Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Azure Databricks è una piattaforma unificata di analisi aperta per la creazione, la distribuzione, la condivisione e la gestione di dati, analisi e soluzioni di intelligenza artificiale di livello aziendale su larga scala. Databricks Data Intelligence Platform si integra con l'archiviazione cloud e la sicurezza nell'account cloud e gestisce e distribuisce automaticamente l'infrastruttura cloud.
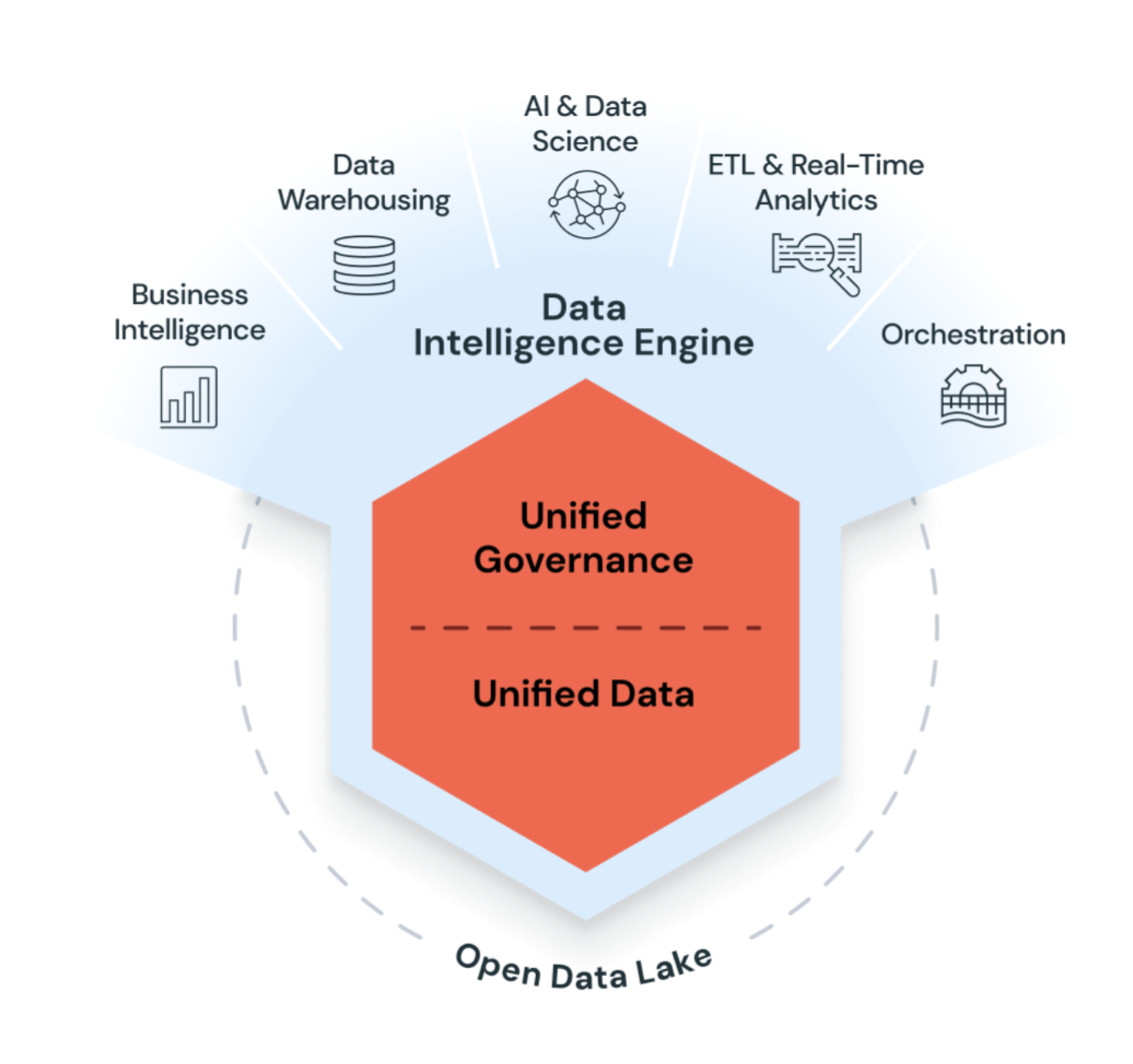
Azure Databricks utilizza l'intelligenza artificiale generativa con il data lakehouse per comprendere le caratteristiche semantiche uniche dei tuoi dati. Ottimizza quindi automaticamente le prestazioni e gestisce l'infrastruttura in base alle esigenze aziendali.
