Considerazioni sulla progettazione delle applicazioni per carichi di lavoro cruciali
L'architettura di riferimento mission critical di base illustra un carico di lavoro estremamente affidabile tramite una semplice applicazione del catalogo online. Gli utenti finali possono esplorare un catalogo di elementi, visualizzare i dettagli di un elemento e pubblicare valutazioni e commenti per gli elementi. Questo articolo è incentrato sugli aspetti relativi all'affidabilità e alla resilienza di un'applicazione cruciale, ad esempio l'elaborazione asincrona delle richieste e su come ottenere una velocità effettiva elevata all'interno di una soluzione.
Importante
 Le linee guida sono supportate da un'implementazione di riferimento di livello di produzione che illustra lo sviluppo di applicazioni cruciali in Azure. Questa implementazione può essere usata come base per un ulteriore sviluppo di soluzioni nel primo passo verso la produzione.
Le linee guida sono supportate da un'implementazione di riferimento di livello di produzione che illustra lo sviluppo di applicazioni cruciali in Azure. Questa implementazione può essere usata come base per un ulteriore sviluppo di soluzioni nel primo passo verso la produzione.
Composizione dell'applicazione
Per le applicazioni cruciali su larga scala, è essenziale ottimizzare l'architettura per la scalabilità e la resilienza end-to-end. Questo stato può essere ottenuto tramite la separazione dei componenti in unità funzionali che possono funzionare in modo indipendente. Applicare questa separazione a tutti i livelli nello stack di applicazioni, consentendo a ogni parte del sistema di ridimensionare in modo indipendente e soddisfare le variazioni della domanda.
Un esempio di questo approccio è illustrato nell'implementazione. L'applicazione usa endpoint API senza stato, che separano in modo asincrono le richieste di scrittura a esecuzione prolungata tramite un broker di messaggistica. Il carico di lavoro è composto in modo che l'intero cluster del servizio Azure Kubernetes e altre dipendenze nel timbro possa essere eliminato e ricreato in qualsiasi momento. I componenti principali sono:
- Interfaccia utente: l'applicazione Web a pagina singola a cui si accede dagli utenti finali è ospitata nell'hosting di siti Web statici dell'account di archiviazione di Azure.
- API (
CatalogService): API REST chiamata dall'applicazione dell'interfaccia utente, ma disponibile per altre potenziali applicazioni client. - Worker (
BackgroundProcessor): ruolo di lavoro in background, che elabora le richieste di scrittura nel database ascoltando nuovi eventi nel bus di messaggi. Questo componente non espone alcuna API. - API del servizio integrità (
HealthService): usata per segnalare l'integrità dell'applicazione controllando se funzionano componenti critici (database, bus di messaggistica).

Le applicazioni API, ruolo di lavoro e controllo integrità vengono definite carico di lavoro e ospitate come contenitori in uno spazio dei nomi del servizio Azure Kubernetes dedicato (denominato workload). Non esiste alcuna comunicazione diretta tra i pod. I pod sono senza stato e possono essere ridimensionati in modo indipendente.
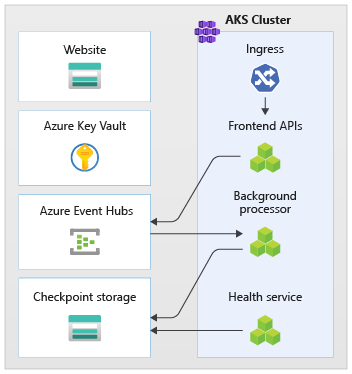
Nel cluster sono in esecuzione altri componenti di supporto:
- Controller di ingresso: il controller di ingresso Nginx viene usato per instradare le richieste in ingresso al carico di lavoro e il bilanciamento del carico tra i pod. Viene esposto tramite Azure Load Balancer con un indirizzo IP pubblico (ma accessibile solo tramite Frontdoor di Azure).
- Gestione certificati: Jetstack
cert-managerviene usato per effettuare automaticamente il provisioning dei certificati SSL/TLS (usando Let's Encrypt) per le regole di ingresso. - Driver dei segreti CSI: il provider di Key Vault di Azure per l'archivio segreti CSI viene usato per leggere in modo sicuro i segreti, ad esempio le stringhe di connessione da Azure Key Vault.
- Agente di monitoraggio: la configurazione omsAgent predefinita viene modificata per ridurre la quantità di dati di monitoraggio inviati all'area di lavoro Log Analytics.
