Idee per le soluzioni
Questo articolo è un'idea di soluzione. Per espandere il contenuto con altre informazioni, ad esempio potenziali casi d'uso, servizi alternativi, considerazioni sull'implementazione o indicazioni sui prezzi, inviare commenti e suggerimenti su GitHub.
Implementare una soluzione di elaborazione del linguaggio naturale (NLP) personalizzata in Azure. Usare La prevenzione della perdita dei dati di Spark per attività come il rilevamento e l'analisi di argomenti e sentiment.
Apache, Apache Spark e il logo flame sono marchi o marchi registrati di Apache® Software Foundation nei Stati Uniti e/o in altri paesi. L'uso di questi marchi non implica alcuna approvazione da parte di Apache Software Foundation.
Architettura

Scaricare un file di Visio di questa architettura.
Workflow
- Hub eventi di Azure, Azure Data Factory o entrambi i servizi ricevono documenti o dati di testo non strutturati.
- Hub eventi e Data Factory archivia i dati in formato file in Azure Data Lake Archiviazione. È consigliabile configurare una struttura di directory conforme ai requisiti aziendali.
- L'API di Visione artificiale di Azure usa la funzionalità di riconoscimento ottico dei caratteri (OCR) per usare i dati. L'API scrive quindi i dati nel livello bronze. Questa piattaforma a consumo usa un'architettura lakehouse.
- Nel livello bronze, varie funzionalità di NLP Spark pre-elaborano il testo. Gli esempi includono suddivisione, correzione dell'ortografia, pulizia e comprensione della grammatica. È consigliabile eseguire la classificazione dei documenti a livello bronzo e quindi scrivere i risultati nel livello silver.
- Nel livello silver, le funzionalità avanzate di NLP spark eseguono attività di analisi dei documenti, ad esempio il riconoscimento delle entità denominate, il riepilogo e il recupero delle informazioni. In alcune architetture, il risultato viene scritto nel livello oro.
- Nel livello oro, Spark NLP esegue varie analisi visive linguistiche sui dati di testo. Queste analisi forniscono informazioni dettagliate sulle dipendenze del linguaggio e consentono di visualizzare le etichette NER.
- Gli utenti eseguono query sui dati di testo del livello gold come frame di dati e visualizzano i risultati in Power BI o nelle app Web.
Durante i passaggi di elaborazione, Azure Databricks, Azure Synapse Analytics e Azure HDInsight vengono usati con Spark NLP per fornire funzionalità NLP.
Componenti
- Data Lake Archiviazione è un file system compatibile con Hadoop con uno spazio dei nomi gerarchico integrato e la scalabilità e l'economia di Archiviazione BLOB di Azure.
- Azure Synapse Analytics è un servizio di analisi per data warehouse e sistemi di Big Data.
- Azure Databricks è un servizio di analisi per Big Data facile da usare, semplifica la collaborazione ed è basato su Apache Spark. Azure Databricks è progettato per data science e data engineering.
- Hub eventi inserisce flussi di dati generati da applicazioni client. Hub eventi archivia i dati di streaming e mantiene la sequenza di eventi ricevuti. I consumer possono connettersi agli endpoint dell'hub per recuperare i messaggi da elaborare. Hub eventi si integra con Data Lake Archiviazione, come illustrato in questa soluzione.
- Azure HDInsight è un servizio di analisi open source, ad ampio spettro e gestito nel cloud, rivolto alle aziende. È possibile usare framework open source con Azure HDInsight, ad esempio Hadoop, Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Storm e R.
- Data Factory sposta automaticamente i dati tra gli account di archiviazione con livelli di sicurezza diversi per garantire la separazione dei compiti.
- Visione artificiale usa le API di riconoscimento del testo per riconoscere il testo nelle immagini ed estrarre tali informazioni. L'API Lettura usa i modelli di riconoscimento più recenti ed è ottimizzata per documenti di grandi dimensioni e immagini rumorose. L'API OCR non è ottimizzata per documenti di grandi dimensioni, ma supporta più lingue rispetto all'API di lettura. Questa soluzione usa OCR per produrre dati nel formato hOCR .
Dettagli dello scenario
L'elaborazione del linguaggio naturale (NLP) include molti usi: analisi del sentiment, rilevamento degli argomenti, rilevamento della lingua, estrazione di frasi chiave e categorizzazione dei documenti.
