenti di parole, blocchi, frasi e documenti. La raccolta include modelli linguistici con training preliminare che supportano livelli di incorporamento di parole, blocchi, frasi e documenti. Questi incorporamenti forniscono rappresentazioni vettoriali dense che consentono attività downstream come la ricerca e la classificazione di somiglianza.
L'elaborazione unificata del linguaggio naturale e le pipeline di Machine Learning supportano la classificazione dei documenti e la stima dei rischi. L'integrazione con Spark ML supporta l'elaborazione unificata del linguaggio naturale e le pipeline di Machine Learning per attività come la classificazione dei documenti e la stima dei rischi. Con questo approccio unificato, è possibile combinare l'elaborazione del testo con i modelli di Machine Learning tradizionali in una singola pipeline, riducendo la complessità dell'architettura.
Risolvere i problemi comuni di elaborazione del linguaggio naturale
Sia Azure Language che Apache Spark con Spark NLP devono affrontare sfide comuni nell'elaborazione del linguaggio naturale su larga scala. Se si conoscono queste sfide, è possibile pianificare risorse, progettare pipeline e impostare aspettative di accuratezza prima di eseguire il commit in entrambe le opzioni.
Elaborazione delle risorse
L'elaborazione di testo in formato libero richiede risorse di calcolo e tempo significative. I documenti di testo in formato libero sono dispendiosi a livello di calcolo e richiedono molto tempo per l'analisi. Ogni documento richiede la tokenizzazione, la normalizzazione e l'inferenza del modello prima di produrre risultati utilizzabili.
I carichi di lavoro Spark NLP spesso richiedono l'implementazione di elaborazione GPU. Per le pipeline NLP spark su larga scala, i cluster con accelerazione GPU in Azure Databricks o Fabric forniscono la potenza di elaborazione parallela necessaria per il training e l'inferenza. Le ottimizzazioni come la quantizzazione del modello Llama 3.x consentono di ridurre il footprint della memoria e migliorare la velocità effettiva per queste attività a elevato utilizzo.
Azure Language richiede la pianificazione della velocità effettiva e la gestione delle quote. Il servizio gestisce la gestione delle risorse, ma le chiamate API ad alto volume richiedono un'attenta pianificazione della velocità effettiva. Monitorare le tariffe delle richieste in base ai limiti del servizio e ai limiti di frequenza per evitare limitazioni e garantire prestazioni di elaborazione coerenti.
Standardizzazione dei documenti
I documenti reali seguono raramente una struttura coerente. Questa incoerenza crea sfide per le pipeline di estrazione e richiede strategie mirate per mantenere l'accuratezza attraverso le fonti.
Formati incoerenti: Senza un formato documento standardizzato, l'estrazione di fatti specifici dal testo in formato libero può essere difficile. Ad esempio, può trattarsi di una sfida per estrarre numeri di fattura e date da fornitori diversi perché i layout dei campi, le etichette e la formattazione variano in base alle origini.
Training del modello personalizzato: Quando si esegue il training di modelli personalizzati in Spark NLP e Azure Language, è possibile adattarsi ai formati di documento specifici del dominio. Quando si esegue il training su campioni rappresentativi dei documenti effettivi, è possibile migliorare l'accuratezza dell'estrazione per campi, entità e modelli non gestiti correttamente dai modelli predefiniti.
Varietà e complessità dei dati
Diverse strutture di documenti e sfumature linguistiche aggiungono complessità. I dati di testo reali sono disponibili in molti formati, stili di scrittura e lingue. Per affrontare queste varianti è necessario che i modelli possano gestire ambiguità, gergo, abbreviazioni e terminologia specifica del dominio mantenendo al contempo l'accuratezza.
Gli incorporamenti MPNet in NLP spark offrono una comprensione contestuale avanzata. Gli incorporamenti MPNet acquisiscono relazioni contestuali tra parole e frasi, che consentono alle pipeline di Spark NLP di gestire in modo più efficace testi complessi. Questi incorporamenti producono rappresentazioni vettoriali dense che mantengono il significato semantico in diversi formati di documento.
I modelli personalizzati nel linguaggio Azure si adattano a modelli di testo specifici del dominio. Con CNER è possibile eseguire il training dei modelli sui propri dati etichettati per riconoscere modelli specifici del dominio. Questo approccio migliora l'affidabilità insegnando al modello di riconoscere le entità e le categorie che i modelli predefiniti non hanno.
Applicare i criteri di selezione chiave
Usare i criteri seguenti per determinare quale opzione di elaborazione del linguaggio naturale di Azure sia la più adatta alle proprie esigenze. Ogni criterio descrive una caratteristica del carico di lavoro e identifica il servizio che lo risolve.
Gestisci le funzionalità di elaborazione del linguaggio naturale: Usare Azure Language API per il riconoscimento delle entità, l'identificazione delle finalità, il rilevamento degli argomenti o l'analisi del sentiment. Queste funzionalità sono disponibili come servizi gestiti con configurazione minima e non è necessario effettuare il provisioning o gestire alcuna infrastruttura.