L'elaborazione del linguaggio naturale apprende il linguaggio dell'azienda, in modo da poter cercare e individuare i dati ponendo una domanda nelle proprie parole. L'assistenza per il linguaggio naturale consente di scrivere codice, risolvere gli errori e trovare risposte nella documentazione.
Integrazione open source gestita
Databricks si impegna nella community open source e gestisce gli aggiornamenti delle integrazioni open source con le versioni di Databricks Runtime. Le tecnologie seguenti sono progetti open source creati originariamente dai dipendenti di Databricks:
Casi d'uso comuni
I casi d'uso seguenti evidenziano alcuni dei modi in cui i clienti usano Azure Databricks per eseguire attività essenziali per l'elaborazione, l'archiviazione e l'analisi dei dati che determinano funzioni e decisioni aziendali critiche.
Creare un data lakehouse aziendale
Data lakehouse combina data warehouse aziendali e data lake per accelerare, semplificare e unificare soluzioni di dati aziendali. I data engineer, i data scientist, gli analisti e i sistemi di produzione possono tutti usare data lakehouse come singola fonte di verità, fornendo l'accesso a dati coerenti e riducendo le complessità della compilazione, della gestione e della sincronizzazione di molti sistemi dati distribuiti. Vedere Che cos'è un data lakehouse?.
ETL e ingegneria dei dati
Sia che si generino dashboard o si alimentano applicazioni di intelligenza artificiale, l'ingegneria dei dati fornisce la spina dorsale per le aziende incentrate sui dati assicurandosi che i dati siano disponibili, puliti e archiviati in modelli di dati per un'individuazione e un uso efficienti. Azure Databricks combina la potenza di Apache Spark con gli strumenti delta e personalizzati per offrire un'esperienza ETL senza precedenti. Usare SQL, Python e Scala per comporre la logica ETL e orchestrare la distribuzione pianificata dei processi con pochi clic.
Le pipeline dichiarative di Lakeflow semplificano ulteriormente l'ETL gestendo in modo intelligente le dipendenze tra set di dati e distribuendo e ridimensionando automaticamente l'infrastruttura di produzione per garantire un recapito tempestivo e accurato dei dati alle specifiche.
Azure Databricks offre strumenti per l'ingestione dei dati, incluso Auto Loader, uno strumento efficiente e scalabile per il caricamento incrementale e idempotente dei dati dall'archiviazione oggetti cloud e dai data lake nel data lakehouse.
Machine Learning, intelligenza artificiale e data science
Azure Databricks Machine Learning espande le funzionalità di base della piattaforma con una suite di strumenti personalizzati in base alle esigenze di data scientist e ingegneri di Machine Learning, tra cui MLflow e Databricks Runtime per Machine Learning.
Modelli linguistici di grandi dimensioni e intelligenza artificiale generativa
Databricks Runtime per Machine Learning include librerie come Hugging Face Transformers che consentono di integrare modelli con training preliminare esistenti o altre librerie open source nel flusso di lavoro. L'integrazione di Databricks MLflow semplifica l'uso del servizio di rilevamento MLflow con pipeline, modelli ed elaborazione dei trasformatori. Integrare modelli o soluzioni OpenAI da partner come John Snow Labs nei flussi di lavoro di Databricks.
Con Azure Databricks, personalizzare un LLM sui dati per l'attività specifica. Grazie al supporto di strumenti open source, come Hugging Face e DeepSpeed, è possibile prendere efficacemente un modello di base LLM e iniziare l'addestramento con i propri dati per una maggiore accuratezza nel proprio dominio e carico di lavoro.