Apache Spark è un framework di elaborazione parallela che supporta l'elaborazione in memoria per migliorare le prestazioni delle applicazioni analitiche di Big Data come NLP. Azure Synapse Analytics, Azure HDInsight e Azure Databricks offrono l'accesso a Spark e sfruttano la potenza di elaborazione.
Per i carichi di lavoro NLP personalizzati, la libreria open source Spark NLP funge da framework efficiente per l'elaborazione di una grande quantità di testo. Questo articolo presenta una soluzione per la prevenzione della perdita di rete personalizzata su larga scala in Azure. La soluzione usa le funzionalità NLP di Spark per elaborare e analizzare il testo. Per altre informazioni su Spark NLP, vedere Spark NLP funzionalità e pipeline, più avanti in questo articolo.
Potenziali casi d'uso
Classificazione dei documenti: Spark NLP offre diverse opzioni per la classificazione del testo:
- Pre-elaborazione del testo in spark NLP e algoritmi di Machine Learning basati su Spark ML
- Pre-elaborazione del testo e incorporamento di parole in algoritmi di Apprendimento automatico e NLP Spark, ad esempio GloVe, BERT e ELMo
- Pre-elaborazione del testo e incorporamento di frasi in algoritmi spark NLP e machine learning e modelli come Universal Sentence Encoder
- Pre-elaborazione e classificazione del testo in NLP Spark che usa l'annotatore ClassifierDL ed è basato su TensorFlow
Estrazione di entità nome (NER): in NLP Spark, con poche righe di codice, è possibile eseguire il training di un modello NER che usa BERT ed è possibile ottenere un'accuratezza all'avanguardia. NER è una sottoattività dell'estrazione delle informazioni. NER individua le entità denominate in testo non strutturato e le classifica in categorie predefinite, ad esempio nomi di persona, organizzazioni, località, codici medici, espressioni temporali, quantità, valori monetari e percentuali. Spark NLP usa un modello NER all'avanguardia con BERT. Il modello è ispirato a un precedente modello NER, LSTM-CNN bidirezionale. Il modello precedente usa una nuova architettura di rete neurale che rileva automaticamente le funzionalità a livello di parola e a livello di carattere. A questo scopo, il modello usa un'architettura LSTM bidirezionale ibrida e CNN, quindi elimina la necessità della maggior parte della progettazione delle funzionalità.
Rilevamento del sentiment e delle emozioni: Spark NLP può rilevare automaticamente aspetti positivi, negativi e neutrali del linguaggio.
Parte del parlato (POS): questa funzionalità assegna un'etichetta grammaticale a ogni token nel testo di input.
Rilevamento frasi (SD): SD si basa su un modello di rete neurale per utilizzo generico per il rilevamento dei limiti delle frasi che identifica le frasi all'interno del testo. Molte attività NLP accettano una frase come unità di input. Esempi di queste attività includono l'assegnazione di tag POS, l'analisi delle dipendenze, il riconoscimento di entità denominate e la traduzione automatica.
Funzionalità e pipeline spark NLP
Spark NLP offre librerie Python, Java e Scala che offrono la funzionalità completa delle librerie NLP tradizionali, ad esempio spaCy, NLTK, Stanford CoreNLP e Open NLP. Spark NLP offre anche funzionalità come il controllo ortografico, l'analisi del sentiment e la classificazione dei documenti. Spark NLP migliora le attività precedenti fornendo precisione, velocità e scalabilità all'avanguardia.
L'NLP di Spark è di gran lunga la libreria NLP open source più veloce. I benchmark pubblici recenti mostrano Spark NLP come 38 e 80 volte più veloci rispetto a spaCy, con un'accuratezza paragonabile per il training di modelli personalizzati. Spark NLP è l'unica libreria open source che può usare un cluster Spark distribuito. Spark NLP è un'estensione nativa di Spark ML che opera direttamente nei frame di dati. Di conseguenza, le velocità in un cluster comportano un altro ordine di miglioramento delle prestazioni. Poiché ogni pipeline NLP spark è una pipeline di Spark ML, L'NLP di Spark è particolarmente adatta per la creazione di pipeline di NLP e Machine Learning unificate, ad esempio la classificazione dei documenti, la stima dei rischi e le pipeline di raccomandazione.