Modelle predefinite o con training preliminare: Usare Azure Linguaggio se si prevede di usare modelli predefiniti o con training preliminare senza gestire l'infrastruttura. Questo approccio è adatto a set di dati di piccole e medie dimensioni e alle attività standard di elaborazione del linguaggio naturale in cui i modelli predefiniti offrono un'accuratezza sufficiente. Offre scalabilità automatica, sicurezza predefinita e prezzi con pagamento in base alla chiamata senza sovraccarico di gestione del cluster.
Addestramento di modelli personalizzati su set di dati di testo di grandi dimensioni: Usare Azure Databricks o Fabric con Spark NLP. Queste piattaforme offrono potenza di calcolo e flessibilità necessarie per il training completo del modello su set di dati di testo di grandi dimensioni. È anche possibile scaricare modelli tramite Spark NLP, tra cui Llama 3.x e MPNet.
Primitive di elaborazione del linguaggio naturale a basso livello: Usare Azure Databricks o Fabric con Spark NLP per la tokenizzazione, lo stemming, la lemmatizzazione e il TF-IDF. In alternativa, usare una libreria open source come spaCy o NLTK. Azure Language in Foundry Tools usa internamente la tokenizzazione come parte della pipeline del modello, ma non espone questi passaggi come API autonome e controllabili.
Creare pipeline di elaborazione del linguaggio naturale con Spark NLP
Spark NLP segue lo stesso modello di sviluppo dei modelli di Spark ML tradizionali quando si esegue una pipeline di elaborazione del linguaggio naturale. I modelli sottoposti a training vengono gestiti usando MLflow per il tracciamento degli esperimenti e la distribuzione in produzione.

Assemblare i componenti della pipeline di base
Una pipeline Spark NLP concatena gli annotatori in sequenza. Ogni annotatore trasforma l'output della fase precedente e costruisce partendo da testo grezzo fino a vettori semantici.
DocumentAssembler è il punto di ingresso per ogni pipeline Spark NLP. Usare
setCleanupModeper applicare la pre-elaborazione del testo facoltativa, ad esempio la rimozione di tag HTML o la normalizzazione degli spazi vuoti, prima dell'esecuzione di annotatori downstream.SentenceDetector identifica i limiti delle frasi nel documento assemblato. Restituisce le frasi rilevate come una singola riga tramite
Arrayo come righe separate, a seconda della configurazione della pipeline. Il rilevamento accurato delle frasi è importante perché molti annotatori downstream operano a livello di frase.Tokenizer divide il testo non elaborato in token discreti, ad esempio parole, numeri e simboli. Se le regole predefinite non sono sufficienti per il dominio, aggiungere regole personalizzate per gestire vocabolario specializzato, termini sillabati o modelli specifici del dominio.
Normalizer affina i token applicando espressioni regolari e trasformazioni del dizionario. Pulisce il testo per ridurre il rumore prima dell'incorporamento. Ad esempio, è possibile rimuovere gli accenti, convertire in minuscolo o applicare mappature di dizionari personalizzate per standardizzare la terminologia.
WordEmbedding esegue il mapping dei token ai vettori semantici per l'elaborazione contestuale. Ogni token è rappresentato come vettore denso che ne acquisisce il significato rispetto ad altri token. Token non risolti che non vengono visualizzati nel vocabolario di embedding predefiniscono ai vettori zero.
Gestire i modelli con MLflow
Spark NLP usa pipeline Spark MLlib con supporto MLflow nativo. Non è necessario scrivere codice di serializzazione o integrazione personalizzato.
MLflow gestisce il rilevamento dell'esperimento, il controllo delle versioni del modello e la distribuzione. È possibile registrare parametri, metriche e artefatti della pipeline durante le esecuzioni di training. MLflow tiene traccia di ogni esperimento, in modo da poter confrontare i risultati tra iterazioni e riprodurre configurazioni riuscite.
MLflow si integra direttamente con Azure Databricks e Fabric. In Azure Databricks, MLflow viene preinstallato e si integra strettamente con l'area di lavoro. Fabric offre anche un'esperienza MLflow integrata con il tracciamento nativo degli esperimenti e l'autologging, quindi non è necessario installare MLflow separatamente. Se si esegue NLP Spark in un altro ambiente basato su Apache Spark, è possibile installare MLflow separatamente e configurarlo per tenere traccia degli esperimenti in un server di rilevamento remoto.
Utilizzare il Registro modelli MLflow per promuovere i modelli in produzione e mantenere la governance. Il Registro modelli fornisce un repository centrale per gestire le versioni del modello nelle pipeline di elaborazione del linguaggio naturale. Nelle distribuzioni classiche, i modelli passano attraverso fasi come preparazione, produzione e archiviazione. In Azure Databricks le distribuzioni più recenti usano Models in Unity Catalog, che sostituisce le fasi fisse con alias e tag personalizzati per una gestione più flessibile del ciclo di vita. In Fabric l'area di lavoro fornisce il proprio registro dei modelli basato su MLflow.