Connessione del database
A causa della natura temporanea dei francobolli di distribuzione, evitare di rendere persistente lo stato all'interno del timbro il più possibile. Lo stato deve essere salvato in modo permanente in un archivio dati esternalizzato. Per supportare l'affidabilità SLO, l'archivio dati deve essere resiliente. È consigliabile usare servizi Gestiti (PaaS) combinati con librerie SDK native che gestiscono automaticamente timeout, disconnessioni e altri stati di errore.
Nell'implementazione di riferimento, Azure Cosmos DB funge da archivio dati principale per l'applicazione. Azure Cosmos DB è stato scelto perché fornisce scritture in più aree. Ogni stamp può scrivere nella replica di Azure Cosmos DB nella stessa area con Azure Cosmos DB che gestisce internamente la replica e la sincronizzazione dei dati tra aree. Azure Cosmos DB per NoSQL viene usato perché supporta tutte le funzionalità del motore di database.
Per altre informazioni, vedere Piattaforma dati per carichi di lavoro cruciali.
Nota
Le nuove applicazioni devono usare Azure Cosmos DB per NoSQL. Per le applicazioni legacy che usano un altro protocollo NoSQL, valutare il percorso di migrazione ad Azure Cosmos DB.
Suggerimento
Per le applicazioni cruciali che assegnano priorità alla disponibilità rispetto alle prestazioni, è consigliabile eseguire operazioni di scrittura in un'area singola e in più aree con livello di coerenza assoluta .
In questa architettura è necessario archiviare temporaneamente lo stato nello stamp per il checkpoint di Hub eventi. Archiviazione di Azure viene usata a tale scopo.
Tutti i componenti del carico di lavoro usano .NET Core SDK di Azure Cosmos DB per comunicare con il database. L'SDK include una logica affidabile per gestire connessioni alle banche dati e gestire gli errori. Ecco alcune impostazioni di configurazione chiave:
- Usa la modalità di connettività diretta. Questa è l'impostazione predefinita per .NET SDK v3 perché offre prestazioni migliori. Esistono meno hop di rete rispetto alla modalità gateway che usa HTTP.
- La risposta al contenuto restituito in scrittura è disabilitata per impedire al client Azure Cosmos DB di restituire il documento dalle operazioni Create, Upsert, Patch e Replace per ridurre il traffico di rete. Inoltre, questo non è necessario per un'ulteriore elaborazione nel client.
- La serializzazione personalizzata viene usata per impostare i criteri di denominazione delle proprietà JSON su per
JsonNamingPolicy.CamelCaseconvertire . Proprietà di tipo NET in stile JSON standard e viceversa. La condizione ignore predefinita ignora le proprietà con valori Null durante la serializzazione (JsonIgnoreCondition.WhenWritingNull). - L'area dell'applicazione è impostata sull'area del timbro, che consente all'SDK di trovare l'endpoint di connessione più vicino (preferibilmente all'interno della stessa area).
//
// /src/app/AlwaysOn.Shared/Services/CosmosDbService.cs
//
CosmosClientBuilder clientBuilder = new CosmosClientBuilder(sysConfig.CosmosEndpointUri, sysConfig.CosmosApiKey)
.WithConnectionModeDirect()
.WithContentResponseOnWrite(false)
.WithRequestTimeout(TimeSpan.FromSeconds(sysConfig.ComsosRequestTimeoutSeconds))
.WithThrottlingRetryOptions(TimeSpan.FromSeconds(sysConfig.ComsosRetryWaitSeconds), sysConfig.ComsosMaxRetryCount)
.WithCustomSerializer(new CosmosNetSerializer(Globals.JsonSerializerOptions));
if (sysConfig.AzureRegion != "unknown")
{
clientBuilder = clientBuilder.WithApplicationRegion(sysConfig.AzureRegion);
}
_dbClient = clientBuilder.Build();
Messaggistica asincrona
L'accoppiamento libero consente di progettare i servizi in modo che un servizio non abbia dipendenza da altri servizi. L'aspetto libero consente a un servizio di operare in modo indipendente. L'aspetto di accoppiamento consente la comunicazione tra servizi tramite interfacce ben definite. Nel contesto di un'applicazione mission critical, semplifica la disponibilità elevata impedendo errori downstream da catena a front-end o timbri di distribuzione diversi.
Caratteristiche chiave:
- I servizi non sono vincolati a usare la stessa piattaforma di calcolo, il linguaggio di programmazione o il sistema operativo.
- I servizi sono ridimensionati in modo indipendente.