Azure Databricks offre inoltre funzioni di intelligenza artificiale che gli analisti di dati SQL possono usare per accedere ai modelli LLM, tra cui OpenAI, direttamente all'interno delle pipeline di dati e dei flussi di lavoro. Vedere Applicare intelligenza artificiale ai dati usando Funzioni di intelligenza artificiale di Azure Databricks.
Archiviazione dei dati, analisi e Business Intelligence
Azure Databricks combina interfacce utente semplici da usare con risorse di calcolo convenienti e un'archiviazione infinitamente scalabile e conveniente per offrire una potente piattaforma per l'esecuzione di query analitiche. Gli amministratori configurano cluster di calcolo scalabili come sql warehouse, consentendo agli utenti finali di eseguire query senza doversi preoccupare delle complessità del lavoro nel cloud. Gli utenti SQL possono eseguire query sui dati nel lakehouse usando l'editor di query SQL o nei notebook. I notebook supportano Python, R e Scala oltre a SQL e consentono agli utenti di incorporare le stesse visualizzazioni disponibili nei dashboard legacy insieme a collegamenti, immagini e commenti scritti in markdown.
Governance dei dati e condivisione dei dati sicura
Unity Catalog offre un modello di governance dei dati unificato per data lakehouse. Gli amministratori cloud configurano e integrano autorizzazioni di controllo di accesso grossolano per Unity Catalog e quindi gli amministratori di Azure Databricks possono gestire le autorizzazioni per team e utenti singoli. I privilegi vengono gestiti con elenchi di controllo di accesso (ACL) tramite interfacce utente o sintassi SQL descrittive, rendendo più semplice per gli amministratori del database proteggere l'accesso ai dati senza dover ridimensionare la gestione degli accessi in identità (IAM) e la rete nativa del cloud.
Il catalogo di Unity semplifica l'esecuzione di analisi sicure nel cloud e offre una divisione di responsabilità che consente di limitare il reskilling o l'upskilling necessario sia per gli amministratori che per gli utenti finali della piattaforma. Vedere Che cos'è Unity Catalog?.
Il lakehouse semplifica la condivisione dei dati all'interno della tua organizzazione, rendendola facile quanto concedere l'accesso per le query a una tabella o a una vista. Per la condivisione all'esterno dell'ambiente sicuro, Unity Catalog include una versione gestita di Condivisione Delta.
DevOps, CI/CD e orchestrazione dei task
I cicli di vita di sviluppo per pipeline ETL, modelli di Machine Learning e dashboard di analisi presentano sfide specifiche. Azure Databricks consente a tutti gli utenti di sfruttare una singola origine dati, riducendo le attività duplicate e la creazione di report non sincronizzati. Fornendo inoltre una suite di strumenti comuni per il controllo delle versioni, l'automazione, la pianificazione, la distribuzione di codice e risorse di produzione, è possibile semplificare il sovraccarico per il monitoraggio, l'orchestrazione e le operazioni.
I processi di lavoro pianificano notebook di Azure Databricks, query SQL e altro codice arbitrario. I bundle di asset di Databricks consentono di definire, distribuire ed eseguire risorse di Databricks, ad esempio processi e pipeline a livello di codice. Le cartelle Git consentono di sincronizzare i progetti di Azure Databricks con diversi provider Git più diffusi.
Per le procedure e le raccomandazioni consigliate per CI/CD, vedere Procedure e flussi di lavoro CI/CD consigliati su Databricks. Per una panoramica completa degli strumenti per gli sviluppatori, vedere Sviluppare in Databricks.
Analisi in tempo reale e in streaming
Azure Databricks sfrutta apache Spark Structured Streaming per lavorare con lo streaming di dati e modifiche incrementali dei dati. Structured Streaming si integra strettamente con Delta Lake e queste tecnologie forniscono le basi sia per le pipeline dichiarative di Lakeflow che per il caricatore automatico. Consulta i concetti di Structured Streaming.