Oltre a prestazioni eccellenti, Spark NLP offre anche un'accuratezza all'avanguardia per un numero crescente di attività NLP. Il team spark NLP legge regolarmente i documenti accademici più recenti e produce i modelli più accurati.
Per l'ordine di esecuzione di una pipeline NLP, Spark NLP segue lo stesso concetto di sviluppo dei modelli di Machine Learning Spark tradizionali. Tuttavia, Spark NLP applica tecniche NLP. Il diagramma seguente illustra i componenti principali di una pipeline di NLP Spark.
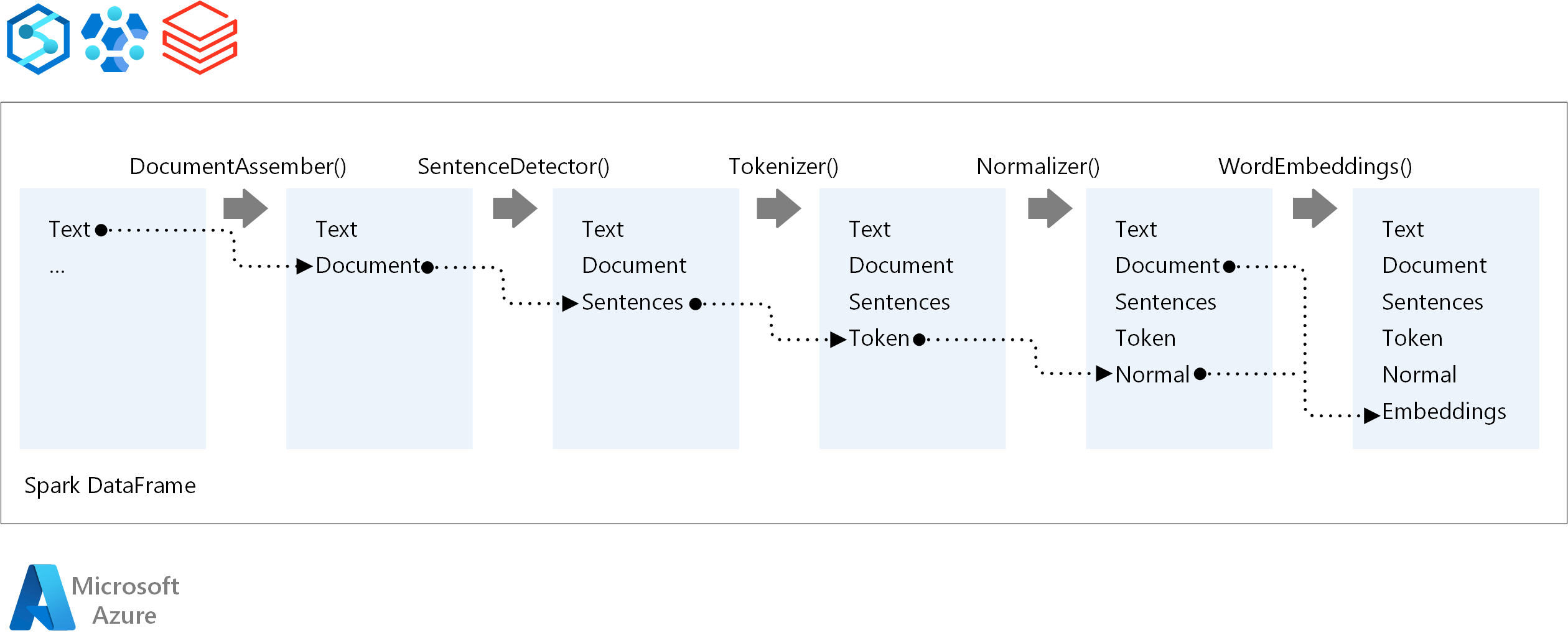
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- Merge Steller | Senior Cloud Solution Architect
Passaggi successivi
Documentazione di Spark NLP:
Componenti di Azure:
Risorse correlate
- Tecnologia di elaborazione del linguaggio naturale (lab)
- Arricchimento tramite intelligenza artificiale con elaborazione di immagini e linguaggio naturale in Ricerca cognitiva di Azure
- Analizzare i feed di notizie con analisi quasi in tempo reale usando l'elaborazione di immagini e linguaggio naturale
- Suggerire tag di contenuto con NLP con Deep Learning