- Gli errori downstream non influiscono sulle transazioni client.
- L'integrità transazionale è più difficile da gestire, perché la creazione e la persistenza dei dati si verifica in servizi separati. Si tratta anche di una sfida per i servizi di messaggistica e persistenza, come descritto in questa guida sull'elaborazione dei messaggi idempotenti.
- La traccia end-to-end richiede un'orchestrazione più complessa.
È consigliabile usare modelli di progettazione noti, ad esempio il modello di livellamento del carico basato su coda e il modello Consumer concorrenti. Questi modelli consentono la distribuzione del carico dal producer ai consumer e l'elaborazione asincrona da parte dei consumer. Ad esempio, il ruolo di lavoro consente all'API di accettare la richiesta e tornare rapidamente al chiamante durante l'elaborazione di un'operazione di scrittura del database separatamente.
Hub eventi di Azure viene usato come broker messaggi tra l'API e il ruolo di lavoro.
Importante
Il broker di messaggi non deve essere usato come archivio dati permanente per lunghi periodi di tempo. Il servizio Hub eventi supporta la funzionalità di acquisizione che consente a un hub eventi di scrivere automaticamente una copia dei messaggi in un account di archiviazione di Azure collegato. In questo modo l'utilizzo viene controllato, ma funge anche da meccanismo per eseguire il backup dei messaggi.
Dettagli di implementazione per le operazioni di scrittura
Le operazioni di scrittura, ad esempio la classificazione post e il commento post , vengono elaborate in modo asincrono. L'API invia innanzitutto un messaggio con tutte le informazioni pertinenti, ad esempio il tipo di azione e i dati di commento, alla coda dei messaggi e restituisce HTTP 202 (Accepted) immediatamente con un'intestazione aggiuntiva Location dell'oggetto da creare.
I messaggi nella coda vengono quindi elaborati da BackgroundProcessor istanze che gestiscono la comunicazione effettiva del database per le operazioni di scrittura. BackgroundProcessor viene ridimensionato in modo dinamico in base al volume dei messaggi nella coda. Il limite di scalabilità orizzontale delle istanze del processore è definito dal numero massimo di partizioni di Hub eventi (ovvero 32 per i livelli Basic e Standard, 100 per il livello Premium e 1024 per il livello Dedicato).

La libreria del processore EventHub di Azure in BackgroundProcessor usa Archiviazione BLOB di Azure per gestire la proprietà della partizione, il bilanciamento del carico tra istanze di lavoro diverse e per tenere traccia dello stato di avanzamento usando i checkpoint. La scrittura dei checkpoint nell'archiviazione BLOB non si verifica dopo ogni evento perché ciò comporta un ritardo proibitivo costoso per ogni messaggio. La scrittura del checkpoint viene invece eseguita in un ciclo timer (durata configurabile con un'impostazione corrente di 10 secondi):
while (!stoppingToken.IsCancellationRequested)
{
await Task.Delay(TimeSpan.FromSeconds(_sysConfig.BackendCheckpointLoopSeconds), stoppingToken);
if (!stoppingToken.IsCancellationRequested && !checkpointEvents.IsEmpty)
{
string lastPartition = null;
try
{
foreach (var partition in checkpointEvents.Keys)
{
lastPartition = partition;
if (checkpointEvents.TryRemove(partition, out ProcessEventArgs lastProcessEventArgs))
{
if (lastProcessEventArgs.HasEvent)
{
_logger.LogDebug("Scheduled checkpointing for partition {partition}. Offset={offset}", partition, lastProcessEventArgs.Data.Offset);
await lastProcessEventArgs.UpdateCheckpointAsync();
}
}
}
}
catch (Exception e)
{
_logger.LogError(e, "Exception during checkpointing loop for partition={lastPartition}", lastPartition);
}
}
}
Se l'applicazione del processore rileva un errore o viene arrestata prima di elaborare il messaggio, allora:
- Un'altra istanza rileverà il messaggio per la rielaborazione, perché non è stato eseguito correttamente il checkpoint in Archiviazione.
- Se il ruolo di lavoro precedente è riuscito a rendere persistente il documento nel database prima dell'esito negativo, si verificherà un conflitto (perché viene usato lo stesso ID e la stessa chiave di partizione) e il processore può ignorare in modo sicuro il messaggio, perché è già persistente.
- Se il ruolo di lavoro precedente è stato terminato prima della scrittura nel database, la nuova istanza ripeterà i passaggi e finalizzerà la persistenza.
Dettagli di implementazione per le operazioni di lettura
Le operazioni di lettura vengono elaborate direttamente dall'API e restituiscono immediatamente i dati all'utente.

Se l'operazione è stata completata correttamente, non esiste alcun canale back che comunica con il client. L'applicazione client deve eseguire il polling proattivo dell'API a per gli aggiornamenti dell'elemento specificato nell'intestazione Location HTTP.
Scalabilità
I singoli componenti del carico di lavoro devono aumentare in modo indipendente perché ognuno ha modelli di carico diversi. I requisiti di scalabilità dipendono dalla funzionalità del servizio. Alcuni servizi hanno un impatto diretto sull'utente finale e devono essere in grado di aumentare l'impatto aggressivo per offrire una risposta rapida per un'esperienza utente positiva e prestazioni in qualsiasi momento.
Nell'implementazione i servizi vengono inseriti come contenitori Docker e distribuiti usando i grafici Helm a ogni stampo. Sono configurati per avere le richieste e i limiti previsti di Kubernetes e una regola di ridimensionamento automatico preconfigurato. Il CatalogService componente del BackgroundProcessor carico di lavoro può essere ridimensionato singolarmente, entrambi i servizi sono senza stato.
Gli utenti finali interagiscono direttamente con , CatalogServicequindi questa parte del carico di lavoro deve rispondere in qualsiasi carico. Esistono almeno 3 istanze per cluster da distribuire in tre zone di disponibilità in un'area di Azure. Il servizio di scalabilità automatica orizzontale del pod del servizio Azure Kubernetes si occupa automaticamente dell'aggiunta automatica di altri pod se necessario e la scalabilità automatica di Azure Cosmos DB è in grado di aumentare dinamicamente e ridurre le UR disponibili per la raccolta. Insieme, e CatalogService Azure Cosmos DB formano un'unità di scala all'interno di un timbro.
HPA viene distribuito con un grafico Helm con numero massimo configurabile e numero minimo di repliche. I valori vengono configurati come:
Durante un test di carico è stato identificato che ogni istanza deve gestire ~250 richieste/secondo con un modello di utilizzo standard.
Il BackgroundProcessor servizio ha requisiti molto diversi e viene considerato un ruolo di lavoro in background che ha un impatto limitato sull'esperienza utente. Di conseguenza, BackgroundProcessor ha una configurazione di scalabilità automatica diversa rispetto CatalogService a e può essere ridimensionata tra 2 e 32 istanze (questo limite deve essere basato sul numero di partizioni usate negli Hub eventi, senza alcun vantaggio in presenza di più ruoli di lavoro rispetto alle partizioni).
| Componente | minReplicas |
maxReplicas |
|---|---|---|
| Catalogservice | 3 | 20 |
| BackgroundProcessor | 2 | 32 |
Oltre a questo, ogni componente del carico di lavoro, incluse le dipendenze, ad ingress-nginx esempio ha i budget di interruzione pod configurati per garantire che un numero minimo di istanze sia sempre disponibile quando vengono implementate modifiche nei cluster.
#
# /src/app/charts/healthservice/templates/pdb.yaml
# Example pod distribution budget configuration.
#
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: {{ .Chart.Name }}-pdb
spec:
minAvailable: 1
selector:
matchLabels:
app: {{ .Chart.Name }}
Nota
Il numero minimo effettivo e massimo di pod per ogni componente deve essere determinato tramite test di carico e può variare per ogni carico di lavoro.
Strumentazione
La strumentazione è un meccanismo importante per valutare i collo delle prestazioni e i problemi di integrità che i componenti del carico di lavoro possono introdurre nel sistema. Ogni componente deve generare informazioni sufficienti tramite metriche e log di traccia per poter quantificare le decisioni. Ecco alcune considerazioni chiave per la strumentazione dell'applicazione.
- Inviare log, metriche e dati di telemetria aggiuntivi al sistema di log del timbro.
- Usare la registrazione strutturata anziché testo normale in modo che sia possibile eseguire query sulle informazioni.
- Implementare la correlazione degli eventi per garantire la visualizzazione delle transazioni end-to-end. Nella RI ogni risposta API contiene l'ID operazione come intestazione HTTP per la tracciabilità.
- Non basarsi solo sulla registrazione stdout (console). Tuttavia, questi log possono essere usati per la risoluzione immediata della risoluzione dei problemi di un pod non riuscito.
Questa architettura implementa la traccia distribuita con Application Insights supportata dall'area di lavoro Log Analytics per tutti i dati di monitoraggio delle applicazioni. Azure Log Analytics viene usato per i log e le metriche di tutti i componenti del carico di lavoro e dell'infrastruttura. Il carico di lavoro implementa la traccia end-to-end completa delle richieste provenienti dall'API, tramite Hub eventi, ad Azure Cosmos DB.
Importante
Le risorse di monitoraggio di stamp vengono distribuite in un gruppo di risorse di monitoraggio separato e hanno un ciclo di vita diverso rispetto al timbro stesso. Per altre informazioni, vedere Monitoraggio dei dati per le risorse di stamp.

Dettagli sull'implementazione per il monitoraggio delle applicazioni
Il BackgroundProcessor componente usa il Microsoft.ApplicationInsights.WorkerService pacchetto NuGet per ottenere la strumentazione predefinita dall'applicazione. Serilog viene inoltre usato per tutte le registrazioni all'interno dell'applicazione con applicazione Azure Insights configurato come sink (accanto al sink della console). Solo se necessario per tenere traccia di metriche aggiuntive, viene usata direttamente un'istanza TelemetryClient di Application Insights.
//
// /src/app/AlwaysOn.BackgroundProcessor/Program.cs
//
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureServices((hostContext, services) =>
{
Log.Logger = new LoggerConfiguration()
.ReadFrom.Configuration(hostContext.Configuration)
.Enrich.FromLogContext()
.WriteTo.Console(outputTemplate: "[{Timestamp:yyyy-MM-dd HH:mm:ss.fff zzz} {Level:u3}] {Message:lj} {Properties:j}{NewLine}{Exception}")
.WriteTo.ApplicationInsights(hostContext.Configuration[SysConfiguration.ApplicationInsightsConnStringKeyName], TelemetryConverter.Traces)
.CreateLogger();
}
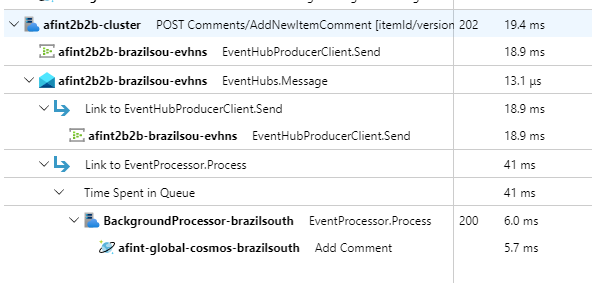
Per dimostrare la tracciabilità delle richieste pratiche, ogni richiesta API (riuscita o meno) restituisce l'intestazione ID correlazione al chiamante. Con questo identificatore il team di supporto dell'applicazione è in grado di cercare Application Insights e ottenere una visualizzazione dettagliata della transazione completa.
//
// /src/app/AlwaysOn.CatalogService/Startup.cs
//
app.Use(async (context, next) =>
{
context.Response.OnStarting(o =>
{
if (o is HttpContext ctx)
{
// ... code omitted for brevity
context.Response.Headers.Add("X-Server-Location", sysConfig.AzureRegion);
context.Response.Headers.Add("X-Correlation-ID", Activity.Current?.RootId);
context.Response.Headers.Add("X-Requested-Api-Version", ctx.GetRequestedApiVersion()?.ToString());
}
return Task.CompletedTask;
}, context);
await next();
});
Nota
Application Insights SDK ha il campionamento adattivo abilitato per impostazione predefinita. Ciò significa che non ogni richiesta viene inviata al cloud e cercabile in base all'ID. I team di applicazioni cruciali devono essere in grado di tracciare in modo affidabile ogni richiesta, pertanto l'implementazione di riferimento ha disabilitato il campionamento adattivo nell'ambiente di produzione.
Dettagli sull'implementazione del monitoraggio di Kubernetes
Oltre all'uso delle impostazioni di diagnostica per inviare log e metriche del servizio Azure Kubernetes a Log Analytics, il servizio Azure Kubernetes è configurato anche per l'uso di Container Insights. L'abilitazione di Container Insights distribuisce OMSAgentForLinux tramite un DaemonSet Kubernetes in ognuno dei nodi nei cluster del servizio Azure Kubernetes. OMSAgentForLinux è in grado di raccogliere log e metriche aggiuntivi dall'interno del cluster Kubernetes e inviarli all'area di lavoro Log Analytics corrispondente. Contiene dati più granulari sui pod, le distribuzioni, i servizi e l'integrità complessiva del cluster.
La registrazione estesa può influire negativamente sui costi e non offre alcun vantaggio. Per questo motivo, l'insieme di log stdout e prometheus è disabilitato per i pod del carico di lavoro nella configurazione di Container Insights, perché tutte le tracce sono già acquisite tramite Application Insights, generando record duplicati.
#
# /src/config/monitoring/container-azm-ms-agentconfig.yaml
# This is just a snippet showing the relevant part.
#
[log_collection_settings]
[log_collection_settings.stdout]
enabled = false
exclude_namespaces = ["kube-system"]
Per informazioni di riferimento, vedere il file di configurazione completo .
Monitoraggio dell’integrità
Il monitoraggio delle applicazioni e l'osservabilità vengono comunemente usati per identificare rapidamente i problemi con un sistema e informare il modello di integrità sullo stato dell'applicazione corrente. Il monitoraggio dell'integrità , eseguito tramite endpoint di integrità e usato dai probe di integrità fornisce informazioni, che in genere indicano al servizio di bilanciamento del carico principale di rimuovere la rotazione dal componente non integro.
Nell'architettura, il monitoraggio dell'integrità viene applicato a questi livelli:
- Pod del carico di lavoro in esecuzione nel servizio Azure Kubernetes. Questi pod hanno probe di integrità e livezza, pertanto il servizio Azure Kubernetes è in grado di gestire il ciclo di vita.
- Il servizio integrità è un componente dedicato nel cluster. Frontdoor di Azure è configurato per eseguire il probe dei servizi di integrità in ogni stamp e rimuovere automaticamente i francobolli non integri dal bilanciamento del carico.
Dettagli sull'implementazione del servizio integrità
HealthService è un componente del carico di lavoro in esecuzione lungo altri componenti (CatalogService e BackgroundProcessor) nel cluster di calcolo. Fornisce un'API REST chiamata dal controllo integrità di Frontdoor di Azure per determinare la disponibilità di un timbro. A differenza dei probe di livezza di base, il servizio di integrità è un componente più complesso che aggiunge lo stato delle dipendenze oltre al proprio.
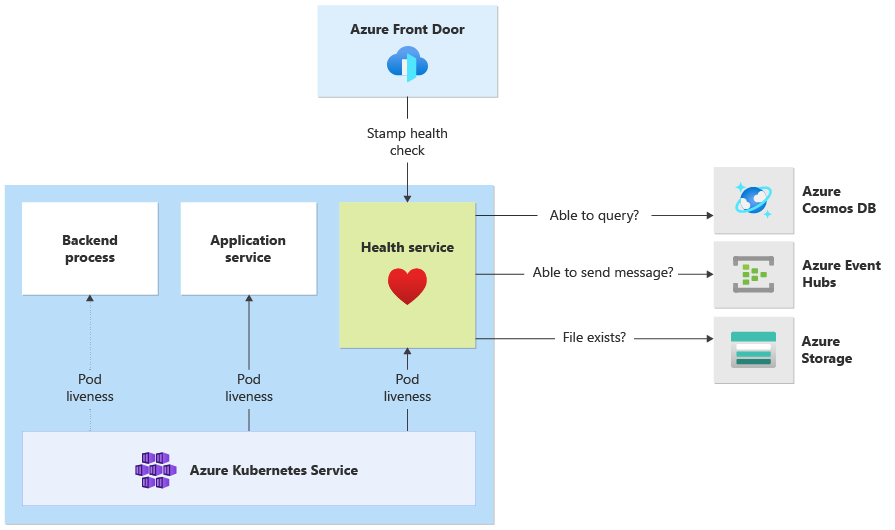
Se il cluster del servizio Azure Kubernetes è inattivo, il servizio integrità non risponde, esegue il rendering del carico di lavoro non integro. Quando il servizio è in esecuzione, esegue controlli periodici sui componenti critici della soluzione. Tutti i controlli vengono eseguiti in modo asincrono e in parallelo. Se uno di essi ha esito negativo, l'intero timbro verrà considerato non disponibile.
Avviso
I probe di integrità di Frontdoor di Azure possono generare un carico significativo nel servizio integrità, perché le richieste provengono da più posizioni PoP. Per evitare l'overload dei componenti downstream, è necessario eseguire la memorizzazione nella cache appropriata.
Il servizio integrità viene usato anche per i test ping url configurati in modo esplicito con la risorsa application insights di ogni stamp.
Per altre informazioni sull'implementazione HealthService , vedere Servizio integrità applicazioni.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per