Matrice di funzionalità
Le tabelle seguenti riepilogano le principali differenze nelle funzionalità tra NLP Spark in Azure Databricks o Fabric e Azure Language.
Funzionalità generali
| Capacità | Spark NLP (Azure Databricks o Fabric) | Azure Lingua |
|---|---|---|
| Modelli pre-addestrati come servizio | Sì | Sì |
| REST API (Interfaccia di Programmazione delle Applicazioni REST) | Sì | Sì |
| Programmabilità | Python, Scala | Vedere Linguaggi di programmazione supportati. |
| Supporta l'elaborazione di set di dati di grandi dimensioni e documenti di grandi dimensioni | Sì | Limitato 1 |
1.Azure Language presenta limiti per le dimensioni dei documenti per richiesta che variano in base alla modalità. Le richieste sincrone supportano fino a 5.120 caratteri per documento e le richieste asincrone supportano fino a 125.000 caratteri per documento. Entrambe le modalità supportano fino a 25 documenti per ogni chiamata API. È possibile elaborare volumi di set di dati di grandi dimensioni tramite batch e impaginazione, ma i singoli documenti che superano il limite di caratteri per la modalità scelta richiedono la suddivisione in blocchi. Per altre informazioni, vedere Data e limiti di frequenza per Azure Language.
Funzionalità degli annotatori
| Capacità | Spark NLP (Azure Databricks o Fabric) | Azure Lingua |
|---|---|---|
| Rilevatore di frasi | Sì | NO |
| Rilevatore di frasi complesso | Sì | NO |
| Tokenizzatore | Sì | Solo interno (non esposto come API autonoma) |
| Generatore di N-grammi | Sì | NO |
| segmentazione delle parole | Sì | Sì |
| Algoritmo di Stemming | Sì | NO |
| Lemmatizzatore | Sì | NO |
| Tag delle parti del discorso | Sì | NO |
| Parser delle dipendenze | Sì | NO |
| Traduzione | Sì | NO |
| Gestione delle stopword | Sì | NO |
| Correzione dell'ortografia | Sì | NO |
| Normalizzatore | Sì | Sì |
| Matcher di testo | Sì | NO |
| TF-IDF | Sì | NO |
| Corrisponde all'espressione regolare | Sì | Limitato |
| Confronta date | Sì | Limitato |
| Segmentatore | Sì | NO |
Funzionalità di elaborazione del linguaggio naturale di alto livello
| Capacità | Spark NLP (Azure Databricks o Fabric) | Azure Lingua |
|---|---|---|
| Controllo ortografico | Sì | NO |
| Riepilogo | Sì | Sì |
| Risposta alle domande | Sì | Sì |
| Rilevamento del sentimento | Sì | Sì |
| Rilevamento delle emozioni | Sì | Limitato 2 |
| Classificazione dei token | Sì | Limitato 3 |
| Classificazione del testo | Sì | Limitato 3 |
| Rappresentazione di testo | Sì | NO |
| NER | Sì | Sì (predefinito). CNER è disponibile tramite modelli personalizzati. 3 |
| Rilevamento della lingua | Sì | Sì |
| Supporta lingue diverse dall'inglese | Sì. Vedere Linguaggi supportati da Spark NLP. | Sì. Consulta le lingue supportate di Azure. |
2.Azure Language supporta il opinion mining, che identifica i sentimenti collegati a aspetti specifici del testo, ma non fornisce un rilevamento delle emozioni dedicato (ad esempio gioia, rabbia o classificazione della tristezza).
3.Disponibiletramite modelli personalizzati. È possibile eseguire il training di modelli di riconoscimento delle entità CNER o personalizzati sui propri dati etichettati.
Contributori
Microsoft gestisce questo articolo. I collaboratori seguenti hanno scritto questo articolo.
Autori principali:
- Ananya Ghosh Chowdhury | Principal Cloud Solution Architect
- Kranthi Manchikanti | Senior AI Solutions Engineer
Altri collaboratori:
- Freddy Ayala | Cloud Solution Architect
- Tincy Elias | Senior Cloud Solution Architect
- Moritz Steller | Architetto senior di soluzioni cloud
Per visualizzare i profili di LinkedIn non pubblici, accedere a LinkedIn.
Passaggi successivi
- Introduzione all'IA in Azure
- Sviluppare soluzioni di elaborazione del linguaggio naturale usando gli strumenti Foundry
" output is necessary.)
documentazione del linguaggio Azure:
- Panoramica del linguaggio Azure
- Documentazione di Foundry
Documentazione di Spark NPL:
componenti Azure:
Informazioni sulle risorse: